Screaming frog seo spider update
Содержание:
- The SEO Spider Tool Crawls & Reports On…
- 5) XML Sitemap Improvements
- 1) Rendered Crawling (JavaScript)
- Linux
- 2) Gather keyword data
- Extract
- Crawl Overview Report
- TL;DR
- Scaling Force-Directed Digrams
- Viewing Crawl Data
- Smaller Updates & Fixes
- 2) Crawl New URLs Discovered In Google Analytics & Search Console
- Uploading A List
- Other Updates
- Other Updates
- 3) Improved Link Data – Link Position, Path Type & Target
- 8) Buy An External SSD With USB 3.0(+)
- Small Update – Version 3.3 Released 23rd March 2015
- 7) Updated SERP Snippet Emulator
The SEO Spider Tool Crawls & Reports On…
The Screaming Frog SEO Spider is an SEO auditing tool, built by real SEOs with thousands of users worldwide. A quick summary of some of the data collected in a crawl include —
- Errors – Client errors such as broken links & server errors (No responses, 4XX client & 5XX server errors).
- Redirects – Permanent, temporary, JavaScript redirects & meta refreshes.
- Blocked URLs – View & audit URLs disallowed by the robots.txt protocol.
- Blocked Resources – View & audit blocked resources in rendering mode.
- External Links – View all external links, their status codes and source pages.
- Security – Discover insecure pages, mixed content, insecure forms, missing security headers and more.
- URI Issues – Non ASCII characters, underscores, uppercase characters, parameters, or long URLs.
- Duplicate Pages – Discover exact and near duplicate pages using advanced algorithmic checks.
- Page Titles – Missing, duplicate, long, short or multiple title elements.
- Meta Description – Missing, duplicate, long, short or multiple descriptions.
- Meta Keywords – Mainly for reference or regional search engines, as they are not used by Google, Bing or Yahoo.
- File Size – Size of URLs & Images.
- Response Time – View how long pages take to respond to requests.
- Last-Modified Header – View the last modified date in the HTTP header.
- Crawl Depth – View how deep a URL is within a website’s architecture.
- Word Count – Analyse the number of words on every page.
- H1 – Missing, duplicate, long, short or multiple headings.
- H2 – Missing, duplicate, long, short or multiple headings
- Meta Robots – Index, noindex, follow, nofollow, noarchive, nosnippet etc.
- Meta Refresh – Including target page and time delay.
- Canonicals – Link elements & canonical HTTP headers.
- X-Robots-Tag – See directives issued via the HTTP Headder.
- Pagination – View rel=“next” and rel=“prev” attributes.
- Follow & Nofollow – View meta nofollow, and nofollow link attributes.
- Redirect Chains – Discover redirect chains and loops.
- hreflang Attributes – Audit missing confirmation links, inconsistent & incorrect languages codes, non canonical hreflang and more.
- Inlinks – View all pages linking to a URL, the anchor text and whether the link is follow or nofollow.
- Outlinks – View all pages a URL links out to, as well as resources.
- Anchor Text – All link text. Alt text from images with links.
- Rendering – Crawl JavaScript frameworks like AngularJS and React, by crawling the rendered HTML after JavaScript has executed.
- AJAX – Select to obey Google’s now deprecated AJAX Crawling Scheme.
- Images – All URLs with the image link & all images from a given page. Images over 100kb, missing alt text, alt text over 100 characters.
- User-Agent Switcher – Crawl as Googlebot, Bingbot, Yahoo! Slurp, mobile user-agents or your own custom UA.
- Custom HTTP Headers – Supply any header value in a request, from Accept-Language to cookie.
- Custom Source Code Search – Find anything you want in the source code of a website! Whether that’s Google Analytics code, specific text, or code etc.
- Custom Extraction – Scrape any data from the HTML of a URL using XPath, CSS Path selectors or regex.
- Google Analytics Integration – Connect to the Google Analytics API and pull in user and conversion data directly during a crawl.
- Google Search Console Integration – Connect to the Google Search Analytics API and collect impression, click and average position data against URLs.
- PageSpeed Insights Integration – Connect to the PSI API for Lighthouse metrics, speed opportunities, diagnostics and Chrome User Experience Report (CrUX) data at scale.
- External Link Metrics – Pull external link metrics from Majestic, Ahrefs and Moz APIs into a crawl to perform content audits or profile links.
- XML Sitemap Generation – Create an XML sitemap and an image sitemap using the SEO spider.
- Custom robots.txt – Download, edit and test a site’s robots.txt using the new custom robots.txt.
- Rendered Screen Shots – Fetch, view and analyse the rendered pages crawled.
- Store & View HTML & Rendered HTML – Essential for analysing the DOM.
- AMP Crawling & Validation – Crawl AMP URLs and validate them, using the official integrated AMP Validator.
- XML Sitemap Analysis – Crawl an XML Sitemap independently or part of a crawl, to find missing, non-indexable and orphan pages.
- Visualisations – Analyse the internal linking and URL structure of the website, using the crawl and directory tree force-directed diagrams and tree graphs.
- Structured Data & Validation – Extract & validate structured data against Schema.org specifications and Google search features.
- Spelling & Grammar – Spell & grammar check your website in over 25 different languages.
5) XML Sitemap Improvements
You’re now able to create XML Sitemaps with any response code, rather than just 200 ‘OK’ status pages. This allows flexibility to quickly create sitemaps for a variety of scenarios, such as for pages that don’t yet exist, that 301 to new URLs and you wish to force Google to re-crawl, or are a 404/410 and you want to remove quickly from the index.
If you have hreflang on the website set-up correctly, then you can also select to include hreflang within the XML Sitemap.

