Noindex
Содержание:
- Использование Noindex в Яндексе
- Использование структурированных данных
- Тег Noindex
- как убрать в обновлении woocommerce теги noindex,follow
- Что это конкретно и как влияет?
- How much time should you spend on reducing crawl budget?
- What is a Nofollow Tag?
- добавим тег noindex,follow абсолютно ко всем страницам пагинации
- Где еще используются noindex и nofollow
- Как rel nofollow влияет на распределение веса страниц
- Пагинация через Javascript и «бесконечная» прокрутка
- Особенности работы с поисковыми ботами
- Общие сведения
- Что рекомендует Яндекс?
- Закрывать или не закрывать?
- Что изменилось с вводом поддержки rel=nofollow?
- rel=»nofollow»
- Совместное использование noindex nofollow
Использование Noindex в Яндексе
Пользоваться им не сложнее, чем любым другим HTML-тегом. Обычно выглядит всё так:

Возможен и альтернативный вариант — тег ноиндекс в виде стандартного HTML-комментария. Вот, к примеру, как можно скрыть контекст от AdSense:
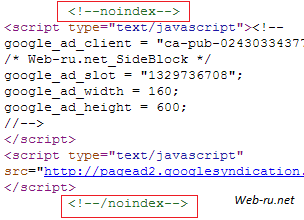
AdSense «завёрнут» в noindex tag
— т.е. всё то же самое, но добавляем указание на то, что это комментарий. На мой взгляд, такой вариант предпочтительней.
Кстати, чтобы узнать, где на веб-странице расставлены блоки тегов ноуиндекс, можно поставить:
- дополнение RDS bar в Chrome.
- дополнение Page Promoter bar в Firefox.
Они будут буквально «подсвечивать» участки кода, «завёрнутые» в этот тег. Правда, RDS bar иногда не подсвечивает вариант в формате комментария — noindex.
Использование структурированных данных
Метатеги robots определяют, какое количество контента Google может автоматически извлекать с веб-страниц и показывать в результатах поиска. Однако многие издатели также применяют структурированные данные schema.org, чтобы показывать в результатах поиска нужную им информацию. Заданные в метатегах robots ограничения не распространяются на структурированные данные, кроме (относится к статьям) и значений , которые указываются для других творческих работ.
Чтобы задать максимальную длину текстового фрагмента в результатах поиска с учетом значений , используйте метатег robots с директивой . К примеру, если на странице есть структурированные данные для рецептов (), определенный ими контент может показываться в карусели рецептов независимо от ограничения длины текстового фрагмента в директиве . Эта директива метатега robots не действует, когда информация предоставляется с применением структурированных данных для расширенных результатов.
Вы можете редактировать типы структурированных данных и их значения на веб-страницах. Добавляйте или удаляйте информацию, чтобы роботу Google были доступны только нужные сведения
Обратите внимание, что структурированные данные могут использоваться в Поиске, даже если они объявлены внутри элемента с атрибутом
Тег Noindex
1.1 Что такое noindex
Noindex – это тег, введенный и используемый Яндексом (и учитываемый Рамблером) для запрета индексации какой-то определенной части html-кода. Другие поисковые системы, в частности – Гугл, его никак не воспринимают (они его просто не замечают).
Используется тег так:
<noindex>какой-то текст</noindex> |
Распространяется тег только на текстовую информацию, а Увы, но многие (преимущественно начинающие) вебмастера этого не знают и пытаются обрамлять все ссылки со своего блога <noindex>анкор ссылки</noindex>. В этой ситуации Яндекс не увидит лишь анкор ссылки, но сама ссылка останется им видна.
Тег noindex, введенный яндексом, не считается общепринятым, поэтому он не валиден (не воспринимаем) многими html-редакторами (к примеру, визуальный редактор wordpress начинает удалять его). Для этого яндекс придумал следующее: придать тегу форму обычного комментария (тег будет восприниматься не как рабочий оператор, а обычный комментарий пользователя), тогда и html-редакторы никак на него не повлияют.
Вид валидного тега noindex:
Валидный открывающийся <!--noindex--> |
Валидный закрывающийся <!--/noindex--> |
В таком виде визуальный редактор вордпресса не пытается удалить тег ноиндекс.
Кстати, не нужно путать этот тег со схожим по написанию мета-тегом noindex. Этот мета-тег прописывается в заголовке (<head></head>) документа – эту часть не видят пользователи, и он указывает поисковым системам (всем без исключения), что этот документ закрыт от индексации. Обычный же тег noindex закрывает от индексации не весь документ, а только ту его часть, которая попала между открывающимся <noindex> и закрывающимся </noindex>.
