4 небанальные директивы meta robots и как их использовать
Содержание:
- Meta Robots
- Атрибуты¶
- Robots.txt & Meta Robots Tags Work Together
- Проверка правильности Meta Robots и его содержимого в Netpeak Spider
- как убрать в обновлении woocommerce теги noindex,follow
- Как закрыть отдельную ссылку от обхода и часть статьи от индексации
- Тег
- Gestione di istruzioni di indicizzazione e pubblicazione combinate
- Meta name robots noindex и nofollow
- 2.
- Особенности работы с поисковыми ботами
- NOINDEX и NOFOLLOW в мета-теге ROBOTS
- NOFOLLOW в ссылках
Meta Robots
Метатег robots позволяет определять настройки индексации и отображения в результатах поиска отдельно для каждой страницы. Его следует помещать в раздел <head> кода страницы.
Meta Robots состоит из двух ключевых атрибутов:
name и content. Первый отвечает за выбор нужного нам поискового робота, а второй — за инструкции для него.
<meta name = «googlebot» content = «noindex»>
Такой тег сообщает сразу всем поисковым роботам, что данную страницу не нужно индексировать и показывать в результатах поиска. Но если мы изменим name, к примеру, на googlebot, то инструкция будет относиться только к поисковому роботу Google.
Если нужно задать инструкции для нескольких поисковых роботов, можно использовать несколько метатегов robots:
<meta name=»googlebot» content=»noindex»>
Тег указывает на запрет индексирования для поискового робота Google.
<meta name=»googlebot-news» content=»nosnippet»>
Тег указывает на запрет отображения расширенного сниппета для новостного поискового робота Google.
Перечень всех возможных директив, которые используются в Meta Robots, можно найти в
инструкциях для вебмастеров от Google.
Атрибуты¶
- Задаёт кодировку документа.
- Устанавливает значение атрибута, заданного с помощью или .
- Предназначен для конвертирования метатега в заголовок HTTP.
- Имя метатега, также косвенно устанавливает его предназначение.
charset
Указывает кодировку документа. Атрибут введён в HTML5 и предназначен для сокращения формы , которая задавала кодировку в предыдущих версиях HTML и XHTML.
Синтаксис
Значения
Название кодировки, например UTF-8.
Значение по умолчанию
Нет.
content
устанавливает значение атрибута, заданного с помощью или . Атрибут может содержать более одного значения, в этом случае они разделяются запятыми или точкой с запятой.
Некоторые значения атрибута для , предназначенных для поисковых роботов, приведены в табл. 1.
| Значение | Описание |
|---|---|
| Разрешает роботу индексировать данную страницу. | |
| Запрещает роботу индексировать текущую страницу. Она не попадает в базу поисковика и её невозможно будет найти через поисковую систему. | |
| Разрешает роботу переходить по ссылкам на данной странице. | |
| Запрещает роботу переходить по ссылкам на данной странице. При этом всем ссылкам не передаётся ТИЦ (тематический индекс цитирования) и PagePank. | |
| Запрещает роботу кэшировать данную страницу. |
Допустимые значения атрибута для , которые предназначены для управления просмотром сайта на мобильных устройствах, приведены в табл. 2.
| Значение | Допустимые значения | Описание |
|---|---|---|
| device-width или целое положительное число | Устанавливает ширину области просмотра в пикселях. | |
| device-height или целое положительное число | Устанавливает высоту области просмотра в пикселях. | |
| Число от 0.0 до 10.0 | Устанавливает соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. | |
| Число от 0.0 до 10.0 | Задаёт максимальное значение масштаба. Должно быть больше или равно minimum-scale, в противном случае игнорируется. | |
| Число от 0.0 до 10.0 | Задаёт минимальное значение масштаба. Должно быть меньше или равно maximum-scale, в противном случае игнорируется. | |
| yes или no | Если указано no, то пользователь не сможет масштабировать веб-страницу. По умолчанию используется yes. |
Синтаксис
Значения
Строка символов, которую надо взять в одинарные или двойные кавычки.
Значение по умолчанию
Нет.
http-equiv
Браузеры преобразовывают значение атрибута , заданное с помощью , в формат заголовка ответа HTTP и обрабатывают их, как будто они прибыли непосредственно от сервера.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Тип кодировки документа.
