Реляционная модель данных
Содержание:
- Структура реляционной модели данных
- Основные характеристики полей реляционных БД
- Примечания
- Принципы создания
- Запросы (Queries)¶
- Примеры реляционных СУБД
- Базы данных: реляционные связи между таблицами
- Шаг 1. Подготовка данных
- Фундаментальные модели
- Аксиомы Армстронга
- Хранимые процедуры
- Определение и свойства отношения
- История
- Реляционная модель
- Язык описания данных в сетевой модели
- Операции над отношениями
- Схема двумерной реляционной таблицы базы данных
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Основные характеристики полей реляционных БД
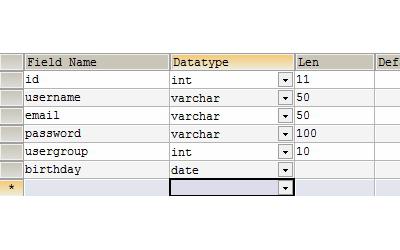
Названия полей должны быть уникальными в рамках одной сущности. Типы атрибутов или полей реляционных баз данных описывают, данные какой категории хранятся в полях сущностей. Поле реляционной базы данных должно иметь фиксированный размер, исчисляемый в символах. Параметры и формат значений атрибутов определяют манеру исправления в них данных. Еще есть такое понятие, как «маска», или «шаблон ввода». Оно предназначено для определения конфигурации ввода данных в значение атрибута. Непременно при записи неправильного типа данных в поле должно выдаваться извещение об ошибке. Также на элементы полей накладываются некоторые ограничения – условия проверки точности и безошибочности ввода данных. Существует некоторое обязательное значение атрибута, которое однозначно должно быть заполнено данными. Некоторые строки атрибутов могут быть заполнены NULL-значениями. Разрешается ввод пустых данных в атрибуты полей. Как и извещение об ошибке, есть значения, которые заполняются системой автоматически – это данные по умолчанию. Для ускорения поиска любых данных предназначено индексированное поле.
Примечания
- ↑ .
- ↑ .
- В частности, ничто не препятствует визуально представить отношение таблицей, в которой столбцы будут соответствовать не атрибутам, а кортежам, а строки — не кортежам, а атрибутам. То есть соотнесение кортежей отношения со строками таблицы, а атрибутов отношения со столбцами таблицы является лишь данью традиции, но не имеет никакой теоретической обусловленности.
- Необходимо помнить, что «таблица» чаще всего означает не «отношение» как , а визуальное представление отношения на бумаге или экране. Некорректное и нестрогое использование термина «таблица» вместо термина «отношение» нередко приводит к недопониманию. Наиболее частая ошибка состоит в рассуждениях о том, что реляционная модель данных имеет дело с «плоскими», или «двумерными» таблицами, тогда как таковыми могут быть только визуальные представления таблиц. Отношения же являются абстракциями, и не могут быть ни «плоскими», ни «неплоскими».
- С. J. Date. What First Normal Form Really Means //С. J. Date. Date on database: Writings 2000—2006, Apress, 2006, ISBN 978-1-59059-746-0
Принципы создания
Каждая таблица, которую еще называют отношением в реляционной базе СУБД, содержит один или ряд категорий данных в столбцах атрибутах. Каждая строка называется записью, или кортежем, содержит уникальный экземпляр данных или ключ для категорий, установленных столбцами. Таблица имеет уникальный первичный ключ, идентифицирующий информацию в ней. Табличная связь устанавливается с помощью внешних ключей, ссылающихся на первичные ключи иной таблицы.
Например, типичная реляционная база СУБД бизнес-заказов имеет таблицу, в которой описывается клиент, со столбцами для имени, адреса, номера телефона и другой информации. Следующая имеет заказ: продукт, клиент, дата, цена продажи и так далее. Пользователь РБД получает представление о базе данных в соответствии со своими потребностями. Например, менеджеру филиала может понравиться просмотр или отчет обо всех клиентах, которые купили товары после определенной даты. Специалист по финансовым услугам в той же компании из тех же таблиц получает отчет о счетах, которые необходимо оплатить.
