Как сделать robots.txt для wordpress
Содержание:
- Разбор примера популярного роботса для ВП.
- Sitemap.xml
- Зачем вообще нужен robots.txt?
- Как применять регулярные выражения и подстановочные знаки
- Robots.txt для Joomla
- robots.txt через хуки WP
- Простое создание файла для любого поисковика
- Robots.txt
- Индексация сайта
- Правильный robots.txt для WordPress в Яндексе
- Плагины для редактирования robots txt
- Какие правила нужно включить в файл robots.txt для WordPress
- Проверка robots.txt
- Как выбрать робота, к которому вы обращаетесь?
- Пример Robots.txt для WordPress
Разбор примера популярного роботса для ВП.
Вижу что многим читателям трудно воспринять теорию без практики, поэтому дополняю статью конкретным примером. Возьмём популярный вариант robots и разберём его по полочкам. Итак, вот он сам файл:
User-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */comments Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/ Disallow: /*?* Disallow: /?s= User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= Host: https://kakoytosite.ru Sitemap: https://kakoytosite.ru/sitemap.xml
Что мы видим? Первое что бросается в глаза, это дублирование условий для всех роботов user-agent: * и отдельно зачем-то для Яндекса user-agent: Yandex. Хочется сразу же спросить у автора – Вы действительно думаете что робот Яндекса тупой и не поймёт общие правила со звёздочкой?
Ну что ж, а теперь по порядку:
Disallow: /wp-login.php Disallow: /wp-register.php
Если вы читаете эту статью не из прошлого, то на борту у вас минимум должна быть версия WordPress 5.x.x не меньше. Так вот, страницы входа wp-login.php и wp-register.php по умолчанию наделены специальным тегом robots – nofollow. То есть, ВордПресс уже сам закрыл эти страницы от индексации и вам не нужно их больше нигде закрывать.
Disallow: /cgi-bin
Директория сервера это классика, только не понятно откуда она взялась. Эта директория изначально отдает 403 ошибку сервиса при переходе, поэтому она никак не может быть проиндексирована поисковиками. Стало быть, этот пункт из файла можно так же смело удалить.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes
Первые две директории wp-admin и wp-includes являются техническими. То есть, к ним нет доступа не авторизованным пользователям. В том числе и пауку (краулеру) не удастся попасть на эти страницы. Он будет автоматически перенаправлен на страницу входа wp-login.php которая уже закрыта тегом роботс от индексации.
Директории /wp-content/… отвечают за файлы ваших тем и плагинов, в том числе и за файлы js и css. Если закрывать эти файлы от индексации, то Google не сможет прочитать их и в вебмастере вы увидите ошибки, что сайт не адаптирован. Хотя он может быть полностью мобильным.
Disallow: */comments Disallow: /category/*/*
Скорее всего, это пользовательские директивы, которые были прописаны под конкретный сайт (как я и говорил в начале) и никаким боком к вашему не относятся. Но все просто копируют готовый и даже не думают, что они делают.
Disallow: /trackback Disallow: */trackback Disallow: */*/trackback
Это одна из приблуд движка WordPress. С помощью неё движок посылает уведомления на сайты, ссылки на которые у вас будут в статьях. Отключается это штатными средствами. В админке перейдите по пути Настройки > Обсуждение и уберите галочки на первых двух (верхних) пунктах.
Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/
Вообще не понимаю, зачем закрывать фиды от индексации? Поисковик фиды не индексирует и не выводит в выдаче. Вы хоть раз видели в поиске страницу фидов?
Disallow: /*?* Disallow: /?s=
Эти директории отвечают за страницы с get параметрами и за страницу поиска по сайту. Здесь уже решать вам, нужны ли они в индексе или нет. Я никогда их не закрываю и бед не знаю.
Sitemap.xml
Теперь добавим карту сайта. Это тоже делается с помощью плагина. Их много, но я предпочитаю тот, что зовется «Google XML Sitemaps». Ставится ровно так же как и предыдущий.
Настраивается в разделе админки (левое вертикальное меню) «Настройки», подпункт «XML-Sitemap». Собственно, достаточно тупо снять галочку с пункта «Add sitemap URL to the virtual robots.txt file.» и сохранить (там есть кнопка сохранения, если пролистаете ниже).
