Иерархическая база данных — это… модели, примеры
Содержание:
- Управляющая часть иерархической модели
- Преобразование концептуальной модели в иерархическую модель данных
- InnoDB
- Примеры
- Управляющая часть иерархической модели
- Примеры
- Обобщенное описание структуры
- Достоинства и недостатки реляционной модели данных
- MyISAM
- Структура реляционной модели данных
- Примеры иерархических данных, представленных в виде реляционных таблиц
- Примеры
- Недостатки
- Логическое проектирование и оптимизация
- Примеры типичных операторов поиска данных
- Управляющая часть иерархической модели
- Примеры типичных операторов поиска данных
- Отношения и функции
- 8.1. Иерархическая модель базы данных
- Сетевые базы данных
- Объектно-реляционные субд
- Как работают базы данных.
- Типы баз данных
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую структуру данных во многом схоже с преобразованием её в сетевую модель, но и имеет некоторые отличия в связи с тем, что иерархическая модель требует организации всех данных в виде дерева.
Преобразование связи типа «один ко многим» между предком и потомком осуществляется практически автоматически в том случае, если потомок имеет одного предка, и происходит это следующим образом. Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
InnoDB
Данный тип таблиц обеспечивает высокую производительность и устойчивое хранение данных в таблицах объемом вплоть до 1 Тбайт и нагрузкой на
сервер до 800 вставок/обновлений в секунду.Особенности таблиц типа InnoDB:
- Таблицы не создаются в базах данных, и для каждой из таблиц не выделяется отдельный файл данных. Исключение – файл определения с расширением frm, который создается по умолчанию. Все таблицы хранятся в едином табличном пространстве, поэтому имена таблиц должны быть уникальными.
- Хранение данных в едином табличном пространстве позволяет снять ограничение на объем таблиц, так как файл с таблицами может быть разбит не несколько частей и распределен по нескольким дискам или даже хостам.
- Данный тип таблиц поддерживает автоматическое восстановление после сбоев.
- Обеспечивается поддержка транзакций.
- Единственный тип таблиц, поддерживающий внешние ключи и каскадное удаление.
- Выполняется блокировка на уровне отдельных записей.
- Расширенная поддержка кодировок.
- Рушатся при достижении объема в несколько гигабайт, однако заметно уступают в скорости и не поддерживают полнотекстовый поиск.
Примеры
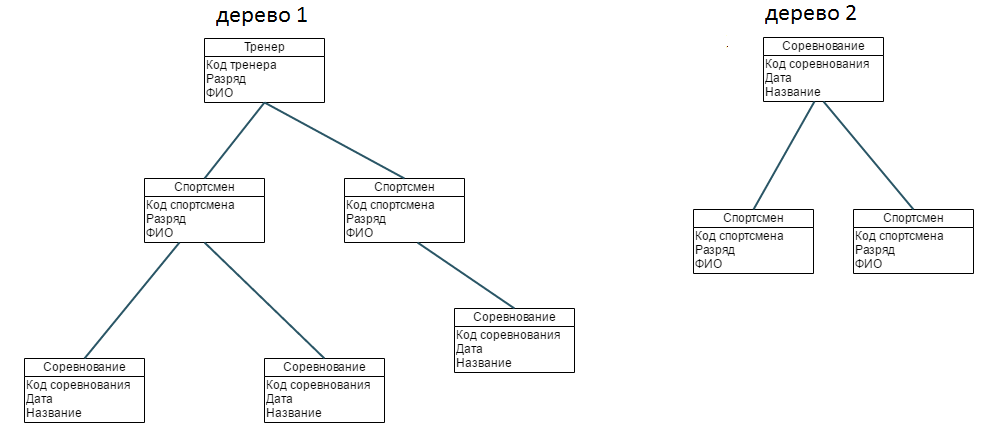
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Достоинства и недостатки реляционной модели данных
Достоинства
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
Недостатки
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
MyISAM
MyISAM – является родным типом таблиц для базы СУБД MySQL. База данных в MySQL организуется как каталог. Таблицы базы данных организуются как файлы данного каталога. Каждая MyISAM таблица хранится на диске в трех файлах, имена которых совпадают с названием таблицы, а расширение может принимать одно из следующих значений:
- Frm – содержит структуру таблицы, в файле данного типа хранится информация об именах и типах столбцов и индексов.