<noindex>Этот текст Яндекс не проиндексирует</noindex> |
Школа Start Up интерпретирует тэг по-своему, хотя ей пора бы уже и обновить данные по поводу nofollow и noindex.
1.2 Нюансы тега Noindex
- Чаще всего проблем с работой тега noindex не наблюдается: текст, заключенный внутрь него не индексируется Яндексом. Но иногда возникают ситуации, по словам оптимизаторов, когда некоторая информация все же проскакивает в индекс самой популярной поисковой системы рунета. Такое действительно бывает, увы. Объяснить это можно следующим образом: яндекс изначально индексирует страницу целиком (даже ту часть, что внутри тегов noindex), а лишь затем формирует индекс и удаляет ненужное; возможно, в таких ситуациях фильтрация просто затягивается, и через некоторое время все нормализуется.
- Соблюдать вложенность этого оператора необязательно – даже при неправильной вложенности, как утверждается в справке Яндекса, тег работает корректно. Правильная вложенность выглядит так: <noindex><b>текст</b></noindex>. Сравните с неправильной: <noindex><b>текст</noindex></b>
- Если вы используете окрывающийся тег <noindex>, не забудьте поставить закрывающийся </noindex>, иначе весь текст после открывающегося может выпасть из индекса.
1.3 Применение тега Noindex
Применяться тэг должен в тех случаях, когда на странице есть информация, которую не нужно отправлять в индекс Яндекса. Это «мусор», который лучше обрамлять тегами noindex. В общем, используется тег в следующих случаях:
- для закрытия кода счетчиков (rambler100, измеритель тИЦ и PR, liveinternet и т.д.);
- для закрытия неуникального (дубля, копипаста и т.д.) или часто повторяющегося текста;
- для того чтобы спрятать от индекса часто меняющийся контент, который индексировать бессмысленно;
- для закрытия различных форм (форма подписки feedburner, форма контактов, форма рассылки и т.д.);
- для удаления из индекса информации в сайдбарах (но только не внутренние ссылки!);
- для того чтобы спрятать баннеры;
- для удаления из индекса различных скриптов и сценариев.
1.4 Когда noindex не применяется
В некоторых ситуациях использование этого оператора может быть бессмысленным или даже нежелательным. Не закрывайте тегом noindex:
- контекстную рекламу (Яндекс.Директ, Гугл.Адсенс и т.д.)
- ссылки (внешние, внутренние), тег на них не работает (но анкоры выпадают из индекса);
- комментарии и ссылки с комментариев на блогах;
- обычный текст, который нет повода скрывать от яндекса, или отдельные слова – частое употребление тега нежелательно.
как убрать в обновлении woocommerce теги noindex,follow
После обновления woocommerce 3.2.0 — в исходном коде будет примерно так:
И если кому-то нужно лично (без разработчиков) управлять индексацией своего магазина, то в этой статье как раз и научимся!
Также в тексте статьи, может кому-то пригодится, предложу вариант уборки через фильтр — init — строку стилистики css галереи (строка также показана выше на скрине):
<noscript><style>.woocommerce-product-gallery{ opacity: 1 !important; }</style></noscript>.
Формирования обработки обоих описанных выше метастрок находится в:
/woocommerce/includes/wc-template-functions.php
В спойлере дан пример одной из функций обновлённого плагина: эта функция отвечает за вывод <meta name=’robots’ content=’noindex,follow’ />.
Итак: если вы закрывали странички «корзина» и «оформление заказа» и пр. WOOC от индексирования каким-то иным способом (пример дам в финале статьи), то у вас получится, как и говорилось выше, две пары закрывающих тегов, однако — разных значений!
…Цель сегодняшней работы — нужно оставить только какую-то одну пару: так правильнее.
Но тут закавыка вот в чём: если мы отключим наши кастомные фильтры, то — пара, выводимая кодом удалится, — но останется другая из обновления wooc …
Это ничего! документ в любом случае закрыт от индексирования. Однако напоминаю: разрешён для прохода роботом!
Вот и подошли к важнейшему в теме: коли нам нужно полностью закрыть какую-то отдельную страничку в , читаем далее…
Один владелец магазина нынче у меня спросил: «как убрать теги, которые внедрены в финальное 3.2.0 обновление wooc, но оставить свои, которые были — т.е ??».
Да, иногда целесообразнее оставить код сайта таким, каким он был до обновления, чтобы исключить так называемое «мигание кода»: не надо путать поисковики!