Чтобы убедиться, что все работает, откройте в соседней вкладке ссылку типа http://ваш_сайт/sitemap.xml
Увидели что-то вроде этого?
Отлично. Не закрывайте вкладку. Она нам еще пригодится. А пока переходим в админку.
Зачем вообще нужен robots.txt?
До появления CMS для поисковых роботов процесс индексации выглядел достаточно просто. Он просто приходил на ваш сайт и сканировал все HTML страницы которые там есть, а затем заносил их к себе в базу для последующей обработки.
После появления CMS данный процесс значительно усложнился в первую очередь потому, что в папке вашего сайта на хостинге появилось огромное количество файлов движка, которые не содержат никакого ценного контента для поискового робота. И среди этой кучи файлов с кодом бедному роботу нужно найти те две – три статьи, которые вы опубликовали, и которые, по вашему мнению, должны попасть в выдачу.
Можете представить, сколько лишней работы приходится проделывать роботу и сколько мусора может попасть в выдачу?
С целью хоть как то упростить индексацию был придуман robots.txt, который содержит в себе набор команд, с описанием тех папок, которые не нужно индексировать, а также указывающей поисковому роботу путь к карте сайта, о важности которой мы поговорим в одной из следующих статей
Как применять регулярные выражения и подстановочные знаки
Стандартный роботс для вордпресс не поддерживает подстановочные знаки или регулярные выражения. Однако, главные поисковики понимают его, потому допустимо использовать привычные строки из кода для блокировки определенных групп файлов.
Например:
Disallow: /*.php
Disallow: /copyrighted-images/*.jpg
|
1 |
Disallow*.php Disallowcopyrighted-images*.jpg |
Есть весьма полезная функция, обозначающая окончание URL-адреса, это проставление знака «$» (Disallow: /*.php$). Таким образом, раздел /index.php не будет индексироваться, а вот /index.php?p=1 – будет. Данная опция хорошо работает в специфических обстоятельствах, но должна использоваться крайне аккуратно. Ведь легко разблокировать страницы, которые на самом деле планировалось заблокировать.
Robots.txt для Joomla
И хотя в 2018 Joomla редко кто использует, я считаю, что нельзя обделять вниманием эту замечательную CMS. При продвижении проектов на Joomla вам непременно придется создавать файл роботс, а иначе как вы хотите закрывать от индексации ненужные элементы?. Как и в предыдущем случае, вы можете создать файл вручную, просто закинув его на хост, либо же использовать модуль для этих целей
В обоих случаях вам придется его грамотно настраивать. Вот так будет выглядеть правильный вариант для Joomla:
Как и в предыдущем случае, вы можете создать файл вручную, просто закинув его на хост, либо же использовать модуль для этих целей. В обоих случаях вам придется его грамотно настраивать. Вот так будет выглядеть правильный вариант для Joomla:
User-agent: *
Allow: /*.css?*$
Allow: /*.js?*$
Allow: /*.jpg?*$
Allow: /*.png?*$
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
User-agent: Yandex
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
User-agent: GoogleBot
Disallow: /cache/
Disallow: /*.pdf
Disallow: /administrator/
Disallow: /installation/
Disallow: /cli/
Disallow: /libraries/
Disallow: /language/
Disallow: /components/
Disallow: /modules/
Disallow: /includes/
Disallow: /bin/
Disallow: /component/
Disallow: /tmp/
Disallow: /index.php
Disallow: /plugins/
Disallow: /*mailto/
Disallow: /logs/
Disallow: /component/tags*
Disallow: /*%
Disallow: /layouts/
Host: site.ru # не забудьте здесь поменять адрес на свой
Sitemap: site.ru/sitemap.xml # и здесь
Как правило, этого достаточно, чтобы лишние файлы не попадали в индекс.
robots.txt через хуки WP
В WordPress запрос на файл robots.txt обрабатывается отдельно и совсем не обязательно физически создавать файл robots.txt в корне сайта, более того это не рекомендуется! Потому что при таком подходе никакой плагин или код не сможет нормально изменить этот файл.
do_robots() — как работает динамическое создание файла robots.txt.
