Понятие и назначение базы данных. примеры и классификация баз данных
Содержание:
- Введение
- Достоинства и недостатки модели
- Проектирование реляционной базы данных. Преобразование модели в реляционную
- Сетевая модель
- Первичные ключи
- Описание
- Описание
- Таблица как важная часть реляционной БД
- Сетевые СУБД
- Плоская модель
- Историческая справка
- История
- В чём преимущества
- Индексирование данных на сервере
- История
- Табличные базы данных
- История
- Примеры
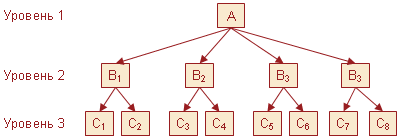
- Иерархическая база данных, структура иерархических данных
- Пример табличной базы данных
- Реляционная модель данных
- Как работают базы данных.
- Сетевые СУБД
- Особенности сетевой модели данных
- Уровни моделирования реляционной базы данных
- Операции над данными в сетевой модели
Введение
Определение 1
База данных – это набор однотипных данных, которые организованы согласно схеме так, что их может эффективно использовать конечный пользователь.
Разработка всех программных систем, предназначенных для работы с базами данных, начинается с формирования структурной организации данных. На базе сформированной структурной организации данных разрабатываются программы, реализуются процедуры по управлению имеющимися данными. Эта очерёдность действий обусловлена тем, что удобнее отталкиваясь от структурной организации данных обратиться к логической обработке этих данных, чем выполнять операции в обратном порядке.
Достоинства и недостатки модели
Сетевая модель данных достаточно хорошо стандартизирована. В 1969 году консорциум CODASYL предложил спецификацию формального языка для описания сетевой модели. Модель обладает высокой выразительной способностью, так как позволяет устанавливать сложные отношения между данными. Сетевые базы данных отличаются высоким быстродействием и универсальностью.
Замечание 2
С другой стороны пользователи сетевых баз данных ограничены использованием той структуры данных, которую определил для них разработчик. Поэтому сетевые базы данных лишены гибкости – любое изменение структуры базы данных влечет перестройку всех записей путем введения новых указателей. Сетевые базы данных требуют сложной структуры памяти. В сетевых базах данных довольно трудно контролировать целостность данных.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
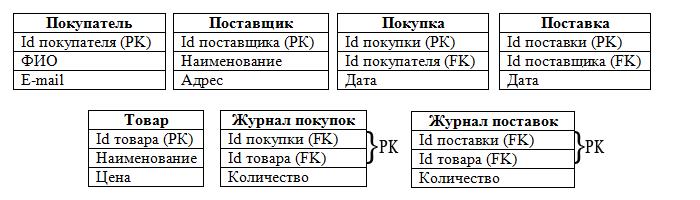
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:

Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Сетевая модель
В данной модели любой объект может быть как главным, так и подчиненным. Каждый объект имеет возможность участвовать в любом числе взаимодействий. Другими словами, любая информационная единица может иметь множество предков и множество потомков.
В моделях подобного рода связи заложены внутри описаний объектов.
Достоинством является гибкость модели, т.е. имеется возможность повышения быстродействия системы.
Недостатком является нагрузка на информационные ресурсы.
Реляционная модель данных (РМД) свое название получила от английского термина relation, что означает «отношение». При соблюдении определенных условий отношение можно представить в виде двумерной привычной для человека таблицы. Основная масса современных БД для компьютеров являются реляционными.
Определение 4
Достоинства реляционной модели данных – это простота, удобство реализации на ЭВМ, наличие теоретического обоснования и возможность формирования гибкой схемы БД, которая допускает настройку при формировании запросов.
Замечание 2
Подобная модель используется, как правило, в базах данных среднего размера. При увеличении количества таблиц в базе данных снижается скорость работы с ней. Возникают также проблемы при создании систем со сложными структурами данных (например, систем автоматизации проектирования).
