Модуль threading на примерах
Содержание:
- RLock Objects¶
- The Threading Module
- Принудительное завершение работы потока
- 11.7. Tools for Working with Lists¶
- Project details
- Использование Queues
- 1- Как использовать модуль thread для создания потоков.
- Synchronizing Threads
- Lock Objects¶
- Многопоточность на Python
- Практическая реализация
- Использование Event.wait() в многопоточности Python
- 17.1.4. RLock Objects¶
- High-level Module Interface¶
- Способы реализации параллельных вычислений в программах на Python.
- Задачи с ограничением скорости вычислений и ввода-вывода
RLock Objects¶
A reentrant lock is a synchronization primitive that may be acquired multiple
times by the same thread. Internally, it uses the concepts of «owning thread»
and «recursion level» in addition to the locked/unlocked state used by primitive
locks. In the locked state, some thread owns the lock; in the unlocked state,
no thread owns it.
To lock the lock, a thread calls its method; this
returns once the thread owns the lock. To unlock the lock, a thread calls
its method. /
call pairs may be nested; only the final (the
of the outermost pair) resets the lock to unlocked and
allows another thread blocked in to proceed.
Reentrant locks also support the .
The Threading Module
The newer threading module included with Python 2.4 provides much more powerful, high-level support for threads than the thread module discussed in the previous section.
The threading module exposes all the methods of the thread module and provides some additional methods −
-
threading.activeCount() − Returns the number of thread objects that are active.
-
threading.currentThread() − Returns the number of thread objects in the caller’s thread control.
-
threading.enumerate() − Returns a list of all thread objects that are currently active.
In addition to the methods, the threading module has the Thread class that implements threading. The methods provided by the Thread class are as follows −
-
run() − The run() method is the entry point for a thread.
-
start() − The start() method starts a thread by calling the run method.
-
join() − The join() waits for threads to terminate.
-
isAlive() − The isAlive() method checks whether a thread is still executing.
-
getName() − The getName() method returns the name of a thread.
-
setName() − The setName() method sets the name of a thread.
Принудительное завершение работы потока
В Python у объектов класса Thread нет методов для принудительного завершения работы потока. Один из вариантов решения этой задачи – это создать специальный флаг, через который потоку будет передаваться сигнал остановки. Доступ к такому флагу должен управляться объектом синхронизации.
from threading import Thread, Lock
from time import sleep
lock = Lock()
stop_thread = False
def infinit_worker():
print("Start infinit_worker()")
while True:
print("--> thread work")
lock.acquire()
if stop_thread is True:
break
lock.release()
sleep(0.1)
print("Stop infinit_worker()")
# Create and start thread
th = Thread(target=infinit_worker)
th.start()
sleep(2)
# Stop thread
lock.acquire()
stop_thread = True
lock.release()
Если мы запустим эту программу, то в консоли увидим следующее:
Start infinit_worker() --> thread work --> thread work --> thread work --> thread work --> thread work Stop infinit_worker()
Разберемся с этим кодом более подробно. В строке 4 мы создаем объект класса Lock, он используется для синхронизации доступа к ресурсам из нескольких потоков, про них мы более подробно расскажем в следующей статье. В нашем случае, ресурс — это переменная stop_thread, объявленная в строке 6, которая используется как сигнал для остановки потока. После этого, в строке 8, объявляется функция infinit_worker(), ее мы запустим как поток. В ней выполняется бесконечный цикл, каждый проход которого отмечается выводом в терминал сообщения “–> thread work” и проверкой состояния переменной stop_thread. В главном потоке программы создается и запускается дочерний поток (строки 24, 25), выполняется функция задержки и принудительно завершается поток путем установки переменной stop_thread значения True.
11.7. Tools for Working with Lists¶
Many data structure needs can be met with the built-in list type. However,
sometimes there is a need for alternative implementations with different
performance trade-offs.