…например, такой вариант — для того, чтобы убрать метатеги robots в обновлении wooc, нужно прописать в файл функций активной темы следующий код:
С robots закончили!
Далее…
…как упоминал выше, уберём из такую строку (если кому-то нужно):
Решение (в файл функций):
Ну и как эпилог:
Что это конкретно и как влияет?
Что это
Здесь может быть много всего:
- куски неуникального текста, взятые вами с чужого сайта и вставленные в вашу уникальную (изначально) статью,
- обилие кодов рекламы — тизеры, баннеры, контекстная реклама и другая,
- множество JavaScript-скриптов и кодов flash-приложений,
- разные блоки ссылок в сайдбаре вроде «наши друзья»,
- куча установленных счётчиков,
- и др.
Как влияет
Исходя из двух пунктов списка, указанных в начале статьи, влияет это так:
- портится уникальность текстов;
- происходит «разбавление» плотности ключевых слов страниц сайта.
Поэтому неплохо бы закрыть все лишние части материалов от индексации поисковыми роботами.
How much time should you spend on reducing crawl budget?
You might hear a lot of talk on SEO forums about how important crawl efficiency and crawl budget is for SEO and, while it’s common practice to disallow and noindex large groups of pages that have no benefit to search engines or readers (for example, back-end code that is only used for the running of the site, or some types of duplicate content), deciding whether to hide lots of individual pages is probably not the best use of time and effort.
Google likes to index as many URLs as possible, so, unless there is a specific reason to hide a page from search engines, it’s usually ok to leave the decision up to Google. In any case, even if you hide pages from search engines, Google will still keep checking to see if those URLs have changed. This is especially pertinent if there are links pointing to that page; even if Google has forgotten about the URL, it might re-discover it the next time a link is found to it anyway.
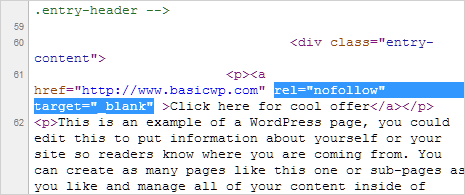
What is a Nofollow Tag?
A nofollow tag on a link tells search engines not to use a link to decide on the importance of the linked pages (PageRank) or discover more URLs within the same site.
Common uses for nofollows include links in comments and other content that you don’t control, paid links, embeds such as widgets or infographics, links in guest posts, or anything off-topic that you still want to link people to.
Historically SEOs have also selectively nofollowed links, to funnel internal PageRank to more important pages.
Nofollow tags can be added in one of two places:
- The <head> of the page (to nofollow all links on that page): <meta name=”robots” content=”nofollow” />
- The link code (to nofollow an individual link): <a href=”example.html” rel=”nofollow”>example page</a>
A nofollow won’t prevent the linked page from being crawled completely; it just prevents it being crawled through that specific link. Our own tests, and others, have shown that Google will not crawl a URL which it finds in a nofollowed link.
Google state that if another site links to the same page without using a nofollow tag or the page appears in a Sitemap, the page might still appear in search results. Similarly, if it’s a URL that search engines already know about, adding a nofollow link won’t remove it from the index.
In September 2019, Google announced an update to their nofollow directive and introduced two new link attributes, these are:
- rel=“sponsored” – The sponsored attribute should be used to identify links that are for advertisement purposes, where sponsorship and compensation agreements are in place.
- rel=“ugc” – As the attribute for User Generated Content, this value is recommended for links within user generated content sites, for example forum posts and blog comments.
In addition, all links marked with nofollow, sponsored or ugc are now treated as hints regarding which links to consider in search and when crawling, as opposed to just a signal, as was used previously for nofollow. You can find out more about this update in our post which also covers the impact of these along with expert insights.
What is Noindex Nofollow?
As mentioned above, adding a nofollow tag to a page won’t prevent it from being crawled completely. Therefore, to prevent it from being indexed, you’ll also need to noindex the page. This will allow Google to still be able to crawl the page but it will not appear in the index. Pages you will probably want to noindex include; admin/login pages, internal search results and registration pages. To stop Google crawling the page completely, you should also disallow it (see above).
добавим тег noindex,follow абсолютно ко всем страницам пагинации
Чтобы понимать, как по теме статьи отрабатывают условные теги Вордпресс, думаю, будет не лишним забежать вперед и рассмотреть примеры по составным частям:
подборка основных условных тегов WP расписана здесь.
как найти и убрать циклические ссылки… работа с условными тегами.