Объектно-ориентированные БД включают в свой состав 2 модели данных: реляционную и сетевую, и применяются при создании крупных баз данных со сложными структурами.
По характеру использования СУБД бывают:
- персональными (СУБДП):
- многопользова¬тельскими (СУБДМ).
К персональным СУБД относят Visual FoxPro, Paradox, Clipper, dBase, Access и др. К многопользовательским СУБД относят Oracle и Informix. Многопользовательские СУБД состоят из сервера БД и клиентской части, работают в неоднородной вычислительной среде (разные типы ЭВМ и различные операционные системы). Поэтому СУБДМ можно использовать для создания информационной системы, функционирующей по технологии «клиент-сервер». Универсальность многопользовательских СУБД отражается на их высокой цене и компьютерных ресурсах, необходимых для их поддержки.
Определение 5
СУБДП — это совокупность языковых и программных средств создания, ведения и использования БД. С их помощью можно создавать персональные БД и недорогие приложения, работающие с ними, и при необходимости приложения, работающие с сервером БД.
Первичные ключи
Строки в реляционной базе данных неупорядоченные. Для выбора в таблице конкретной строки создается один или несколько столбцов, значения которых во всех строках уникальны. Такой столбец называется первичным ключом.Первичный ключ (primary key) – является уникальным значением в столбце. Никакие из двух записей таблицы не могут иметь одинаковых значений первичного ключа.
По способу задания первичных ключей различают логические (естественные) ключи и суррогатные (искусственные).Логический ключ – представляет собой значение, определяющее запись естественным образом.Суррогатный ключ – представляет собой дополнительное поле в базе данных, предназначенное для обеспечения записей первичным ключом.
Описание
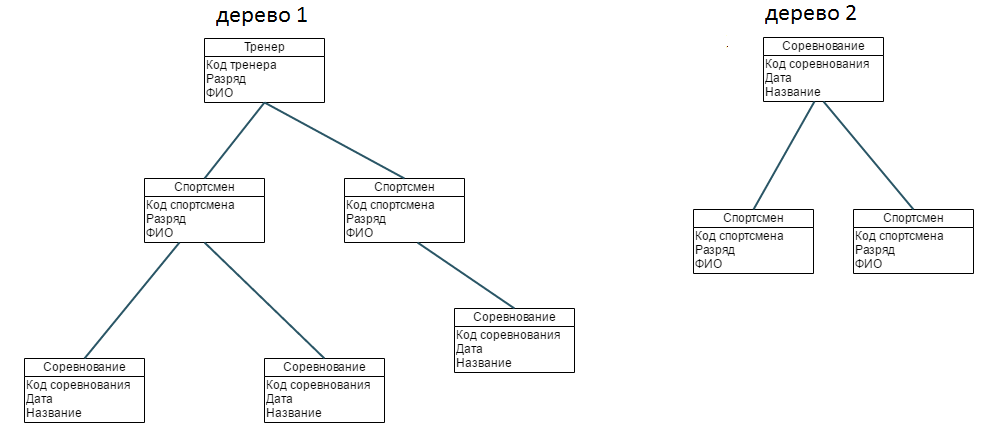
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Описание
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
— столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
— в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
— каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
— на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Сетевые СУБД
Сетевая СУБД — СУБД, построенная на основе сетевой модели данных.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Список самых значимых сетевых СУБД на 1978 год:
- IDS (Integrated Data Store) компании General Electric — самая первая сетевая СУБД, разработаная Чарльзом Бахманом в 1960 г.
- IDS/2 или IDS/II) компании Honeywell, купившей IDS у General Electric, позднее — компании Bull
- Integrated Database Management System (IDMS) компании Cullinet, развитие IDS на основе её исходных кодов
- DMS-1100 (для мейнфреймов UNIVAC 1100) и DMS-90 (для мини-компьютеров, первый релиз — ноябрь 1974) компании UNIVAC
- DBMS-10 компании DEC для Decsystem-10 и Decsystem-20
- CDC DMS-170
- Burroughs Data Management System (DMS-2). Продукт представлен на рынке в октябре 1974 года.