The module provides an object that is like
a list that stores only homogeneous data and stores it more compactly. The
following example shows an array of numbers stored as two byte unsigned binary
numbers (typecode ) rather than the usual 16 bytes per entry for regular
lists of Python int objects:
>>> from array import array
>>> a = array('H', 4000, 10, 700, 22222])
>>> sum(a)
26932
>>> a13
array('H', )
The module provides a object
that is like a list with faster appends and pops from the left side but slower
lookups in the middle. These objects are well suited for implementing queues
and breadth first tree searches:
>>> from collections import deque
>>> d = deque()
>>> d.append("task4")
>>> print("Handling", d.popleft())
Handling task1
unsearched = deque()
def breadth_first_search(unsearched):
node = unsearched.popleft()
for m in gen_moves(node):
if is_goal(m):
return m
unsearched.append(m)
In addition to alternative list implementations, the library also offers other
tools such as the module with functions for manipulating sorted
lists:
>>> import bisect >>> scores = >>> bisect.insort(scores, (300, 'ruby')) >>> scores
The module provides functions for implementing heaps based on
regular lists. The lowest valued entry is always kept at position zero. This
is useful for applications which repeatedly access the smallest element but do
not want to run a full list sort:
Project details
Meta
License: Apache Software License (Apache License, Version 2.0)
Author: Alexey Stepanov
Maintainer: Alexey Stepanov <penguinolog@gmail.com>, Antonio Esposito <esposito.cloud@gmail.com>, Dennis Dmitriev <dis-xcom@gmail.com>
Requires: Python >=3.6.0
Classifiers
-
Development Status
5 — Production/Stable
-
Intended Audience
Developers
-
License
OSI Approved :: Apache Software License
-
Programming Language
-
Python :: 3
-
Python :: 3.6
-
Python :: 3.7
-
Python :: 3.8
-
Python :: 3.9
-
Python :: Implementation :: CPython
-
Python :: Implementation :: PyPy
-
-
Topic
Software Development :: Libraries :: Python Modules
Использование Queues
Очередь(Queues Python) может быть использована для стековых реализаций «пришел первым – ушел первым» (first-in-first-out (FIFO)) или же «пришел последним – ушел последним» (last-in-last-out (LILO)) , если вы используете их правильно.
В данном разделе, мы смешаем потоки и создадим простой скрипт файлового загрузчика, чтобы продемонстрировать, как работает Queues Python со случаями, которые мы хотим паралеллизировать. Чтобы помочь объяснить, как работает Queues, мы перепишем загрузочный скрипт из предыдущей секции для использования Queues. Приступим!
Python
# -*- coding: utf-8 -*-
import os
import threading
import urllib.request
from queue import Queue
class Downloader(threading.Thread):
«»»Потоковый загрузчик файлов»»»
def __init__(self, queue):
«»»Инициализация потока»»»
threading.Thread.__init__(self)
self.queue = queue
def run(self):
«»»Запуск потока»»»
while True:
# Получаем url из очереди
url = self.queue.get()
# Скачиваем файл
self.download_file(url)
# Отправляем сигнал о том, что задача завершена
self.queue.task_done()
def download_file(self, url):
«»»Скачиваем файл»»»
handle = urllib.request.urlopen(url)
fname = os.path.basename(url)
with open(fname, «wb») as f:
while True:
chunk = handle.read(1024)
if not chunk:
break
f.write(chunk)
def main(urls):
«»»
Запускаем программу
«»»
queue = Queue()
# Запускаем потом и очередь
for i in range(5):
t = Downloader(queue)
t.setDaemon(True)
t.start()
# Даем очереди нужные нам ссылки для скачивания
for url in urls:
queue.put(url)
# Ждем завершения работы очереди
queue.join()
if __name__ == «__main__»:
urls = [«http://www.irs.gov/pub/irs-pdf/f1040.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040a.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040ez.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040es.pdf»,
«http://www.irs.gov/pub/irs-pdf/f1040sb.pdf»]
main(urls)
|
1 |