Для того, чтобы добавить информацию на страницы пагинации (важно ! на все страницы сайта, на которых отрабатывает пагинация) существует такой условный тег:
Очень возможно, что этот тег у вас на сайте на ряду с иными уже используется! (или в плагином или сами ручками прописывали) по типу:
В этом случае, на всех страницах пагинации соответственно с условиями выше метатег роботс уже будет выведен.
Замечательно! …однако, в нашем случае, все эти благостные решения с использованием условных тегов, хороши для архивов по умолчанию (рубрик, меток и т.д.).
Мы же, создали свой собственный архив, используя страницу с ID 4, а значит потребуются и настройки более утончённые.
Что ж, давайте попробуем наш архив пролистать по страницам!
…как и говорилось выше, на страницах пагинации появится ошибка, как на скриншоте выше! Лишний тег! …потому что информация robots в соответствии с условным тегом и у кого уже используется будет выведена на всех сопутствующих страницах!
Где еще используются noindex и nofollow
Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots. Последний, в свою очередь, используется в HTML-коде страницы для указания поисковым ботам рекомендаций насчет индексации страничек и переходу по размещенным на них ссылкам.
Приведенный на скриншоте пример трактуется, как пожелание не выполнять индексацию содержимого странички и не анализировать ссылки, размещенные на ней. Наличие подобной конструкции в теле кода страниц может быть возможной причиной, по которой не индексируется сайт.
Как rel nofollow влияет на распределение веса страниц
То, о чем будет рассказано ниже, не является истиной в последней инстанции, так как алгоритмы поисковиков до конца не раскрываются публично по многим причинам. Эта информация основана во многом на общедоступных данных, на результатах экспериментов, проведенных некоторыми крупными кампаниями, а также на итогах собственной деятельности в сети. Наверное, о ссылочном ранжирования Гугла было известно чуть больше, чем об аналогичном механизме Яндекса, поэтому побольше внимания уделим именно первому из них.
В самом начале при ранжировании отдельных сайтов оба поисковика установили алгоритмы, при действии которых рассчитывался статический вес каждой страницы сайта. После опубликования странички (документа) в интернете и ее публикации она уже имела определенный статвес.
Данный изначально минимальный вес мог быть увеличен посредством входящих линков (link — ссылка), проставленных как с других внутренних страничек, так и со страниц внешних ресурсов. При этом вебстраница, на которую ведет ссылка, считается реципиентом, а та, с которой она проставлена — донором. В той или иной степени это можно считать общей схемой в алгоритмах обеих поисковых систем, хотя, конечно, у каждого из них есть свои особенности.
Статический вес отдельных страниц (а по сути их авторитетность, или трастовость) ранее определялся: в Google посредством показателя PageRank (что это такое?), а в Yandex — с помощью вИЦ (взвешенного индекса цитирования). При этом у «зеркала рунета» имелся и так называемый тИЦ для всего сайта в целом.
Именно значения PR и тИЦ (тематический индекс цитирования) имелись в открытом доступе для каждого ресурса, но сейчас данные показатели претерпели существенные изменения, на что есть серьезные причины, одной из которых является минимизация возможности влияния со стороны на результаты ссылочного ранжирования веб-сайтов в поисковых системах.
Итак, давайте разберемся, какое влияние оказывало изначально прописанное значение nofollow для конкретного линка на перераспределение веса.
С самого начала ввода Гуглом этого параметра в 2005 году и по 2009 год закрытие гиперссылки (неважно, внутренней или ведущей на сторонний ресурс) атрибутом нофоллоу приводило к тому, что вес странички-донора (той, с которой проставлен линк) не перетекал на акцептор (страницу, или страницы, куда ведет ссылка). Схематически механизм искусственного распределения веса на внутренние и внешние страницы может выглядеть так (изначально вес акцептора равен 1):
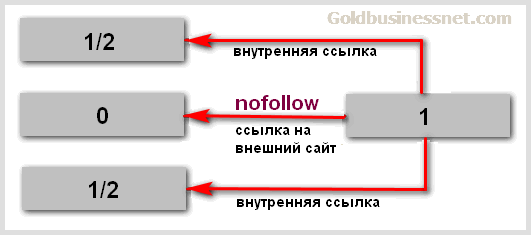
Подчеркиваю, это упрощенная схема, на самом деле расчет перетекания того же Google PageRank гораздо сложнее и имеет нелинейную зависимость. Однако, из рисунка выше вполне ясно видна практическая польза от подобного манипулирования.
