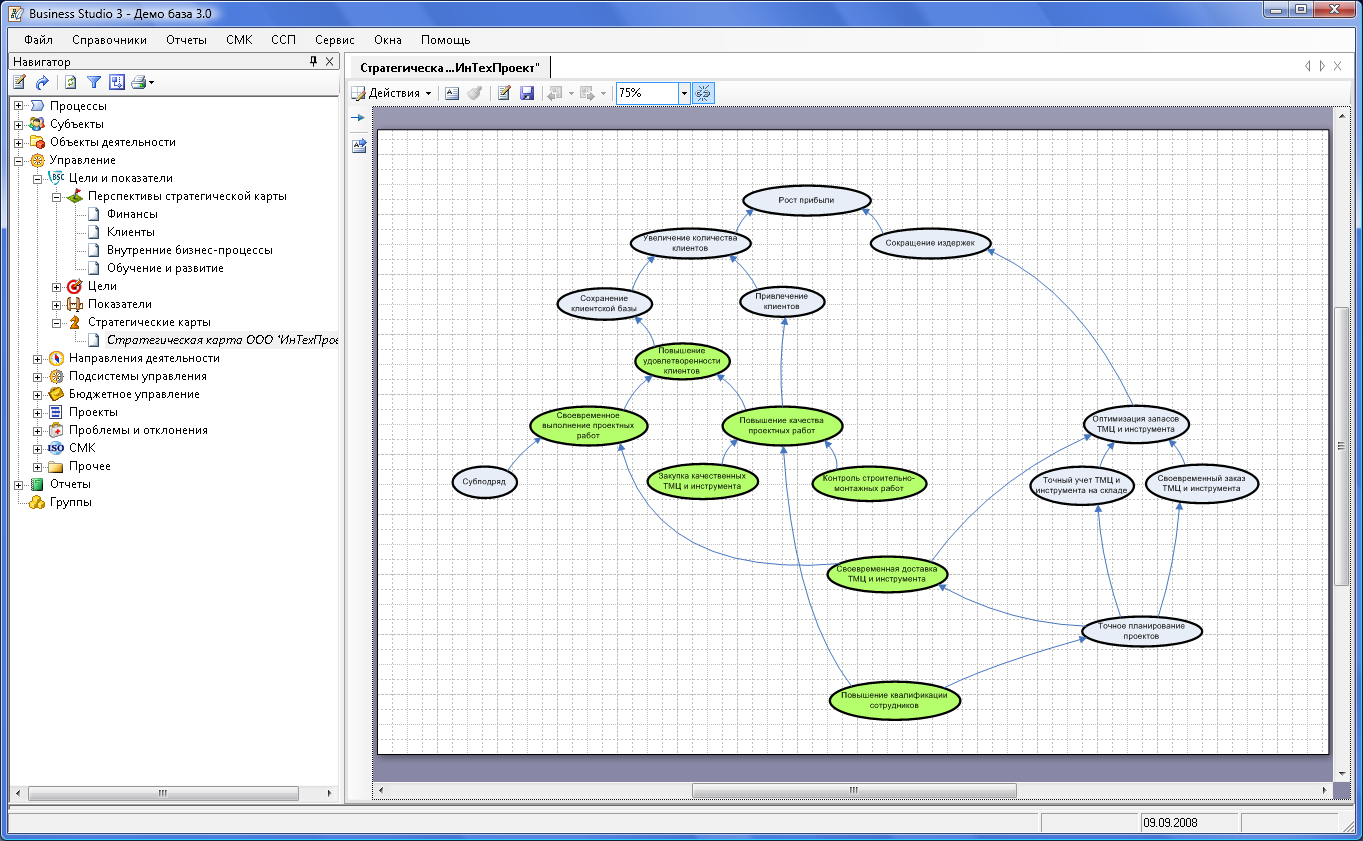
Иерархическая модель данных
Содержание:
- История
- Объектно-ориентированные субд
- Язык описания данных иерархической модели
- Изучение текущей структуры таблицы сотрудниковExamine the current structure of the employee table
- Операторы поиска данных с возможностью модификации
- Теория недели 21.10 — 26.10.2013: Базы данных (табличные, иерархические, сетевые)
- Сетевая модель данных
- Основные понятия иерархической модели
История
Одна из первых новаторских работ по моделированию информационных систем была сделана Янгом и Кентом (1958), которые отстаивали «точный и абстрактный способ определения информационных и временных характеристик проблемы обработки данных ». Они хотели создать «нотацию, которая позволила бы аналитику организовать проблему вокруг любого устройства ». Их работа была первой попыткой создать абстрактную спецификацию и инвариантную основу для разработки различных альтернативных реализаций с использованием различных аппаратных компонентов. Следующий шаг в моделировании ИБ был сделан CODASYL , консорциумом ИТ-индустрии, сформированным в 1959 году, который, по сути, стремился к тому же, что и Янг и Кент: разработка «надлежащей структуры для машинно-независимого языка определения проблем на системном уровне. обработка данных». Это привело к развитию специальной информационной алгебры ИБ .