Запросы (Queries)¶
Ключевой особенностью SQL является возможность построения запросов к данным. Для этого используется команда . Также как и в командах и в ней присутствует параметр WHERE.
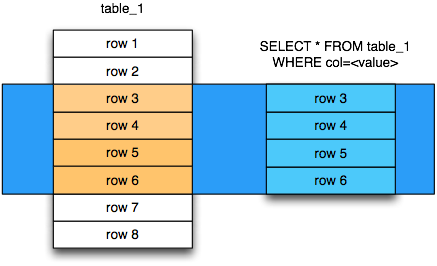
Например, можно выбрать строки у которых равен :
SELECT emp_id, emp_name FROM employee WHERE dep_id=12
Команда из примера выше имеет следующие части:
- Параметр FROM указывает таблицы, из которых выбираются строки.
- Параметр WHERE используется для фильтрации выбираемых строк по какому-либо условию.
- Между словами SELECT и FROM расположен список столбцов, которые необходимо показать из каждой отфильтрованной строки.
Результат примера может выглядеть как-то так:
| emp_id | emp_name |
|---|---|
| 1 | wally |
| 2 | dilbert |
| 5 | wendy |
Сортировка
К команде можно добавить параметр ORDER BY задающий по какому полю сортировать результаты:
SELECT emp_id, emp_name FROM employee WHERE dep_id=12 ORDER BY emp_name
| emp_id | emp_name |
|---|---|
| 2 | dilbert |
| 1 | wally |
| 5 | wendy |
Объединения (Joins)
Запросы могут использовать механизм объединений для строк из двух таблиц и представления их как одна строка. Обычно объединение производится по .
Параметр JOIN помещается внутри блока FROM, между именами объединяемых таблиц. Он, в свою очередь, в себе содержит параметр ON, который отвечает за критерий объединения строк из разных таблиц.
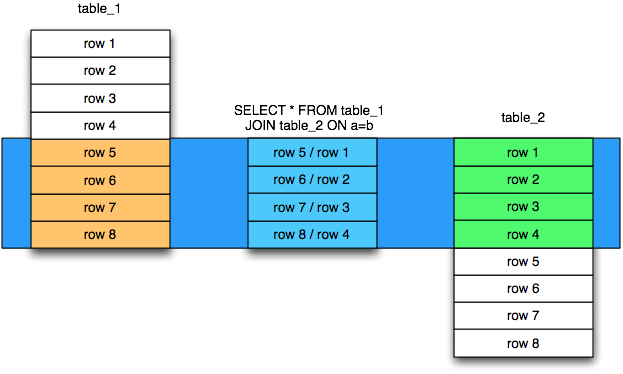
JOIN создаёт промежуточную структуру табличного вида. Она содержит в себе объединенные данные из обоих таблиц.
Используя примеры с таблицами Department и Employee, выберем сотрудников вместе с названиями их отделов:
SELECT e.emp_id, e.emp_name, d.dep_name
FROM employee AS e
JOIN department AS d
ON e.dep_id=d.dep_id
WHERE d.dep_name = 'Software Artistry'
| emp_id | emp_name | dep_name |
|---|---|---|
| 2 | dilbert | Software Artistry |
| 1 | wally | Software Artistry |
| 5 | wendy | Software Artistry |
Левое внешнее объединение (Left Outer Join)
Этот вид объединения позволяет вернуть строки из «левой» части даже в том случае, если у них нет соответствия в «правой». Например, если мы хотим выбрать отделы и их сотрудников, дополнительно, получить названия отделов без сотрудников, то необходимо использовать конструкцию LEFT OUTER JOIN:
SELECT d.dep_name, e.emp_name FROM department AS d LEFT OUTER JOIN employee AS e ON d.dep_id=e.dep_id
Допустим наша компания имеет три отдела, из которых отдел «Sales» на данный момент не имеет сотрудников. В этом случае результаты могут выглядеть следующим образом:
| dep_name | emp_name |
|---|---|
| Management | dogbert |
| Management | boss |
| Software Artistry | dilbert |
| Software Artistry | wally |
| Software Artistry | wendy |
| Sales | <NULL> |
Также существует «right outer join», который использует «правую» часть, как основную. Но использование этой конструкции считается не очень элегантным шагом.