По умолчанию WP 5.5 создает следующий код для файла robots.txt:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: http://example.com/wp-sitemap.xml
Изменить содержание robots.txt можно через два хука: robots_txt и do_robotstxt. Рассмотрим оба из них. Код приведенный ниже можно вставить в файл темы functions.php.
Этот хук позволяет дополнить уже имеющиеся данные файла robots.txt.
// Дополним базовый robots.txt
// -1 before wp-sitemap.xml
add_action( 'robots_txt', 'wp_kama_robots_txt', -1 );
function wp_kama_robots_txt( $output ){
$str = '
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed # Все встраивания.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
';
$str = trim( $str );
$str = preg_replace( '/^+(?!#)/mU', '', $str );
$output .= "$str\n";
return $output;
}
Перейдем на страницу и видим:
User-agent: * Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Disallow: /cgi-bin # Стандартная папка на хостинге. Disallow: /? # Все параметры запроса на главной. Disallow: *?s= # Поиск. Disallow: *&s= # Поиск. Disallow: /search # Поиск. Disallow: /author/ # Архив автора. Disallow: */embed # Все встраивания. Disallow: */page/ # Все виды пагинации. Disallow: */xmlrpc.php # Файл WordPress API Disallow: *utm*= # Ссылки с utm-метками Disallow: *openstat= # Ссылки с метками openstat Sitemap: http://wptest.ru/wp-sitemap.xml
Обратите внимание, что мы дополнили родные данные ВП, а не заменили их. Этот хук позволяет полностью заменить файл robots.txt
Этот хук позволяет полностью заменить файл robots.txt.
add_action( 'do_robotstxt', 'my_robotstxt' );
function my_robotstxt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "\r\n", $lines );
die; // обрываем работу PHP
}
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Простое создание файла для любого поисковика
Если вы боитесь заниматься тонкой настройкой самостоятельно, её можно провести автоматически. Существуют конструкторы, собирающие подобные файлы без вашего участия. Они подходят людям, которые только начинают своё становление в качестве вебмастеров.
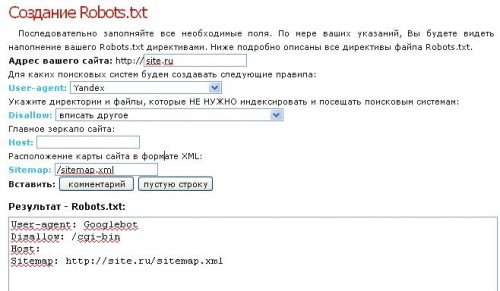
Как видно на изображении, настройка конструктора начинается с введения адреса сайта. Далее вы выбираете поисковые системы, с которыми планируете работать. Если вам не важна выдача той или иной поисковой системы, то нет необходимости создавать под неё настройки. Теперь переходите к указанию папок и файлов, доступ к которым планируете ограничить. В данном примере вы сможете указать адрес карты и зеркала вашего ресурса.
Robots.txt generator будет заполнять форму по мере наполнения конструктора. Всё, что в дальнейшем от вас потребуется — это скопировать полученный текст в txt-файл. Не забудьте присвоить ему название robots.

Robots.txt
Этот файл можно заливать без каких-либо плагинов. По FTP например. Но если нет доступа или хочется все проделать с комфортом, то… Ставим плагин. Как вы уже убедились на предыдущих примерах, это очень простое действие, но профессионалы берут за это деньги.
Итак, ставим плагин «WordPress Robots.txt File». Опять-же, можете выбрать другой, который будет работать.
Ставим плагин, активируем, переходим в «Настройки», в подпункт «Чтение».
На открывшейся странице видим поле robots.txt
Если оно чем-то заполнено — удалите. Сейчас мы его заполним новым содержимым.
Скопируйте из адресной строки браузера адрес вашего сайта и вставьте его в поле с надписью «Введите адрес сайта».
Теперь перейдите во вкладку с Сайтмапом. Помните, выше по тексту я просил ее не закрывать? Скопируйте из адресной строки путь к файлу sitemap.xml и вставьте в поле «Введите адрес вашего файла sitemap.xml».