# -*- coding: utf-8 -*- importos importthreading importurllib.request fromqueueimportQueue classDownloader(threading.Thread) «»»Потоковый загрузчик файлов»»» def__init__(self,queue) «»»Инициализация потока»»» threading.Thread.__init__(self) self.queue=queue defrun(self) «»»Запуск потока»»» whileTrue # Получаем url из очереди url=self.queue.get() # Скачиваем файл self.download_file(url) # Отправляем сигнал о том, что задача завершена self.queue.task_done() defdownload_file(self,url) «»»Скачиваем файл»»» handle=urllib.request.urlopen(url) fname=os.path.basename(url) withopen(fname,»wb»)asf whileTrue chunk=handle.read(1024) ifnotchunk break f.write(chunk) defmain(urls) «»» Запускаем программу queue=Queue() # Запускаем потом и очередь foriinrange(5) t=Downloader(queue) t.setDaemon(True) t.start() # Даем очереди нужные нам ссылки для скачивания forurl inurls queue.put(url) # Ждем завершения работы очереди queue.join() if__name__==»__main__» urls=»http://www.irs.gov/pub/irs-pdf/f1040.pdf», «http://www.irs.gov/pub/irs-pdf/f1040a.pdf», «http://www.irs.gov/pub/irs-pdf/f1040ez.pdf», «http://www.irs.gov/pub/irs-pdf/f1040es.pdf», «http://www.irs.gov/pub/irs-pdf/f1040sb.pdf» main(urls) |
Давайте притормозим. В первую очередь, нам нужно взглянуть на определение главной функции для того, чтобы увидеть, как все протекает. Здесь мы видим, что она принимает список url адресов. Далее, функция main создаете экземпляр очереди, которая передана пяти демонизированным потокам. Основная разница между демонизированным и недемонизированным потоком в том, что вам нужно отслеживать недемонизированные потоки и закрывать их вручную, в то время как поток «демон» нужно только запустить и забыть о нем. Когда ваше приложение закроется, закроется и поток. Далее мы загрузили очередь (при помощи метода put) вместе с переданными url. Наконец, мы указываем очереди подождать, пока потоки выполнят свои процессы через метод join. В классе download у нас есть строчка self.queue.get(), которая выполняет функцию блока, пока очередь делает что-либо для возврата. Это значит, что потоки скромно будут дожидаться своей очереди. Также это значит, чтобы поток получал что-нибудь из очереди, он должен вызывать метод очереди под названием get. Таким образом, добавляя что-нибудь в очередь, пул потоков, поднимет или возьмет эти объекты и обработает их. Это также известно как dequeing. После того, как все объекты в очередь обработаны, скрипт заканчивается и закрывается. На моем компьютере были загружены первые 5 документов за секунду.
1- Как использовать модуль thread для создания потоков.
Если вы решите применить модуль <thread> в вашей программе, то необходимо использовать следующий метод порождения потоков.
Многопоточность в Python: использование модуля thread
thread.start_new_thread ( function, args )
Этот метод является достаточно простым и эффективным способом создания потоков. Вы можете использовать его для запуска программ в Linux, так и Windows.
Этот метод запускает новый поток и возвращает его идентификатор. Он будет вызывать функцию, заданную в качестве параметра «function» с переданным списком аргументов. Когда <function> возвращает, поток выходит.
Здесь арг является кортеж аргументов; используя пустой кортеж для вызова <function> без каких – либо аргументов. Необязательный параметр < kwargs > определяет словарь ключевых аргументов.
Если <function> завершается с необработанным исключением, печатается трассирование, а затем выходит нить (Это не влияет на другие потоки, они продолжают работать). Используйте приведенный ниже код, чтобы узнать больше о многопоточности.
Основной пример многопоточности в Python.
Многопоточность в Python: вызов функции факториала из потока.
#Пример многопоточности в Python.
#1. Вычислить факториал с помощью рекурсии.
#2. Вызов функции факториала с помощью thread.
from thread import start_new_thread
threadId = 1
def factorial(n):
global threadId
if n < 1: # базовый вариант
print "%s: %d" % ("Нить", threadId )
threadId += 1
return 1
else:
returnNumber = n * factorial( n - 1 ) # рекурсивный вызов
print(str(n) + '! = ' + str(returnNumber))
return returnNumber
start_new_thread(factorial,(5, ))
start_new_thread(factorial,(4, ))
c = raw_input("Ждем поток для возврата...\n")
После выполнения программы, вывод будет следующим.
Вывод программы.
Многопоточность в Python: вывод в многопоточных программах.
# Многопоточность в Python: вывод программы - Ждем поток для возврата... Нить: 1 1! = 1 2! = 2 3! = 6 4! = 24 Нить: 2 1! = 1 2! = 2 3! = 6 4! = 24 5! = 120
Synchronizing Threads
The threading module provided with Python includes a simple-to-implement locking mechanism that allows you to synchronize threads. A new lock is created by calling the Lock() method, which returns the new lock.
