Файл robots.txt
Содержание:
- Нужен ли вам файл robots.txt?
- Как создать файл robots.txt на своем сайте?
- Написание и проверка robots.txt
- Для чего нужна проверка robots.txt
- Индексация сайта
- Robots.txt для Яндекса и Google
- Important facts about the robots.txt file
- Особенности работы с поисковыми ботами
- Правильный Robots.txt для Bitrix
- Директивы robots.txt
- Заключение: советы Вебмастерам
Нужен ли вам файл robots.txt?
Многим сайтам, особенно маленьким, не обязательно иметь файл robots.txt.
Тем не менее, нет причины полностью от него отказываться. Он дает вам больше контроля над тем, куда поисковые системы могут и не могут заходить, и это может помочь с такими вещами, как:
- Избежать сканирования дублированного контента;
- Скрыть от индексации части сайта (например, когда сайт в разработке);
- Избежать сканирования страниц с результатами внутреннего поиска;
- Предотвратить перегрузку сервера;
- Избежать растрачивания “краулингового бюджета.”
- Скрыть от индексации картинки, и другие файлы.
Обратите внимание, что хотя Google обычно не индексирует веб-страницы, скрытые в файле robots.txt, это не гарантия того, что эти страницы не появятся в результатах поиска. Как говорят в Google, если на контент ссылаются с других страниц в интернете, он может появиться в результатах поиска Google
Как говорят в Google, если на контент ссылаются с других страниц в интернете, он может появиться в результатах поиска Google.
Как создать файл robots.txt на своем сайте?
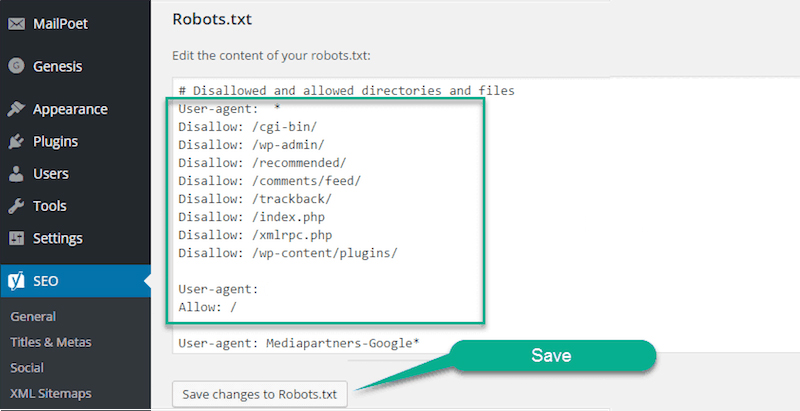
Для того, чтобы создать файл robots.txt, вам нужно открыть любой текстовый редактор, например, Блокнот, MS Word, SublimeText, NotePad++ и т.п. Прописать необходимые инструкции для вашего сайта и сохранить файл в формате .txt.
Далее данный файл необходимо загрузить в корневую директорию вашего сайта. Корневая директория, это папка, как правило, с названием вашего сайта в которой находятся файлы вашей CMS и индексный файл index.html. Загрузить файл robotx.txt на сервер можно с помощью панели управления сервером (напр. ISPmanager, Cpannel), с помощью FTP-клиента (напр. FileZilla, TotalCommander), через консоль, либо через административную панель сайта, если CMS позволяет это сделать.
Некоторые системы управления сайтами имеют встроенный функционал, который позволяет создать robots.txt из админки сайта, либо с помощью дополнительных плагинов или модулей. Каким способом создавать robots.txt — нет абсолютно никакой разницы. Проверить корректность и доступность вашего файла robots вы можете с помощью сервиса в Яндекс.Вебмастере.
Написание и проверка robots.txt
Теперь вы знаете, какими директивами и как пользоваться. Переходите к написанию файла:
- Откройте текстовый редактор, к примеру, Блокнот.
- Пропишите содержимое.
- Сохраните документ с именем robots в формате txt.
- Опубликуйте файл в корневой каталог.
Не загружайте готовый robots.txt сразу на веб-сайт. Сначала сделайте его проверку одним из методов:
- В Google Search Console. Для этого нужно открыть «Сканирование» – «Инструмент проверки файла robots.txt». Потом вставляем содержимое robots.txt в указанное поле и задаём адрес веб-сайта. Кликаем «Проверить».