Другие подобные СУБД:[источник не указан 1484 дня]
- IMAGE/3000 компании Hewlett-Packard (1974 г.)
- Norsk-Data SYBAS
- NCR IDM-9000
- Cincom TOTAL
- dbVista
- Universal Datenbank System (UDS) от Siemens
- СООБЗ Cerebrum
- ИСУБД «CronosPRO»
- Caché
- GT.M
Плоская модель

Модель плоского файла
Модель плоской (или таблица) состоит из одного двумерного массива данных элементов, где предполагаются все члены данного столбца , чтобы быть аналогичные ценности, и все члены ряда предполагаются связанными друг с другом. Например, столбцы для имени и пароля, которые могут использоваться как часть базы данных безопасности системы. Каждая строка будет иметь конкретный пароль, связанный с отдельным пользователем. Столбцы таблицы часто имеют связанный с ними тип, определяющий их как символьные данные, информацию о дате или времени, целые числа или числа с плавающей запятой. Этот табличный формат является предшественником реляционной модели.
Историческая справка
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели был создан в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. и изначально ориентированная на использования на мейнфреймах компании IBM. Архитектура системы основана на предложениях DBTG организации CODASYL. В настоящее время IDMS принадлежит компании Computer Associates.
История
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Активным пропагандистом этой модели был Чарльз Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS.
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Индексирование данных на сервере
За счет наличия в серверных базах данных управления транзакциями, про проблемы с индексами можно забыть. Допустим, что пользователь добавил запись. В этот момент начинается транзакция (не явная), в течение которой происходят все необходимые действия по сохранению данных. Если что-то пошло неправильно и сохранение не прошло до конца, то все изменения откатываются, и ничего в работе сервера не нарушается.
Транзакции могут быть и явными, когда программист сам указывает, где начало и конец и в них может выполняться несколько операций изменения или добавления данных. В этом случае сервер в случае ошибки в указанном блоке откатит любые изменения всех операций, сделанные во время выполнения явной транзакции.
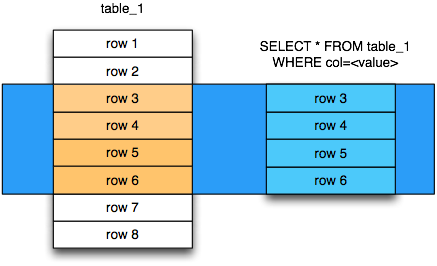
В локальных базах данных индексы хранятся линейно. Это как колонка из упорядоченных данных, и для строк, это то же самое, что выстроить все слова по алфавиту. Конечно же, такой индекс упрощает поиск. Когда происходит сканирование по индексу и программа видит, что уже пошло слово больше, чем задано в условии поиска, сканирование может прекращаться и не придется просматривать всю базу данных. Например, вам надо найти слово «Абажур». Оно будет где-то в начале и чтобы его найти, нужно просканировать всего лишь начало таблицы, не дальше, чем все слова на букву А. За счет того, что данные упорядочены, мы можем быть уверенными, что все остальные слова будут на буквы Б, В и т.д.
В случае с серверной базой, индексы чаще всего (зависит от базы и типа индекса) хранятся немного по-другому – в виде дерева. Сколько слов надо проверить для поиска слова Якорь в базе данных при линейном индексе? Да практически все :(. При древовидном хранении индекса не более чем для слова «Абажур». Для пояснения древообразного индекса рассмотрим классическую задачу (в реальности все немного сложнее, но идея такая же). В самом верху дерева хранятся алфавит. Программа находит букву А, и спускается на уровень ниже. Здесь она находит все слова на буквы АБ и двигается еще ниже. И так пока не найдется нужное слово.
