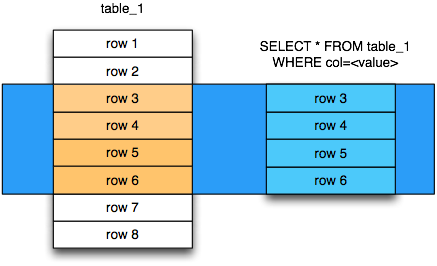
Как спроектировать базу данных, чтобы в будущем не пришлось её переписывать
Содержание:
- Введение
- Системы Управления Базами Данных
- Какими личными качествами должен обладать разработчик баз данных?
- Приведём пример
- Используйте проверочные ограничения
- 1.1 Анализ предметной области
- Правило 1: Какова природа приложения (OLTP или OLAP)?
- 2.2. Создание новой базы данных
- Установите для себя правила именования таблиц и полей
- MVCC — MultiVersion Concurrency Control
- 2.1. Основные принципы проектирования БД
- Инфологическое проектирование
- Проектирование баз данных с помощью CASE-средств
- 5 последних уроков рубрики «Разное»
- Правило 7. Тщательно выбирайте производные столбцы
- Литература
- Правило 2: Разбейте свои данные на логические части, упростите себе работу
- Основные этапы проектирования баз данных
- Правило 6: Следите за частичными зависимостями
Введение
Определение 1
База данных – это набор однотипных данных, которые организованы согласно схеме так, что их может эффективно использовать конечный пользователь.
Разработка всех программных систем, предназначенных для работы с базами данных, начинается с формирования структурной организации данных. На базе сформированной структурной организации данных разрабатываются программы, реализуются процедуры по управлению имеющимися данными. Эта очерёдность действий обусловлена тем, что удобнее отталкиваясь от структурной организации данных обратиться к логической обработке этих данных, чем выполнять операции в обратном порядке.
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле — не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Какими личными качествами должен обладать разработчик баз данных?
Говоря о личных качествах разработчика баз данных, как ни крути, первым отмечается высокий уровень ответственности и дисциплины. А если мы с вами возьмемся составлять своеобразный психологический портрет такого специалиста, то получится следующее:
- обладает техническим складом ума и аналитическим мышлением;
- очень педантичный;
- крайне пунктуальный;
- работает с множеством задач параллельно и делает это качественно;
- очень внимательный и аккуратный;
- усидчивый и терпеливый;
- хорошо коммуницирует с коллегами и клиентами, умеет, как принимать задачи, так и составлять из них ТЗ;
- постоянно повышает уровень своей квалификации.
Приведём пример
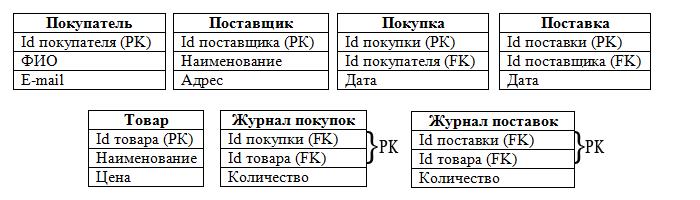
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
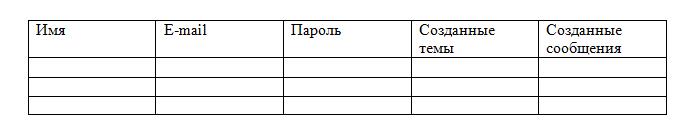
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
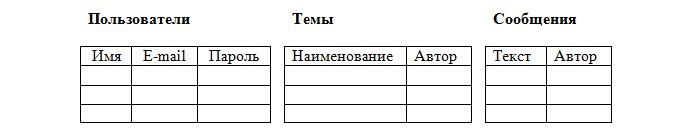
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
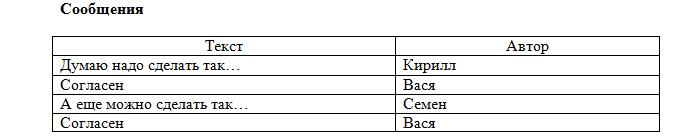
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения и внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы () или изменении родительского ключа (). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения () проверяется для полей, которые строго не должны оставаться пустыми.
Используйте , чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
1.1 Анализ предметной области
При
проектировании базы данных решаются
две основные
проблемы:
1.Отображение
объектов предметной области в абстрактные
объекты модели данных таким образом,
чтобы это отображение не противоречило
семантике предметной области, и было
по возможности лучшим (эффективным,
удобным и т.д.). Часто эту проблему
называют проблемой логического
проектирования баз данных;
2.Обеспечение
эффективного выполнения запросов к
базе данных, т.е. рациональное расположение
данных во внешней памяти, создание
полезных дополнительных структур
(например, индексов) с учетом особенностей
конкретной СУБД. Эту проблему называют
проблемой физического проектирования
баз данных.