Google автоматически укажет вам на имеющиеся ошибки и покажет предупреждения. При наличии таковых нужно внести корректировки. Кроме того, пользуясь инструментами системы, вы можете получать уведомления о появившихся ошибках – они будут доступны в админке Console.
- В Яндекс.Вебмастер. Откройте «Инструменты» – «Анализ robots.txt». Всё происходит аналогично предыдущему способу – вводим адрес веб-сайта, копируем и вставляем содержимое написанного файла. Кликаем «Проверить» и получаем результаты – ошибки и предупреждения.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Индексация сайта
Упомянутые выше инструменты очень важны для успешного развития вашего проекта, и это вовсе не голословное утверждение. В статье про Sitemap xml (см
ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров, там на втором и третьем месте (после не уникального контента) находятся как раз отсутствие этих файлов роботс и сайтмап, либо их неправильное составление и использование
Почему так важно управлять индексацией сайта
Надо очень четко понимать, что при использовании CMS (движка) не все содержимое сайта должно быть доступно роботам поисковых систем. Почему?
- Ну, хотя бы потому, что, потратив время на индексацию файлов движка вашего сайта (а их может быть тысячи), робот поисковика до основного контента сможет добраться только спустя много времени. Дело в том, что он не будет сидеть на вашем ресурсе до тех пор, пока его полностью не занесет в индекс. Есть лимиты на число страниц и исчерпав их он уйдет на другой сайт. Адьес.
- Если не прописать определенные правила поведения в роботсе для этих ботов, то в индекс поисковиков попадет множество страниц, не имеющих отношения к значимому содержимому ресурса, а также может произойти многократное дублирование контента (по разным ссылкам будет доступен один и тот же, либо сильно пересекающийся контент), что поисковики не любят.
Хорошим решением будет запрет всего лишнего в robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв). С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Представляет он из себя обычный текстовый файл, который вы сможете создать и в дальнейшем редактировать в любом текстовом редакторе (например, Notepad++).
Поисковый бот будет искать этот файл в корневом каталоге вашего ресурса и если не найдет, то будет загонять в индекс все, до чего сможет дотянуться. Поэтому после написания требуемого роботса, его нужно сохранить в корневую папку, например, с помощью Ftp клиента Filezilla так, чтобы он был доступен к примеру по такому адресу:
https://ktonanovenkogo.ru/robots.txt
Кстати, если вы хотите узнать как выглядит этот файл у того или иного проекта в сети, то достаточно будет дописать к Урлу его главной страницы окончание вида . Это может быть полезно для понимания того, что в нем должно быть.
Однако, при этом надо учитывать, что для разных движков этот файл будет выглядеть по-разному (папки движка, которые нужно запрещать индексировать, будут называться по-разному в разных CMS). Поэтому, если вы хотите определиться с лучшим вариантом роботса, допустим для Вордпресса, то и изучать нужно только блоги, построенные на этом движке (и желательно имеющие приличный поисковый трафик).
Как можно запретить индексацию отдельных частей сайта и контента?
Прежде чем углубляться в детали написания правильного файла robots.txt для вашего сайта, забегу чуть вперед и скажу, что это лишь один из способов запрета индексации тех или иных страниц или разделов вебсайта. Вообще их три:
Большинство роботов хорошо спроектированы и не создают каких-либо проблем для владельцев сайтов. Но если бот написан дилетантом или «что-то пошло не так», то он может создавать существенную нагрузку на сайт, который он обходит. Кстати, пауки вовсе на заходят на сервер подобно вирусам — они просто запрашивают нужные им страницы удаленно (по сути это аналоги браузеров, но без функции просмотра страниц).
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Important facts about the robots.txt file
Keep in mind that robots can ignore your robots.txt file, especially abusive bots like those run by hackers looking for security vulnerabilities.
Also, if you are trying to hide a folder from your website, then just putting it in the robots.txt file may not be a smart approach.
Anyone can see the robots.txt file if they type it into their browser and may be able to figure out what you are trying to hide that way.
In fact, you can look at some popular sites to see how their robots.txt files are set up. Just try adding /robots.txt to the home page URL of your favorite websites.