Таким образом, даже если нужное слово находится в самом конце, его поиск будет не намного дольше, чем поиск слова из начала таблицы.
История
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Активным пропагандистом этой модели был Чарльз Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS.
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
Табличные базы данных
База данных, хранящая данные о группе объектов с одинаковыми свойствами, представляется в виде двумерной таблицы, где каждая ее строка последовательно размещает значения свойств одного из объектов; а каждое значение свойства находится в своем столбце, названном по имени свойства.
Столбцы подобной таблицы называются полями, причем каждое поле имеет свое имя (имя соответствующего свойства) и тип данных, который представляет значения этого свойства.
Поле базы данных является столбцом таблицы, содержащим значения определенного свойства.
Определение 2
Строки таблицы – это записи об объекте, которые разбиты на поля столбцами таблицы, в результате каждая запись представлена набором значений, находящихся в полях.
Запись базы данных представляет собой строку таблицы, содержащую набор значений свойств, размещенных в полях базы данных.
Каждая таблица, как правило, содержит одно ключевое поле, содержимое которого является уникальным для каждой записи данной таблицы. С помощью ключевого поля однозначно идентифицируются записи в таблице.
Замечание 2
Таким образом, ключевое поле является полем, значения которого однозначно определяют записи в таблице.
Ключевое поле, как правило, имеет тип данных счетчик. Однако в некоторых случаях удобнее, чтобы ключевое поле таблицы имело другой тип (например, числовой — инвентарный номер или код объекта).
История
Сетевая модель была одним из первых подходов, использовавшимся при создании баз данных в конце 50-х — начале 60-х годов. Исторически на разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Идеи Бахмана послужили основой для разработки стандартной сетевой модели под эгидой организации CODASYL. После публикации отчетов рабочей группы этой организации в 1969, 1971 и 1973 годах многие компании привели свои сетевые базы данных более-менее в соответствие со стандартами CODASYL. До середины 70-х годов главным конкурентом сетевых баз данных была иерархическая модель данных, представленная ведущим продуктом компании IBM в области баз данных — IBM IMS.
В конце 60-х годов Эдгаром Коддом была предложена реляционная модель данных и после долгих и упорных споров с Бахманом реляционная модель приобрела большую популярность и теперь является доминирующей на рынке СУБД.
Примеры
Общие логические модели данных для баз данных включают:
Иерархическая модель базы данных
- Это самая старая форма модели базы данных. Он был разработан IBM для IMS (система управления информацией). Это набор организованных данных в древовидной структуре. Запись БД — это дерево, состоящее из множества групп, называемых сегментами. Он использует отношения «один ко многим». Доступ к данным также предсказуем.
- Сетевая модель
- Реляционная модель
-
Модель сущность – отношения
Расширенная модель сущность – отношения
- Объектная модель
- Модель документа
- Модель сущность – атрибут – значение
- Схема звездочки
Объектно -реляционная база данных объединяет две связанные структуры.
К физическим моделям данных относятся:
- Инвертированный индекс
- Плоский файл
Другие модели включают:
- Ассоциативная модель
- Корреляционная модель
- Многомерная модель
- Многозначная модель
- Семантическая модель
- База данных XML
- Именованный граф
- Triplestore
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Пример табличной базы данных
Рассмотрим базу данных «Компьютер» (рис.3), которая представляет собой перечень объектов (компьютеры), каждый из которых имеет свое имя (название). В качестве характеристик (свойств) будут выступать тип процессора и объем оперативной памяти.
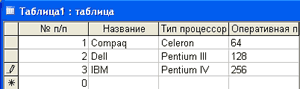
Столбцы этой таблицы представляют поля, каждое из которых имеет свое имя (название соответствующего свойства) и тип данных, которые отражают значения этого свойства. Тип полей Название и Тип процессора — текстовый, а тип поля Оперативная память — числовой. При этом каждое поле имеет определенный набор свойств (размер, формат и др.). Так, для поля Оперативная память задается формат данных «целое число».
