Основы правил проектирования базы данных
Содержание:
Виды баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных», по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных
Примеры:
- Иерархическая
- Объектная и объектно-ориентированная
- Объектно-реляционная
- Реляционная
- Сетевая
- Функциональная.
Классификация по среде постоянного хранения
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.В оперативную память СУБД помещает лишь кэш и данные для текущей обработки.
- В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Примеры:
- Географическая
- Историческая
- Научная
- Мультимедийная
- Клиентская.
Классификация по степени распределённости
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
-
Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Главное о базах данных
- Чаще всего базы данных напоминают таблицы: в них одному параметру соответствует один набор данных. Например, один клиент — одно имя, один телефон, один адрес.
- Такие «табличные» базы данных называются реляционными.
- Чтобы строить сложные связи, разные таблицы в реляционных базах можно связывать между собой: ставить ссылки.
- Реляционная база — не единственный способ хранения данных. Есть ситуации, когда нам нужна большая гибкость в хранении.
- Бывают сетевые базы данных: когда нужно хранить много связей между множеством объектов. Например, каталог фильмов: в одном фильме может участвовать много человек, а каждый из них может участвовать во множестве фильмов.
- Бывают иерархические базы, или «деревья». Пример — наша файловая система.
- Какую выбрать базу — зависит от задачи. Одна база не лучше другой, но они могут быть более или менее подходящими для определённых задач.
Текст и иллюстрации:Миша Полянин
Редактор:Максим Ильяхов
Корректор:Ира Михеева
Иллюстратор:Даня Берковский
Вёрстка:Маша Дронова
Доставка:Олег Вешкурцев
Что-то делает руками:Паша Федоров
Во славу:Практикума
Особенности реляционных БД
Определение 1
Реляционные базы данных (РБД) представляют собой совокупности связанных посредством ключевых полей таблиц, данные в которых хранятся в виде разбитых на поля записей-строк. Набор полей в каждой строке таблицы одинаков. Данные из таблиц извлекаются с помощью запросов на языке SQL, в который заложены возможности фильтрации, сортировки и группировки данных.
Наиболее популярные современные реализации РБД:
- Oracle Database;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- DB2.
Достоинства РБД:
- зрелость кодовой базы;
- наличие обширной документации;
- принятие сообществом разработчиков стандартов SQL как давней и неоспоримой традиции;
- большое количество специалистов по РБД на рынке труда;
- все они соответствуют принципу ACID (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, — Долговечность).
Недостатки РБД:
- не приспособлены для работы с нерегулярными (отличающимися от табличных) структурами;
- плохая совместимость между различными реализациями РДБ (например, данные, хранящиеся в формате MySQL невозможно обрабатывать средствами PostgreSQL без дополнительной конвертации);
- высокие затраты на проектирование баз данных (создание таблиц и установление взаимосвязей между ними), что особенно ощущается в простых проектах;
- необходимость разворачивать и настраивать ПО (сервер БД), требующее предварительной настройки и определенной производительности компьютера (подчас довольно высокой).
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:

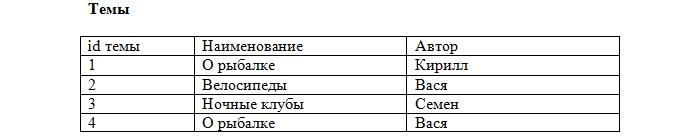
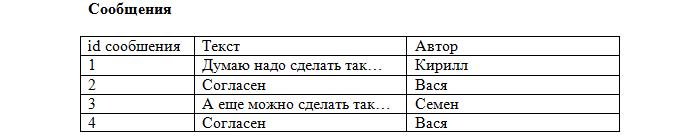
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.

Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
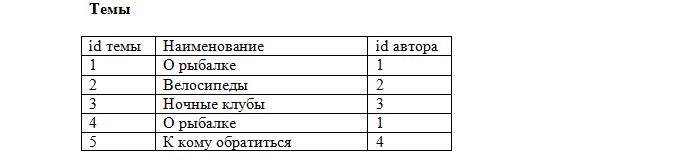

Итак, наша база данных фактически готова. Схематично она выглядит так:
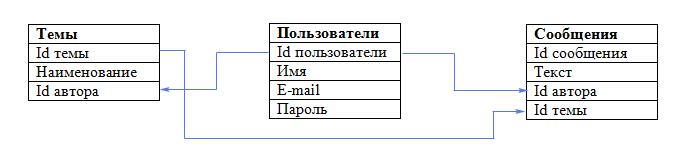
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
Классификация СУБД
По модели данных
По типу управляемой базы данных СУБД разделяются на:
§ Иерархические (система FAT, Серверы каталогов)
§ Сетевые (интернет)
§ Реляционные (MS Access)
§ Объектно-реляционные ( Oracle Database, Microsoft SQL Server 2005, PostgreSQL)
По архитектуре организации хранения данных
§ локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
§ распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах)
По способу доступа к БД
§ Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
На данный момент файл-серверные СУБД считаются устаревшими.
Примеры: Microsoft Access (Microsoft Access — реляционная СУБД корпорации Microsoft. Имеет широкий спектр функций, включая связанные запросы, сортировку по разным полям, связь с внешними таблицами и базами данных. Благодаря встроенному языку VBA, в самом Access можно писать приложения, работающие с базами данных. Основные компоненты MS Access:просмотр таблиц; построитель экранных форм; построитель SQL-запросов (язык SQL в MS Access не соответствует стандарту ANSI); построитель отчётов, выводимых на печать.), Borland Paradox.
§ Клиент-серверные
Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Примеры: Firebird, Interbase, MS SQL Server, Sybase, Oracle, PostgreSQL, MySQL, ЛИНТЕР.
§ Встраиваемые
Примеры: OpenEdge, SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL, Sav Zigzag, Microsoft SQL Server Compact, ЛИНТЕР.
6. Виды нормализации (1-3-нормальная форма).
Нормальная форма(НФ) — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение.
Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации.
Устранение избыточности производится, как правило, за счёт отношений таким образом, чтобы в каждом отношении хранились только первичные факты (то есть факты, не выводимые из других хранимых фактов).
Всего в реляционной теории насчитывается 6 НФ:
1. 1-я НФ (обычно обозначается также 1НФ).
2. 2НФ.
3. 3НФ.
4. НФ Бойса-Кодда (НФБК).
5. 4НФ.
6. 5НФ.
1НФ
Таблица находится в первой нормальной форме, если каждый её атрибут атомарен. Под выражением «атрибут атомарен» понимается, что атрибут может содержать только одно значение. Таким образом, не существует 1NF таблицы, в полях которых могут храниться списки значений. Для приведения таблицы к 1NF обычно требуется разбить таблицу на несколько отдельных таблиц.
Замечание: в реляционной модели отношение всегда находится в 1 (или более высокой) нормальной форме в том смысле, что иные отношения не рассматриваются в реляционной модели. То есть само определение понятия отношение заведомо подразумевает наличие 1NF.
Справочная информация
ДокументыЗаконыИзвещенияУтверждения документовДоговораЗапросы предложенийТехнические заданияПланы развитияДокументоведениеАналитикаМероприятияКонкурсыИтогиАдминистрации городовПриказыКонтрактыВыполнение работПротоколы рассмотрения заявокАукционыПроектыПротоколыБюджетные организацииМуниципалитетыРайоныОбразованияПрограммыОтчетыпо упоминаниямДокументная базаЦенные бумагиПоложенияФинансовые документыПостановленияРубрикатор по темамФинансыгорода Российской Федерациирегионыпо точным датамРегламентыТерминыНаучная терминологияФинансоваяЭкономическаяВремяДаты2015 год2016 годДокументы в финансовой сферев инвестиционной
Базы данных NoSQL
Класс NoSQL (нереляционных) баз данных достаточно широк. Их объединяет отсутствие необходимости структурировать данные в виде таблиц, но варианты реализации этой задачи используются разные.