Нажмите кнопку «Создать robots.txt».
Если все сделано правильно, в поле под кнопкой появится текст. Скопируйте его весь и вставьте в поле robots.txt, открытое в админке вашего сайта («Настройки», «Чтение»).
Нажмите кнопку «Сохранить изменения».
Если на открывшейся странице вы видите текст, который только что копировали и вставляли из поля, значит все установилось как надо.
Помогло? Зашли Админу на чай.
Т.е. только что, благодаря умению читать и искать, вы сами, своими руками, установили Карту сайта и файл директив для поисковых роботов. Браво!
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см
ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
https://ktonanovenkogo.ru/robots.txt
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида . Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Правильный robots.txt для WordPress в Яндексе
Правильный robots.txt для WordPress должен иметь отдельную часть для Яндекса, как в примере, который можно скачать выше. Для этого поисковика обязательно необходимо указать следующие директивы:
- Host. Это адрес главного зеркала сайта, либо с WWW, либо без WWW. Главное зеркало также должно быть настроено в файле .htaccess. Подробнее тут.
- Sitemap. Это адрес к карте сайта XML формата (для роботов). Необходимо указать полный путь до карты, например «https://example.ru/sitemap.xml».
Роботы Яндекса также понимают правило «Crawl-delay». Оно указывает, с какой периодичность робот может сканировать сайт. Указывается в секундах, например, «Crawl-delay: 2.5» указывает, что робот может посещать страницу не чаще, чем один раз в 2,5 секунды. Эта директива может быть полезна, если сканирующий робот оказывает слишком большую нагрузку на сайт.
Если хотите, то можно узнать, как выглядит файл robots.txt на любом сайте. Для этого напишите в браузере адрес «https://example.ru/robots.txt» (вместо «example.ru» целевой сайт).
SEO оптимизацияSEO плагиныWordPressАнализ сайтаДоменЗащита сайтаНаполнение сайта контентомНастройка сайтаПлагины для дизайнаПлагины для записейПлагины для юзабилитиПоисковые системыПолезные сервисы и программыСистемные плагиныСоздание сайтаТемы WordPressТехническая оптимизацияХостингЯндекс
Оставьте комментарий:
Плагины для редактирования robots txt
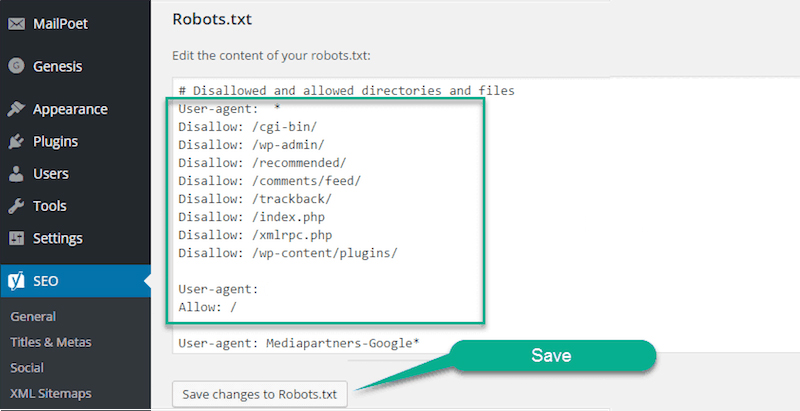 Если вы хотите редактировать или генерировать правильный robots для wordpress через плагин вместо cPanel, то непременно должны знать об удобных инструментах системы управления контентом WordPress. С их помощью легко и быстро работать с файлами-роботами в веб-сайтах различного назначения и блогах. Вот лучшие плагины для редактирования robots txt.
Если вы хотите редактировать или генерировать правильный robots для wordpress через плагин вместо cPanel, то непременно должны знать об удобных инструментах системы управления контентом WordPress. С их помощью легко и быстро работать с файлами-роботами в веб-сайтах различного назначения и блогах. Вот лучшие плагины для редактирования robots txt.