Смотрите. Допустим, у вас на страничке веб-сайта проставлены три ссылки: две внутренние (на другие вебстраницы вашего ресурса) и одна, которая закрыта nofollow, ведет на внешний веб-проект. Тогда внутренние странички получат свою «весовую» порцию (что выгодно для поднятия их траста), а внешний документ не получит ничего, то есть, вес «не утечет» на сторонний сайт.
Поскольку rel=»nofollow» действует одинаково на внутренние и внешние линки, то некоторые вебмастера пытались максимально накопить вес на нужных (продвигаемых в поиске) веб-страницах, используя нофоллоу и при внутренней перелинковке, если необходимо было сослаться на второстепенные с точки зрения продвижения страницы.
Однако, такие действия отдают искусственным влиянием на ранжирование. Более того, закрытие поисковым ботам перехода на важные страницы, такие как «Контакты», «О нас», «Правила использования», внутренние ссылки на которые часто включали нофоллоу по той причине, что не предназначались для прямого продвижения, сильно затрудняло оценку сайта в полной мере.
По это причине Гугл в 2009 году исключил возможность подобного манипулирования, введя принципиально новый алгоритм, заключавшийся в том, что при закрытии от индекса страница-реципиент, как и раньше, не получает дополнительного веса, но и внутренние страницы также приобретают меньше:
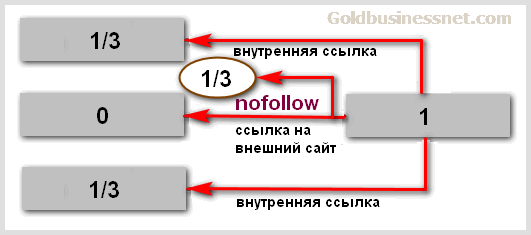
То бишь, та часть веса, которая могла бы перейти с донора на внутренние акцепторы, уходит в «никуда». Таким образом, вся предыдущая стратегия по накоплению веса стала несостоятельной.
В результате возникает вопрос: как же быть? Ответ до безобразия прост и неоднократно звучал из уст авторитетных SEO-специалистов и ведущих специалистов Google. Смысл его в следующем:
Таким образом, на современном этапе гораздо важнее сосредоточиться на юзабилити вебсайта и других аспектах его SEO-оптимизации, позволяющих продвинуть проект естественным образом.
Пагинация через Javascript и «бесконечная» прокрутка
Есть и такой вариант вывода дополнительных карточек товаров — через javascript. Это либо динамическая «бесконечная прокрутка» (новые товары автоматически появляются сразу, как только посетитель прокручивает до конца списка), либо кнопка «Показать еще».
Главный плюс — нет проблем с пагинацией. Ее, по сути, просто нет. Главный минус — возможные проблемы с индексацией карточек товаров. Также у поисковой системы пропадает возможность оценить широту ассортимента категории, а это один из .
Если у вас товары выводятся с помощью javascript, то Яндекс советует следующее:
Здесь 2 варианта:
- К динамической прокрутке добавлять обычную систему пагинации и действовать по общему алгоритму. Советую этот пункт.
- Следить за объемом карточек товаров в sitemap.xml и перелинковкой, чтобы страницы продуктов индексировались максимально полно. Совет полезен и для всех остальных сайтов .
Тема вроде узкая, а получилась на 10.000 символов. Много нюансов, которыми нельзя пренебрегать.
Особенности работы с поисковыми ботами
Чтобы индексация сайта поисковыми роботами происходила быстро и эффективно, необходимо:
Кроме ошибок в robots.txt, медленной скорости загрузки сайта и блокировки в .htaccess, причинами плохой индексации могут быть:
3.1. Высокая нагрузка на сервер при посещениях роботов
Индексация ботами поисковых систем крайне важна для продвижения, однако в некоторых ситуациях она может перегружать сервер, либо под видом роботов сайт могут атаковать хакеры. Чтобы знать цели, с которыми боты обращаются к ресурсу, и отслеживать возможные проблемы, проверяйте логи сервера и динамику серверной нагрузки в панели хостинг-провайдера. Критические значения могут свидетельствовать о проблемах, связанных с активным доступом к сайту поисковых роботов.
Когда роботы перегружают сервер слишком активными запросами к сайту, можно снизить их скорость обхода. Как это сделать, узнайте из справок и .
3.2. Проблемы из-за доступа фейковых ботов к сайту
Бывает, что под видом ботов Google к сайту пытаются получить доступ спамеры или хакеры. Если возникла такая проблема, проверьте, действительно ли сайт сканирует поисковый робот Google:
-
В логах сервера хостинг-провайдера скопируйте IP-адрес, с которого был сделан запрос к сайту.