Определение 3
Полем базы данных является столбец таблицы, который включает в себя значения определенного свойства.
Строки таблицы представляют записи об объекте, которые разбиты столбцами таблицы на поля. Запись базы данных представляет собой строку таблицы, содержащую набор значений различных свойств объекта.
Замечание 3
Каждая таблица должна иметь хотя бы 1 ключевое поле, содержимое которого является уникальным для любой записи в данной таблице. Значениями ключевого поля однозначно определяются записи в таблице.
Реляционная модель данных
В основе реляционной модели
данных лежат не графические, а табличные
методы и средства представления данных
и манипулирования
ими (рис. 3). В реляционной модели для
отображения информации о предметной
области используется таблица, называемая
«отношением». Строка такой таблицы
называется кортежем, столбец — атрибутом.
Каждый атрибут может принимать некоторое
подмножество значений из определенной
области — домена.
Таблица организации БД позволяет
реализовать ее важнейшее преимущество
перед другими моделями данных, а именно
— возможность использования точных
математических методов манипулирования
данными, и прежде всего — аппарата
реляционной алгебры и исчисления
отношений, К другим достоинствам
реляционной модели можно отнести
наглядность, простоту изменения данных
и организации разграничения доступа к
ним.
Основным недостатком реляционной модели
данных является информационная
избыточность, что ведет к перерасходу
ресурсов вычислительных систем. Однако
именно реляционная модель данных находит
все более широкое применение в практике
автоматизации информационного обеспечения
профессиональной деятельности.
|
Вуз |
Место расположения |
Количество |
|
МГУ им. М.В. |
г. Москва |
26170 |
|
… |
… |
… |
|
Государственный |
г. |
12150 |
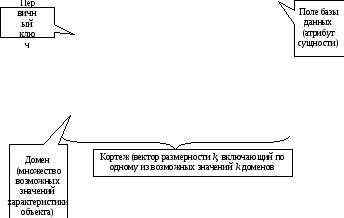
Рис. 3. Фрагмент
реляционной модели данных.
Подавляющее большинство СУБД,
ориентированных на персональные ЭВМ,
являются системами, построенными на
основе реляционной модели данных —
реляционными СУБД.
Как работают базы данных.
По сути, база данных – это набор файлов, в которых хранится информация. СУБД – система управления базами данных, управляет данными, берет на себя все низкоуровневые операции по работе с файлами, благодаря чему программист при работе с базой данных может оперировать лишь логическими конструкциями при помощи
языка программирования, не прибегая к низкоуровневым операциям.
Язык структурированных запросов SQL позволяет производить следующие операции:
- Выборку данных – извлечение из базы данных содержащейся в ней информации.
- Организацию данных – определение структуры базы данных и установления отношений между ее элементами.
- Обработку данных – добавление, изменение, удаление.
- Управление доступом – ограничение возможностей ряда пользователей на доступ к некоторым категориям данных, защита данных от несанкционированного доступа.
- Обеспечение целостности данных – защита базы данных от разрушения.
- Управление состоянием СУБД.
Достоинства системы управления базами данных MySQL:
- Скорость выполнения запросов.
- СУБД MySQL разработана с использованием языков C/C++ и оттестирована более чем на 23 платформах.
- Открытый код доступен для просмотра и модернизации всем желающим.
- Высокое качество и устойчивость работы.
- Поддержка API для различных языков программирования
- Наличие встроенного сервера. СУБД MySQL может быть использован как с внешним сервером, поддерживающим соединение с локальной машиной и с удаленным хостом, так и в качестве встроенного сервера.
- Широкий выбор типов таблиц позволяет реализовать оптимальную для решаемой задачи производительность и функциональность.
- Локализация выполнена корректна.
