Устройство реляционной базы данных
Содержание:
- O(1) vs O(n2)
- Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
- История
- SQL и NoSQL
- Системы Управления Базами Данных
- Схема двумерной реляционной таблицы базы данных
- Хранилище пар «ключ — значение»Key/value data stores
- Шаг 3. Удаление повторений из строк
- Ключи
- Стандартные требованияTypical requirements
- Терминология
O(1) vs O(n2)
В настоящее время многие разработчики не заботятся о временной сложности алгоритмов … и они правы!
Но когда вы имеете дело с большим количеством данных (я не говорю о тысячах) или если вы боретесь за миллисекунды, становится критически важным понять эту концепцию. И как вы понимаете, базы данных должны иметь дело с обеими ситуациями! Я не заставлю вас потратить больше времени, чем необходимо чтобы ухватить суть. Это поможет нам позже понять концепцию оптимизации на основе затрат (cost based optimization).
Концепция
Временная сложность алгоритма используется, чтобы увидеть сколько времени займет выполнение алгоритма для данного объема данных. Чтобы описать эту сложность, используют математические обозначения больших О. Эта нотация используется с функцией, которая описывает, сколько операций нужно алгоритму для заданного количества входных данных.
Например, когда я говорю «этот алгоритм имеет сложность O (some_function() )», это означает, что для обработки определенного объема данных алгоритму требуется some_function(a_certain_amount_of_data) операций.
При этом важно не количество данных**, а то, ** как увеличивается количество операций при увеличении объема данных. Сложность по времени не дает точное количество операций, но хороший способ для оценки времени выполнения
На этом графике вы можете увидеть зависимость числа операций от объема входных данных для различных типов временных сложностей алгоритмов. Я использовал логарифмическую шкалу, чтобы отобразить их. Другими словами, количество данных быстро увеличивается с 1 до 1 млрд. Мы можем увидеть, что:
- O(1) или постоянная сложность остаются постоянными (иначе это не будет называться постоянной сложностью).
- O(log(n)) остается низкой даже с миллиардами данных.
- Наихудшая сложность — O(n2), где количество операций быстро растет.
- Две другие сложности так же быстро увеличиваются.
Примеры
При небольшом количестве данных разница между O(1) и O(n2) незначительна. Например, предположим, что у вас есть алгоритм, который должен обрабатывать 2000 элементов.
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 7 операций
- Алгоритм O (n) обойдется вам в 2 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 операций
- Алгоритм O (n2) обойдется вам в 4 000 000 операций
Как я уже сказал, по-прежнему важно знать эту концепцию при работе с огромным количеством данных. Если на этот раз алгоритм должен обработать 1 000 000 элементов (что не так уж много для базы данных):
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 14 операций
- Алгоритм O (n) обойдется вам в 1 000 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 000 операций
- Алгоритм O (n2) обойдется вам в 1 000 000 000 000 операций
Я не делал расчетов, но я бы сказал, что с помощью алгоритма O (n2) у вас есть время выпить кофе (даже два!). Если вы добавите еще 0 к объему данных, у вас будет время, чтобы вздремнуть.
Идем глубже
Для справки:
- Поиск в хорошей хеш-таблице находит элемент за O (1).
- Поиск в хорошо сбалансированном дереве дает результат за O (log (n)).
- Поиск в массиве дает результат за O (n).
- Лучшие алгоритмы сортировки имеют сложность O (n * log (n)).
- Плохой алгоритм сортировки имеет сложность O (n2).
Примечание: в следующих частях мы увидим эти алгоритмы и структуры данных.
Есть несколько типов временной сложности алгоритма:
- сценарий среднего случая
- лучший вариант развития событий
- и худший сценарий
Временная сложность часто является наихудшим сценарием.
Я говорил только о временной сложности алгоритма, но сложность также применима для:
- потребления памяти алгоритмом
- потребления дискового ввода / вывода алгоритмом
Конечно, есть сложности хуже, чем n2, например:
- n4: это ужасно! Некоторые из упомянутых алгоритмов имеют такую сложность.
- 3n: это еще хуже! Один из алгоритмов, которые мы увидим в середине этой статьи, имеет эту сложность (и он действительно используется во многих базах данных).
- факториал n: вы никогда не получите свои результаты даже с небольшим количеством данных.
- nn: если вы столкнетесь с этой сложностью, вы должны спросить себя, действительно ли это ваша сфера деятельности …
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы ;
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе ;
- возможность работать с разными представлениями информации, в т.ч. без задания схемы данных ;
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения .
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа ;
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений .
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов . Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) . Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции . Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай ;
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами .
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь
А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS
Нереляционные СУБД находят больше областей приложений, чем традиционные SQL-решения
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
История
Термин «реляционная база данных» был изобретен EF Codd в IBM в 1970 году. Кодд ввел этот термин в свою исследовательскую работу «Реляционная модель данных для больших общих банков данных». В этой и последующих статьях он определил, что он имел в виду под словом «реляционный». Одно хорошо известное определение того, что составляет систему реляционных баз данных, состоит из 12 правил Кодда . Однако никакие коммерческие реализации реляционной модели не соответствуют всем правилам Кодда, поэтому этот термин постепенно стал описывать более широкий класс систем баз данных, который как минимум:
- Представить данные пользователя в виде отношений (презентации в табличной форме, то есть в виде коллекции из таблиц с каждой таблицей , состоящей из набора строк и столбцов);
- Предоставьте реляционные операторы для управления данными в табличной форме.
В 1974 году IBM начала разработку System R , исследовательского проекта по разработке прототипа СУБД. Первой системой, проданной как РСУБД, была система Multics Relational Data Store (июнь 1976 г.). Oracle была выпущена в 1979 году компанией Relational Software, ныне Oracle Corporation .. Ingres и IBM BS12 . Другие примеры СУБД включают DB2 , SAP Sybase ASE и Informix . В 1984 году началась разработка первой СУБД для Macintosh под кодовым названием Silver Surfer, позже она была выпущена в 1987 году как 4th Dimension и известна сегодня как 4D.
Первые системы, которые были относительно точными реализациями реляционной модели, были от:
- Мичиганский университет — Микро СУБД (1969)
- Массачусетский технологический институт (1971)
- Британский научный центр IBM в Питерли — IS1 (1970–72) и его преемник PRTV (1973–79)
Наиболее распространенное определение РСУБД — это продукт, который представляет данные в виде набора строк и столбцов, даже если он не основан строго на теории отношений . Согласно этому определению, продукты СУБД обычно реализуют некоторые, но не все из 12 правил Кодда.
Вторая школа мысли утверждает, что если база данных не реализует все правила Кодда (или текущее понимание реляционной модели, выраженное Кристофером Дж. Дейтом , Хью Дарвеном и другими), она не является реляционной. Эта точка зрения, разделяемая многими теоретиками и другими строгими приверженцами принципов Кодда, дисквалифицирует большинство СУБД как нереляционных. Для пояснения они часто называют некоторые СУБД действительно реляционными системами управления базами данных (TRDBMS), а другие называют псевдореляционными системами управления базами данных (PRDBMS).
По состоянию на 2009 год большинство коммерческих реляционных СУБД используют SQL в качестве языка запросов .
Были предложены и реализованы альтернативные языки запросов, в частности, реализация Ingres QUEL до 1996 года .
SQL и NoSQL
abДва варианта представления данных
уплотнения
Масштабируемость
Тип хранилища данных
Сценарий использования
Пример
Рекомендации
Хранилище типа ключ-значение
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту.
Интерактивное обновление домашней страницы пользователя в Facebook.
Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы.
Хранилище, ориентированное на документы
Подходит для хранения объектов различных типов.
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет.
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости.
Система хранения данных с расширяемыми записями
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы.
Приложения, похожие на eBay
Вертикальное и горизонтальное разделение данных для хранения информации клиентов.
Для упрощения разделения данных используются HBase или Hypertable.
Масштабируемая RDBMS
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии.
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов.
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование.
этом
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле — не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
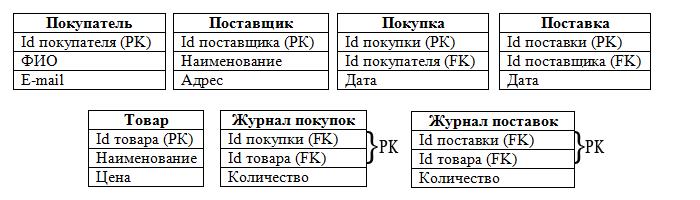
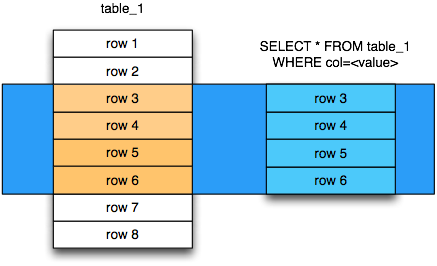
Схема двумерной реляционной таблицы базы данных
| Название атрибута 1 | Название атрибута 2 | Название атрибута 3 | Название атрибута 4 | Название атрибута 5 |
| Элемент_1_1 | Элемент_1_2 | Элемент_1_3 | Элемент_1_4 | Элемент_1_5 |
| Элемент_2_1 | Элемент_2_2 | Элемент_2_3 | Элемент_2_4 | Элемент_2_5 |
| Элемент_3_1 | Элемент_3_2 | Элемент_3_3 | Элемент_3_4 | Элемент_3_5 |
Для детального понимания системы управления модели с помощью SQL лучше всего рассмотреть схему на примере. Нам уже известно, что представляет собой реляционная БД. Запись в каждой таблице – это один элемент данных. Чтобы предотвратить избыточность данных, необходимо провести операции нормализации.