-
Проверьте данный IP с помощью сервиса MyIp.
-
Затем проверьте адрес, указанный в строке IP Reverse DNS (Host).
Полученный IP-адрес должен совпадать с исходным в логах сервера, иначе это говорит о том, что имя бота поддельное. В данном случае сайт действительно сканировал Googlebot Аналогично проверяются и вызвавшие подозрения боты Яндекса.
Узнайте о других причинах плохой индексации из нашего поста «Почему поисковые роботы и Netpeak Spider не сканируют ваш сайт».
Чтобы узнать, как тот или иной поисковый бот сканирует ваш сайт, воспользуйтесь краулером Netpeak Spider, который позволяет имитировать поведение робота. Для анализа необходимо:
-
Открыть настройки «Продвинутые» и выбрать шаблон «По умолчанию: бот» → он предполагает учёт всех инструкций по сканированию и индексации.
-
Перейти на вкладку «User Agent» и из списка ботов выбрать нужного.
- Начать сканирование и по окончании ознакомиться с полученными данными.
3.3. Список ботов поисковых систем
Поисковые системы используют различные типы роботов: для индексации обычных страниц, новостей, изображений, фавиконов и прочих типов контента. Список IP-адресов, которые используют боты поисковиков, постоянно меняется и не разглашается.
3.2.1. Роботы Google
Полный список роботов Google можно посмотреть в справке. Рассмотрим наиболее популярных ботов:
- Googlebot — к ним относятся краулеры двух типов: для десктопных и мобильных версий стандартных сайтов. С июля 2019 года для новых и адаптированных под мобильные устройства сайтов включено приоритетное сканирование мобильных версий, соответственно большинство запросов будут обрабатывать мобильные боты.
-
Googlebot Images — поисковый робот для индексации изображений. При желании можно запретить индексацию всех картинок на сайте с помощью такой директивы в robots.txt:
User-agent: Googlebot-Image
Disallow: / - Googlebot News — бот, добавляющий материалы в Google Новости.
- Googlebot Video — робот, индексирующий видеоконтент.
- Google Favicon — краулер, собирающий фавиконы сайтов.
- APIs-Google — агент пользователя для отправки PUSH-уведомлений. Такие уведомления используются, чтобы веб-разработчики могли быстро получить информацию о каких-либо изменениях на сайтах без излишней нагрузки серверов Google.
- AdsBot Mobile Web Android, AdsBot Mobile Web, AdsBot — краулеры, проверяющие качество рекламы на различных типах устройств.
3.2.2. Роботы Яндекс
У Яндекса тоже обширный список ботов, который можно детально изучить в Яндекс.Помощи. Расскажу о некоторых из них:
- Основной робот, индексирующий страницы, — YandexBot/3.0. Указания боту можно указывать с помощью директив в robots.txt.
- Бот, скачивающий страницы для проверки их доступности, — YandexAccessibilityBot/3.0. Этот краулер игнорирует команды в файле robots.txt.
- Робот, определяющий зеркала проектов, — YandexBot/3.0; MirrorDetector.
- Бот, индексирующий картинки, — YandexImages/3.0.
- Бот, который скачивает фавиконы сайтов. — YandexFavicons/1.0.
- Краулер, индексирующий мультимедийный контент, — YandexMedia/3.0.
- Бот, собирающий материалы для Яндекс.Новостей, — YandexNews/4.0.
- Краулеры Яндекс.Метрики — YandexMetrika/2.0, YandexMetrika/3.0.
Общие сведения
Как и в случае с атрибутом nofollow, с которым я рекомендую ознакомиться, noindex имеет значения, как в случае обычного тега, так и мета-тега.
- Тег noindex закрывает от индексации только те части, которые заключены внутри него;
- Мета-тег noindex — закрывает всю страницу от индексирования.
В первом случае, тегом оборачиваются необходимые части текста на страницах, которые не нужно индексировать. Это могут быть служебные участки текста или же какая-то конфиденциальная информация.
Тег можно использовать, как в общепринятом варианте, так и валидном, чтобы сделать код страницы валидным и убрать ошибки за счет тега. Снизу даю 2 строки, первая из которых обычный вариант, а вторая — валидный.
Какой вариант использовать, решайте сами. Я же пришел ко второму.
В случае же с мета-тегом, noindex добавляется в шапку сайта, что запрещает всю страницу от индексации. Необходим в том же случае (служебные страницы и так далее), только уже для полной страницы.
В данном случае noindex является значением мета-тега robots (см. ниже).