Агрегация
Функция агрегации принимает на вход множество значений, выдавая на выходе одно. Наиболее часто используемая функция агрегации — это«count()«. Она получает набор строк и возвращает их количество.
В качестве параметра может использоваться любое SQL выражение. Наиболее часто используется шаблон , означающий «все столбцы». В отличии от большинства функций агрегации не вычисляет значение своего аргумента, а просто считает сколько раз он был вызван:
SELECT count(*) FROM employee
| count |
|---|
| 18 |
Другая функция агрегации может вернуть нам среднее количество сотрудников в офисах. Для этого нам также потребуется использовать конструкцию GROUP BY в подзапросе:
SELECT avg(emp_count) FROM
(SELECT count(*) AS emp_count
FROM employee GROUP BY dep_id) AS emp_counts
| count |
|---|
| 2 |
Примечание
Запрос в этом примере производит подсчёт только по отделам, в которых есть сотрудники. Для включения в расчёты отделы без сотрудников нужно использовать более сложный подзапрос.
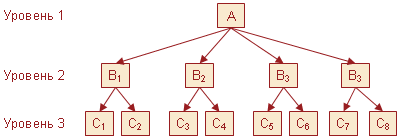
Группировка
Конструкция GROUP BY, применяемая в выражении , служит для группировки результатов по какому-либо полю. Она зачастую используется совместно с агрегацией для применения агрегирующей функции к каждой из групп.
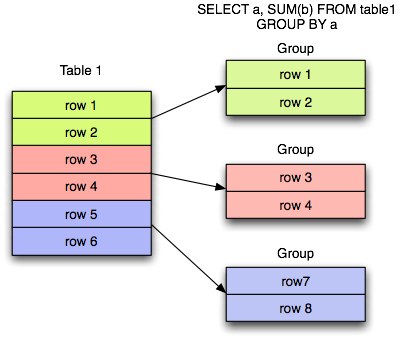
На изображении выше строки разделены на 3 подгруппы по некоему полю «a». Затем применена функция к полю «b» в каждой из этих групп.
В качестве примера совместного использования агрегации и конструкции GROUP BY рассчитаем количество сотрудников в каждом отделе:
SELECT count(*) FROM employee GROUP BY dep_id
| count | dep_id |
|---|---|
| 2 | 1 |
| 10 | 2 |
| 6 | 3 |
| 9 | 4 |
Having
Для фильтрации сгруппированных агрегированных значений применяется конструкция HAVING. Например, можно изменить вывод примера выше: отфильтровать отделы, в которых количество сотрудников больше семи:
SELECT count(*) as emp_count FROM employee GROUP BY dep_id HAVING emp_count > 7
| count | dep_id |
|---|---|
| 10 | 2 |
| 9 | 4 |
Примеры реляционных СУБД
SQLite — это популярная БД SQL с открытым исходным кодом. ПО может хранить всю БД в одном файле. Самым значительным преимуществом, которое она обеспечивает, является то, что все данные могут храниться локально без подключения к серверу. SQLite стала популярной для БД в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных гаджетах.
MySQL — еще одна популярная реляционная модель СУБД SQL с открытым исходным кодом. Обычно она применяется в веб-приложениях и часто доступна с помощью PHP. Главные преимущества ее — простота использования, ценовая доступность, надежность. Некоторые из недостатков проявляются в том, что при масштабировании она страдает от низкой производительности, разработка с применением открытого исходного кода отстает с тех пор, как Oracle установил контроль над MySQL и не включает в себя некоторые расширенные функции.
PostgreSQL — это реляционная модель данных СУБД SQL с использованием открытого исходного кода, которая не контролируется какой-либо корпорацией. Обычно ее используют для разработки веб-приложений. PostgreSQL — простая, надежная и бюджетная программа с большим сообществом разработчиков. Имеет дополнительные функции в виде поддержки внешнего ключа, не требуя сложной настройки. Главный ее недостаток — она работает медленнее, чем иные БД, такие как MySQL. Она также менее популярна, чем MySQL, что затрудняет доступ хостов или поставщиков услуг, которые предлагают управляемые экземпляры PostgreSQL.