Virtual Robots.txt
Virtual Robots — оптимальный плагин для роботов WordPress, зарекомендовавший себя в среде разработчиков. Он генерирует файл роботс в автоматическом режиме и позволяет быстро его конфигурировать с учетом потребностей ресурса. Этот плагин имеет более 50 тысяч активных установок, и совместим с последней версией CMS.
Ключевые преимущества:
- Нет необходимости открывать robots txt в cPanel или через FTP;
- Автоматическая генерация файла и добавление карты сайта;
- Открытие доступа только к нужным файлам и папкам, остальные блокируются.
Для новичков в ИТ-разработке подобный инструмент весьма полезен за счет простоты и функциональности. Цена: бесплатно.
WordPress Robots.txt optimization (+Sitemap)
Используется для создания robots wordpress, где требуется автоматизированное включение XML-файла Sitemap. Данный плагин имеет более 3K активных установок и ряд преимуществ:
- Быстрая, беспроблемная генерация файла robots txtи помощь в SEO-оптимизации;
- Совместимость с Yoast SEO, WooCommerce и др.;
- Полный контроль над файлами-роботами txt wordpress;
- Поддержка 7+ языков;
- Защита ценных данных с помощью блокировки соответствующих источников и папок, а также зачистка спама;
- Обеспечение безопасности и конфиденциальности обратных ссылок.
Судя по перечню возможностей, это премиум плагин. Цена: некоторые функции являются бесплатными, остальные доступны в платной версии.
Yoast SEO
Считается лучшим плагином для оптимизации веб-сайтов, созданных на WordPress. Он имеет более 5 миллионов активных установок, и эффективно помогает создавать и редактировать роботс. На сегодняшний день – это самый популярный инструмент в мире.
Главные функции:
- Простая оптимизация блогов и сайтов любого типа;
- Упор на SEO, читабельность и «ключи»;
- Автоматическое создание файлов робота и sitemap без использования cPanel или FTP;
- Совместим с последней версией системы.
Цена: разработка и редакция robots txt доступны в бесплатной версии плагина, но имеется и ряд полезных опций в премиум-разделе.
DB Robots.txt
Данный плагин помогает генерировать правильный роботс для вордпресс в автоматическом режиме с созданием специальных правил для поисковых роботов Яндекса. Имеет более 200 активных установок, и совместим с последней версией WordPress.
Характеристики:
- Легкое создание и редактирование robots txt;
- Бесплатная автоматическая генерация robots.txt file для сайтов WordPress;
- Автодобавление карты веб-сайта;
- Создание правила для ПС Яндекс.
При работе с этим инструментом не требуется углубленных знаний разработки, так как он сам добавляет важные файлы и папки. Цена: бесплатно.
Multipart robots.txt editor
Помогает настроить ваши txt-файлы и добавлять в них свой контент. Данный плагин имеет более 7000 активных установок.
Есть много встроенных функций, предоставляемых бесплатно:
- Допускается включить или исключить файл роботов;
- Позволяет легко конфигурировать правильный роботс для вордпресс 2018;
- Совместим с плагинами sitemap;
- Используется одна команда Disallow;
- Включение/исключение удаленных файлов и пользовательских записей.
Этот инструмент WordPress Robots подходит практически для любого сайта WordPress. Цена: бесплатно.
Robots.txt rewrite
Этот плагин обеспечивает простую панель управления для создания файла роботов. Имеет 9000+ активных установок.
Преимущества:
- Упрощенное управление и настройка роботс;
- Помогает легко индексироваться в различных поисковых системах;
- Допускается разрешить или запретить любые файлы или папки;
- Беспроблемное внедрение sitemap в сайт или блог;
- Возможность установки задержки обхода контента.
Таким образом, использовать данный плагин для WordPress-сайта или блога, может даже начинающий разработчик. Цена: бесплатно.