If you want to make sure that your robots.txt file is working, you can use Google Search Console to test it. Here are instructions.
Особенности работы с поисковыми ботами
Чтобы индексация сайта поисковыми роботами происходила быстро и эффективно, необходимо:
Кроме ошибок в robots.txt, медленной скорости загрузки сайта и блокировки в .htaccess, причинами плохой индексации могут быть:
3.1. Высокая нагрузка на сервер при посещениях роботов
Индексация ботами поисковых систем крайне важна для продвижения, однако в некоторых ситуациях она может перегружать сервер, либо под видом роботов сайт могут атаковать хакеры. Чтобы знать цели, с которыми боты обращаются к ресурсу, и отслеживать возможные проблемы, проверяйте логи сервера и динамику серверной нагрузки в панели хостинг-провайдера. Критические значения могут свидетельствовать о проблемах, связанных с активным доступом к сайту поисковых роботов.
Когда роботы перегружают сервер слишком активными запросами к сайту, можно снизить их скорость обхода. Как это сделать, узнайте из справок и .
3.2. Проблемы из-за доступа фейковых ботов к сайту
Бывает, что под видом ботов Google к сайту пытаются получить доступ спамеры или хакеры. Если возникла такая проблема, проверьте, действительно ли сайт сканирует поисковый робот Google:
-
В логах сервера хостинг-провайдера скопируйте IP-адрес, с которого был сделан запрос к сайту.
-
Проверьте данный IP с помощью сервиса MyIp.
-
Затем проверьте адрес, указанный в строке IP Reverse DNS (Host).
Полученный IP-адрес должен совпадать с исходным в логах сервера, иначе это говорит о том, что имя бота поддельное. В данном случае сайт действительно сканировал Googlebot Аналогично проверяются и вызвавшие подозрения боты Яндекса.
Узнайте о других причинах плохой индексации из нашего поста «Почему поисковые роботы и Netpeak Spider не сканируют ваш сайт».
Чтобы узнать, как тот или иной поисковый бот сканирует ваш сайт, воспользуйтесь краулером Netpeak Spider, который позволяет имитировать поведение робота. Для анализа необходимо:
-
Открыть настройки «Продвинутые» и выбрать шаблон «По умолчанию: бот» → он предполагает учёт всех инструкций по сканированию и индексации.
-
Перейти на вкладку «User Agent» и из списка ботов выбрать нужного.
- Начать сканирование и по окончании ознакомиться с полученными данными.
3.3. Список ботов поисковых систем
Поисковые системы используют различные типы роботов: для индексации обычных страниц, новостей, изображений, фавиконов и прочих типов контента. Список IP-адресов, которые используют боты поисковиков, постоянно меняется и не разглашается.
3.2.1. Роботы Google
Полный список роботов Google можно посмотреть в справке. Рассмотрим наиболее популярных ботов:
- Googlebot — к ним относятся краулеры двух типов: для десктопных и мобильных версий стандартных сайтов. С июля 2019 года для новых и адаптированных под мобильные устройства сайтов включено приоритетное сканирование мобильных версий, соответственно большинство запросов будут обрабатывать мобильные боты.
-
Googlebot Images — поисковый робот для индексации изображений. При желании можно запретить индексацию всех картинок на сайте с помощью такой директивы в robots.txt:
User-agent: Googlebot-Image
Disallow: / - Googlebot News — бот, добавляющий материалы в Google Новости.
- Googlebot Video — робот, индексирующий видеоконтент.
- Google Favicon — краулер, собирающий фавиконы сайтов.
- APIs-Google — агент пользователя для отправки PUSH-уведомлений. Такие уведомления используются, чтобы веб-разработчики могли быстро получить информацию о каких-либо изменениях на сайтах без излишней нагрузки серверов Google.
- AdsBot Mobile Web Android, AdsBot Mobile Web, AdsBot — краулеры, проверяющие качество рекламы на различных типах устройств.
3.2.2. Роботы Яндекс
У Яндекса тоже обширный список ботов, который можно детально изучить в Яндекс.Помощи. Расскажу о некоторых из них:
- Основной робот, индексирующий страницы, — YandexBot/3.0. Указания боту можно указывать с помощью директив в robots.txt.