Концепция NoSQL хорошо проявляет себя там, где нужно учитывать плохо структурированные данные. В качестве примера можно привести учет почтовых отправлений, среди которых встречаются разнородные объекты: письма, газеты, бандероли, посылки, открытки. При реализации такой задачи в реляционной среде данных пришлось бы на каждый вид отправления заводить по отдельной таблице, что не всегда оправдано. В NoSQL можно ограничиться самыми общими признаками для формирования ключей, а алгоритмы обработки специфических признаков хранить в форме записей произвольной формы, анализ которых можно вообще за рамки БД (в компьютерный код, написанный на обычном языке программирования).
Типы NoSQL баз данных.
Базы данных NoSQL можно разделить на несколько категорий. При этом некоторые из них подпадают более чем под одну категорию.
- БД типа ключ-значение (Redis, Amazon DynamoDB). В них значения хранятся в связи с уникальным ключом, с помощью которого запись можно легко запросить и извлечь. Такой подход существенно облегчает разворачивание таких баз данных и управление ими. Кроме того, архитектура «ключ-значение» способствует скорости высокой работы приложений.
- Концепция «широких колонок» (примеры реализации — Cassandra, Scylla, HBase) представляет собой способ хранения, сходный с РБД (имеются таблицы, колонки), но без строгой типизации. Каждая запись в такой базе может представлять собой многомерный массив. Это позволяет хранить объемы информации, измеряющиеся в
петабайтах (тысячах терабайт) и при этом обеспечивать приемлемую скорость доступа к записям, что затруднительно или недостижимо для обычных РДБ. Для баз данных с «широкими колонками» разработан язык запросов, аналогичный SQL (CQL). - Документоориентированные БД (MongoDB, Couchbase) хранят данные в формате JSON, который разработан для описания объектов. К этой же категории можно отнести СУБД Elasticsearch, Splunk и Solr, которые дополнительно оснащены эффективными механизмами поиска.
- Графообразные БД (Neo4J, Datastax Enterprise Graph) представляют данные в форме сетей, где узлы могут быть связаны между собой. Такие базы данных удобны для хранения объектов, которые должны быть представлены и визуализированы как математические графы. На формат данных, хранящихся в узлах графов, не накладывается ограничений, за ними лишь закреплены метки. Такой подход делает графообразные ДБ удобным инструментом для анализа гетерогенных сред. Например, они используются для предотвращения мошенничеств в сети Facebook.
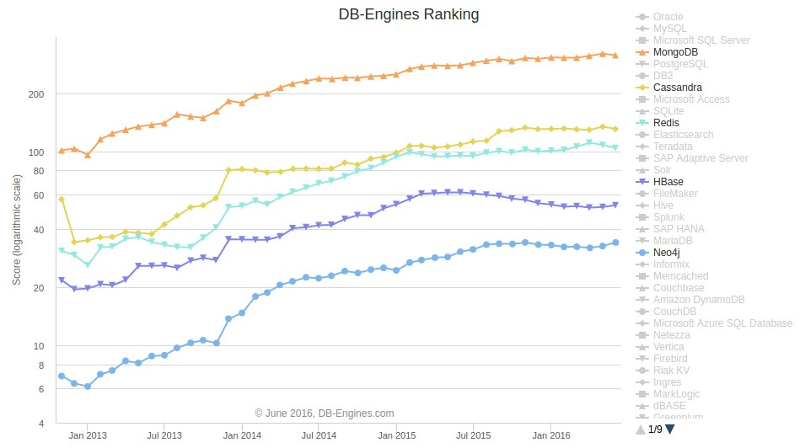 Рисунок 3. Востребованность NoSQL баз данных. Автор24 — интернет-биржа студенческих работ
Рисунок 3. Востребованность NoSQL баз данных. Автор24 — интернет-биржа студенческих работ
Преимущества NoSQL:
- отсутствие жестких схем данных, характерных для РДБ;
- легкость масштабирования (расширения объемов хранимой информации);
- возможность быстрой синхронизации между узлами при работе в составе кластера.
Недостатки NoSQL:
- отсутствие достаточного количества специалистов для обслуживания таких БД;
- слишком сильные различия в форматах хранения, делающие затруднительным переход с одной базы данных на другую.