Базы данных: реляционные связи между таблицами
Существует 2 основных вида связей реляционных табличек:
«Один-многие». Возникает при соответствии одной ключевой записи таблицы №1 нескольким экземплярам второй сущности. Значок ключа на одном из концов проведенной линии говорит о том, что сущность находится на стороне «один», второй конец линии зачастую отмечают символом бесконечности.
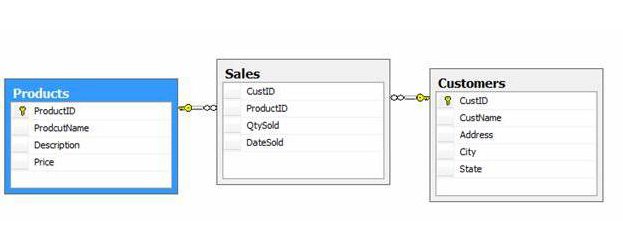
- Связь «много-много» образуется в случае возникновения между несколькими строками одной сущности явного логичного взаимодействия с рядом записей другой таблицы.
- Если между двумя сущностями возникает конкатенация «один к одному», это значит, что ключевой идентификатор одной таблицы присутствует в другой сущности, тогда следует убрать одну из таблиц, она лишняя. Но иногда исключительно в целях безопасности программисты преднамеренно разделяют две сущности. Поэтому гипотетически связь «один к одному» может существовать.
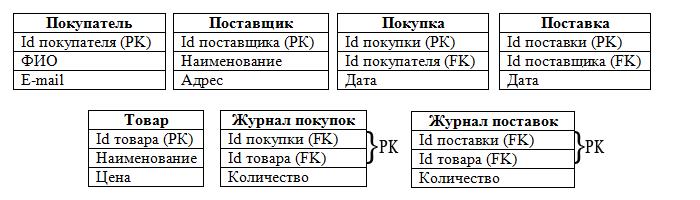
Шаг 1. Подготовка данных
Для того чтобы нам было с чем работать, я набрал в твиттере запрос “#databases” и сформировал таблицу из 10 записей:
Таблица 1
| full_name | username | text | created_at | following_username |
|---|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 | Scootmedia, MetiersInternet |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 | klout, zillow |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 | DayJobDoc, byosko |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 | CindyCrawford, Arjantim |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 | MichaelDell, Yahoo |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 | MichaelDell, Yahoo |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 | RealSkipBayless, stephenasmith |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 | RealSkipBayless, stephenasmith |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 | dellock6, rohitkilam |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 | drsql, steam_games |
В первую очередь, давайте разберёмся с колонками:
- full_name: имя пользователя
- username: логин в Twitter-е
- text: текст твита
- created_at: время создания твита
- following_username: список пользователей, разделённых запятыми, которые подписались на этот твитт. Для краткости я сократил этот список до 2 имён.
Это реальные данные. Если хотите, вы можете их найти и обновить.
Хорошо. Теперь все наши данные находятся в одном месте. Даёт ли это нам возможность легко осуществить поиск по ним? Не совсем. Данная таблица далека от идеала. Во-первых, в некоторых столбцах у нас есть повторяющиеся записи: к примеру, в х “username” и “following_username”. Также колонка “following_username” нарушает правила реляционных моделей, т.к. её в ячейках присутствует более 1 значения (записи разделены запятыми).
К тому же у нас попадаются дубликаты и в строках.
Повторяющиеся данные действительно являются проблемой, т.к. они затрудняют процесс CRUD. К примеру, при поиске по данной таблице на обработку дубликатов будет уходить дополнительное время. К тому же, если пользователь обновит твитт, то нам нужно будет перезаписать все дубликаты.
Решение данной проблемы заключается в разделении Таблицы 1 на несколько таблиц. Давайте примемся за решение первой проблемы, а именно — устранение дубликатов в столбцах.