«>
Теперь по поводу использования данного тега.
Применение
Как я уже я писал выше, применять его стоит в том случае, если на странице имеется какая-то служебная информация. Также это имеет место, когда имеются неуникальные куски текста, которые пагубно влияют на продвижения страницы. Их также можно закрывать тегом noindex.
Если же взять мета-тег, который применяется ко всей странице и содержится внутри мета-тега robots (скриншот выше), то данный случай стоит применять для закрытия целых страниц от индексации. Это могут быть целые служебные страницы, не несущие никакой пользы сайту и посетителям. Например, страницы контактов, карты сайта и так далее.
Также имеет место закрытие страниц пагинации, то есть тех страниц, которые разбиваются на списки. Например, в постраничной навигации на сайте можно закрыть все страницы, кроме первой, чтобы обезопасить себя от появления дублированного контента.
«>
Хотя, в последнее время я перестал закрывать страницы мета-тегом noindex. Связано это с произведенным мной анализом других популярных сайтов. Я увидел, что никто из гигантов не использует такое закрытие. Исходя из этого, я также убрал. Хотя раньше я добавлял noindex на такие страницы и все работало на ура. Поэтому, если у вас мета-тег добавляется на страницы пагинации, то можете не переживать.
Главное, чтобы сами контентные страницы были полностью открыти и на них не было мета-тега noindex.
Посмотреть его наличие можно в исходном коде страницы, нажав комбинацию клавиш ctrl+u.
Касаемо моего сайта, то я применяю тег и довольно часто, но не в самих статьях, а в самой верстке шаблона. Я закрываю все части, которые не несут смысловой нагрузки сайту:
- социальные кнопки;
- формы подписки;
- на страницах рубрик, архивов и поиска закрываю текст краткого анонса, чтобы не дублировать контент, ведь он доступен и в полной версии статьи.
Проверить закрытые части данным тегом можно с помощью дополнения к браузеру RDS bar.
Вот, как выглядит закрытие формы подписки и социальных кнопок при активном RDS баре (закрытые области подсвечиваются коричневым).
«>
А вот закрытый кусок текста на страницах рубрик, архивов и поиска.
«>
Таким образом можно закрыть очень много ненужного в своем шаблоне.
На этом можно заканчивать данный материал. Больше о данном теге ничего толкового и не скажешь. В окончание хочу сказать, что если вы хотите закрывать внешние ссылки в noindex, то закроется только содержимое ссылки, то есть ее анкор.
Сама же ссылка работать будет и вес также будет передаваться акцептору. Для закрытия внешних ссылок, нужно использовать атрибут nofollow.
Все, друзья. До связи.
Что рекомендует Яндекс?
Особенности:
- Карточки товаров будут индексироваться как обычно.
- Предотвращает возможное дублирование.
- Помогает поисковику определить корректную посадочную страницу.
- Для Яндекса rel=»canonical» не является строгой директивой. По опыту могу судить, что Яндекс иногда не учитывает или пропускает указания каноникала.
- rel=»canonical» позволяет передать на основную страницу «некоторые показатели неканонических адресов».
- В комментариях Платон ответил, что оказывается можно ссылаться не на первую страницу пагинации, а на документ со всем количеством товаров (если таковой имеется). Возникает вопрос — почему эту информацию не вывели в содержание записи?
- В марте 2018 года Платон ответил в комментариях фразой «Если страницы со всеми товарами нет, на страницах пагинации атрибут rel=»canonical» можно не устанавливать». Ставьте каноникал на первую страницу. Хотя нет, на документ с общим ассортимент. Но если его нет, то вообще не ставьте. Так, ставить или не ставить, и куда? .
Получается, что идеальный вариант для Яндекса — rel=»canonical» на отдельную страницу со всем ассортиментом продукции категории. Почему это не подходит для большинства сайтов?
- Во-первых, на многих сайтах нет подобного функционала.
- Во-вторых, такая страница должна быть основным документом категории и быть прописана в меню. Иначе ее внутренний вес будет минимальным. Или ставить дополнительно rel=»canonical» со стандартной категории на документ со всем ассортиментом раздела. Сюда же ее оптимизация: Title, Description, h1. На мой взгляд, много сомнительных манипуляций. Непонятно, как на это еще отреагируют поисковые системы.
- В-третьих, самое главное — теряется значение пагинации: посетители с поисковиков будут переходить на большую страницу с общим ассортиментом.
- В-четвертых, документ будет «тяжелее». От этого будет страдать скорость загрузки, которая, в свою очередь, влияет на ранжирование. Получается, ловим одно, но топим другое .