Устанавливает дату и время, после которой информация в документе будет считаться устаревшей.
Способ кэширования документа.
- Загружает другой документ в текущее окно браузера.
Значение по умолчанию
Нет.
name
Устанавливает идентификатор метатега для пары «». Одновременно использовать атрибуты и не допускается.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Имя автора документа.
- Описание текущего документа.
- Список ключевых слов, встречающихся на странице.
- Управляет просмотром сайта на мобильных устройствах.
Значение по умолчанию
Нет.
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты. Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке
Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
Воспользуйтесь промокодом при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!
С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции в блоке .
- Nofollow в Meta Robots. Показывает страницы, содержащие инструкции в блоке .
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.
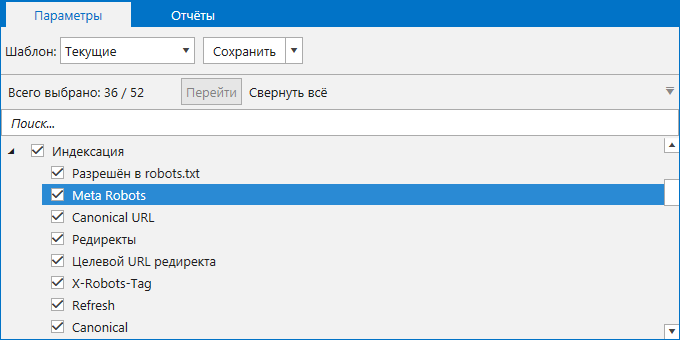
Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.

По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.
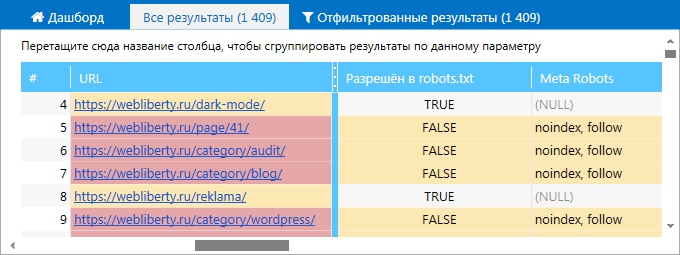
2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.
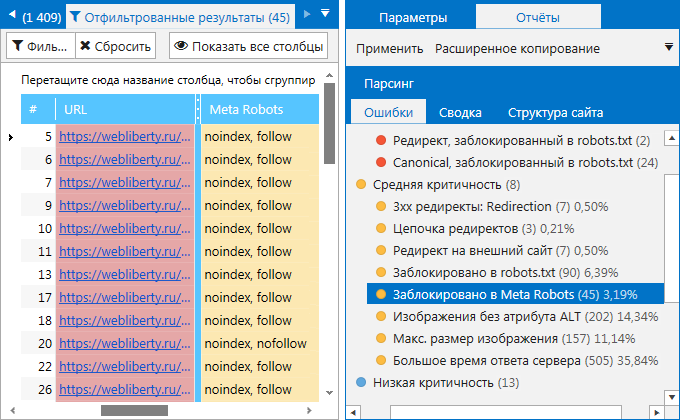
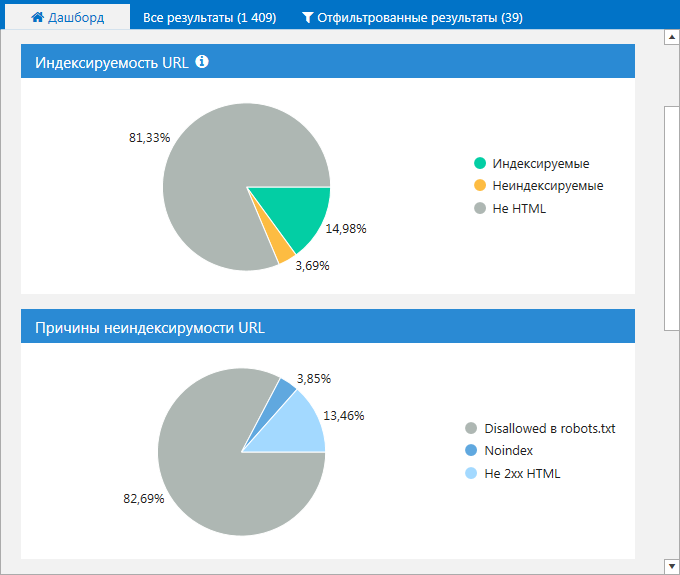
3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.