Какие правила нужно включить в файл robots.txt для WordPress
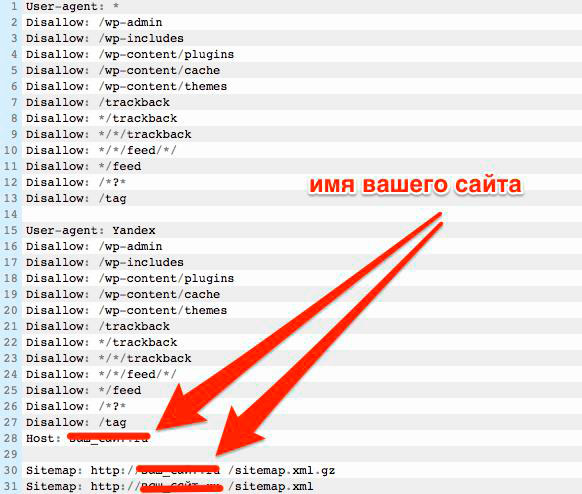
Базовый вариант файла robots.txt для WordPress выглядит так:
User-agent:
Disallow: /wp-admin/
Disallow: /wp-includes/
Каждая строка документа представляет собой отдельную директиву, то есть правило, которое относится к поисковикам.
«User-agent», это обращение к роботам поисковых систем. Если правило прописывается для всех поисковиков, перед ним нужно поставить знак «*».
«Disallow» указывает какую папку нужно роботам обходить при индексации. Наличие строки «Disallow: /wp-admin/» обеспечивает запрет индексации всего, что находится в папке «admin». Соответственно, строка «Disallow: /wp-includes/» запрещает скачивать для проверки папку «includes».
В документе можно оставлять комментарии, которые предназначены не для роботов, а для самого администратора сайта. Комментарии пишутся после знака «#». Все, что прописано после решетки роботы не читают.
Первой строкой прописывается директива «User-agent». Она показывает, к какому из поисковиков обращено следующее за не правило. Если после нее ставится звездочка, значит следующее правило обращено к роботам всех поисковых систем. Строка со значением «User-agent: Googlebot» – это обращение к поисковому роботу Google. Обращение к Яндексу начинается со значения «User-agent: Yandex».
«Disallow» обозначает, что прописанное правило имеет запрещающее содержание. «Allow» – это разрешающая директива.
Пример:
User-agent: *
Allow: /cgi-bin
Disallow: /
Составленный таким образом файл указывает на то, что поисковикам запрещается скачивать все, кроме тех страниц, названия которых начинаются со значения «cgi-bin».
Пустые переводы строк между «User-agent» и «Disallow (Allow)» недопустимы. Если оставить просто строку «Disallow: /», без исключений, прописанных после «Allow», то сайт окажется полностью закрытым для индексации. Но если при отсутствии «Allow» строка «Disallow» оставляется пустой (без значения /), то скачиваться будут абсолютно все страницы сайта.
Обычно от скачивания прячут папки с личной информацией, паролями и логинами. Скрыть эти три папки можно такой директивой:
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallw: /wp-includes/
Плагины и скрипты, не имеющие отношения к контенту тоже желательно скрыть. Для этого прописываются такие строки:
Disallow: /wp-content/plugins/
Disallow: /wp-content/cache/
Disallow: /wp-content/themes/
В случае с зеркалом сайта указать Яндексу основной домен очень просто – при помощи директивы «Host». Это делается в специальной строке, адресованной именно Яндексу. Для других поисковиков необходимо создать другую строку с запрещающей директивой.
Проверка robots.txt
Чтобы проверить правильность составленного файла – необходимо провести анализ. Для этого существуют два наиболее популярных инструмента:
Проверка robots.txt в Яндекс вебмастере или с помощью инструментов Google. ( Если вы еще не зарегистрировались в сервисах для Вебмастеров – советую это сделать незамедлительно. )
Я покажу как воспользоваться обеими вариантами, выбирайте сами какой больше нравиться. А еще лучше воспользуйтесь каждым, тем более это не займет больше пары минут.
Проверка с помощью Яндекс Вебмастера
Заходим в инструменты в левом меню, и выбираем первый пункт Анализ robots.txt:
Добавляем ссылку на проверяемый сайт, нажимаем кнопку загрузки, а затем проверить.

Немного ждем и смотрим Результаты анализа, в моем случае 0 ошибок.