Закрывать или не закрывать?
Мнение Яндекса — закрывать (из комментариев к той же записи):
Мнение Google — не закрывать. Либо поисковик сам разберется, что лучше держать в индексе и ранжировать, либо создайте для него отдельную страницу.
Основной вывод один — я бы крайне не советовал оставлять все на волю поисковых систем. Приведу несколько причин:
- Мигающая индексация. Яндекс любит, то добавлять пагинацию в индекс, то исключать (статус «некачественная страница»).
- Постоянно меняются посадочные в связи со схожей релевантностью и пунктом №1. Посетители из ПС постоянно попадают на разные документы. В поисковой выдаче они конкурируют с основной категорией (особенно если на ней нет дополнительного контента).
- Пользователи не попадают на нужный набор товаров. Например, вы сделали наиболее привлекательную сортировку. В начале листинга показываются товары в наличие или по скидке, но потенциальный клиент может попасть на любую из страниц пагинации с распроданным ассортиментом.
Что изменилось с вводом поддержки rel=nofollow?
- Для тех, кто ведет ресурсы для людей и не использует спам-продвижения, почти ничего не изменится. Возможно некоторое уменьшение числа внешних ссылок, закрытых с rel=»nofollow».
- Для тех, кто использовал в продвижении ссылочный спам (спам в комментариях, спам в форумах, соц. сетях, Википедии и т.д), и у кого основная ссылочная масса, дающая ТИЦ, состояла из таких ссылок, будет существенное снижение ТИЦ и как правило, проседание в поисковой выдаче Yandex.
Кратко, о новинках апреля 2010 года в Яндекс:
- У страницы поисковой выдачи Яндекс теперь фиксированная ширина.
- Появились в выдаче навигационные цепочки, у некоторых сниппетов и даты публикации.
- Появился колдунщик видео.
- В панели веб-мастера появилась возможность просмотра статистики по собственным ключевым словам.
P.S. Теперь осталось дождаться включения поддержки Яндексом канонического атрибута rel=»canonical», о котором я писал в статье о дублированном контенте, и многие блогеры вздохнут с облегчением.
Хорошая новость, в конце мая 2011г. Яндекс стал учитывать атрибут rel=»canonical». Принесет это облегчение или нет, покажет время.
rel=»nofollow»
<a rel="nofollow" href="htmlweb.ru>WEB-технологии</a>
Данный атрибут не влияет на индексацию ссылки. В большинстве поисковиков (кроме Google) переход по ней все-таки осуществляется. Единственная задача данного атрибута — сообщить поисковой системе, что рейтинг со страницы, на которой ссылка размещена, не должен передаваться странице, на которую данная ссылка ведет.
Если вам необходимо уменьшить количество внешних ссылок на странице, заключите их в теги <NOINDEX>здесь ссылки</NOINDEX> или <!—NOINDEX—>здесь ссылки<!—/NOINDEX—>
Использованны материалы с сайтов поисковых систем: Google
Совместное использование noindex nofollow
Очень часто вебмастера стараются использовать оба тега совместно, хотя их одновременное использование сомнительно.
Синтаксис noindex nofollow:
<noindex><a href="http://site.ru" rel="nofollow">текст ссылки</a></noindex> |
Для того чтобы вам была понятна механика работы тегов, рассмотрим несколько примеров с комментариями:
Пример 1:
<noindex><a href="http://site.ru">текст ссылки</a></noindex> |
Используются только теги <noindex>. В этом случае ссылка индексируется поисковыми системами, но Яндекс ее будет считать безанкорной (безтекстовой). Гугл видит анкор ссылки.
Пример 2:
<a href="http://site.ru" rel="nofollow">текст ссылки</a> |
Используется атрибут rel=»nofollow». В этой ситуации обе поисковые системы не учитывают передаваемый вес ссылки, однако ссылку они видят и учитывают.
Пример 3:
<noindex><a href="http://site.ru" rel="nofollow">текст ссылки</a></noindex> |
Используются оба тега: и noindex, и nofollow. Ссылка учитывается обоими поисковиками, но вес по ней не передается. Также яндекс считает ссылку безанкорной.
Другими словами, при совместном использовании теги noindex nofollow будто не замечают друг друга, и работают как обычно.
Однако, как уже было упомянуто выше, использование ноиндекс здесь сомнительно, т.к. закрывать анкоры ссылок – необязательно и практически всегда не нужно. Теперь решайте сами, нужно ли использовать совместно nofollow и noindex или нет.