В 1960-х годах моделирование данных приобрело большее значение с появлением концепции информационной системы управления (MIS). По словам Леондеса (2002), «в это время информационная система предоставляла данные и информацию для целей управления. Система баз данных первого поколения , получившая название Integrated Data Store (IDS), была разработана Чарльзом Бахманом из General Electric. Две известные базы данных модели, сетевая модель данных и иерархическая модель данных , были предложены в этот период времени «. К концу 1960-х Эдгар Ф. Кодд разработал свои теории организации данных и предложил реляционную модель управления базами данных, основанную на логике предикатов первого порядка .
В 1970-х годах моделирование отношений сущностей возникло как новый тип концептуального моделирования данных, первоначально предложенный в 1976 году Питером Ченом . Модели сущностных отношений использовались на первом этапе проектирования информационной системы во время анализа требований для описания информационных потребностей или типа информации, которая должна храниться в базе данных . Этот метод может описывать любую онтологию , т. Е. Обзор и классификацию концепций и их отношений для определенной области интересов .
В 1970-х GM Nijssen разработал метод «Метод анализа информации на естественном языке» (NIAM), который в 1980-х годах в сотрудничестве с Терри Халпином развил в объектно-ролевом моделировании (ORM). Однако именно докторская диссертация Терри Халпина в 1989 году создала формальную основу, на которой основано объектно-ролевое моделирование.
Билл Кент в своей книге 1978 года « Данные и реальность» сравнил модель данных с картой территории, подчеркнув, что в реальном мире «шоссе не окрашены в красный цвет, у рек нет линий графств, проходящих посередине, и вы не вижу контурных линий на горе ». В отличие от других исследователей, которые пытались создать математически чистые и элегантные модели, Кент подчеркивал существенную беспорядок в реальном мире и задачу разработчика моделей данных создавать порядок из хаоса, не искажая истину.
В 1980-х годах, согласно Яну Л. Харрингтону (2000), «развитие объектно-ориентированной парадигмы привело к фундаментальным изменениям в нашем подходе к данным и процедурам, которые работают с ними. Традиционно данные и процедуры были хранятся отдельно: данные и их взаимосвязь в базе данных, процедуры в прикладной программе. Однако объектная ориентация объединила процедуру сущности с ее данными ».
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Язык описания данных иерархической модели
В рамках
иерархической модели выделяют языковые средства описания данных (DDL, Data Definition
Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая
база описывается набором операторов, определяющих как ее логическую структуру,
так и структуру хранения БД. Описание начинается с оператора определения базы — DBD (Data Base
Definition):
DBD Name = <
имя БД>, ACCESS = < способ доступа>
Способ доступа
определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа:
HSAM
—
hierarchical sequential access method (иерархически
последовательный метод),
HISAM
—
hierarchical index sequential access method
(иерархически индексно-последовательный метод),
EDAM
—
hierarchical direct access method (иерархически прямой метод),
HID AM
—
hierarchical index direct access method (иерархически индексно-прямой метод),
INDEX
—
индексный метод.
Далее идет
описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>,
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться
и превысит исходную длину записи до модификации. В этом случае при определенных
методах хранения может понадобиться дополнительное пространство хранения, где
и будут размещены дополнительные данные. Это пространство и называется областью
переполнения.
После описания
всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш
с иерархией. Описание сегментов всегда начинается с описания корневого сегмента.