Проверка с помощью Search Console
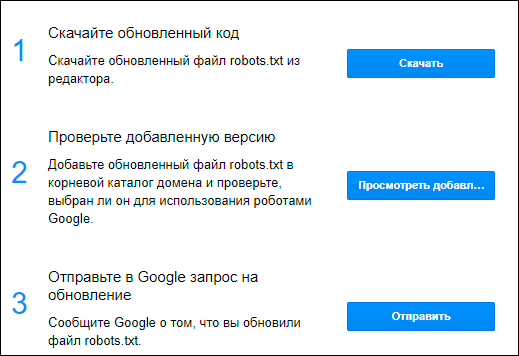
Заходим в Сканирование, выбираем раздел инструменты проверки файла:
Вставляем robots.txt и кликаем отправить.

В 3-ем пункте выбираем отправить и смотрим на количество ошибок.
Как выбрать робота, к которому вы обращаетесь?
User-agent — это обращение к определенному поисковому роботу. Помимо того, что у каждой поисковой системы свой робот (Яндекс, Google), так еще и в рамках одного поисковика есть десяток специфических роботов. Например, YandexBot — основной робот Яндекса, YandexMedia — робот, индексирующий мультимедиа — картинки, аудио, видео, YandexImages — специализированный индексатор картинок (в Яндекс-картинки). Есть даже специальные роботы, которые сканируют микроразметку сайта.
Но нам особо вдаваться в детали не надо, только запомните, что звездочкой (*) отмечается обращение ко всем поисковым роботам.
Пример Robots.txt для WordPress
Сразу хочу предупредить: не существует идеального файла, который подойдет абсолютно всем сайтам, работающим на ВордПресс! Не идите на поводу, слепо копируя содержимое файла без проведения анализа под ваш конкретный случай! Многое зависит от выбранных настроек постоянных ссылок, структуры сайта и даже установленных плагинов. Я рассматриваю пример, когда используется ЧПУ и постоянные ссылки вида .

WordPress, как и любая система управления контентом, имеет свои административные ресурсы, каталоги администрирования и прочее, что не должно попасть в индекс поисковых систем. Для защиты таких страниц от доступа необходимо запретить их индексацию в данном файле следующими строками:
Директива во второй строке закроет доступ по всем каталогам, начинающимся на , в их число входят:
- wp-admin
- wp-content
- wp-includes
Но мы знаем, что изображения по умолчанию загружаются в папку uploads, которая находится внутри каталога wp-content. Разрешим их индексацию строкой:
Служебные файлы закрыли, переходим к исключению дублей с основным содержимым, которые снижают уникальность контента в пределах одного домена и увеличивают вероятность наложения на сайт фильтра со стороны ПС. К дублям относятся страницы категорий, авторов, тегов, RSS-фидов, а также постраничная навигация, трекбеки и отдельные страницы с комментариями. Обязательно запрещаем их индексацию:
Далее хотелось бы уделить особое внимание такому аспекту как постоянные ссылки. Если вы используете ЧПУ, то страницы содержащие в URL знаки вопроса зачастую являются «лишними» и опять же дублируют основной контент
Такие страницы с параметрами следует запрещать аналогичным образом:
Это правило распространяется на простые постоянные ссылки , страницы с поисковыми запросами и другими параметрами. Ещё одной проблемой могут стать страницы архивов, содержащие в URL год, месяц. На самом деле их очень просто закрыть, используя маску , тем самым запрещая индексирование архивов по годам:
Для ускорения и полноты индексации добавим путь к расположению карты сайта. Робот обработает файл и при следующем посещении сайта будет его использовать для приоритетного обхода страниц.
В файле robots.txt можно разместить дополнительную информацию для роботов, повышающую качество индексации. Среди них директива — указывает на главное зеркало для Яндекса:
При работе сайта по HTTPS необходимо указать протокол:
С 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Подводя итог, я объединил всё выше сказанное воедино и получил содержимое файла robots.txt для WordPress, который использую уже несколько лет и при этом в индексе нет дублей:
Постоянно следите за ходом индексации и вовремя корректируйте файл в случае появления дублей.
От того правильно или нет составлен файл зависит очень многое, поэтому обратите особо пристальное внимание к его составлению, чтобы поисковики быстро и качественно индексировали сайт. Если у вас возникли вопросы — задавайте, с удовольствием отвечу!