Проблема
проектирования реляционной базы данных
состоит в обоснованном принятии решений
о том, из каких отношений (таблиц) должна
состоять БД и какие атрибуты (характеристики
и свойства) должны быть у этих отношений.
Классическим
является подход, при котором весь процесс
проектирования производится в терминах
реляционной модели данных методом
последовательных приближений к
удовлетворительному набору схем
отношений.
Исходной точкой
является представление предметной
области в виде одного или нескольких
отношений, и на каждом шаге проектирования
производится некоторый набор схем
отношений, обладающих лучшими свойствами.
Процесс проектирования представляет
собой процесс нормализации схем
отношений, причем каждая следующая
нормальная форма обладает свойствами
лучшими, чем предыдущая.
В
ходе анализа предметной области
необходимо:
-
уяснить
и указать назначение базы данных;
2.
определить
и выделить первоначальный набор сущностей
и атрибутов предметной области.
Рассмотрим пример
проектирования базы данных предметной
области «Библиотека»
Правило 1: Какова природа приложения (OLTP или OLAP)?
Когда вы начинаете разработку базы данных, первое, что нужно определить — природа приложения, которое вы разрабатываете: будет оно транзакционное или аналитическое? Многие разработчики находят применение трем нормальным формам не задумываясь о характере приложения, а затем у них возникают вопросы о том, как получить информацию о производительности и настройке. Как уже сказано выше, есть два вида приложений: основанные на транзакциях и аналитические. Давайте разберемся, что это за типы.
Транзакционный: в этом типе приложения ваш конечный пользователь больше интересуется четырьмя функциями CRUD: созданием, чтением, обновлением и удалением записей. Официальное название такой базы данных — OLTP.
Аналитический: в таких приложениях ваш конечный пользователь больше заинтересован в анализе, отчетности, прогнозировании и т. д. Эти типы баз данных имеют меньшее количество вставок и обновлений. Основная цель здесь — собрать и проанализировать данные как можно быстрее. Официальное название такой базы данных — OLAP.
Если вы считаете, что вставки, обновления и удаления будут использоваться чаще, то создайте нормализованный дизайн таблицы, или же создайте плоскую денормализованную структуру базы данных.
Ниже приведена простая диаграмма, показывающая, как имена и адрес в левой части составляют простую нормализованную таблицу. С помощью денормализованной структуры мы создали структуру плоской таблицы.
2.2. Создание новой базы данных
Для создания БД нужно выбрать в меню Файл команду Создать или нажать кнопку Создать базу данных на панели инструментов. Будет открыто диалоговое окно Создание. В этом окне следует выбрать диск и каталог для сохранения БД и ввести имя файла новой БД. Access автоматически добавит к нему расширение mdb. В этом файле хранятся данные, а также описания структуры таблиц, запросов, форм, отчетов и других объектов создаваемой БД. На экране появится окно новой «пустой» базы данных. Она постепенно заполняется содержимым по мере создания с помощью соответствующих мастеров или «вручную» нужных таблиц, а затем и других объектов.
С помощью специального мастера можно быстро создать БД определенного типа со всеми необходимыми таблицами, формами и отчетами. Для этого в окне Создание нужно щелкнуть по корешку вкладки Базы данных и выбрать из списка нужную БД.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: , , . Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе () или в единственном (). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
MVCC — MultiVersion Concurrency Control
zr1(y)yyy
Как это работает?
- Когда мы пошли исполнять транзакцию t1, имеется чтение x, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
yw2yt1xy
- В MySQL он внутри InnoDB,
- В PostgreSQL это отдельная директория, которая наконец в версии 10 стала называться WAL вместо PGX-Log;
- В Oracle это называется Redo Log;
- В DB2 — WAL.
2.1. Основные принципы проектирования БД
Создание БД должно начинаться с ее проектирования. Процесс проектирования БД включает следующие основные этапы:
1. Определение назначения БД. На первом этапе проектирования БД необходимо определить список задач, решаемых с ее помощью, и какие данные для этого нужны.