- Myd – файл, в котором содержатся данные таблицы.
- Myi – файл, котором содержатся индексы таблицы.
Особенности типа таблиц MyISAM:
- Данные хранятся в кросс-платформенном формате, это позволяет переносить базы данных с сервера непосредственным копированием файлов, минуя промежуточные форматы.
- Максимальное число индексов в таблице составляет 64. Каждый индекс может состоять максимум из 16 столбцов.
- Для каждого из текстовых столбцов может быть назначена своя кодировка.
- Допускается индексирования текстовых столбцов, в том числе и переменной длины.
- Поддерживается полнотекстовый поиск.
- Каждая таблица имеет специальный флаг, указывающий правильность закрытия таблиц. Если сервер останавливается аварийно, то при его повторном старте незакрытые флаги сигнализируют о возможных сбойных таблицах, сервер автоматически проверяет их и пытается восстановить.
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Примеры иерархических данных, представленных в виде реляционных таблиц
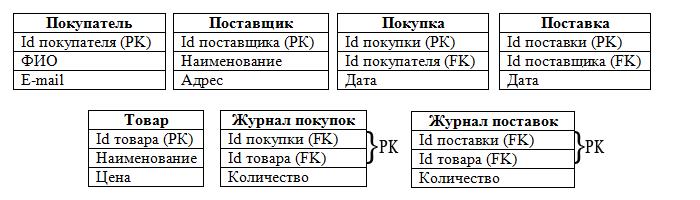
Организация может хранить информацию о сотрудниках в таблице, содержащей атрибуты / столбцы, такие как номер сотрудника, имя, фамилия и номер отдела. Организация предоставляет каждому сотруднику компьютерное оборудование по мере необходимости, но компьютерное оборудование может использоваться только тем сотрудником, за которым оно закреплено. Организация может хранить информацию о компьютерном оборудовании в отдельной таблице, которая включает серийный номер каждой детали, тип и сотрудника, который ее использует. Таблицы могут выглядеть так:
|
|
В этой модели таблица данных представляет «родительскую» часть иерархии, а таблица представляет «дочернюю» часть иерархии. В отличие от древовидных структур, обычно встречающихся в алгоритмах компьютерного программного обеспечения, в этой модели дети указывают на родителей. Как показано, каждый служащий может владеть несколькими единицами компьютерного оборудования, но каждая отдельная единица компьютерного оборудования может иметь только одного служащего-владельца.
Рассмотрим следующую структуру:
| EmpNo | Обозначение | Отчеты |
|---|---|---|
| 10 | Директор | |
| 20 | Старший менеджер | 10 |
| 30 | Машинистка | 20 |
| 40 | Программист | 20 |
В этом «дочерний» тот же тип, что и «родитель». В иерархии указано, что EmpNo 10 является начальником из 20, а 30 и 40 каждый отчет по 20 представлен столбцом «ReportsTo». В терминах реляционной базы данных столбец ReportsTo — это внешний ключ, ссылающийся на столбец EmpNo. Если бы «дочерний» тип данных был другим, он находился бы в другой таблице, но все равно существовал бы внешний ключ, ссылающийся на столбец EmpNo таблицы сотрудников.
Эта простая модель, широко известная как модель списка смежности, была введена доктором Эдгаром Ф. Коддом после того, как появились первые критические замечания о том, что реляционная модель не может моделировать иерархические данные. Однако эта модель является лишь частным случаем общего списка смежности для графа.
Примеры
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например, какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневого каталога, в котором имеется иерархия подкаталогов и файлов.
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Логическое проектирование и оптимизация
OLTP – обработка транзакций в режиме реального времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы минимальное время отклика. Примерами OLTP приложений могут быть системы складского учета, системы заказов билетов, банковские системы, выполняющие операции по переводу денег.