- Бот, скачивающий страницы для проверки их доступности, — YandexAccessibilityBot/3.0. Этот краулер игнорирует команды в файле robots.txt.
- Робот, определяющий зеркала проектов, — YandexBot/3.0; MirrorDetector.
- Бот, индексирующий картинки, — YandexImages/3.0.
- Бот, который скачивает фавиконы сайтов. — YandexFavicons/1.0.
- Краулер, индексирующий мультимедийный контент, — YandexMedia/3.0.
- Бот, собирающий материалы для Яндекс.Новостей, — YandexNews/4.0.
- Краулеры Яндекс.Метрики — YandexMetrika/2.0, YandexMetrika/3.0.
Правильный Robots.txt для Bitrix
Код для Robots, который прописан ниже, является базовым, универсальным для любого сайта на битриксе. В то же время, нужно понимать, что у вашего сайта могут быть свои индивидуальные особенности, и этот файл потребуется скорректировать в вашем конкретном случае.
User-agent: * # правила для всех роботов Disallow: /cgi-bin # папка на хостинге Disallow: /bitrix/ # папка с системными файлами битрикса Disallow: *bitrix_*= # GET-запросы битрикса Disallow: /local/ # папка с системными файлами битрикса Disallow: /*index.php$ # дубли страниц index.php Disallow: /auth/ # авторизация Disallow: *auth= # авторизация Disallow: /personal/ # личный кабинет Disallow: *register= # регистрация Disallow: *forgot_password= # забыли пароль Disallow: *change_password= # изменить пароль Disallow: *login= # логин Disallow: *logout= # выход Disallow: */search/ # поиск Disallow: *action= # действия Disallow: *print= # печать Disallow: *?new=Y # новая страница Disallow: *?edit= # редактирование Disallow: *?preview= # предпросмотр Disallow: *backurl= # трекбеки Disallow: *back_url= # трекбеки Disallow: *back_url_admin= # трекбеки Disallow: *captcha # каптча Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров Disallow: *?ei= Disallow: *?p= Disallow: *?q= Disallow: *?tags= Disallow: *B_ORDER= Disallow: *BRAND= Disallow: *CLEAR_CACHE= Disallow: *ELEMENT_ID= Disallow: *price_from= Disallow: *price_to= Disallow: *PROPERTY_TYPE= Disallow: *PROPERTY_WIDTH= Disallow: *PROPERTY_HEIGHT= Disallow: *PROPERTY_DIA= Disallow: *PROPERTY_OPENING_COUNT= Disallow: *PROPERTY_SELL_TYPE= Disallow: *PROPERTY_MAIN_TYPE= Disallow: *PROPERTY_PRICE= Disallow: *S_LAST= Disallow: *SECTION_ID= Disallow: *SECTION= Disallow: *SHOWALL= Disallow: *SHOW_ALL= Disallow: *SHOWBY= Disallow: *SORT= Disallow: *SPHRASE_ID= Disallow: *TYPE= Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Disallow: *from= # ссылки с метками from Allow: */upload/ # открываем папку с файлами uploads Allow: /bitrix/*.js # здесь и далее открываем для индексации скрипты Allow: /bitrix/*.css Allow: /local/*.js Allow: /local/*.css Allow: /local/*.jpg Allow: /local/*.jpeg Allow: /local/*.png Allow: /local/*.gif # Укажите один или несколько файлов Sitemap Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал # Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают. Host: www.site.ru
В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Директивы robots.txt
Порядок включения директив:
|
<Директива><двоеточие><пробел><документ, к которому применяется директива> |
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent – указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс – Yandex (, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google – Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится – «*»
Disallow – директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
 Рис. 1 Директива Disallow
Рис. 1 Директива Disallow
Allow – директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
Стоит обратить внимание на : «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
 Рис. 2 Директива Allow
Рис. 2 Директива Allow
Sitemap – директива для указания пути к файлу xml-карты сайта.
Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
|
User-agent: * Sitemap: http://site.ru/sitemap-1.xml Sitemap: http://site.ru/sitemap-2.xml |
Спецсимволы
- * — означает любую последовательность символов. Добавляется по умолчанию к концу каждой директивы (красная стрелочка на рисунке 3).
- $ — используется для отмены знака «*» на конце директивы (синяя стрелочка на рисунке 3).