2.Определение структуры таблиц. Это один из наиболее сложных этапов в процессе создания БД. Правильная структуризация БД позволяет быстро извлечь нужные данные, исключает их дублирование и обеспечивает целостность хранящейся информации. Процедура разделения сложных данных на несколько таблиц называется нормализацией. Специалистами по проектированию БД была разработана теория нормализации БД (см. ). Она рекомендует при проектировании таблиц руководствоваться следующими основными принципами:
•Каждая из таблиц должна содержать информацию о наборе однотипных объектов, например, сведения о студентах или итоги сдачи сессии.
•Каждому из таких наборов данных должна соответствовать отдельная таблица. Например, сведения о студентах и о полученных ими оценках в сессию должны храниться в разных таблицах. Тогда при удалении сведений об оценках студента информация о нем останется в БД.
•Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Это исключает возможность несовпадения информации в разных таблицах и делает работу с БД более эффективной.
3.Определение полей. Каждая таблица содержит информацию о наборе объектов одного типа. При разработке полей для таблицы необходимо помнить следующее:
•В таблице должна присутствовать вся необходимая информация о данном наборе объектов.
Инфологическое проектирование
Идентификация сущностей составляет смысловую основу инфологического проектирования. Сущность здесь – это такой объект (абстрактный или конкретный), информация о котором будет накапливаться в системе. В инфологической модели предметной области в понятных пользователю терминах, которые не зависят от конкретной реализации БД, описывается структура и динамические свойства предметной области. Но термины, при этом берутся в типовых масштабах. То есть, описание выражается не через отдельные объекты предметной области и их взаимосвязи, а через:
- описание типов объектов,
- ограничения целостности, связанные с описанным типом,
- процессы, приводящие к эволюции предметной области – переходу её в другое состояние.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
- Функциональный подход отталкивается от поставленных задач. Функциональным он называется, потому что применяется, если известны функции и задачи лиц, которые с помощью проектируемой базы данных будут обслуживать свои информационные потребности.
- Предметный подход во главу угла ставит сведения об информации, которая будет содержаться в базе данных, при том, что структура запросов может не быть определена. В этом случае в исследованиях предметной области ориентируются на её максимально адекватное отображение в базе данных в контексте полного спектра предполагаемых информационных запросов.
- Комплексный подход по методу «сущность-связь» объединяет достоинства двух предыдущих. Метод сводится к разделению всей предметной области на локальные части, которые моделируются по отдельности, а затем вновь объединяются в цельную область.
Поскольку использование метода «сущность-связь» является комбинированным способом проектирования на данном этапе, он чаще других становится приоритетным.
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Зависимость сущностей отражается в разделении их на сильные (базовые, родительские) и слабые (дочерние). Сильная сущность (например, читатель в библиотеке) может существовать в БД сама по себе, а слабая сущность (например, абонемент этого читателя) «привязывается» к сильной и отдельно не существует.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений.При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа, бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
Проектирование баз данных с помощью CASE-средств
К ключевым понятиям проектирования баз данных относятся:
- CASE-технологии — программная основа CASE-средств, применяемая для разработки и поддержки процессов жизненных циклов ПО, используемых в моделировании данных и генерации схем баз данных. Чаще всего программные коды в CASE-технологиях пишутся на языке SQL;
- концептуальное проектирование — построение обобщенной, не имеющей конкретики, модели базы данных с описанием ее объектов и связей между ними;
- логическое проектирование — создание схемы базы данных с учетом специфики конкретной модели данных (но не конкретной СУБД). Например, для реляционной модели данных логическая схема БД будет содержать определенный набор таблиц и связей между ними;
- физическое проектирование — построение схемы базы данных под конкретную СУБД. При таком проектировании учитываются ограничения на именование объектов базы данных, ограничения на определенные типы данных, физические условия хранения данных в БД (разделение по файлам и устройствам), возможность доступа к БД.
При проектировании баз данных с помощью CASE-средств выделяются и анализируются определенные бизнес-процессы, для которых создается БД, определяются взаимосвязи их элементов, оптимизируется их инфраструктура. CASE-средства позволяют существенно сократить время на разработку БД и уменьшить количество ошибок в них.