Особенности OLTP приложений:
- Транзакций очень много.
- Транзакции выполняются одновременно.
- При возникновении ошибки транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до начала транзакции (не должно быть ситуации, когда деньги сняты со счета, но не поступили на другой счет).
- Все запросы к базе данных, которые должны выполняться в реальном времени, состоят из команд вставки, обновления, удаления.
OLAP системы характеризуются следующими признаками:
- Добавление в систему новых данных происходит относительно редко крупными блоками.
- Данные, добавленные в систему, обычно никогда не удаляются.
- Перед загрузкой данные проходят различные процедуры очистки, связанные с тем, что в одну систему могут поступать данные из многих источников, имеющих различные форматы представления для одних и тех же понятий, данные могут быть некорректны, ошибочны
- Запросы к системе являются нерегламентированными и, как правило, достаточно сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата, полученного при выполнении предыдущего запроса.
- Скорость выполнения запросов важна, но не критична.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Управляющая часть иерархической модели
В рамках иерархической модели выделяют языковые средства описания данных (ЯОД) и средства манипулирования данными (ЯМД). Каждая физическая база описывается набором операторов, обусловливающих как её логическую структуру, так и структуру хранения БД. При этом способ доступа устанавливает способ организации взаимосвязи физических записей.
Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо задания имени БД и способа доступа описания должны содержать определения типов сегментов, составляющих БД, в соответствии с иерархией, начиная с корневого сегмента. Каждая физическая БД содержит только один корневой сегмент, но в системе может быть несколько физических БД.
Среди операторов манипулирования данными можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической БД невелик, но вполне достаточен.
Примеры типичных операторов поиска данных
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Отношения и функции
Данная система управления базой данных может предоставлять одну или несколько моделей. Оптимальная структура зависит от естественной организации данных приложения и требований приложения, которые включают скорость транзакций (скорость), надежность, ремонтопригодность, масштабируемость и стоимость. Большинство систем управления базами данных построено на одной конкретной модели данных, хотя продукты могут предлагать поддержку более чем одной модели.
Различные физические модели данных могут реализовать любую заданную логическую модель. Большинство программ баз данных предлагают пользователю некоторый уровень контроля при настройке физической реализации, поскольку сделанный выбор оказывает значительное влияние на производительность.
Модель — это не просто способ структурирования данных: она также определяет набор операций, которые могут выполняться с данными. Например, реляционная модель определяет такие операции, как выбор ( проект ) и соединение . Хотя эти операции могут быть неявными в конкретном языке запросов , они обеспечивают основу, на которой построен язык запросов.
8.1. Иерархическая модель базы данных
Иерархические
модели баз
данных исторически возникли одними из
первых. Информация в
иерархической базе организована по
принципу древовидной структуры, в виде
отношений «предок-потомок«.
Каждая запись может
иметь не более одной родительской записи
и несколько подчиненных. Связи записей
реализуются в виде физических указателей
с одной записи на другую. Основной
недостаток иерархической
структуры базы данных —
невозможность реализовать отношения
«многие-ко-многим«,
а также ситуации, когда запись имеет
несколько предков.
Иерархические
базы данных. Иерархические
базы данных графически
могут быть представлены как
перевернутое дерево,
состоящее из объектов различных уровней.
Верхний уровень (корень
дерева)
занимает один объект,
второй — объекты второго уровня и так
далее.
Между
объектами существуют связи,
каждый объект может
включать в себя несколько объектов
более низкого уровня. Такие объекты
находятся в отношении предка (объект,
более близкий к корню) к потомку
(объект более
низкого уровня), при этомобъект-предок
может не иметь потомков или иметь их
несколько, тогда как объект—потомок обязательно
имеет только одного предка. Объекты,
имеющие общего предка, называются
близнецами.
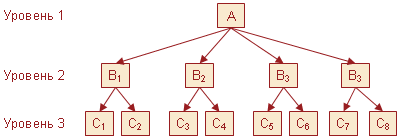
Рис.
