Our missionto free the genius within everyoneby making data stunningly easy to work with
Содержание:
- Графовая база данных Neo4j в PHP
- Устройство базы данных. Документы
- Ключевая терминология
- Почему вы никогда не должны использовать MongoDB
- Aggregation¶
- New Aggregation Stage for Recursive Search
- New Aggregation Stages for Faceted Search
- New Aggregation Stages to Facilitate Reshaping Documents
- New Aggregation Stage to Count
- New Aggregation Array Operators
- New Aggregation String Operators
- New Aggregation Control Flow Expression
- New Date Aggregation Operators
- Creating a MongoDB Database with the CLI (the MongoDB shell)
- Replica Set¶
- Запросы к массивам
- Установка MongoDB на Windows
- Run MongoDB Community Edition as a Windows Service¶
- Использовение BSON объектов
- Почему MongoDB
- Почему не все так просто с MongoDB
- Run MongoDB Community Edition¶
Графовая база данных Neo4j в PHP
Из песочницы
В последнее время я все чаще слышу о NoSQL и о графовых базах данных в частности. Но воспользовавшись хабропоиском с удивлением обнаружил, что статей на эту тему не так и много, а по запросу «Neo4j», так вообще 4 результата, где косвенно упоминается это название в тексте статей.
Что такое Neo4j?
Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Как я докатился до этого?
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД «MongoDB». После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер «Neo4jPHP», который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.
Устройство базы данных. Документы
Последнее обновление: 25.03.2018
Всю модель устройства базы данных в MongoDB можно представить следующим образом:
Если в реляционных бд содержимое составляют таблицы, то в mongodb база данных состоит из коллекций.
Каждая коллекция имеет свое уникальное имя — произвольный идентификатор, состоящий из не более чем 128 различных алфавитно-цифровых символов и знака подчеркивания.
В отличие от реляционных баз данных MongoDB не использует табличное устройство с четко заданным количеством столбцов и типов данных. MongoDB
является документо-ориентированной системой, в которой центральным понятием является документ.
Документ можно представить как объект, хранящий некоторую информацию. В некотором смысле он подобен строкам в реляционных субд, где строки
хранят информацию об отдельном элементе. Например, типичный документ:
{
"name": "Bill",
"surname": "Gates",
"age": "48",
"company": {
"name" : "microsoft",
"year" : "1974",
"price" : "300000"
}
}
Документ представляет набор пар ключ-значение. Например, в выражении name представляет ключ, а Bill — значение.
Ключи представляют строки. Значения же могут различаться по типу данных. В данном случае у нас почти все значения также представляют строковый тип,
и лишь один ключ (company) ссылается на отдельный объект. Всего имеется следующие типы значений:
- String: строковый тип данных, как в приведенном выше примере (для строк используется кодировка UTF-8)
- Array (массив): тип данных для хранения массивов элементов
- Binary data (двоичные данные): тип для хранения данных в бинарном формате
-
Boolean: булевый тип данных, хранящий логические значения или ,
например, - Date: хранит дату в формате времени Unix
- Double: числовой тип данных для хранения чисел с плавающей точкой
- Integer: используется для хранения целочисленных значений, например,
- JavaScript: тип данных для хранения кода javascript
- Min key/Max key: используются для сравнения значений с наименьшим/наибольшим элементов BSON
- Null: тип данных для хранения значения
- Object: строковый тип данных, как в приведенном выше примере
- ObjectID: тип данных для хранения id документа
- Regular expression: применяется для хранения регулярных выражений
- Symbol: тип данных, идентичный строковому. Используется преимущественно для тех языков, в которых есть специальные символы.
- Timestamp: применяется для хранения времени
В отличие от строк документы могут содержать разнородную информацию. Так, рядом с документом, описанным выше, в одной коллекции
может находиться другой объект, например:
{
"name": "Tom",
"birthday": "1985.06.28",
"place" : "Berlin",
"languages" :
}
Казалось бы разные объекты за исключением отдельных свойств, но все они могут находиться в одной коллекции.
Еще пара важных замечаний: в MongoDB запросы обладают регистрозависимостью и строгой типизацией. То есть следующие два документа не будут
идентичны:
{"age" : "28"}
{"age" : 28}
Если в первом случае для ключа age определена в качестве значения строка, то во втором случае значением является число.
Идентификатор документа
Для каждого документа в MongoDB определен уникальный идентификатор, который называется . При добавлении документа в коллекцию
данный идентификатор создается автоматически. Однако разработчик может сам явным образом задать идентификатор, а не полагаться на автоматически генерируемые,
указав соответствующий ключ и его значение в документе.