Фундаментальные модели
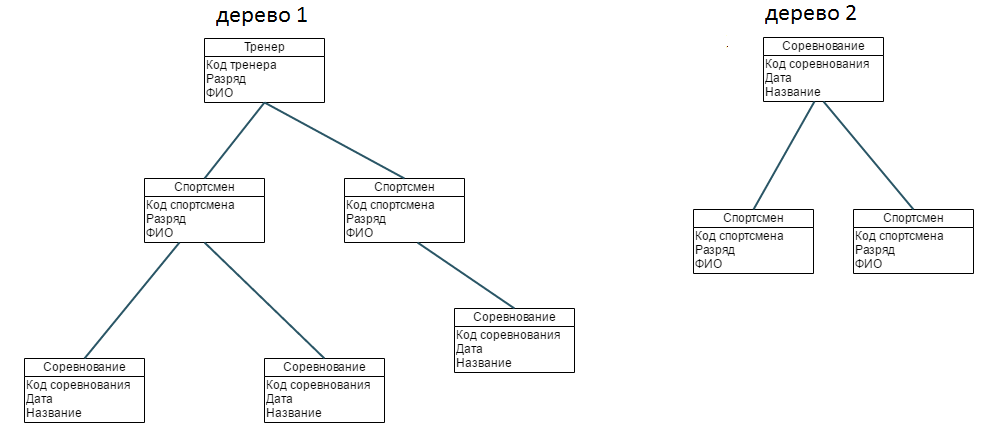
Возвращаясь к возникновению баз данных, стоит сказать, что этот процесс был достаточно сложным, он берет свое начало вместе с развитием программируемого оборудования обработки информации. Поэтому неудивительно, что количество их моделей на данный момент достигает более 50, но основными из них считаются иерархическая, реляционная и сетевая, которые и до сих пор широко применяются на практике. Что же они собой представляют?
Иерархическая база данных имеет древовидную структуру и составляется из данных разных уровней, между которыми существуют связи. Сетевая модель БД представляет собой более сложный шаблон. Ее структура напоминает иерархическую, а схема расширенная и усовершенствованная. Разница между ними в том, что потомственные данные иерархической модели могут иметь связь только с одним предком, а у сетевой их может быть несколько. Структура реляционной базы данных гораздо сложнее. Поэтому ее следует разобрать более подробно.
Аксиомы Армстронга
Существуют правила вывода новых ФЗ из существующих, называемые аксиомами Армстронга.
- Аксиомы Армстронга
-
- Правило рефлексивности: если \(B \subset A\), то \(A\rightarrow B\)
- Правило дополнения: если \(A\rightarrow B\), то \(AC\rightarrow BC\)
- Правило транзитивности: если \(A\rightarrow B\) и \(B\rightarrow C\), то \(A\rightarrow C\)
Из этих аксиом так же могут быть выведены следующие дополнительные правила:
- Правило самоопределения: \(A\rightarrow A\)
- Правило декомпозиции: Если \(A\rightarrow BC\), то \(A\rightarrow B\) и \(A\rightarrow C\)
- Правило объединения: Если \(A\rightarrow B\) и \(A\rightarrow C\), то \(A\rightarrow BC\)
- Правило композиции: Если \(A\rightarrow B\) и \(C\rightarrow D\), то \(AC\rightarrow BD\)
Можно заметить, что, вследствие правила рефлексивности, любое множество атрибутов \(A\) подразумевает ФЗ вида \(A\to A\). Такие ФЗ, а так же следующие из них, не представляют интереса, и называются тривиальными.
- Тривиальная функиональная зависимость
- ФЗ \(A \to B\), такая, что \(B \subset A\).
В принципе, этих правил достаточно для того, чтобы найти все ФЗ, следующие из данных. В связи с этим вводится понятие замыкания множества ФЗ.
- Замыкание множества ФЗ
- Замыканием множества ФЗ называется такое множество ФЗ, которое включает все ФЗ исходного множества, а так же все подразумеваемые ими. Другими словами, для отношения \(R\), обладающего функциональными зависимостями \(S\), замыканием \(S^+\) называется множество всех ФЗ, возможных для \(R\), исходя из \(S\).
Как правило, требуется установить, будет ли некая ФЗ \(X\rightarrow Y\) следовать из данного множества ФЗ \(S\). Оказывается, это возможно тогда и только тогда, когда множество атрибутов \(Y\) является подмножеством замыкания атрибутов \(X^+\) в \(S\).