4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
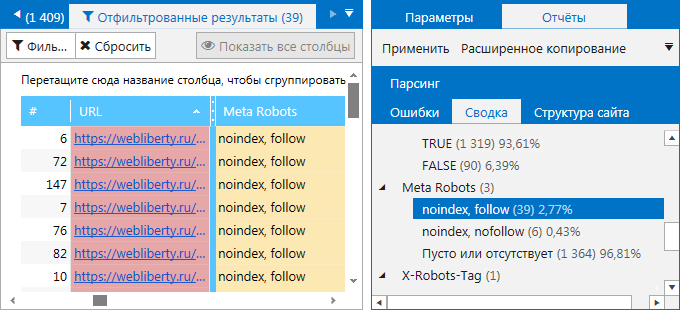
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
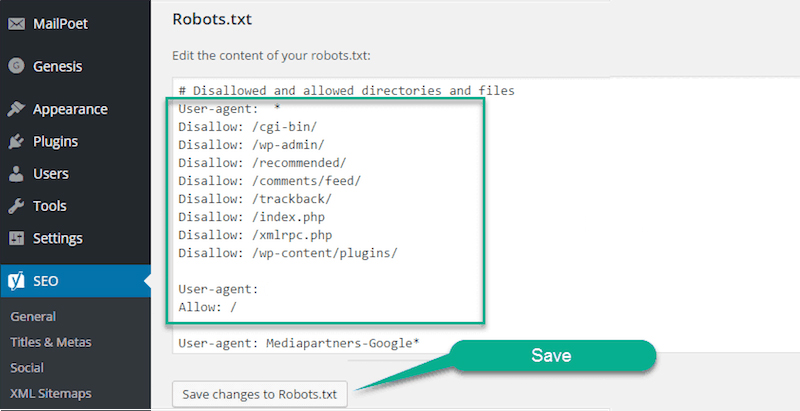
как убрать в обновлении woocommerce теги noindex,follow
После обновления woocommerce 3.2.0 — в исходном коде будет примерно так:

И если кому-то нужно лично (без разработчиков) управлять индексацией своего магазина, то в этой статье как раз и научимся!
Также в тексте статьи, может кому-то пригодится, предложу вариант уборки через фильтр — init — строку стилистики css галереи (строка также показана выше на скрине):
<noscript><style>.woocommerce-product-gallery{ opacity: 1 !important; }</style></noscript>.
Формирования обработки обоих описанных выше метастрок находится в:
/woocommerce/includes/wc-template-functions.php
В спойлере дан пример одной из функций обновлённого плагина: эта функция отвечает за вывод <meta name=’robots’ content=’noindex,follow’ />.
Итак: если вы закрывали странички «корзина» и «оформление заказа» и пр. WOOC от индексирования каким-то иным способом (пример дам в финале статьи), то у вас получится, как и говорилось выше, две пары закрывающих тегов, однако — разных значений!
…Цель сегодняшней работы — нужно оставить только какую-то одну пару: так правильнее.
Но тут закавыка вот в чём: если мы отключим наши кастомные фильтры, то — пара, выводимая кодом удалится, — но останется другая из обновления wooc …
Это ничего! документ в любом случае закрыт от индексирования. Однако напоминаю: разрешён для прохода роботом!
Вот и подошли к важнейшему в теме: коли нам нужно полностью закрыть какую-то отдельную страничку в , читаем далее…
Один владелец магазина нынче у меня спросил: «как убрать теги, которые внедрены в финальное 3.2.0 обновление wooc, но оставить свои, которые были — т.е ??».
Да, иногда целесообразнее оставить код сайта таким, каким он был до обновления, чтобы исключить так называемое «мигание кода»: не надо путать поисковики!
…например, такой вариант — для того, чтобы убрать метатеги robots в обновлении wooc, нужно прописать в файл функций активной темы следующий код:
С robots закончили!