- Совместимость с другими базами данных и полностью удовлетворяет стандарту SQL.
Сетевые СУБД
Сетевая СУБД — СУБД, построенная на основе сетевой модели данных.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно изменить и приложение.
Список самых значимых сетевых СУБД на 1978 год:
- IDS (Integrated Data Store) компании General Electric — самая первая сетевая СУБД, разработаная Чарльзом Бахманом в 1960 г.
- IDS/2 или IDS/II) компании Honeywell, купившей IDS у General Electric, позднее — компании Bull
- Integrated Database Management System (IDMS) компании Cullinet, развитие IDS на основе её исходных кодов
- DMS-1100 (для мейнфреймов UNIVAC 1100) и DMS-90 (для мини-компьютеров, первый релиз — ноябрь 1974) компании UNIVAC
- DBMS-10 компании DEC для Decsystem-10 и Decsystem-20
- CDC DMS-170
- Burroughs Data Management System (DMS-2). Продукт представлен на рынке в октябре 1974 года.
Другие подобные СУБД:[источник не указан 1484 дня]
- IMAGE/3000 компании Hewlett-Packard (1974 г.)
- Norsk-Data SYBAS
- NCR IDM-9000
- Cincom TOTAL
- dbVista
- Universal Datenbank System (UDS) от Siemens
- СООБЗ Cerebrum
- ИСУБД «CronosPRO»
- Caché
- GT.M
Особенности сетевой модели данных
- Связи в сетевой модели данных осуществляются наборами, которые реализуются с помощью указателей. Сетевая модель данных являются особым витком в развитии иерархической модели данных, их основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию.
- Сетевая модель данных предпологает наличие в ней произвольного количества записей и наборов в том числе их различных типов.
- Связь между двумя записями может выражаться произвольным количеством наборов.
- В любом наборе может быть только один владелец.
- Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов, а также не входить ни в какой тип наборов.
- Допускается добавление новой записи в качестве экземпляра владельца, если экземпляр-член отсутствует.
- При удалении записи-владельца удаляются соответствующие указатели на экземпляры-члены, но сами записи-члены не уничтожаются (сингулярный набор).
Уровни моделирования реляционной базы данных
Внешний уровень – уровень представления базы данных с точки зрения пользователя.Концептуальный – описывает какие данные хранятся в базе данных, а также, какие связи имеются между этими данными.Внутренний – описывает физическое представление базы данных в компьютере, то есть отвечает на вопрос, как информация хранится в базе данных.
Вводятся следующие понятия:
- Модель предметной области – знания о предметной области, описанные с помощью некоторого формального общепринятого способа.
- Логическая (концептуальная) модель данных – является органической составляющей модели предметной области, описывает понятия предметной области в реляционных терминах данных.
- Физическая модель данных – описывает данные средствами конкретной реляционной СУБД.
- База данных и приложение – средства, реализованные на конкретной программно-аппаратной основе.
Операции над данными в сетевой модели
Добавление – внесение записи в базу данных и, в зависимости от режима включения, или включение ее в групповое отношение, где она является подчиненной, или не включение ни в какое групповое отношение.
Включение в групповое отношение – связывание существующей подчиненной записи с записью-владельцем.
Переключение – связывание существующей подчиненной записи с другой записью-владельцем в том же групповом отношении.
Обновление – изменение значения элементов предварительно извлеченной записи.
Извлечение – извлечение записи последовательно по значению ключа и при использовании групповых отношений:– от записи-владельца можно перейти к записям-членам, а от подчиненной записи – к владельцу.
Удаление – удаление записи из базы данных. Если запись – это владелец группового отношения, то происходит анализ класса членства подчиненных записей. Обязательные члены необходимо предварительно исключить из группового отношения, фиксированные – удалить вместе с владельцем, необязательные останутся в базе данных.
Исключение из группового отношения – разрыв связи между записью-владельцем и записью-членом.