Please note – The SEO Spider can only create XML Sitemaps with hreflang if they are already present currently (as attributes or via the HTTP header). More to come here.
1) Rendered Crawling (JavaScript)
There were two things we set out to do at the start of the year. Firstly, understand exactly what the search engines are able to crawl and index. This is why we created the Screaming Frog Log File Analyser, as a crawler will only ever be a simulation of search bot behaviour.
Secondly, we wanted to crawl rendered pages and read the DOM. It’s been known for a long time that Googlebot acts more like a modern day browser, rendering content, crawling and indexing JavaScript and dynamically generated content rather well. The SEO Spider is now able to render and crawl web pages in a similar way.
You can choose whether to crawl the static HTML, obey the old AJAX crawling scheme or fully render web pages, meaning executing and crawling of JavaScript and dynamic content.

Google deprecated their old AJAX crawling scheme and we have seen JavaScript frameworks such as AngularJS (with links or utilising the HTML5 History API) crawled, indexed and ranking like a typical static HTML site. I highly recommend reading Adam Audette’s Googlebot JavaScript testing from last year if you’re not already familiar.
After much research and testing, we integrated the Chromium project library for our rendering engine to emulate Google as closely as possible. Some of you may remember the excellent ‘Googlebot is Chrome‘ post from Joshua G on Mike King’s blog back in 2011, which discusses Googlebot essentially being a headless browser.
The new rendering mode is really powerful, but there are a few things to remember –
- Typically crawling is slower even though it’s still multi-threaded, as the SEO Spider has to wait longer for the content to load and gather all the resources to be able to render a page. Our internal testing suggests Google wait approximately 5 seconds for a page to render, so this is the default AJAX timeout in the SEO Spider. Google may adjust this based upon server response and other signals, so you can configure this to your own requirements if a site is slower to load a page.
- The crawling experience is quite different as it can take time for anything to appear in the UI to start with, then all of a sudden lots of URLs appear together at once. This is due to the SEO Spider waiting for all the resources to be fetched to render a page before the data is displayed.
- To be able to render content properly, resources such as JavaScript and CSS should not be blocked from the SEO Spider. You can see URLs blocked by robots.txt (and the corresponding robots.txt disallow line) under ‘Response Codes > Blocked By Robots.txt’. You should also make sure that you crawl JS, CSS and external resources in the SEO Spider configuration.
It’s also important to note that as the SEO Spider renders content like a browser from your machine, so this can impact analytics and anything else that relies upon JavaScript.
By default the SEO Spider excludes executing of Google Analytics JavaScript tags within its engine, however, if a site is using other analytics solutions or JavaScript that shouldn’t be executed, remember to use the .
Linux
This screamingfrogseospider binary is placed in your path during installation. To run this open a terminal and follow the examples below.
To start normally:
screamingfrogseospider
To open a saved crawl file:
screamingfrogseospider /tmp/crawl.seospider
To see a full list of the command line options available:
screamingfrogseospider --help