Далее…
…как упоминал выше, уберём из такую строку (если кому-то нужно):
Решение (в файл функций):
Ну и как эпилог:
Как закрыть отдельную ссылку от обхода и часть статьи от индексации
- Чтобы закрыть отдельную ссылку от обхода и её учета используем синтаксис: <a href=»/url» rel=»nofollow»>текст ссылки</a>.
- Чтобы закрыть часть текста от индексации поисковиком Яндекс, используем синтаксис: <!—noindex—>текст, запрещенный к индексации<!—/noindex—>
- если забыть поставить закрывающий тег <!—/noindex—>, Яндекс проигнорирует весь после <!—noindex—>.
Joomla3-x.ru
- Как изменить префикс базы данных Joomla 3
- 4 шага создания страницы 404 Not found на Joomla
- 5 простых шагов защиты сайта Joomla 3
- 7 лучших альтернатив Joomla для создания профессиональных сайтов
- 7 шагов переноса сайта Joomla 3 на WordPress
- Google Analytics для Joomla 3 сайта
- Joomla 4.0 на подходе: смотрим Joomla 4.0.0 Alpha 12
- АГС Яндекс на сайте Joomla — за что попасть и как вывести сайт Joomla под фильтра АГС Yandex
- Базовые SEO настройки Joomla 3 сайта
- Безопасность Joomla сайта и почему она важна
Тег
Noindex – тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
<noindex>Здесь находится закрытый для индексации контент</noindex>
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия noindex
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
Gestione di istruzioni di indicizzazione e pubblicazione combinate
Puoi creare un’istruzione con più indicazioni combinando le istruzioni dei meta tag robots
con le virgole. Di seguito è riportato un esempio di meta tag robots che
indica ai web crawler di non indicizzare la pagina e di non sottoporre a scansione
nessun link sulla pagina:
<meta name="robots" content="noindex, nofollow">
Di seguito è riportato un esempio che limita lo snippet di testo a 20 caratteri e consente un’anteprima delle immagini di grandi dimensioni:
<meta name="robots" content="max-snippet:20, max-image-preview:large">
Per le situazioni in cui vengono specificati più crawler con diverse
istruzioni, il motore di ricerca utilizza la somma delle istruzioni
negative. Ad esempio:
<meta name="robots" content="nofollow"> <meta name="googlebot" content="noindex">
Googlebot identificherà la pagina contenente questi meta tag come
una pagina con istruzione .
Meta name robots noindex и nofollow
Для того чтобы отключить индексацию нужно написать
<meta name=»robots» content=»noindex»>
Если вы хотите чтобы робот не переходил по ссылкам со страницы нужно изменить значение meta-тега атрибута content на nofollow.
Чтобы не дать определенному поисковому роботу индексировать вашу страницу, но разрешить это другим, нужно использовать такую запись:
<meta name=»имя_робота которому_запрещена_индексация» content=»noindex, nofollow»>
Как видите, если аргумент content имеет несколько параметров, то они перечисляются через запятую.
Имя робота в случае ПС Яндекса — yandex
<meta name=»yandex» content=»noindex, nofollow»>
Meta name google
Для поисковой системы Google имя робота следует указать — google, пример:
<meta name=»» content=»noindex, nofollow»>
2.
Этот мета-тег устанавливается в секцию <head> на той странице, которая не должна индексироваться и в исходном коде выглядит так:
<head> ... <meta name ”robots” content=”noindex” /> ... </head>
В примере выше метатег запрещает индексацию на уровне страницы (весь контент, который на ней есть), но не запрещает поисковым роботам посещать ее и переходить по ссылкам, которые используются в контенте.
Но обычно используется комбинация с nofollow, чтобы запретить поисковому роботу переходить по ссылкам на данной странице (и по внешним, и по внутренним). В этом случае метатег выглядит так:
<head> ... <meta name ”robots” content=”noindex, nofollow” /> ... </head>
Возможные комбинации noindex + nofollow:
- <meta name=”robots” content=”noindex, follow” /> — используется в случае, если не нужно, чтобы страница была проиндексирована поисковиками, но роботам были доступны ссылки с этой страницы на другие внутренние или внешние ссылки с нее.