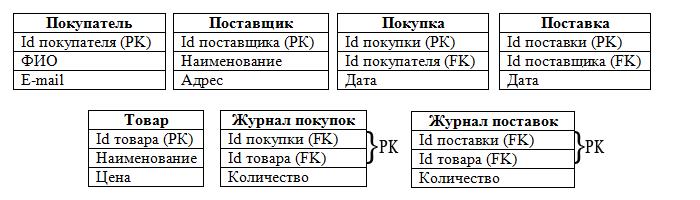
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
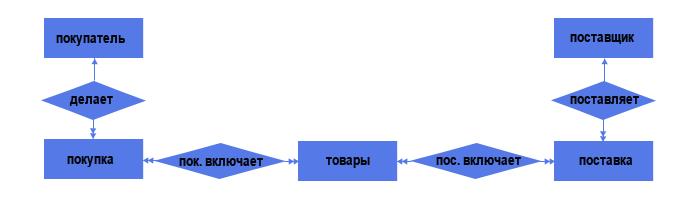
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Иерархическая модель данных
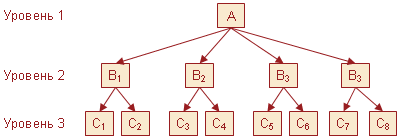
Иерархические, или древовидные, структуры данных разработаны и используются достаточно давно. Например, большинство методов индексирования базируются именно на древовидных структурах данных. Иерархическая модель данных близка по своей идее к иерархическойструктуре данных. Но модель описывает не конкретные методы работы и манипулирования ссылками, аспособ логического представления данных, то, какими терминами оперирует проектировщик структуры базы данных, когда отражает реальные зависимости с помощью имеющихся в СУБД механизмов.
Иерархическая модель позволяет строить иерархию элементов. То есть у каждого элемента может быть несколько “наследников” и существует один “родитель”. Для каждого уровня связи вводится интерпретация, зависящая от предметной области и описывающая взаимоотношение между “родителями” и “наследниками”. Каждый элемент представляется с помощью записи. Структура данных, обычно используемая для представления этой записи об элементе, обычно содержит некоторые атрибуты, характеристики каждого элемента.
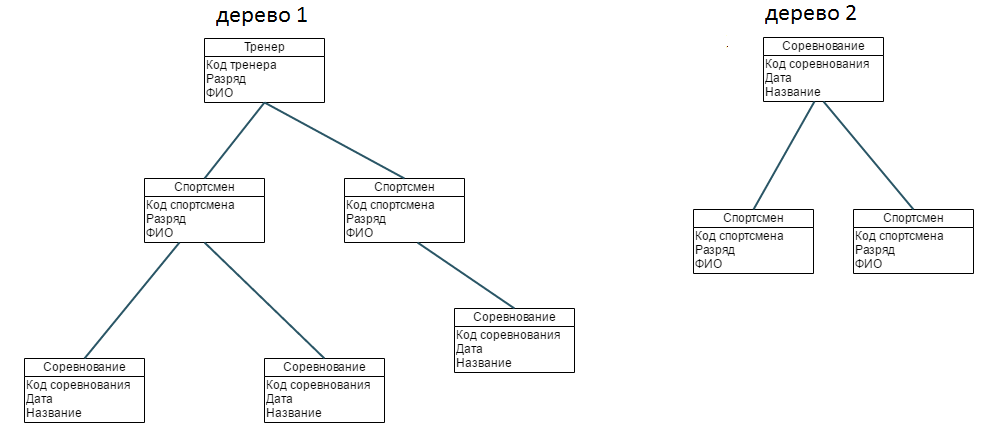
Попробуем представить себе базуданных для описания тематических сборников по некоторой теме. Прежде всего, выделим уровни иерархии.
Первый уровень — это издательства. Каждое издательство характеризуется своим названием, юридическим адресом, номером счета в банке.
Каждое издательство выпускает несколько сборников. То есть издательство является “родителем” для сборника и связано со сборником соотношением “издает” (“публикует”, “печатает” и т.д.). Для каждого сборника появляются такие атрибуты, как размер, периодичность, цена, ответственный редактор, корректор и т.д.
В каждом сборнике есть несколькостатей (хотя бы, одна). То есть сборник и статья связаны соотношением “включает”. Далее, у каждой статьи естьназвание, авторы.