Для создания баз данных под наиболее распространенные СУБД чаще всего используются следующие CASE-средства:
- ERwin (Logic Works) — CASE-инструмент для создания концептуальных и логических схем баз данных. Он позволяет редактировать различные наборы данных, представляя их в виде электронных таблиц, разрабатывать структуры баз данных, синхронизировать модели, скрипты и БД, настраивать шаблоны, выводить рабочую информацию в виде отчетов, строить удобные и понятные диаграммы, отображающие различные процессы в системе и взаимосвязи между ними;
- S-Designor (SDP) — графический CASE-инструмент для проектирования структуры реляционных БД. Он создает модели баз данных в два этапа — выстраивая концептуальную модель и затем преобразуя ее в физическую, причем в данном процессе разработки возможен как прямой, так и обратный переход между моделями. Данный инструмент позволяет проектировать базы данных под различные СУБД, в том числе под Oracle и MySQL;
- DataBase Designer (ORACLE) — интегрированная CASE-среда, которая позволяет анализировать предметную область создания БД, выполнять программирование и проектирование, проводить оценку и тестирование, осуществлять сопровождение, обеспечивать качество, управлять конфигурацией и проектом, разрабатывать и анализировать требования к информационной системе.

5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете над приложениями OLTP, избавление от производных столбцов было бы хорошей мыслью, если только не существует веской причины для повышения производительности. В случае работы с OLAP, где нам нужно производить много сумм и вычислений, эти поля необходимы для повышения производительности.
На приведенном выше рисунке вы можете увидеть, как среднее поле зависит от меток и объекта. Это также одна из форм избыточности. Подумайте, действительно ли нужны поля, полученные из других полей?
Это правило также выражено в 3-й нормальной форме:«Ни один столбец не должен зависеть от других столбцов непервичного ключа». Не стоит применять это правило вслепую, так как не всегда избыточные данные плохие. Если избыточные данные являются расчетными данными, проанализируйте ситуацию, а затем решите, хотите ли вы реализовать третью нормальную форму.
Литература
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4.
- Когаловский М.Р. Перспективные технологии информационных систем. — М.: ДМК Пресс; Компания АйТи, 2003. — 288 с. — ISBN 5-279-02276-4.
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: «Вильямс», 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. — М.: «Вильямс», 2003. — 1088 с. — ISBN 5-8459-0384-X.
Правило 2: Разбейте свои данные на логические части, упростите себе работу
Это правило на самом деле является первым правилом из 1-й нормальной формы. Одним из признаков нарушения этого правила является то, что ваши запросы используют слишком много функций синтаксического анализа, таких как SUBSTRING, CHARINDEX и т. д., Тогда, вероятно, это правило необходимо применять.
К примеру, ниже приведена таблица с именами учеников. Если вам понадобится запросить имена учеников,, содержащих «Koirala», но не содержащих «Harisingh», представьте, какой запрос вы получите.
Поэтому лучше было бы разбить это поле на логические части, чтобы мы могли писать чистые и оптимальные запросы.
Основные этапы проектирования баз данных
Концептуальное (инфологическое) проектирование

Пример концептуальной схемы
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные .
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование
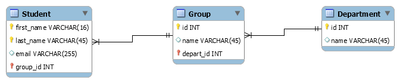
Пример логической схемы для реляционной модели данных.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.
Результатом физического проектирования логической схемы выше на языке SQL может являться следующий скрипт:
CREATE TABLE IF NOT EXISTS Department ( -- Факультет
id INT NOT NULL,
name VARCHAR(45),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS Group (
id INT NOT NULL,
name VARCHAR(45) ,
depart_id INT NOT NULL,
UNIQUE INDEX depart_id_UNIQUE (depart_id ASC),
PRIMARY KEY (id, depart_id),
CONSTRAINT depart_fk
FOREIGN KEY (depart_id)
REFERENCES Department (id)
);
CREATE TABLE IF NOT EXISTS Student (
first_name VARCHAR(16) NOT NULL,
last_name VARCHAR(45) NOT NULL,
email VARCHAR(255),
group_id INT NOT NULL,
PRIMARY KEY (last_name, first_name, group_id),
INDEX group_fk_idx (group_id ASC),
CONSTRAINT group_fk
FOREIGN KEY (group_id) REFERENCES Group (id)
);
Правило 6: Следите за частичными зависимостями
Следите за полями, которые частично зависят от первичных ключей. Например, в приведенной выше таблице мы видим, что первичный ключ создается с номером и стандартом. Теперь внимательно посмотрите на поле «Syllabus»: оно связано со стандартом, а не со студентом напрямую (roll number).
Учебный план (syllabus) связан со стандартом, по которому учится студент, а не непосредственно со студентом. Поэтому, если завтра мы хотим обновить учебный план, мы должны обновить ее для каждого учащегося, что кропотливо и нелогично. Имеет смысл перемещать эти поля и связывать их со стандартной таблицей.
Посмотрите, как мы переместили поле Syllabus и привязали его к таблице стандартов.
Это правило не что иное, как 2-я нормальная форма: «Все ключи должны зависеть от полного первичного ключа, а не частично».