- <meta name=”robots” content=”noindex” /> выполняет то же самое. В данном случае вы запретите поисковой системе индексировать страницу, но индексация ссылок на ней возможна.
- <meta name=”robots” content=”noindex, nofollow” /> – запрещает индексировать контент на соответствующей странице + запрещает роботам переходить по ссылкам. Т.е. полный запрет индексирования страницы.
- <meta name=”robots” content=”index, follow” /> – разрешает роботам индексировать страницу и ходить по ссылкам. Использовать данный вариант смысла нет, так как по умолчанию, и без него поисковикам разрешено выполнять те же действия.
- <meta name=”robots” content=”index, nofollow” /> — разрешает индексировать страницу, но запрещает переходить по ссылкам и индексировать их.
- <meta name=”robots” content=”nofollow” /> — делает то же самое, т.е. разрешает индексировать контент на странице, но запрещает индексацию ссылок.
Отдельное использование Noindex для Google и Yandex
- <meta name=”googlebot” content=”noindex” /> — закрывает страницу от индексации для робота Google
- <meta name=”yandex” content=”noindex” /> — закрывает страницу от индексации для робота Yandex
Особенности работы с поисковыми ботами
Чтобы индексация сайта поисковыми роботами происходила быстро и эффективно, необходимо:
Кроме ошибок в robots.txt, медленной скорости загрузки сайта и блокировки в .htaccess, причинами плохой индексации могут быть:
3.1. Высокая нагрузка на сервер при посещениях роботов
Индексация ботами поисковых систем крайне важна для продвижения, однако в некоторых ситуациях она может перегружать сервер, либо под видом роботов сайт могут атаковать хакеры. Чтобы знать цели, с которыми боты обращаются к ресурсу, и отслеживать возможные проблемы, проверяйте логи сервера и динамику серверной нагрузки в панели хостинг-провайдера. Критические значения могут свидетельствовать о проблемах, связанных с активным доступом к сайту поисковых роботов.
Когда роботы перегружают сервер слишком активными запросами к сайту, можно снизить их скорость обхода. Как это сделать, узнайте из справок и .
3.2. Проблемы из-за доступа фейковых ботов к сайту
Бывает, что под видом ботов Google к сайту пытаются получить доступ спамеры или хакеры. Если возникла такая проблема, проверьте, действительно ли сайт сканирует поисковый робот Google:
-
В логах сервера хостинг-провайдера скопируйте IP-адрес, с которого был сделан запрос к сайту.
-
Проверьте данный IP с помощью сервиса MyIp.
-
Затем проверьте адрес, указанный в строке IP Reverse DNS (Host).
Полученный IP-адрес должен совпадать с исходным в логах сервера, иначе это говорит о том, что имя бота поддельное. В данном случае сайт действительно сканировал Googlebot Аналогично проверяются и вызвавшие подозрения боты Яндекса.
Узнайте о других причинах плохой индексации из нашего поста «Почему поисковые роботы и Netpeak Spider не сканируют ваш сайт».
Чтобы узнать, как тот или иной поисковый бот сканирует ваш сайт, воспользуйтесь краулером Netpeak Spider, который позволяет имитировать поведение робота. Для анализа необходимо:
-
Открыть настройки «Продвинутые» и выбрать шаблон «По умолчанию: бот» → он предполагает учёт всех инструкций по сканированию и индексации.
-
Перейти на вкладку «User Agent» и из списка ботов выбрать нужного.
- Начать сканирование и по окончании ознакомиться с полученными данными.
3.3. Список ботов поисковых систем
Поисковые системы используют различные типы роботов: для индексации обычных страниц, новостей, изображений, фавиконов и прочих типов контента. Список IP-адресов, которые используют боты поисковиков, постоянно меняется и не разглашается.
3.2.1. Роботы Google
Полный список роботов Google можно посмотреть в справке. Рассмотрим наиболее популярных ботов:
- Googlebot — к ним относятся краулеры двух типов: для десктопных и мобильных версий стандартных сайтов. С июля 2019 года для новых и адаптированных под мобильные устройства сайтов включено приоритетное сканирование мобильных версий, соответственно большинство запросов будут обрабатывать мобильные боты.