Общая схема описания типа сегмента такова:
SEGM NAME =
< имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя
частота реализаций сегмента под одним исходным>
PARENT = <имя
родительского сегмента>
Параметр
FREQ определяет среднее количество экземпляров данного сегмента, связанных с
одним экземпляром родительского сегмента. Для корневого сегмента это число возможных
экземпляров корневого сегмента.
Для корневого
сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание
полей:
FIELD NAME =
{(<имя поля> .{U M}) | <имя поля> }.
START = <
номер байта, с которого начинается значения поля >,
BYTES = <размер
поля в байтах>,
TYPE = {X |
Р | С}
Признак SEQ
— задается для ключевого поля, если экземпляры данного сегмента физически упорядочены
в соответствии со значениями данного поля.
Параметр
U задается, если значения ключевого поля уникальны для всех экземпляров данного
сегмента, М — в противном случае. Если поле является ключевым, то его описание
задается в круглых скобках, в противном случае имя поля задается без скобок.
Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены
только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С
— символьный.
Заканчивается
описание схемы вызовом процедуры генерации:
- DBDGEN — указывает
на конец последовательности управляющих операторов описания БД; - FINISH — устанавливает
ненулевой код завершения при обнаружении ошибки; - END — конец.
В системе
может быть несколько физических БД (ФБД), но каждая из них описывается отдельно
своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один
корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
Изучение текущей структуры таблицы сотрудниковExamine the current structure of the employee table
Образец базы данных Adventureworks2017 (или более поздней версии) содержит таблицу Employee в схеме HumanResources.The sample Adventureworks2017 (or later) database contains an Employee table in the HumanResources schema. Чтобы не изменять исходную таблицу, на этом шаге создается копия таблицы Employee , называющаяся EmployeeDemo.To avoid changing the original table, this step makes a copy of the Employee table named EmployeeDemo. Для упрощения этого примера копируется только пять столбцов из исходной таблицы.To simplify the example, you only copy five columns from the original table. Затем выполняется запрос к таблице HumanResources.EmployeeDemo , позволяющий просмотреть структуру данных в таблице без использования типа данных hierarchyid .Then, you query the HumanResources.EmployeeDemo table to review how the data is structured in a table without using the hierarchyid data type.
Копирование таблицы EmployeeCopy the Employee table
- Запустите следующий код в окне редактора запросов, чтобы скопировать структуру и данные таблицы Employee в новую таблицу EmployeeDemo.In a Query Editor window, run the following code to copy the table structure and data from the Employee table into a new table named EmployeeDemo. Поскольку в исходной таблице уже используется hierarchyid, этот запрос фактически преобразует иерархию в плоскую структуру, чтобы получить записи руководителя и сотрудника.Since the original table already uses hierarchyid, this query essentially flattens the hierarchy to retrieve the manager of the employee. В следующих частях этого занятия мы будем реконструировать эту иерархию.In subsequent parts of this lesson we will be reconstructing this hierarchy.
Операторы поиска данных с возможностью модификации
- Найти и удержать единственный
экземпляр сегмента. Эта операция подобна первой операции поиска GET UNIQUE,
единственным отличием этой операции является то, что после выполнения этой
операции пал найденным экземпляром сегмента допустимы операции модификации
(изменения) данных.
Синтаксис:
GET HOLD UNIQUE
<имя сегмента> WHERE <список поиска>
- Найти и удержать следующий
с теми же условиями поиска. Аналогично операции 4 эта операция дублирует вторую
операции поиска GET NEXT с возможностью выполнения последующей модификации
данных.
Синтаксис:
GET HOLD NEXT
- Получить и удержать
следующий для того же родителя. Эта операция является аналогом операции поиска
3, но разрешает выполнение операций модификации данных после себя.
Синтаксис:
GET HOLD NEXT
WITHIN PARENT
Операторы
модификации данных
- Удалить : Это первая
из трех операций модификации.
Синтаксис:
DELETE
Эта команда
не имеет параметров. Почему? Потому что операции модификации действуют на экземпляр
сегмента, найденный командами поиска с удержанием. А он всегда единственный
текущий найденный и удерживаемый для модификации экземпляр конкретного сегмента.
Поэтому при выполнении команды удаления будет удален именно этот экземпляр сегмента.