- Замыкание атрибутов
- Замыканием \(X^+\) атрибутов \(X\) по множеству ФЗ \(S\) называется множество всех атрибутов, которые функционально зависят от какого-либо подмножества \(X\).
Для вычисления замыкания множества атрибутов \(X^+\) по множеству ФЗ \(S\) существует следующее правило: для каждой ФЗ \(A\rightarrow B\) в \(S\), если \(A \subset X^+\), то и \(B \subset X^+\), причем достаточно начать с предположения, что \(X^+ = X\).
Следует заметить, что для любого замыкания \(X^+\), существуют ФЗ вида \(X \to B\), где \(B \subset X^+\), таким образом, замыкания всех атрибутов отношения по его ФЗ описывают замыкание ФЗ этого отношения.
Это правило используется для вычисления неприводимого множества ФЗ, эквивалентного данному (в смысле эквивалентности их замыканий). Уменьшение количества ФЗ при сохранении замыкания (и, следовательно, внутренней логики, описываемой ФЗ) является важным шагом в проектировании БД.
Множество ФЗ называется неприводимым, если:
- Правая часть каждой ФЗ содержит только один элемент
- Ни один атрибут ни одной левой части ФЗ множества не может быть удален без изменения замыкания
- Ни одна ФЗ множества не может быть удалена без изменения замыкания.
Для любого множества ФЗ существует хотя бы одно эквивалентное неприводимое множество. Такое множество называется минимальным покрытием.
Хранимые процедуры
Большая часть программирования в РСУБД выполняется с использованием хранимых процедур (SP). Часто процедуры могут использоваться для значительного уменьшения объема информации, передаваемой внутри и вне системы. Для повышения безопасности проект системы может предоставлять доступ только к хранимым процедурам, а не напрямую к таблицам. Фундаментальные хранимые процедуры содержат логику, необходимую для вставки новых и обновления существующих данных. Могут быть написаны более сложные процедуры для реализации дополнительных правил и логики, связанных с обработкой или выбором данных.
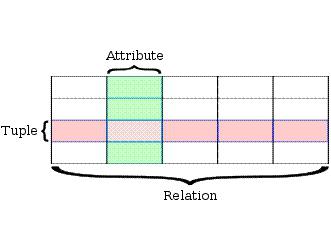
Определение и свойства отношения
Пусть дана совокупность типов данных T1, T2, …, Tn, называемых также доменами, не обязательно различных. Тогда n-арным отношением R, или отношением R степени n называют подмножество декартовa произведения множеств T1, T2, …, Tn.
Отношение R состоит из заголовка (схемы) и тела. Заголовок представляет собой множество атрибутов (именованных вхождений домена в заголовок отношения), а тело — множество кортежей, соответствующих заголовку. Более строго:
- Заголовок (или схема) H отношения R — конечное множество упорядоченных пар вида (Ai, Ti), где Ai — имя атрибута, а Ti — имя типа (домена), i=1,…, n. По определению требуется, чтобы все имена атрибутов в заголовке отношения были различными (уникальными).
- Тело B отношения R — множество кортежей t. Кортеж t, соответствующий заголовку H, — множество упорядоченных триплетов (троек) вида <Ai, Ti, vi>, по одному такому триплету для каждого атрибута в H, где vi — допустимое значение типа (домена) Ti. Так как имена атрибутов уникальны, то указание домена в кортеже обычно излишне. Поэтому кортеж t, соответствующий заголовку H, нередко определяют как множество пар (Ai, vi).
Количество кортежей называют кардинальным числом отношения (кардинальностью), или мощностью отношения.
Количество атрибутов называют степенью, или «арностью» отношения; отношение с одним атрибутом называется унарным, с двумя — бинарным и т.д., с n атрибутами — n-арным. С точки зрения теории вполне корректным является и отношение с нулевым количеством атрибутов, которое либо не содержит кортежей, либо содержит единственный кортеж без компонент (пустой кортеж).
Основные свойства отношения:
- В отношении нет двух одинаковых элементов (кортежей).
- Порядок кортежей в отношении не определён.