- # — знак описания комментариев. Все что указывается справа от этого знака не будет учитываться роботами.

Рис. 3 Спецсимволы
Host – директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
- Данная директива может склеить не только зеркала вида www.site.ru и site.ru но и другие сайты, в robots.txt которых указан соответствующий Host.
- Если зеркало доступно только по защищенному протоколу, указывается адрес с протоколом (https://site.ru). В других случаях протокол не указывается.
- Для настройки главного зеркала в поисковой системе Google используется функция «Настройки сайта» в Google Search Console.
Crawl-delay – директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
Clean-param – директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
 Рис. 4 Clean-param
Рис. 4 Clean-param
Заключение: советы Вебмастерам
Совет #1
Если ваш сайт не индексируется поисковыми системами, или его страницы начали массово пропадать из поисковой выдачи, первым делом необходимо проверить файл robots.txt на предмет запрета индексации сайта. При необходимости снимите запрет на полезные страницы, которые должны участвовать в выдаче.
Если файл robots.txt не запрещает индексирование сайта, проверьте содержимое мета-тегов в head вашего сайта, адресованных поисковым роботам
Обратите внимание на наличие на вашем сайте следующих тегов:
<meta name="robots" content="noindex"/> — запрещает индексировать содержимое страницы <meta name="robots" content="nofollow"/> — запрещает переходить по ссылкам на странице <meta name="robots" content="none"/> — запрещает переходить по ссылкам и индексировать содержимое страницы <meta name="robots" content="noindex, nofollow"/> — аналогичен предыдущему тегу
Наличие данных тегов может негативно повлиять на представление вашего сайта в поисковых системах.
Совет #2
Хотя бы 1 раз в 2-3 недели заглядывайте в Яндекс Вебмастер в разделы «Индексирование — Статистика обхода» и «Индексирование — Страницы в поиске». Отслеживайте страницы, которые обходит поисковый робот на вашем сайте.
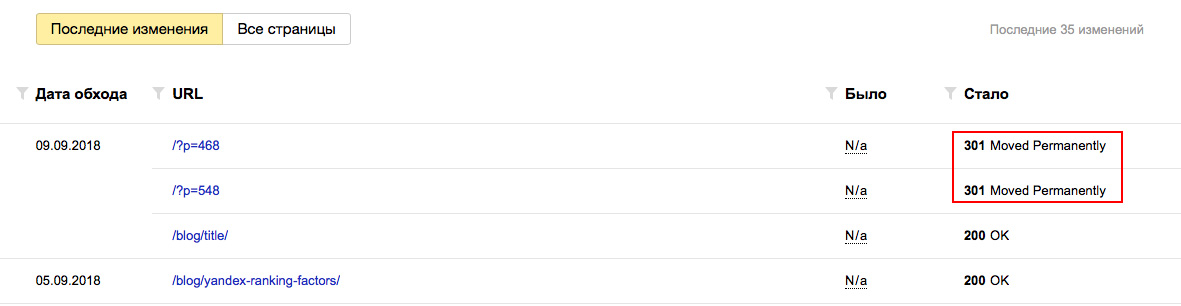
Если робот обходит технические страницы, или страницы, которые отвечают редиректом, их следуют запретить директивой Disallow в robots.txt. Таким образом вы сузите объем страниц, который необходимо обойти поисковому роботу и повысите эффективность индексации своего сайта.

Аналогична ситуация с разделом «Страницы в поиске». С его помощью вы можете не только отследить документы, которые больше не участвуют в поиске, но и проверить свой сайт на предмет наличия поискового спама. Если в данном разделе вы также найдете технические страниц, либо сервисные страницы с параметрами, которые не должны принимать участие в ранжировании, добавьте запрет на их обход в robots.txt.
Заключение
Файл robots.txt является одним из важнейших инструментов SEO-оптимизации. Через него можно напрямую влиять на индексирование абсолютно любых страниц и разделов сайта. Грамотно составленный robots.txt поможет вам сэкономить место в ограниченном краулинговом бюджете, избавит поисковые роботы от переобхода сотен ненужных технических страниц, избавит выдачу от поискового спама, а ваш сервер от излишней нагрузки. Создавайте robots.txt с умом!