- Обновить
Синтаксис:
UPDATE
Как же происходит
обновление, если мы и в этой команде не задаем никаких параметров. СУБД берет
данные из рабочей области пользователя, где в шаблонах записей соответствующих
внутренних переменных находятся значения полей каждого сегмента внешней модели,
с которой работает данный пользователь. Именно этими значениями и обновляется
текущий экземпляр сегмента. Значит, перед тем как выполнить операции модификации
UPDATE, необходимо присвоить соответствующим переменным новые значения.
Ввести новый
экземпляр сегмента.
INSERT <имя
сегмента>
Эта команда
позволяет ввести новый экземпляр сегмента, имя которого определено в параметре
команды. Если мы вводим данные в сегмент, который является подчиненным некоторому
родительскому экземпляру сегмента, то он будет внесен в БД и физически подключен
к тому экземпляру родительского сегмента, который в данный момент является текущим.
Как видим,
набор операций поиска и манипулирования данными в иерархической БД невелик,
но он вполне достаточен для получения доступа к любому экземпляру любого сегмента
БД. Однако следует отметить, что способ доступа, который применяется в данной
модели, связан с последовательным перемещением от одного экземпляра сегмента
к другому. Такой способ напоминает движение летательного аппарата или корабля
по заданным координатам и называется навигационным.
Теория недели 21.10 — 26.10.2013: Базы данных (табличные, иерархические, сетевые)
Базы данных (табличные, иерархические, сетевые)
Любой из нас, начиная с раннего детства, много раз сталкивался с базами данных. Что может являться базой данных? Приведите примеры из жизни. Итак, тема урока: База данных.
Поднимите руку, у кого есть записная книжка? Ее можно назвать Базой данных? Конечно! А какую информацию хранит записная книжка? Информацию о людях (фамилия, имя, телефон и т.д.).
Итак, БАЗА ДАННЫХ – это информационная модель, позволяющая в упорядоченном виде хранить данные об объектах и их свойствах.
Рассмотрим типы баз данных.
табличные;
иерархические;
сетевые.
Как вы думаете, какой рисунок подходит к указанной картинке? (сопоставляют)
А наш пример – записная книжка – какой тип данных? (табличный)
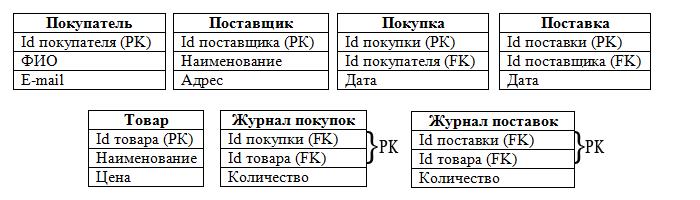
Рассмотрим табличную базу данных. Она содержит перечень объектов одного типа. Давайте посмотрим конкретный пример – таблица “Товар” и таблица “Сотрудники”. К ним мы еще вернемся.
Иерархическая база данных. Такую базу данных графически можно представить как перевернутое дерево, состоящее из объектов различных уровней.
Это База данных, элементы которой организованы по принципу “управления-подчинения”.
Рассмотрим конкретный пример – Проводник.
Нажмите ПКМ по кнопке “Пуск”, выберите Проводник. Верхний уровень занимает папка Рабочий стол. На втором уровне находятся папки Мой компьютер, Мои документы, Сетевое окружение и Корзина, которые являются потомками папки Рабочий стол, а между собой являются близнецами. В свою очередь, папка Мой компьютер является предком по отношению к папкам третьего уровня – папкам дисков и системным папкам.
Еще один тип базы данных – сетевая база данных.
Это база данных, элементы которой могут быть связаны между собой произвольным образом. Самый яркий пример – Глобальная сеть Интернет.
Итак, перейдем к электронной базе данных. Не путайте, пожалуйста, определения Базы данных с Системой управления базой данных.
База данных – это упорядоченный набор данных, а Система управления базой данных – это программа, которая позволяет создавать и работать с базой данных.
Практическая работа. Ребята, давайте запустим программу Access: на Рабочем столе ярлык программы – ключик.
Вы видите, что интерфейс программы похож на все офисные программы Microsoft, поэтому на первом этапе остановимся на окне Базы данных:
В левой части окна расположены объекты, с которыми более подробно мы познакомимся на следующих занятиях.