To start the UI and immediately start crawling:
screamingfrogseospider --crawl https://www.example.com/
To start headless, immediately start crawling and save the crawl along with Internal->All and Response Codes->Client Error (4xx) filters:
screamingfrogseospider --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
In order to utilize JavaScript Rendering when running headless in Linux a display is required. You can use a Virtual Frame Buffer to simulate having a display attached. See full details here.
Please see the full list of command line options below.
2) Gather keyword data
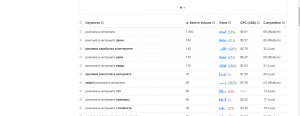
Next you’ll need to find relevant keywords where featured snippets and / or related questions are showing in the SERPs. Most well-known SEO intelligence tools have functionality to filter keywords you rank for (or want to rank for) and where these features show, or you might have your own rank monitoring systems to help. Failing that, simply run a few searches of important and relevant keywords to look for yourself, or grab query data from Google Search Console. Wherever you get your keyword data from, if you have a lot of data and are looking to prune and prioritise your keywords, I’d advise the following –
Prioritise keywords where you have a decent ranking position already. Not only is this relevant to winning a featured snippet (almost all featured snippets are taken from pages ranking organically in the top 10 positions, usually top 5), but more generally if Google thinks your page is already relevant to the query, you’ll have a better chance of targeting all types of search features.
Certainly consider search volume (the higher the better, right?), but also try and determine the likelihood of a search feature driving clicks too. As with keyword intent in the main organic results, not all search features will drive a significant amount of additional traffic, even if you achieve ‘position zero’. Try to consider objectively the intent behind a particular query, and prioritise keywords which are more likely to drive additional clicks.
Extract
Now that the tool can crawl and render our chosen URLs, we need to tell it what data we actually want to pull out, (i.e: those glorious PageSpeed scores).
Open up the custom extraction panel, (Configuration > Custom > Extraction) and enter in the following Xpath variables depending on which metrics you want to pull.

Desktop Estimated Input Latency
If done correctly you should have a nice green tick next to each entry, a bit like this:

(Be sure to add custom labels to each one, set the type to Xpath and change the far right drop down from extract HTML to extract text.)
(There are also quite a lot of variables so you may want to split your crawl by mobile & desktop or take a selection of metrics you wish to report on.)
Hit OK.
Crawl Overview Report
Under the new ‘reports’ menu discussed above, we have included a little ‘crawl overview report’. This does exactly what it says on the tin and provides an overview of the crawl, including total number of URLs encountered in the crawl, the total actually crawled, the content types, response codes etc with proportions. This will hopefully provide another quick easy way to analyse overall site health at a glance. Here’s a third of what the report looks like –
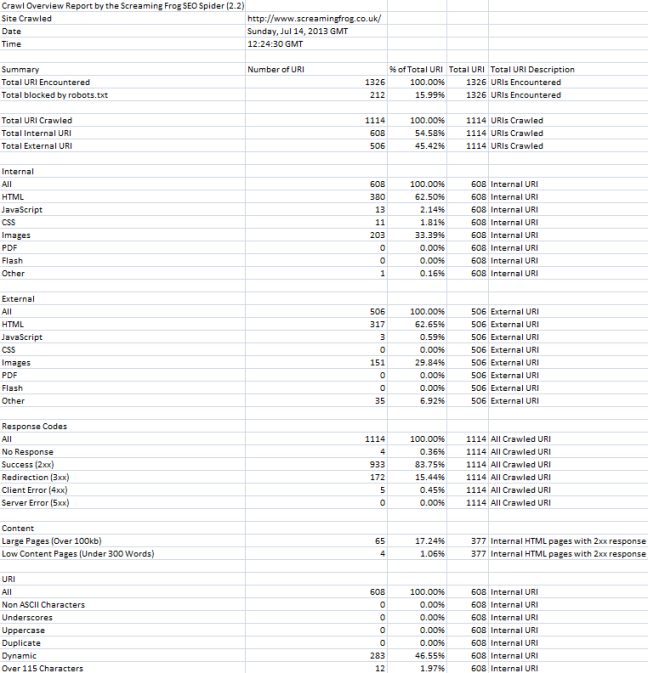
We have also changed the max page title length to 65 characters (although it seems now to be based on pixel image width), added a few more preset mobile user agents, fixed some bugs (such as large sitemaps being created over the 10Mb limit) and made other smaller tweaks along the way.
As always, we love any feedback and thank you again for all your support. Please do update your to try out all the new features.
TL;DR
If you’re already an XPath and scraping expert and are just here for the syntax and data type to setup your extraction (perhaps you saw me eloquently explain the process at SEOCamp Paris or Pubcon Las Vegas this year!), here you go (spoiler alert for everyone else!) –
Featured snippet page title (Text) –
Featured snippet text paragraph (Text) –
Featured snippet bullet point text (Text) –
Featured snippet numbered list (Text) –
Featured snippet table (Text) –
Featured snippet URL (Inner HTML) –
Featured snippet image source (Text) –
Related questions XPath syntax
Related question 1 text (Text) –
Related question 2 text (Text) –
Related question 3 text (Text) –
Related question 4 text (Text) –
Related question snippet text for all 4 questions (Text) –
Related question page titles for all 4 questions (Text) –
Related question page URLs for all 4 questions (Inner HTML) –
You can also get this list in . Back to our regularly scheduled programming for the rest of you…follow these steps to start scraping featured snippets and related questions!
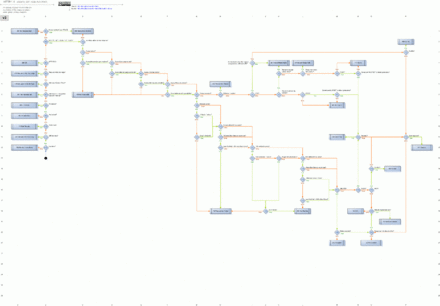
Scaling Force-Directed Digrams
Both the ‘force-directed crawl diagram’ and ‘force-directed directory tree diagram’ can be scaled by different metrics (by clicking on the cog icon). As described above, the size and colouring of the nodes are scaled by crawl depth, or URL path respectively.
However, both diagrams can be scaled by other items such as – unique inlinks, Link Score (PageRank), or external metrics like Moz Page Authority or Ahrefs URL Rating for example.

This means diagrams can be configured to visualise which URLs on a website have the highest authority (including external link metrics, not just internal links), by using Ahrefs URL Rating, as an example. For our website, the SEO Spider page is the most linked to and authoritative page.

Or alternatively, to only consider internal links, then Link Score represents internal PageRank throughout the site.

Both of the above examples can help visualise key pages and sections of a site that have most authority, and those that require improvement with better linking.
Viewing Crawl Data
Data from the crawl populates in real-time within the SEO Spider and is displayed in tabs. The ‘‘ tab includes all data discovered in a crawl for the website being crawled. You can scroll up and down, and to the right to see all the data in various columns.

The tabs focus on different elements and each have filters that help refine data by type, and by potential issues discovered.
The ‘Response Codes’ tab and ‘Client Error (4xx) filter will show you any 404 pages discovered for example.

You can click on URLs in the top window and then on the tabs at the bottom to populate the lower window pane.
These tabs provide more detail on the URL, such as their inlinks (the pages that link to them), outlinks (the pages they link out to), images, resources and more.