Хранилище пар «ключ — значение»Key/value data stores
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу.A key/value store is essentially a large hash table. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования.You associate each data value with a unique key, and the key/value store uses this key to store the data by using an appropriate hashing function. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.The hashing function is selected to provide an even distribution of hashed keys across the data storage.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления.Most key/value stores only support simple query, insert, and delete operations. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком.To modify a value (either partially or completely), an application must overwrite the existing data for the entire value. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.In most implementations, reading or writing a single value is an atomic operation. Запись больших значений занимает относительно долгое время.If the value is large, writing may take some time.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений.An application can store arbitrary data as a set of values, although some key/value stores impose limits on the maximum size of values. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся.The stored values are opaque to the storage system software. Все сведения о схеме поддерживаются и применяются на уровне приложения.Any schema information must be provided and interpreted by the application. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.Essentially, values are blobs and the key/value store simply retrieves or stores the value by key.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.Key/value stores are highly optimized for applications performing simple lookups using the value of the key, or by a range of keys, but are less suitable for systems that need to query data across different tables of keys/values, such as joining data across multiple tables.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам.Key/value stores are also not optimized for scenarios where querying or filtering by non-key values is important, rather than performing lookups based only on keys. Например, с помощью реляционной базы данных можно найти запись, используя предложение WHERE для фильтрации неключевых столбцов, но в хранилищах «ключ-значение» обычно отсутствует возможность поиска в значениях, или, если они есть, требуется медленный Просмотр всех значений.For example, with a relational database, you can find a record by using a WHERE clause to filter the non-key columns, but key/values stores usually do not have this type of lookup capability for values, or if they do, it requires a slow scan of all values.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.A single key/value store can be extremely scalable, as the data store can easily distribute data across multiple nodes on separate machines.
Соответствующие службы Azure:Relevant Azure services:
- API таблиц Azure Cosmos DBAzure Cosmos DB Table API
- Кэш Azure для RedisAzure Cache for Redis
- хранилище таблиц AzureAzure Table Storage
Шаг 3. Удаление повторений из строк
Теперь мы займёмся устранением других проблем, а именно, избавимся от дубликатов в строках таблицы “users”. Поскольку пользователи @AndyRyder5 и @Brett_Englebert разместили по несколько твиттов, то их имена в таблице “users” (Таблица 3) дублируются в колонке full_name. Данная проблема также решается разделением таблицы “users”.
Поскольку текст твитта и время его создания являются уникальными данными, то их мы поместим в одну и ту же таблицу. Также нам нужно указать связь между твитами и пользователями. Для этого я создал специальный столбец username.
Таблица 4. tweets
| username | text | created_at |
|---|---|---|
| _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Таблица 5. users
| full_name | username |
|---|---|
| Boris Hadjur | _DreamLead |
| Gunnar Svalander | GunnarSvalander |
| GE Software | GEsoftware |
| Adrian Burch | adrianburch |
| Andy Ryder | AndyRyder5 |
| Brett Englebert | Brett_Englebert |
| Nimbus Data Systems | NimbusData |
| SSWUG.ORG | SSWUGorg |
После разделения в таблице users (Таблица 5) у нас присутствуют уникальные (не повторяющиеся) строки.
Данный процесс удаления дубликатов из строк называется приведением ко второй нормальной форме.
Ключи
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций.
Часть этой обработки включает постоянную возможность выбрать или изменить одну и только одну строку в таблице. Таким образом, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другие, более естественные ключи также могут быть идентифицированы и определены как альтернативные ключи (AK). Часто для формирования AK требуется несколько столбцов (это одна из причин, по которой один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Дополнительная технология может применяться для обеспечения уникального идентификатора во всем мире, глобального уникального идентификатора , когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда ПК переходит в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять отношения « один к одному» или « один ко многим» . Большинство проектов реляционных баз данных разрешают отношения « многие ко многим» путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей — отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы — вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе множества других типов столбцов.