- Порядок атрибутов в заголовке отношения не определён.
Подмножество атрибутов отношения, удовлетворяющее требованиям уникальности и минимальности (несократимости), называется потенциальным ключом. Поскольку все кортежи в отношении по определению уникальны, в любом отношении должен существовать по крайней мере один потенциальный ключ.
История
Системы управления объектно-реляционными базами данных выросли из исследований, проведенных в начале 1990-х годов. Это исследование расширило существующие концепции реляционных баз данных, добавив концепции объектов . Исследователи стремились сохранить декларативный язык запросов, основанный на исчислении предикатов, в качестве центрального компонента архитектуры. Вероятно, самый известный исследовательский проект, Postgres (Калифорнийский университет в Беркли), породил два продукта, восходящих к этому исследованию: Illustra и PostgreSQL .
В середине 1990-х появились первые коммерческие продукты. К ним относятся Illustra (Illustra Information Systems, приобретенная , которая, в свою очередь, была приобретена IBM ), Omniscience (Omniscience Corporation, приобретенная Oracle Corporation и ставшая первоначальным Oracle Lite) и UniSQL (UniSQL, Inc., приобретенная KCOMS). ). Украинский разработчик Руслан Засухин, основатель Paradigma Software, Inc. , разработал и выпустил первую версию базы данных Valentina в середине 1990-х годов в виде C ++ SDK . К следующему десятилетию PostgreSQL стала коммерчески жизнеспособной базой данных и является основой для нескольких текущих продуктов, поддерживающих ее функции ORDBMS.
Ученые-компьютерщики стали называть эти продукты «системами управления объектно-реляционными базами данных» или СУБД.
Многие идеи ранних работ по объектно-реляционным базам данных в значительной степени вошли в SQL: 1999 через структурированные типы . Фактически, любой продукт, который соответствует объектно-ориентированным аспектам SQL: 1999, может быть описан как продукт для управления объектно-реляционными базами данных. Например, IBM DB2 , база данных Oracle и Microsoft SQL Server заявляют о поддержке этой технологии и делают это с разной степенью успеха.
Реляционная модель
У реляционной модели есть несколько ограничений. Одним из главных является ограниченность в возможностях представления сущностей реального мира, которые имеют гораздо более сложный вид, чем тот, в котором их можно представить с помощью кортежей и отношений. Еще более слабой эта модель является в том, что касается различения разных видов отношений между сущностями. Представлять сложные данные и манипулировать ими в традиционных реляционных базах данных не возможно: набор операций, которые можно выполнять в реляционных моделях, не подходит для многих реальных приложений, в состав которых входят объекты с нечисловыми атрибутами.
Ограничения традиционной реляционной модели при моделировании нескольких сущностей реального мира привели к изучению семантических моделей данных и так называемых расширенных реляционных моделей данных. За право считаться следующим поколением реляционной модели сейчас соревнуются две модели: объектно-ориентированная и объектно-реляционная. Базы данных, разрабатываемые на основе первой, называются объектно-ориентированными системами управления базами данных (ООСУБД; Object-Oriented Database Management Systems — OODBMS), а базы данных,разрабатываемые на основе второй, соответственно — объектно-реляционными системами управления базами данных.
Язык описания данных в сетевой модели
Язык описания
данных в сетевой модели имеет несколько разделов:
- описание базы данных
— области размещения; - описания записей —
элементов и агрегатов (каждого в отдельности); - описания наборов (каждого
в отдельности).
SCHEMA IS <Имя
БД>.
AREA NAME IS
<Имя физической области>.
RECORD NAME
IS <Имя записи (уникапьное)>
Для каждой
записи определяется способ размещения экземпляров записи данного типа:
LOCATION MODE
IS'{DIRECT (напрямую)
CALC <Имя
программы> USING <
DUPLICATE ARE
ALLOWED
VIA <Имя
на6ора> SET (рядом с записями владельца)
SYSTEM (решать
будет система)}
Каждый тип
записи должен быть приписан к некоторой физической области размещения:
WITHIN <Имя
области размещения> AREA
После описания
записи в целом идет описание внутренней структуры:
<Имя уровня>
<Имя данного> <Шаблон> <Тип>
Номер уровня
определяет уровень вложенности при описании элементов и агрегатов данных. Первый
уровень — сама запись. Поэтому элементы или агрегаты данных имеют уровень начиная
со второго. Если данное соответствует агрегату, то любая его составляющая добавляет
один уровень вложенности.