Авторы представляются отдельным элементом и образуют следующий уровень иерархии. Каждый автор характеризуется фамилией, именем, отчеством, гонораром и т.д. Статьи связаны с автором соотношением “написаны”.
Графическое представление этого примера приведено наРис.2.2. Элементы нарисованы прямоугольниками, их названия даны обычным шрифтом. Связи нарисованы стрелками и их названия даны курсивом, атрибуты для каждого элемента на этой схеме не показаныони являются частью элемента данных.
Издательство
выпускает
Сборник
содерж ит
Статья
написана
Автор
Рис.2.2. Графическое представление иерархической модели данных (справа пример какой-то конкретной базы
данных)
Достоинства иерархических СУБД: возможность реализовать быстрый поиск нужных значений, когда условия запроса соответствуют иерархии в схеме базе данных.
Недостатки иерархических СУБД: например, если запрос не соответствует имеющейся иерархии, то и его программирование, и его исполнение, потребуют значительных усилий. Например, попытки реализовать запрос типа“в
Основные типы данных СУБД
Изначально применение СУБД ограничивалось преимущественно решением финансово-экономических задач.
Независимо от модели представления, базы данных обрабатывали такие основные типы данных:
- числовые – наиболее используемыми являются целочисленные, вещественные и денежные (финансовые);
- символьные, например, значения данных «четверг», «столбец», «менеджер»;
- логические, которые принимают значения «истина» или «ложь»;
- даты, которые задаются с помощью типа «Дата» или в виде обычных символьных данных.
В разных СУБД эти типы несущественно отличались названиями, диапазоном значений и видом представления. С развитием информационных технологий разрабатывались специализированные системы обработки данных (системы обработки видеоизображений, геоинформационные системы и т.д.), что привело к введению в СУБД их разработчиками поддержки новых типов данных.
К таким типам данных относились:
- время и дата/время, которые были предназначены для хранения информации о времени и/или дате;
- символьные переменной длины, которые хранили текстовую информацию большой длины (например, документ);
- двоичные для хранения графических, аудио- и видеообъектов, хронологической, пространственной и другой специальной информации. Такие данные часто называются мультимедиа-данными. Например, в MS Access тип данных «Поле объекта OLE» позволяет хранить в базе данных графические данные в формате BMP и отображать их автоматически при работе с базой;
- гиперссылки, которые предназначены для хранения ссылок на разные ресурсы (документы, файлы, узлы и т. д.), не принадлежащие базе данных, например, находящиеся в сети Интернет, корпоративной сети Интранет или на жестком диске персонального компьютера;
- данные в формате XML.
Преимущества и недостатки
Надлежащие системы управления базами данных помогают получить лучший доступ к данным, а также оптимизировать управление ими. В свою очередь, точечный доступ помогает конечным пользователям быстро и эффективно обмениваться данными в рамках выполнения задач организации.
|
Модель базы данных |
Год создания |
Преимущества |
Недостатки |
|
Иерархическая |
1960-й |
Очень быстрый доступ для чтения, четкая структура, технически простой. |
Исправлена структура в дереве, которая не допускает связи между деревьями. |
|
Сетевая |
Начало 1970-х |
Поддерживает несколько способов доступа к записи, без строгой иерархии. |
Плохой обзор с большими базами данных. |
|
Реляционная |
1970-й |
Простое, гибкое создание и редактирование, легко расширяемое, быстрый ввод в эксплуатацию, простое расширение, быстрый запуск, очень динамичный контекст. |
Неуправляемый с большими объемами данных, плохой сегментацией, атрибутами искусственного ключа, внешним интерфейсом программирования, плохо отражает свойства и поведение объектов. |
|
Ориентирована на объекты |
Конец 1980-х |
Лучшая поддержка объектноориентированных языков программирования, хранение мультимедийного контента. Поддерживает объектноориентированные языки программирования, позволяет хранить мультимедийный контент. |
Более низкая производительность с большими объемами данных, мало совместимых интерфейсов. |
|
Ориентирована на документы |
1980-е |
Соответствующие данные хранятся централизованно в независимых документах, свободной структуре, концепции мультимедиа, относится к классификации сущностей БД. |
Организационная работа относительно высока, часто требует навыков программирования. |