Данное поле должно иметь уникальное значение в рамках коллекции. И если мы попробуем добавить в коллекцию два документа с одинаковым идентификатором, то добавится только один из них, а при добавлении второго мы получим ошибку.
Если идентификатор не задан явно, то MongoDB создает специальное бинарное значение размером 12 байт. Это значение состоит из нескольких
сегментов: значение типа размером 4 байта, идентификатор машины из 3 байт, идентификатор процесса из 2 байт и счетчик из 3 байт.
Таким образом, первые 9 байт гарантируют уникальность среди других машин, на которых могут быть реплики базы данных. А следующие
3 байта гарантируют уникальность в течение одной секунды для одного процесса. Такая модель построения идентификатора гарантирует с высокой долей вероятности,
что он будет иметь уникальное значение, ведь она позволяет создавать до 16 777 216 уникальных объектов ObjectId в секунду для одного процесса.
НазадВперед
Ключевая терминология
Перед тем как приступить к установке MongoDB, давайте разберёмся с основными понятиями.
Как и MySQL, MongoDB может содержать множество баз данных, только вместо таблиц они содержат “коллекции”.
Коллекция — это что-то типа таблицы, только без колонок. Вместо этого каждая строка содержит наборы записей в виде ключ:значение.
Пример:
Каждая из этих записей, или строк, называется “документ”, но это не тот документ типа .txt или .html. Данная запись хранится в памяти в JSON формате.
Пример:
Предположим, в нашей коллекции содержится 500 документов. Как уже говорилось раньше, каждый из них может содержать разные поля. Единственное поле, которое должно быть у каждой записи, — это уникальный идентификатор (id), который добавляется автоматически.
Поначалу данная терминология может быть непривычной. Всё будет намного понятнее, когда вы увидите работу с СУБД на практике.
Почему вы никогда не должны использовать MongoDB
Перевод
Дисклеймер от автора (автор — девушка): Я не разрабатываю движки баз данных. Я создаю веб-приложения. Я участвую в 4-6 разных проектах каждый год, то есть создаю много веб-приложений. Я вижу много приложений с различными требованиями и различными потребностями хранения данных. Я разворачивала большинство хранилищ, о которых вы слышали, и несколько, о которых даже не подозреваете.
Несколько раз я делала неправильный выбор СУБД. Эта история об одном таком выборе — почему мы сделали такой выбор, как бы узнали что выбор был неверен и как мы с этим боролись.Это все произошло на проекте с открытым исходным кодом, называемым Diaspora.
Aggregation¶
New Aggregation Stage for Recursive Search
3.4 introduces a stage to the aggregation pipeline that allows for recursive search.
| Stage | Description |
|---|---|
| Performs a recursive search on a collection. To each output document, adds a new array field that contains the traversal results of the recursive search for that document. |
See also
New Aggregation Stages for Faceted Search
Faceted search allows for the categorization of documents into
classifications. For example, given a collection of inventory
documents, you may want to classify items by a single category, such as
by the price range, or by multiple categories, such as by price range
as well as separately by the departments.
3.4 introduces stages to the aggregation pipeline that allow for faceted search.
| Stage | Description |
|---|---|
| Categorizes or groups incoming documents into buckets that represent a range of values for a specified expression. |
|
| Categorizes or groups incoming documents into specified number of buckets that represent a range of values for a specified expression. MongoDB automatically determines the bucket boundaries. |
|
| Processes multiple on the input documents and outputs a document that contains the results of these pipelines. By specifying facet-related stages (, , and ) in these pipelines, allows for multi-faceted search. |
|
| Categorizes or groups incoming documents by a specified expression to compute the count for each group. Output documents are sorted in descending order by the count. |
New Aggregation Stages to Facilitate Reshaping Documents
3.4 introduces stages to the aggregation pipeline that faciliate replacing documents as
well as adding new fields.
| Stage | Description |
|---|---|
| Adds new fields to documents. The stage outputs documents that contains all existing fields from the input documents as well as the newly added fields. |
|
| Replaces a document with the specified document. You can specify a document embedded in the input document to promote the embedded document to the top level. |
New Aggregation Stage to Count
3.4 introduces a new stage to the aggregation pipeline that faciliate counting document.