Если агрегат
является вектором, то он описывается как <Номер уровня> <Имя агрегата>.<Номер
уровня> <Имя 1-й сост.> а если — повторяющейся группой, то следующим
образом:
<Номер уровня>
<Имя агрегата>.OCCURS <N> TIMES
где N — среднее
количество элементов в группе.
Описание
набора и порядка включения членов в него выглядит следующим образом:
SET NAME IS
<Имя набора>:
OWNER IS (<Имя
владельца> SYSTEM).
Далее указывается
порядок включения новых экземпляров члена данного набора в экземпляр набора:
ORDER PERMANENT
INSERTION IS {SORTED | NEXT | PREV | LAST FIRST}
После этого
описывается член набора с указанием способа включения и способа исключения экземпляра
— члена набора из экземпляра набора.
MEMBER IS <Имя
члена набора> {AUTOMATIC | MANUAL} {MANDATORY OPTIONAL} KEY IS (ACCENDING
| DESCENDING) <Имя элемента данных>
При автоматическом
включении каждый новый; экземпляр члена набора автоматически попадает в текущий
экземпляр набора в соответствии с заданным ранее Порядком включения. При ручном
способе экземпляр члена набора сначала попадает в БД, а только потом командой
CONNECT может быть включен в конкретный экземпляр набора.
Если задан
способ исключения MANDATORY, то экземпляр записи, исключаемый из набора, автоматически
исключается и из базы данных. Иначе просто разрываются связи.
Внешняя
модель при сетевой организации данных поддерживается путем описания части
общего связного графа.
Операции над отношениями
См. также: реляционная алгебра, реляционное исчисление.
Любая операция, результатом которой является отношение, подпадает под понятие реляционной операции и может использоваться в реляционной теории и практике. Ниже приведён список из восьми операций, изначально предложенных создателем реляционной модели Эдгаром Коддом. Все операции из списка, кроме деления, по-прежнему широко востребованы, однако список не является исчерпывающим, то есть по факту используется гораздо большее число реляционных операций.
- Объединение — тело отношения-результата является объединением тел отношений-операндов; схема не изменяется.
- Пересечение — тело отношения-результата является пересечением тел отношений-операндов; схема не изменяется.
- Вычитание — тело отношения-результата получено вычитанием тел отношений-операндов; схема не изменяется.
- Проекция — схема отношения-результата является подмножеством схемы отношения-операнда; тело отношения-результата является нестрогим подмножеством тела отношения-операнда вследствие возможного удаления кортежей-дубликатов.
- Декартово произведение — тело отношения-результата является декартовым произведением тел отношений-операндов; схема результата является конкатенацией схем операндов.
- Выборка — тело отношения-результата является подмножеством тела отношения-операнда: отбираются лишь те кортежи, которые удовлетворяют заданному предикату (условию выборки); схема не изменяется.
- Соединение — выборка над декартовым произведением.
- Деление — делитель является унарным отношением, частное — совпадающие части кортежей делимого, перед которыми стоит делитель.
Схема двумерной реляционной таблицы базы данных
| Название атрибута 1 | Название атрибута 2 | Название атрибута 3 | Название атрибута 4 | Название атрибута 5 |
| Элемент_1_1 | Элемент_1_2 | Элемент_1_3 | Элемент_1_4 | Элемент_1_5 |
| Элемент_2_1 | Элемент_2_2 | Элемент_2_3 | Элемент_2_4 | Элемент_2_5 |
| Элемент_3_1 | Элемент_3_2 | Элемент_3_3 | Элемент_3_4 | Элемент_3_5 |
Для детального понимания системы управления модели с помощью SQL лучше всего рассмотреть схему на примере. Нам уже известно, что представляет собой реляционная БД. Запись в каждой таблице – это один элемент данных. Чтобы предотвратить избыточность данных, необходимо провести операции нормализации.