Кратко рассмотрим объекты.
Таблица – обычные двумерные таблицы.
Формы – электронный аналог бумажного бланка. Одна строка таблицы или запроса.
Запросы – отбор данных на основании заданных условий. Например, есть таблица, где указаны фамилии сотрудников и их год рождения. Требуется узнать фамилии тех сотрудников, у которых год рождения с 1980 по 1985. Эти даты закладывают в условие и затем будут отображены данные только сотрудников этих лет.
Отчеты – собираются данные из разных таблиц в одну таблицу, которую затем можно распечатать.
Модули и макросы мы не будем сегодня рассматривать, т.к. работа с данными объектами требует знаний.
Вернемся к табличной базе данных.
Табличная база данных содержит перечень объектов одного типа.
Поле базы данных – столбец таблицы, содержащей значения определенного свойства.
Запись базы данных – это строка таблицы.
Посмотрим еще раз на таблицы. Что является записью, а что полем?
Домашнее задание:
Дома необходимо выучить все основные определения понятий и найти, где еще применяются базы данных. Придумать свою базу данных. Записать в тетради по две задачи, для решения которых можно использовать созданные сегодня структуры таблиц баз данных
- < Назад
- Вперёд >
Сетевая модель данных
Стандарт
сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference
of Data System Languages), которая определила базовые понятия модели и формальный
язык описания.
Базовыми
объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных,
Элемент данных
—
то же, что и в иерархической модели, то есть минимальная информационная
единица, доступная пользователю с использованием СУБД.
Агрегат данных
—
соответствует следующему уровню обобщения в модели. В модели определены
агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных
имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа
вектор соответствует линейному набору элементов данных. Например, агрегат Адрес
может быть представлен следующим образом:
|
Адрес |
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа
повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат
Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
Записью называется
совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов
реального мира. Понятие записи соответствует понятию «сегмент» в
иерархической модели. Для записи, так же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели является понятие «Набор».
Набор
—
это двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
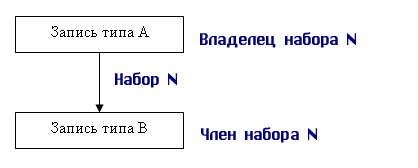
Набор фактически
отражает иерархическую связь между двумя типами записей. Родительский тип записи
в данном наборе называется владельцем набора, а дочерний тип записи — членом
того же набора.
Для любых
двух типов записей может быть задано любое количество наборов, которые их связывают.
Фактически наличие подобных возможностей позволяет промоделировать отношение
«многие-ко-многим» между двумя объектами реального мира, что выгодно
отличает сетевую модель от иерархической. В рамках набора возможен последовательный
просмотр экземпляров членов набора, связанных с одним экземпляром владельца
набора.
Между двумя
типами записей может быть определено любое количество наборов: например, можно
построить два взаимосвязанных набора. Существенным ограничением набора является
то, что один и тот же тип записи не может быть одновременно владельцем и членом
набора.
В качестве
примера рассмотрим таблицу, на основе которой организуем два набора и определим
связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
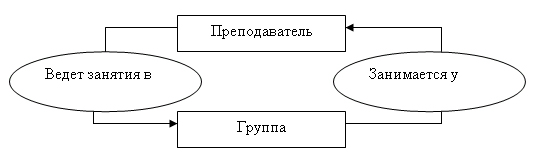
Экземпляров
набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается
у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров
данных наборов.
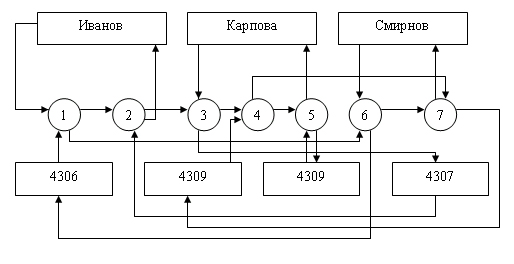
Рис.
3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех
наборов выделяют специальный тип набора, называемый «Сингулярным набором»,
владельцем которого формально определена вся система. Сингулярный набор изображается
в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора,
но у которой не определен тип записи «Владелец набора». Например,
сингулярный набор М.