The acquire(blocking) method of the new lock object is used to force threads to run synchronously. The optional blocking parameter enables you to control whether the thread waits to acquire the lock.
If blocking is set to 0, the thread returns immediately with a 0 value if the lock cannot be acquired and with a 1 if the lock was acquired. If blocking is set to 1, the thread blocks and wait for the lock to be released.
The release() method of the new lock object is used to release the lock when it is no longer required.
Example
#!/usr/bin/python
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print "Starting " + self.name
# Get lock to synchronize threads
threadLock.acquire()
print_time(self.name, self.counter, 3)
# Free lock to release next thread
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print "%s: %s" % (threadName, time.ctime(time.time()))
counter -= 1
threadLock = threading.Lock()
threads = []
# Create new threads
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# Start new Threads
thread1.start()
thread2.start()
# Add threads to thread list
threads.append(thread1)
threads.append(thread2)
# Wait for all threads to complete
for t in threads:
t.join()
print "Exiting Main Thread"
When the above code is executed, it produces the following result −
Starting Thread-1 Starting Thread-2 Thread-1: Thu Mar 21 09:11:28 2013 Thread-1: Thu Mar 21 09:11:29 2013 Thread-1: Thu Mar 21 09:11:30 2013 Thread-2: Thu Mar 21 09:11:32 2013 Thread-2: Thu Mar 21 09:11:34 2013 Thread-2: Thu Mar 21 09:11:36 2013 Exiting Main Thread
Lock Objects¶
A primitive lock is a synchronization primitive that is not owned by a
particular thread when locked. In Python, it is currently the lowest level
synchronization primitive available, implemented directly by the
extension module.
A primitive lock is in one of two states, “locked” or “unlocked”. It is created
in the unlocked state. It has two basic methods, and
. When the state is unlocked,
changes the state to locked and returns immediately. When the state is locked,
blocks until a call to in another
thread changes it to unlocked, then the call resets it
to locked and returns. The method should only be
called in the locked state; it changes the state to unlocked and returns
immediately. If an attempt is made to release an unlocked lock, a
will be raised.
Locks also support the .
When more than one thread is blocked in waiting for the
state to turn to unlocked, only one thread proceeds when a
call resets the state to unlocked; which one of the waiting threads proceeds
is not defined, and may vary across implementations.
All methods are executed atomically.
Многопоточность на Python
За потоки в Python отвечает модуль threading, а сам поток можно создать с помощью класса Thread из этого модуля. Подключается он так:
from threading import Thread
После этого с помощью функции Thread() мы сможем создать столько потоков, сколько нам нужно. Логика работы такая:
- Подключаем нужный модуль и класс Thread.
- Пишем функции, которые нам нужно выполнять в потоках.
- Создаём новую переменную — поток, и передаём в неё название функции и её аргументы. Один поток = одна функция на входе.
- Делаем так столько потоков, сколько требует логика программы.
- Потоки сами следят за тем, закончилась в них функция или нет. Пока работает функция — работает и поток.
- Всё это работает параллельно и (в теории) не мешает друг другу.