In the example above, we can see inlinks to a broken link discovered during the crawl.
Smaller Updates & Fixes
That’s the main features for our latest release, which we hope you find useful. Other bug fixes and updates in this release include the following –
- The Analytics and Search Console tabs have been updated to allow URLs blocked by robots.txt to appear, which we believe to be HTML, based upon file type.
- The maximum number of Google Analytics metrics you can collect from the API has been increased from 20 to 30. Google restrict the API to 10 metrics for each query, so if you select more than 10 metrics (or multiple dimensions), then we will make more queries (and it may take a little longer to receive the data).
- With the introduction of the new ‘Accept-Language’ configuration, the ‘User-Agent’ configuration is now under ‘Configuration > HTTP Header > User-Agent’.
- We added the ‘MJ12Bot’ to our list of preconfigured user-agents after a chat with our friends at Majestic.
- Fixed a crash in XPath custom extraction.
- Fixed a crash on start up with Windows Look & Feel and JRE 8 update 60.
- Fixed a bug with character encoding.
- Fixed an issue with Excel file exports, which write numbers with decimal places as strings, rather than numbers.
- Fixed a bug with Google Analytics integration where the use of hostname in some queries was causing ‘Selected dimensions and metrics cannot be queried together errors’.
2) Crawl New URLs Discovered In Google Analytics & Search Console
If you connect to or via the API, by default any new URLs discovered are not automatically added to the queue and crawled. URLs are loaded, data is matched against URLs in the crawl, and any orphan URLs (URLs discovered only in GA or GSC) are available via the ‘‘ report export.
If you wish to add any URLs discovered automatically to the queue, crawl them and see them in the interface, simply enable the ‘Crawl New URLs Discovered in Google Analytics/Search Console’ configuration.

This is available under ‘Configuration > API Access’ and then either ‘Google Analytics’ or ‘Google Search Console’ and their respective ‘General’ tabs.
This will mean new URLs discovered will appear in the interface, and orphan pages will appear under the respective filter in the Analytics and Search Console tabs (after performing ).

Uploading A List
When you’re in list mode (Mode > List), just click the ‘Upload’ button and choose to upload from a file, enter into a dialog box, paste a list of URLs or download an XML Sitemap.

It’s that simple. But there are a couple of initial things you should be aware of in list mode when uploading URLs.
Protocol Required
If you don’t include either HTTP or HTTPS (e.g, just www.screamingfrog.co.uk/), the URL won’t be read and uploaded.

You’ll see a very sad message saying ‘found 0 URLs’. So always include the URL with protocol, for example –
Normalisation & De-Duplication
The SEO Spider normalises URLs on upload, and de-dupes during the crawl. Let’s say you have the following 4 URLs to upload for example –
The SEO Spider will automatically determine how many are unique URLs to be crawled.
For a small list, it’s easy to see (for most SEOs) that these 4 URLs are actually only 2 unique URLs, but with larger lists, it can be less obvious.
The SEO Spider page is duplicated, while the fragment URL (with a ‘#’) is not seen as a separate unique URL, so it’s normalised upon upload.
If these URLs are uploaded into the SEO Spider, it will report that it’s found the 4 URLs – and normalise them in the window dialog –

However, upon crawling it will only crawl the unique URLs (2 in this case).