6. Иерархическая
база данных
Организация
данных в СУБД иерархического
типа определяется в терминах: элемент,
агрегат, запись (группа),
групповоеотношение, база
данных.
|
Атрибут(элемент |
— |
|
Запись |
— |
|
Групповое |
— иерархическое |
|
Пример.
Поэтому,
Для
Рис. |
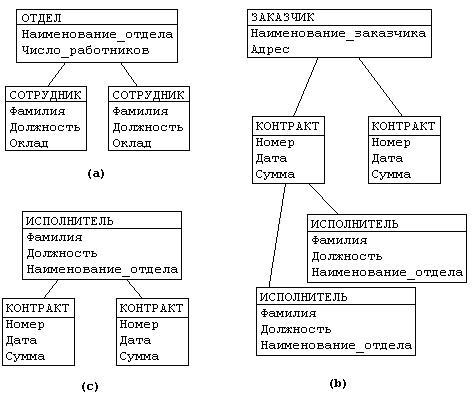
Из
этого примера видны недостатки
иерархических БД:
Частично
дублируется информация между
записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие
записи называют парными), причем
виерархической
модели данных не
предусмотрена поддержка соответствия
между парными записями.
Иерархическая
модель реализует отношение между
исходной и дочерней записью по схеме
1:N, то есть одной родительской записи
может соответствовать любое число
дочерних.
Допустим
теперь, что исполнитель может
принимать участие более чем в одном
контракте (т.е. возникает связь типа
M:N). В этом случае в базу данных необходимо
ввести еще одно групповое отношение,
в котором ИСПОЛНИТЕЛЬ будет
являться исходной записью, а КОНТРАКТ
— дочерней ( рис.
7 c). Таким образом, мы опять вынуждены
дублировать информацию.
Иерархическая
структура предполагаета неравноправие
между данными — одни жестко подчинены
другим. Подобные структуры, безусловно,
четко удовлетворяют требованиям многих,
но далеко не всех реальных задач.
Сетевые базы данных
Существуют:
- реляционные;
- иерархические;
- сетевые базы данных.
Почему мы вновь вспомнили о классификации? Поскольку, в отличие от реляционной, сетевая БД имеет с иерархической схожие черты.
Время вспомнить виды связей в базах данных. Есть связи «один-к-одному», «один-ко-многим» и «многие-ко-многим». Нас интересует последняя. В сетевой БД она проявляется следующим образом: у одного узла-наследника может быть сразу несколько предков. Свойство иметь несколько потомков также сохраняется. Можно сказать, что иерархические базы данных, сетевые базы данных сами по себе уже пример такого наследования. Предком в данном случае является именно иерархическая БД, так как принцип построения структуры в сетевых БД остается прежним.
Объектно-реляционные субд
Разница между объектно-реляционными и объектными СУБД: первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р)СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java. Характерные свойства OРСУБД:
- комплексные данные,
- наследование типа,
- объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты (persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип (UDT — user-defined type). Используются также встроенные конструкторы составных типов, например массив (ARRAY).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором (OID).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database, Microsoft SQL Server 2005, PostgreSQL, а также Sav Zigzag, IBM Cloudscape,
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Типы баз данных
В базах данных информация хранится, как было отмечено выше, в упорядоченном виде. В связи с этим существуют различные типы баз данных: иерархические, сетевые и табличные.
Иерархические базы данных графически представляются в виде дерева, состоящего из объектов различных уровней. На самом верхнем уровне находится один объект, на втором — объекты второго уровня и т. д.
Объекты связаны между собой, причем каждый из них может включать в себя объекты более низкого уровня. Примером иерархической базы данных является каталог папок в операционной системе Windows.
Замечание 1
Сетевую базу данных от иерархической отличает то, что в ней каждый элемент верхнего уровня может быть связан одновременно с любыми элементами следующего уровня.
Отметим, что связи между объектами в сетевых моделях не имеют никаких ограничений. Примером сетевой базы данных является Всемирная паутина глобальной сети Интернет. Миллионы документов связаны между собой при помощи гиперссылок в единую распределенную сетевую базу данных.
Табличная (реляционная) база данных представляет сбой перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.