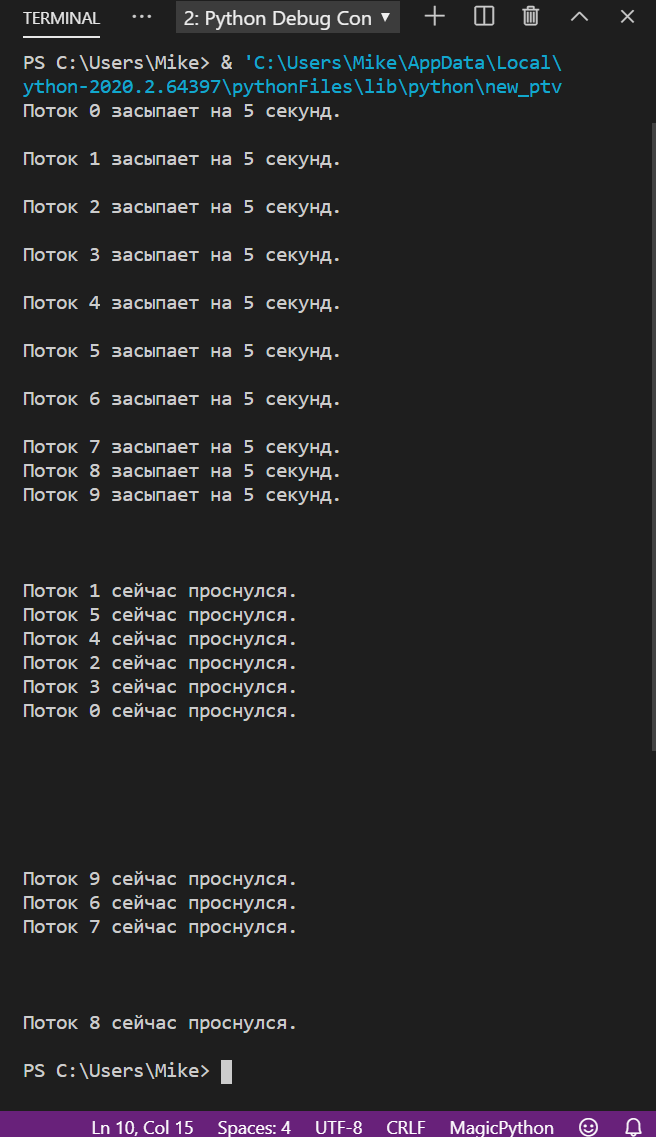
Для иллюстрации запустим такой код:
А вот как выглядит результат. Обратите внимание — потоки просыпаются не в той последовательности, как мы их запустили, а в той, в какой их выполнил процессор. Иногда это может помешать работе программы, но про это мы поговорим отдельно в другой статье.
Практическая реализация
В этих примерах на Python будет использоваться модуль потоковой передачи, который является частью стандартной библиотеки.
import threading
Чтобы проиллюстрировать мощь потоков, давайте сначала создадим два потока, A и B.
Мы заставим поток A выполнить короткое вычисление, в то время как поток B будет пытаться отслеживать общий ресурс.
Если для этого ресурса установлено значение , мы заставим поток B предупреждать пользователя о статусе.
import threading
import time
# Set the resource to False initially
shared_resource = False
# A lock for the shared resource
lock = threading.Lock()
def perform_computation():
# Thread A will call this function and manipulate the resource
print(f'Thread {threading.currentThread().name} - performing some computation....')
shared_resource = True
print(f'Thread {threading.currentThread().name} - set shared_resource to True!')
print(f'Thread {threading.currentThread().name} - Finished!')
time.sleep(1)
def monitor_resource():
# Thread B will monitor the shared resource
while shared_resource == False:
time.sleep(1)
print(f'Thread {threading.currentThread().name} - Detected shared_resource = False')
time.sleep(1)
print(f'Thread {threading.currentThread().name} - Finished!')
if __name__ == '__main__':
a = threading.Thread(target=perform_computation, name='A')
b = threading.Thread(target=monitor_resource, name='B')
# Now start both threads
a.start()
b.start()
Здесь поток A установит в , а поток B будет ждать, пока этот ресурс не станет True.
Выход
Thread A - performing some computation.... Thread A - set shared_resource to True! Thread A - Finished! Thread B - Detected shared_resource = False Thread B - Finished!
Теперь давайте сделаем поток B потоком демона. Посмотрим, что теперь будет. Для этого мы можем установить его как параметр в методе .
import threading
import time
shared_resource = False # Set the resource to False initially
lock = threading.Lock() # A lock for the shared resource
def perform_computation():
# Thread A will call this function and manipulate the resource
print(f'Thread {threading.currentThread().name} - performing some computation....')
shared_resource = True
print(f'Thread {threading.currentThread().name} - set shared_resource to True!')
print(f'Thread {threading.currentThread().name} - Finished!')
time.sleep(1)
def monitor_resource():
# Thread B will monitor the shared resource
while shared_resource == False:
time.sleep(1)
print(f'Daemon Thread {threading.currentThread().name} - Detected shared_resource = False')
time.sleep(1)
print(f'Daemon Thread {threading.currentThread().name} - Finished!')
if __name__ == '__main__':
a = threading.Thread(target=perform_computation, name='A')
b = threading.Thread(target=monitor_resource, name='B', daemon=True) # Make thread B as a daemon thread
# Now start both threads
a.start()
b.start()
Выход
Thread A - performing some computation.... Thread A - set shared_resource to True! Thread A - Finished! Daemon Thread B - Detected shared_resource = False
Обратите внимание, что Daemon Thread не завершается. Это потому, что он будет автоматически убит основным потоком
Неблокирующая природа потоков делает их очень полезными для многих приложений Python.