Although it’s only crawled 2 unique URLs from the 4 uploaded, you are still able to export your original uploaded list in the same order.
Other Updates
Version 8.0 also includes a number of smaller updates, which include –
- The ‘Internal’ tab now has new columns for ‘Unique Inlinks’, ‘Unique Outlinks’ and ‘Unique External Outlinks’ numbers. The unique number of ‘inlinks’ was previously only available within the ‘Site Structure’ tab and displays a percentage of the overall number of pages linking to a page.
- A new ‘Noindex Confirmation Links’ filter is available within the ‘Hreflang’ tab and corresponding export in the ‘Reports > Hreflang > Noindex Confirmation Links’ menu.
- An ‘Occurences’ column has been added to the Hreflang tab to count the number on each page and identify potential problems.
- A new ‘Encoded URL’ column has been added to ‘Internal’ and ‘Response Codes’ tab.
- The ‘Level’ column has been renamed to ‘Crawl Depth’ to avoid confusion & support queries.
- There’s a new ‘External Links’ export under the ‘Bulk Export’ top level menu, which provides all source pages with external links.
- The SERP Snippet tool has been updated to refine pixel widths within the SERPs.
- Java is now bundled with the SEO Spider, so it doesn’t have to be downloaded separately anymore.
- Added a new preset user-agent for SeznamBot (for a search engine in the Czech Republic). Thanks to Jaroslav for the suggestion.
- The insecure content report now includes hreflang and rel=“next” and rel=“prev” links.
- You can highlight multiple rows, right click and open them all in a browser now.
- List mode now supports Sitemap Index files (alongside usual sitemap .xml files).
We also fixed up some bugs.
- Fixed a couple of crashes in JavaScript rendering.
- Fixed parsing of query strings in the canonical HTTP header.
- Fixed a bug with missing confirmation links of external URLs.
- Fixed a few crashes in Xpath and in GA integration.
- Fixed filtering out custom headers in rendering requests, causing some rendering to fail.
If you spot any bugs, or have any issues, then please do get in touch with us via support.
We’re now starting work on version 9.0, which has a couple of very big features we’re already excited about. Thanks to everyone for all their feedback, suggestions and continued support. There’s lots more to come!
Now go and download version 8.0 of the SEO Spider.
I also wanted to say a quick thank you to our friends at Jolt hosting, for working hard to keep the server online yesterday! If you’re experiencing any problems downloading, do let us know via .
Other Updates
Version 13.0 also includes a number of smaller updates and bug fixes, outlined below.
- The has been updated with the new Core Web Vitals metrics (Largest Contentful Paint, First Input Delay and Cumulative Layout Shift). ‘Total Blocking Time’ Lighthouse metric and ‘Remove Unused JavaScript’ opportunity are also now available. Additionally, we’ve introduced a new ‘JavaScript Coverage Summary’ report under ‘Reports > PageSpeed’, which highlights how much of each JavaScript file is unused across a crawl and the potential savings.
- Following the Log File Analyser version 4.0, the SEO Spider has been updated to Java 11. This means it can only be used on 64-bit machines.
- iFrames can now be stored and crawled (under ‘Config > Spider > Crawl’).
- Fragments are no longer crawled by default in JavaScript rendering mode. There’s a new ‘Crawl Fragment Identifiers’ configuration under ‘Config > Spider > Advanced’ that allows you to crawl URLs with fragments in any rendering mode.
- A tonne of Google features for structured data validation have been updated. We’ve added support for COVID-19 Announcements and Image Licence features. Occupation has been renamed to Estimated Salary and two deprecated features, Place Action and Social Profile, have been removed.
- All Hreflang ‘confirmation links’ named filters have been updated to ‘return links’, as this seems to be the common naming used by Google (and who are we to argue?). Check out our How To Audit Hreflang guide for more detail.
- Two ‘AMP’ filters have been updated, ‘Non-Confirming Canonical’ has been renamed to ‘Missing Non-AMP Return Link’, and ‘Missing Non-AMP Canonical’ has been renamed to ‘Missing Canonical to Non-AMP’ to make them as clear as possible. Check out our How To Audit & validate AMP guide for more detail.
- The ‘Memory’ configuration has been renamed to ‘Memory Allocation’, while ‘Storage’ has been renamed to ‘Storage Mode’ to avoid them getting mixed up. These are both available under ‘Config > System’.
- Custom Search results now get appended to the Internal tab when used.
- The Forms Based Authentication browser now shows you the URL you’re viewing to make it easier to spot sneaky redirects.
- Deprecated APIs have been removed for the .
That’s everything. If you experience any problems, then please do just let us know via our support and we’ll help as quickly as possible.
Thank you to everyone for all their feature requests, feedback, and bug reports. Apologies for anyone disappointed we didn’t get to the feature they wanted this time. We prioritise based upon user feedback (and a little internal steer) and we hope to get to them all eventually.
Now, go and download version 13.0 of the Screaming Frog SEO Spider and let us know what you think!
3) Improved Link Data – Link Position, Path Type & Target
Some of our most requested features have been around link data. You want more, to be able to make better decisions. We’ve listened, and the SEO Spider now records some new attributes for every link.
Link Position
You’re now able to see the ‘link position’ of every link in a crawl – such as whether it’s in the navigation, content of the page, sidebar or footer for example. The classification is performed by using each link’s ‘link path’ (as an XPath) and known semantic substrings, which can be seen in the ‘inlinks’ and ‘outlinks’ tabs.