| Stage | Description |
|---|---|
| Returns a document that contains a count of the number of documents input to the stage. |
New Aggregation Array Operators
| Operator | Description |
|---|---|
| Returns a boolean that indicates if a specified value is in an array. |
|
| Searches an array for an occurrence of a specified value and returns the array index (zero-based) of the first occurrence. |
|
| Returns an array whose elements are a generated sequence of numbers. |
|
| Returns an output array whose elements are those of the input array but in reverse order. |
|
| Takes an array as input and applies an expression to each element in the array to return the final result of the expression. |
|
| Returns an output array where each element is itself an array, consisting of elements in the corresponding array index position from the input arrays. |
New Aggregation String Operators
| Operator | Description |
|---|---|
| Searches a string for an occurrence of a substring and returns the UTF-8 byte index (zero-based) of the first occurrence. |
|
| Searches a string for an occurrence of a substring and returns the UTF-8 index (zero-based) of the first occurrence. |
|
| Splits a string by a specified delimiter into string components and returns an array of the string components. |
|
| Returns the number of UTF-8 bytes for a string. | |
| Returns the number of UTF-8 for a string. | |
| Returns the substring of a string. The substring starts with the character at the specified UTF-8 byte index (zero-based) in the string for the length specified. |
|
| Returns the substring of a string. The substring starts with the character at the specified UTF-8 index (zero-based) in the string for the length specified. |
New Aggregation Control Flow Expression
| Operator | Description |
|---|---|
| Evaluates, in sequential order, the expressions of the specified branches to enter the first branch for which the expression evaluates to . |
New Date Aggregation Operators
| Operator | Description |
|---|---|
| Returns the ISO 8601 weekday number, ranging from (for Monday) to (for Sunday). |
|
| Returns the ISO 8601 week number, which can range from to . Week numbers start at with the week (Monday through Sunday) that contains the year’s first Thursday. |
|
| Returns the ISO 8601 year number, where the year starts with the Monday of week 1 (ISO 8601) and ends with the Sundays of the last week (ISO 8601). |
Creating a MongoDB Database with the CLI (the MongoDB shell)
Once you have access to a cluster via the MongoDB shell, you can see all the databases in a cluster that you have access to using the “show” command:
Note that and are databases that are part of every MongoDB cluster.
From here on out there are only two tricky things to remember.
The first is that there isn’t a “create” command in the MongoDB shell.
To create a database you use the command. If the database doesn’t exist, then the MongoDB cluster will create it.
In other words, a database is created when you try to use it with the “” command.
But let’s say you entered the following command to create a new database:
That’s all you have to do. The database is created. But that leads us to the second tricky thing. Even though the database exists, if you enter the command it will look like this:
Wait a second. Where’s ?
The second tricky thing is that the database isn’t fully created until you put something into it.
To add a document to your database, use the command.
A couple of notes. The “” in the command refers to the collection that the document was being inserted in. Collections in MongoDB are like tables in a SQL database, but they are groups of documents rather than groups of records.
Collections are created just like databases, by referring to them in a command.
indicates that the document was added to the collection.
Now if you run the show dbs command you will see your database.
There’s one more thing.
How did the command know to put the data into ?
It turns out that when you entered the command, then became the current database on which commands operate.
To find out which database is the current one, enter the command:
The command displays the name of the current database. To switch to a different database, type the command and specify that database.
Replica Set¶
Default Journaling Behavior of Write Concern
A new replica set configuration setting
determines whether an
acknowledgement for a write concern of returns after the majority of the voting members apply
the write in memory or to the on-disk journal if the
option is unspecified in the write concern.
Adjustable Catchup Period for Newly Elected Primary
A new replica set configuration setting
defines the time limit for a
newly elected primary to catch up with the other replica set members
that may have more recent writes.
Linearizable Read Concern
MongoDB 3.4 introduces a read concern level of
to read data that reflects all successful
writes issued with a and acknowledged
prior to the start of the read operation. Linearizable read concern
guarantees only apply if read operations specify a query filter that
uniquely identifies a single document.
Linearizable read concern is available for all MongoDB supported
storage engines.
Combined with write concern,
read concern enables multiple threads to
perform reads and writes on a single document as if a single thread
performed these operations in real time; that is, the corresponding
schedule for these reads and writes is considered linearizable.
Reads with linearizable read concern may be significantly slower than
reads with or read
concerns. Always use with linearizable read concern, in
case a majority of data bearing members are unavailable. For example:
copy
db.restaurants.find( { _id 5 } ).readConcern("linearizable").maxTimeMS(10000)
db.runCommand( {
find "restaurants",
filter { _id 5 },
readConcern { level "linearizable" },
maxTimeMS 10000
} )
For more information on read concern, including operations that support
read concerns, see Read Concern.
Запросы к массивам
Теперь мы узнаем, как работать с массивами внутри документов.