Сингулярные
наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому
если в задаче алгоритм обработки информации предполагает обеспечение произвольного
доступа к некоторому типу записи, то для поддержки этой возможности необходимо
ввести соответствующий сингулярный набор.
В общем случае
сетевая база данных представляет совокупность взаимосвязанных наборов, которые
образуют на концептуальном уровне некоторый граф.
Основные понятия иерархической модели
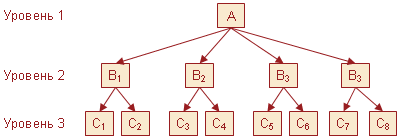
Иерархическая модель является самой ранней моделью баз данных. Для понимания иерархической модели необходимо запомнить следующие термины:
- Атрибут (или поле)– минимальный элемент данных. Атрибут имеет уникальное имя, по которому к нему можно обратиться из программного кода.
- Запись – логически связанная совокупность атрибутов. Запись имеет уникальное имя, которое позволяет обращаться к ней из программного кода. Записи можно добавлять, изменять, удалять.
- Экземпляр записи – конкретная запись с конкретными значениями атрибутов.
- Групповое отношение — иерархическое отношение между записями двух разных типов. Запись, которая, находится выше по иерархии, называется родительской. Записи, которые, расположены ниже по иерархии называются дочерними.
Модель графически можно представить в виде перевернутого дерева, которое состоит из записей различных уровней. Вверху дерева находится одна запись, которая называется корневой записью. Корневая запись содержит ключ — атрибут с уникальным значением. Некорневые записи тоже имеют ключи, но эти ключи должны быть уникальными только в рамках группового отношения. Каждая запись однозначно идентифицируется полным ключом. Полным ключом записи называется совокупность ключей всех записей, начиная с корневой и заканчивая данной записью.
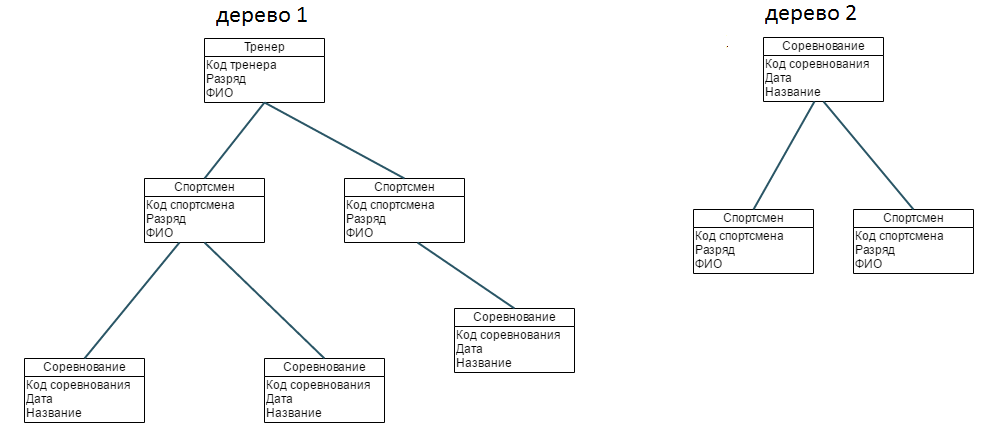
Пример 1
Имеется спортивный клуб, где у каждого спортсмена есть свой тренер. У тренера может быть несколько спортсменов. Спортсмены участвуют в соревнованиях. Каждый спортсмен может участвовать во многих соревнованиях. Для автоматизации учета в спортивном клубе потребуются следующие записи:
- Спортсмен (код спортсмена, разряд, ФИО);
- Тренер (код тренера, разряд, ФИО);
- Соревнование (код соревнования, дата, название).
Отношения между записями соответствуют связям между объектами реального мира. Например, отношение между объектом «тренер» и объектом «спортсмен» моделируется связью типа «один-ко-многим». Поэтому в записи «спортсмен» являются дочерними по отношению к записи «тренер». А вот между объектами «спортсмен» и «соревнование» в реальной жизни присутствует связь «много-ко-многим», потому что спортсмен может участвовать во многих соревнованиях, а в одном соревновании участвует много спортсменов. Отношения типа «много-ко-многим» в иерархической модели данных не существует. Единственный способ смоделировать его — это дублирование информации путем создания дополнительного дерева 2.