Использование Event.wait() в многопоточности Python
Модуль предоставляет , которого можно использовать как . Однако преимущество в том, что он более отзывчив. Причина в том, что когда событие установлено, программа сразу выходит из цикла. В Python с коду надо будет подождать завершения вызова до выхода из потока.
Причина, по которой здесь лучше использовать в том, что он не блокируется, в то время, как блокируется. Это значит, что при использовании вы заблокируете выполнение основного потока, пока тот будет ждать завершения вызова . решает данную проблему. Более подробнее прочитать о принципах работы потоков можно в .
Далее показан пример добавления в Python вызова с :
Python
import logging
import threading
def worker(event):
while not event.isSet():
logging.debug(«рабочий поток вносится»)
event.wait(1)
def main():
logging.basicConfig(
level=logging.DEBUG,
format=»%(relativeCreated)6d %(threadName)s %(message)s»
)
event = threading.Event()
thread = threading.Thread(target=worker, args=(event,))
thread_two = threading.Thread(target=worker, args=(event,))
thread.start()
thread_two.start()
while not event.isSet():
try:
logging.debug(«Добавление из главного потока»)
event.wait(0.75)
except KeyboardInterrupt:
event.set()
break
if __name__ == «__main__»:
main()
|
1 8 15 25 |
importlogging importthreading defworker(event) whilenotevent.isSet() logging.debug(«рабочий поток вносится»)
defmain() logging.basicConfig( level=logging.DEBUG, format=»%(relativeCreated)6d %(threadName)s %(message)s» )
thread=threading.Thread(target=worker,args=(event,)) thread_two=threading.Thread(target=worker,args=(event,)) thread.start() thread_two.start() whilenotevent.isSet() try logging.debug(«Добавление из главного потока») exceptKeyboardInterrupt event.set() break if__name__==»__main__» main() |
В данном примере создается и передается к . Вспомните, что в предыдущем примере вместо этого передавался словарь.
Затем устанавливаются циклы для проверки, настроено ли событие . Если это не так, тогда код выведет сообщение и немного подождет перед повторной проверкой. Для установки события можно воспользоваться комбинацией . Как только событие установлено, вернется, и цикл оборвется, завершив программу.
Рассмотрите подробнее код выше. Как бы вы передали разное время сна каждому работающему потоку? Справитесь с задачей? Не бойтесь экспериментировать!
17.1.4. RLock Objects¶
A reentrant lock is a synchronization primitive that may be acquired multiple
times by the same thread. Internally, it uses the concepts of “owning thread”
and “recursion level” in addition to the locked/unlocked state used by primitive
locks. In the locked state, some thread owns the lock; in the unlocked state,
no thread owns it.
To lock the lock, a thread calls its method; this
returns once the thread owns the lock. To unlock the lock, a thread calls
its method. /
call pairs may be nested; only the final (the
of the outermost pair) resets the lock to unlocked and
allows another thread blocked in to proceed.
Reentrant locks also support the .
High-level Module Interface¶
-
An int containing the default buffer size used by the module’s buffered I/O
classes. uses the file’s blksize (as obtained by
) if possible.
- (file, mode=’r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
-
This is an alias for the builtin function.
This function raises an with
arguments , and . The and
arguments may have been modified or inferred from the original call.
- (path)
-
Opens the provided file with mode . This function should be used
when the intent is to treat the contents as executable code.should be a and an absolute path.
The behavior of this function may be overridden by an earlier call to the
. However, assuming that is a
and an absolute path, should always behave
the same as . Overriding the behavior is intended for
additional validation or preprocessing of the file.New in version 3.8.
- exception
-
This is a compatibility alias for the builtin
exception.
- exception
-
An exception inheriting and that is raised
when an unsupported operation is called on a stream.