Простой запрос элемента в массиве : Вы можете запрашивать массивы в обычном режиме, а обо всем остальном позаботится mongo. Он проверит, существует ли значение в массиве или нет.
# найти всех покемонов с weakness "ground"
> db.pokemons.find({weakness: "ground"})
# если вы сделаете что-то подобное, он проверит точное совпадение массива
> db.pokemons.find({weakness: })
Запрос по индексу в массиве : Можно запросить элемент по конкретному индексу в массиве. Просто укажите индекс, аналогично указанию ключа в объекте.
> db.pokemons.find({"weakness.2": "electric" })
Что, если у нас есть встроенные документы внутри массива ?? (Подсказка: аналогично встроенным документам)
# найти всех покемонов, у которых есть "quick attack"
> db.pokemons.find({"moves.name": "quick attack"})
Все может стать сложным, когда структура документа станет более сложной. В нашем примере выше мы искали только один ключ. Давайте посмотрим еще несколько примеров, которые могут доставить нам неприятности. Мы будем использовать другую структуру документа вместо структуры наших покемонов.
// e.g collection = articles
{
comments:
}
# допустим нам нужно найти статьи, в которых рейтинг больше 2
# это не сработает, так как будет поиск на точное совпадение
> db.articles.find({"comments": { name: "Nina", rating: {$gt: 2}}})
# это тоже не сработает
# имя может совпасть с другим комментарием, чем рейтинг
> db.articles.find({"comments.name": "Nina", "comments.rating": {$gt: 2}})
Эта проблема решается с помощью операторов.
Установка MongoDB на Windows
Сперва качаем архив с MongoDB для win32 или win64.
Распаковываем скачанный архив и помещаем его, к примеру, на диск C, в каталог mongodb. Причём, проследите за тем, чтобы каталог bin был доступен по адресу .
Далее прописываем путь к папке bin в настройках нашей ОС, для того чтобы к .exe файлам данной папки мы могли достучаться из любого места. Итак, делаем правый клик на Компьютер — Свойства. В списке слева, выбираем “Дополнительные параметры системы”:
Далее, нажимаем на кнопку “Переменные среды”:
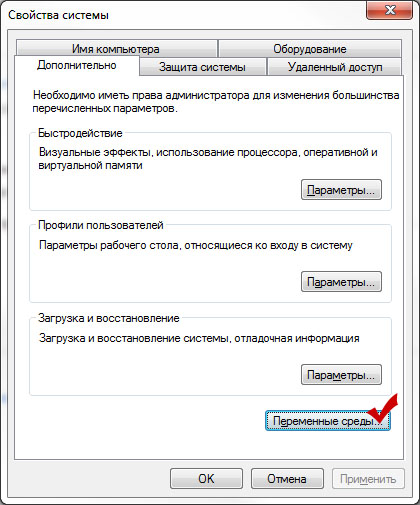
В открывшемся окне ищем системную переменную Path. Кликаем по ней дважды. В поле “значение переменной” переходим в самый конец, ставим знак “;” и вписываем путь к каталогу bin:
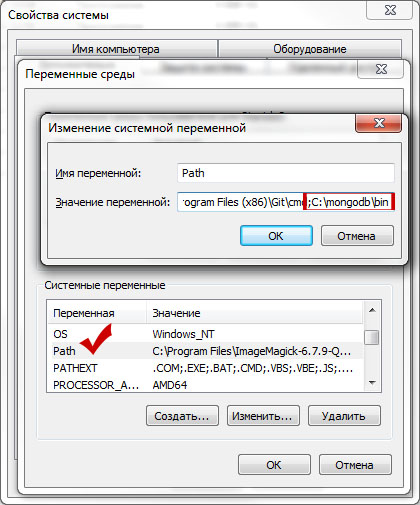
Отлично! Жмём “ок”… и переходим к следующему шагу.
Для начала, нам необходимо создать каталог, где будут храниться наши БД. К примеру, . Создаём эту папку.
Далее нам необходимо зарегистрировать MongoDB как сервис, чтобы он запускался автоматически при включении компьютера. Для этого вызываем командную строку и пишем:
echo logpath=C:\mongodb\log\mongo.log > C:\mongodb\mongod.cfg
Данная команда создаст специальный лог файл и настройки конфигурации для сервиса.
Далее создаём сервис:
mongod --config C:\mongodb\mongod.cfg --install
Прежде чем запустить его, давайте отредактируем файл , вписав туда настройку — путь к папке с нашими базами данных. В моём случае, после правки файла его содержание должно выглядеть примерно так:
logpath=C:\mongodb\log\mongo.log dbpath=C:\databases
Возвращаемся к командной строке и запускаем сервис MongoDB:
net start MongoDB
Для того чтобы проверить, будет ли сервис запускаться автоматически, нажимаем сочетание клавиш “windows+r”, пишем “services.msc”, нажимаем ОК.