If your website uses semantic HTML5 elements (or well-named non-semantic elements, such as div id=”nav”), the SEO Spider will be able to automatically determine different parts of a web page and the links within them.

But not every website is built in this way, so you’re able to configure the link position classification under ‘Config > Custom > ‘. This allows you to use a substring of the link path, to classify it as you wish.
For example, we have mobile menu links outside the nav element that are determined to be in ‘content’ links. This is incorrect, as they are just an additional sitewide navigation on mobile.

The ‘mobile-menu__dropdown’ class name (which is in the link path as shown above) can be used to define its correct link position using the Link Positions feature.

These links will then be correctly attributed as a sitewide navigation link.

This can help identify ‘inlinks’ to a page that are only from in-body content, for example, ignoring any links in the main navigation, or footer for better internal link analysis.
Path Type
The ‘path type’ of a link is also recorded (absolute, path-relative, protocol-relative or root-relative), which can be seen in inlinks, outlinks and all bulk exports.

This can help identify links which should be absolute, as there are some integrity, security and performance issues with relative linking under some circumstances.
Target Attribute
Additionally, we now show the ‘target’ attribute for every link, to help identify links which use ‘_blank’ to open in a new tab.

This is helpful when analysing usability, but also performance and security – which brings us onto the next feature.
8) Buy An External SSD With USB 3.0(+)
If you don’t have an internal SSD and you’d like to crawl large websites using database storage mode, then an external SSD can help.
It’s important to ensure your machine has USB 3.0 port and your system supports UASP mode. Most new systems do automatically, if you already have USB 3.0 hardware. When you connect the external SSD, ensure you connect to the USB 3.0 port, otherwise reading and writing will be very slow.
USB 3.0 ports generally have a blue inside (as recommended in their specification), but not always; and you will typically need to connect a blue ended USB cable to the blue USB 3.0 port. After that, you need to switch to database storage mode, and then select the database location on the external SSD (the ‘D’ drive in the example below).

Simple!
Small Update – Version 3.3 Released 23rd March 2015
We have just released another small update to version 3.3 of the Screaming Frog SEO Spider. Similar to the above, this is just a small release with a few updates, which include –
- Fixed a relative link bug for URLs.
- Updated the right click options for ‘Show Other Domains On This IP’, ‘Check Index > Yahoo’ and OSE to a new address.
- CSV files now don’t include a BOM (Byte Order Mark). This was needed before we had excel export integration. It causes problems with some tools parsing the CSV files, so has been removed, as suggested by Kevin Ellen.
- Fixed a couple of crashes when using the right click option.
- Fixed a bug where images only linked to via an HREF were not included in a sitemap.
- Fixed a bug effecting users of 8u31 & JDK 7u75 and above trying to connect to SSLv3 web servers.
- Fixed a bug with handling of mixed encoded links.
You can download the SEO Spider 3.3 now.
Thanks to everyone for all their comments on the latest version and feeback as always.
7) Updated SERP Snippet Emulator
Google increased the average length of SERP snippets significantly in November last year, where they jumped from around 156 characters to over 300. Based upon our research, the default max description length filters have been increased to 320 characters and 1,866 pixels on desktop within the SEO Spider.
The lower window has also been updated to reflect this change, so you can view how your page might appear in Google.

It’s worth remembering that this is for desktop. Mobile search snippets also increased, but from our research, are quite a bit smaller – approx. 1,535px for descriptions, which is generally below 230 characters. So, if a lot of your traffic and conversions are via mobile, you may wish to update your max description preferences under ‘Config > Spider > Preferences’. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop.
As outlined previously, the SERP snippet emulator might still be occasionally a word out in either direction compared to what you see in the Google SERP due to exact pixel sizes and boundaries. Google also sometimes cut descriptions off much earlier (particularly for video), so please use just as an approximate guide.