Способы реализации параллельных вычислений в программах на Python.
Что такое параллелизм?
Параллелизм дает возможность работать над несколькими вычислениями одновременно в одной программе. Такого поведения в Python можно добиться несколькими способами:
- Используя многопоточность ||, позволяя нескольким потокам работать по очереди.
- Используя многопроцессорность ||. Делать сразу несколько вычислений, используя несколько ядер процессора. Это и называется параллелизмом.
- Используя асинхронный ввод-вывод с модулем . Запуская какую то задачу, продолжать делать другие вычисления, вместо ожидания ответа от сетевого подключения или от операций чтения/записи.
Разница между потоками и процессами.
Поток — это независимая последовательность выполнения каких то вычислений. Поток делит выделенную память ядру процессора, а так же его процессорное время со всеми другими потоками, которые создаются программой в рамках одного ядра процессора. Программы на языке Python имеют, по умолчанию, один основной поток. Можно создать их больше и позволить Python переключаться между ними. Это переключение происходит очень быстро и кажется, что они работают параллельно.
Понятие процесс в — представляет собой так же независимую последовательность выполнения вычислений. В отличие от потоков , процесс имеет собственное ядро и следовательно выделенную ему память, которое не используется совместно с другими процессами. Процесс может клонировать себя, создавая два или более экземпляра в одном ядре процессора.
Асинхронный ввод-вывод не является ни потоковым (), ни многопроцессорным (). По сути, это однопоточная, однопроцессная парадигма и не относится к параллельным вычислениям.
У Python есть одна особенность, которая усложняет параллельное выполнение кода. Она называется GIL, сокращенно от Global Interpreter Lock. GIL гарантирует, что в любой момент времени работает только один поток. Из этого следует, что с потоками невозможно использовать несколько ядер процессора.
GIL был введен в Python потому, что управление памятью CPython не является потокобезопасным. Имея такую блокировку Python может быть уверен, что никогда не будет условий гонки.
Что такое условия гонки и потокобезопасность?
-
Состояние гонки возникает, когда несколько потоков могут одновременно получать доступ к общей структуре данных или местоположению в памяти и изменять их, в следствии чего могут произойти непредсказуемые вещи…
Пример из жизни: если два пользователя одновременно редактируют один и тот же документ онлайн и второй пользователь сохранит данные в базу, то перезапишет работу первого пользователя. Чтобы избежать условий гонки, необходимо заставить второго пользователя ждать, пока первый закончит работу с документом и только после этого разрешить второму пользователю открыть и начать редактировать документ.
-
Потокобезопасность работает путем создания копии локального хранилища в каждом потоке, чтобы данные не сталкивались с другим потоком.
Алгоритм планирования доступа потоков к общим данным.
Как уже говорилось, потоки используют одну и ту же выделенную память. Когда несколько потоков работают одновременно, то нельзя угадать порядок, в котором потоки будут обращаются к общим данным. Результат доступа к совместно используемым данным зависит от алгоритма планирования. который решает, какой поток и когда запускать. Если такого алгоритма нет, то конечные данные могут быть не такими как ожидаешь.
Например, есть общая переменная . Теперь предположим, что есть два потока, и . Они выполняют следующие операции:
a = 2
# функция 1 потока
def thread_one():
global a
a = a + 2
# функция 2 потока
def thread_two():
global a
a = a * 3
Если поток получит доступ к общей переменной первым и вторым, то результат будет 12:
- 2 + 2 = 4;
- 4 * 3 = 12.
или наоборот, сначала запустится , а затем , то мы получим другой результат:
- 2 * 3 = 6;
- 6 + 2 = 8.
Таким образом очевидно, что порядок выполнения операций потоками имеет значение
Без алгоритмов планирования доступа потоков к общим данным такие ошибки очень трудно найти и произвести отладку. Кроме того, они, как правило, происходят случайным образом, вызывая беспорядочное и непредсказуемое поведение.
Есть еще худший вариант развития событий, который может произойти без встроенной в Python блокировки потоков GIL . Например, если оба потока начинают читать глобальную переменную одновременно… Оба потока увидят, что , а дальше, в зависимости от того какой поток произведет вычисления последним, в конечном итоге и будет равна переменная (4 или 6). Не то, что ожидалось!
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.