-
Googlebot Images — поисковый робот для индексации изображений. При желании можно запретить индексацию всех картинок на сайте с помощью такой директивы в robots.txt:
User-agent: Googlebot-Image
Disallow: / - Googlebot News — бот, добавляющий материалы в Google Новости.
- Googlebot Video — робот, индексирующий видеоконтент.
- Google Favicon — краулер, собирающий фавиконы сайтов.
- APIs-Google — агент пользователя для отправки PUSH-уведомлений. Такие уведомления используются, чтобы веб-разработчики могли быстро получить информацию о каких-либо изменениях на сайтах без излишней нагрузки серверов Google.
- AdsBot Mobile Web Android, AdsBot Mobile Web, AdsBot — краулеры, проверяющие качество рекламы на различных типах устройств.
3.2.2. Роботы Яндекс
У Яндекса тоже обширный список ботов, который можно детально изучить в Яндекс.Помощи. Расскажу о некоторых из них:
- Основной робот, индексирующий страницы, — YandexBot/3.0. Указания боту можно указывать с помощью директив в robots.txt.
- Бот, скачивающий страницы для проверки их доступности, — YandexAccessibilityBot/3.0. Этот краулер игнорирует команды в файле robots.txt.
- Робот, определяющий зеркала проектов, — YandexBot/3.0; MirrorDetector.
- Бот, индексирующий картинки, — YandexImages/3.0.
- Бот, который скачивает фавиконы сайтов. — YandexFavicons/1.0.
- Краулер, индексирующий мультимедийный контент, — YandexMedia/3.0.
- Бот, собирающий материалы для Яндекс.Новостей, — YandexNews/4.0.
- Краулеры Яндекс.Метрики — YandexMetrika/2.0, YandexMetrika/3.0.
NOINDEX и NOFOLLOW в мета-теге ROBOTS
Мета-тег robots отвечает за всю страницу целиком. Через данный мета-тег можно запрещать или разрешать индексировать контент страницы.
Noindex отвечает за запрет индексации текста на странице.
Nofollow отвечает за запрет индексации ссылок на странице.
Используются данные значения следующим образом:
<meta name=»robots» content=»noindex, nofollow» />
что означает – данную страницу нельзя индексировать вообще.
Могут быть и такие значения:
<meta name=»robots» content=»index, nofollow» />
можно индексировать контент, но игнорировать ссылки на странице, т.е. не индексировать их.
Или так:
<meta name=»robots» content=»noindex, follow» />
не индексировать контент, но учитывать ссылки.
Более подробно про мета-тег robots вы можете прочитать в моей статье Мета тег Robots и файл Robots.txt – как управлять индексацией страниц сайта.
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
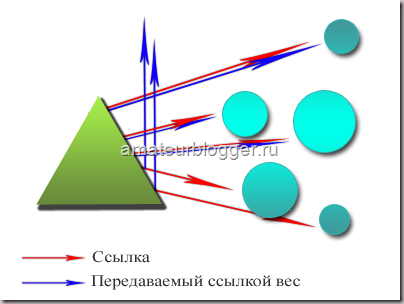
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
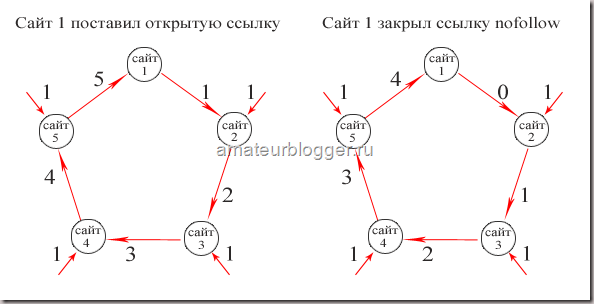
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:

Выдержка из раздела Справка Google:
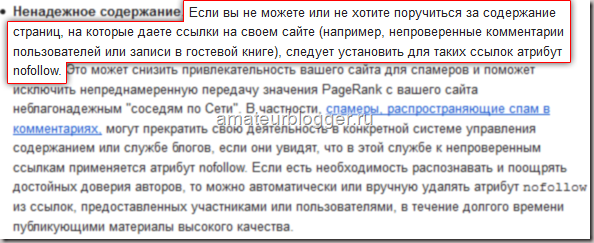
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.