Отношения
Отношения — это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Стандартные требованияTypical requirements
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных.Non-relational data stores often use a different storage architecture from that used by relational databases. В частности, они обычно не имеют фиксированной схемы.Specifically, they tend toward having no fixed schema. а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.Also, they tend not to support transactions, or else restrict the scope of transactions, and they generally don’t include secondary indexes for scalability reasons.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных.The following compares the requirements for each of the non-relational data stores:
| ТребованиеRequirement | Хранилище данных документовDocument data | Столбчатое хранилище данныхColumn-family data | Хранилище данных пар «ключ — значение»Key/value data | Хранилище данных графовGraph data |
|---|---|---|---|---|
| НормализацияNormalization | Денормализированные данныеDenormalized | Денормализированные данныеDenormalized | Денормализированные данныеDenormalized | Нормализированные данныеNormalized |
| схемаSchema | Схема при чтенииSchema on read | Семейства столбцов, определенные при записи, схема столбца при чтенииColumn families defined on write, column schema on read | Схема при чтенииSchema on read | Схема при чтенииSchema on read |
| Согласованность (между параллельными транзакциями)Consistency (across concurrent transactions) | Настраиваемый уровень согласованности, гарантии на уровне документаTunable consistency, document-level guarantees | Гарантии на уровне семейства столбцовColumn-family–level guarantees | Гарантии на уровне ключейKey-level guarantees | Гарантии на уровне графаGraph-level guarantees |
| Атомарность (область транзакции)Atomicity (transaction scope) | КоллекцияCollection | ТаблицаTable | ТаблицаTable | ГрафикGraph |
| Стратегия блокировкиLocking Strategy | Оптимистичная (без блокировки)Optimistic (lock free) | Пессимистичная (блокировка строк)Pessimistic (row locks) | Оптимистичная (ETag)Optimistic (ETag) | |
| Шаблон доступаAccess pattern | Прямой доступRandom access | Статистические выражения на основе данных большого форматаAggregates on tall/wide data | Прямой доступRandom access | Прямой доступRandom access |
| ИндексацияIndexing | Первичный и вторичные индексыPrimary and secondary indexes | Первичный и вторичные индексыPrimary and secondary indexes | Только первичный индексPrimary index only | Первичный и вторичные индексыPrimary and secondary indexes |
| Форма представления данныхData shape | ДокументDocument | Таблица с семействами столбцовTabular with column families containing columns | Ключ и значениеKey and value | Граф с ребрами и вершинамиGraph containing edges and vertices |
| разреженные;Sparse | ДаYes | ДаYes | ДаYes | НетNo |
| Масштабность (большое количество столбцов и атрибутов)Wide (lots of columns/attributes) | ДаYes | ДаYes | НетNo | НетNo |
| Размер данныхDatum size | От малого (КБ) до среднего (несколько МБ)Small (KBs) to medium (low MBs) | От среднего (МБ) до большого (несколько ГБ)Medium (MBs) to Large (low GBs) | Небольшой (КБ)Small (KBs) | Небольшой (КБ)Small (KBs) |
| Общий максимальный масштабOverall Maximum Scale | Очень большой (ПБ)Very Large (PBs) | Очень большой (ПБ)Very Large (PBs) | Очень большой (ПБ)Very Large (PBs) | Большой (ТБ)Large (TBs) |
Терминология
Терминология реляционных баз данных.
Реляционная база данных была впервые определена в июне 1970 года Эдгаром Коддом из исследовательской лаборатории IBM в Сан-Хосе . Взгляд Кодда на то, что квалифицируется как СУБД, резюмирован в 12 правилах Кодда . Реляционная база данных стала преобладающим типом базы данных. Другие модели, помимо реляционной, включают иерархическую модель базы данных и сетевую модель .
В таблице ниже приведены некоторые из наиболее важных терминов реляционных баз данных и соответствующие термины SQL :
| Термин SQL | Термин реляционной базы данных | Описание |
|---|---|---|
| Строка | Кортеж или запись | Набор данных, представляющий один элемент |
| Столбец | Атрибут или поле | Помеченный элемент кортежа, например «Адрес» или «Дата рождения». |
| Стол | Отношение или базовая relvar | Набор кортежей с одинаковыми атрибутами; набор столбцов и строк |
| Просмотр или набор результатов | Производный relvar | Любой набор кортежей; отчет с данными из СУБД в ответ на запрос |