В списке сервисов ищем MongoDB и, если его тип запуска не автоматический, то выставляем данный пункт, предварительно сделав правый клик, и выбрав, “свойства”.
Теперь, когда мы создали сервис, который будет запускать MongoDB при включении компьютера, нам не нужно будет делать это вручную.
Для проверки работы MongoDB открываем командную строку и пишем:
mongo
Нажимаем Enter. Далее можем работать с данной СУБД. К примеру, посмотрим, какие сейчас у нас есть базы:
show dbs
В ответе вы должны увидеть вот такую вот строку:
local (empty)
Run MongoDB Community Edition as a Windows Service¶
Starting in version 4.0, you can install and configure MongoDB as a
Windows Service during the install, and the MongoDB service
is started upon successful installation. MongoDB is configured using
the configuration file .
Start MongoDB Community Edition as a Windows Service
To start/restart the MongoDB service, use the Services console:
- From the Services console, locate the MongoDB service.
- Right-click on the MongoDB service and click Start.
To begin using MongoDB, connect a shell
to the running MongoDB instance. To connect, open a Command
Interpreter with Administrative privileges and run:
copy
"C:\Program Files\MongoDB\Server\4.4\bin\mongo.exe"
For more information on connecting a
shell, such as to connect to a MongoDB instance running on a different
host and/or port, see The mongo Shell. For information on CRUD
(Create,Read,Update,Delete) operations, see:
- Insert Documents
- Query Documents
- Update Documents
- Delete Documents
Stop MongoDB Community Edition as a Windows Service
To stop/pause the MongoDB service, use the Services console:
- From the Services console, locate the MongoDB service.
- Right-click on the MongoDB service and click Stop (or Pause).
Использовение BSON объектов
JSON документы в mongoDB хранятся в двоичном формате, называемом BSON. В отличие от других баз данных в которых JSON данные хранятся в виде строк и чисел, кодировка BSON добавляет новые типы, такие как int, long, date, float и decimal128.
Это значительно упрощает обработку, сортировку и сравнение данных приложениями. Драйвер Go имеет два семейства типов для представления данных BSON: Типы D и типы RAW.
Семейство D состоит из четырех типов:
- D: документ BSON. Этот тип следует использовать в ситуациях, когда порядок имеет значение, например, команды MongoDB.
- M: Неупорядоченный словарь(ассоциативный массив, map). Он такой же, как D, за исключением того, что он не сохраняет порядок.
- A: массив BSON.
- E: одиночный элемент внутри D.
Вот пример фильтра, построенного с использованием D-типов, который производит поиск документов, в которых поле name соответствует значениям Alice или Bob:
Семейство типов Raw используется для проверки среза байтов. Вы можете извлечь одиночные элементы из типов Raw, используя .
Это может быть полезно когда необходимо избавиться от лишней нагрузки при конвертировании BSON в иной тип.
В этом туториале будет использоваться только семейство типов D.
Почему MongoDB
Между не табличными СУБД многие пользователи делают выбор в пользу MongoDB. Во-первых, данную систему можно установить практически на всех операционных системах (Windows, OSX, Linux). Во-вторых, проект до сих пор активно развивается и с завидной частотой команда разработчиков публикует обновления. Также мне кажется, что MongoDB предоставляет хорошую документацию для начинающих.
MongoDB лучше подходит в тех случаях, когда таблицы можно представить в виде объектов. По-моему, подобные системы лучше использовать при разработке приложений для мобильный устройств. В этом плане, Mongo предоставляет отдельные библиотеки, как для iOS, так и для Adndroid-а.
Ещё один весомый аргумент в пользу MongoDB: работать с данной системой можно на многих языках программирования, таких как C/C++, Python, PHP, Rubym Perl, .NET и даже Node.js.
MongoDB — это реальное решение, если вы хотите отступить от SQL и попробовать что-то новенькое.
Почему не все так просто с MongoDB
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (Meteor.js например).
По долгу работы я примерно 3 года занимаюсь разработкой и поддержкой нескольких проектов, которые используют MongoDB в качестве основной БД, и в этой статье хочу рассказать, почему на мой взгляд с MongoDB далеко не все так просто, как написано в мануалах, и к чему вы должны быть готовы, если вдруг решите взять MongoDB в качестве основной БД в ваш новый модный стартап 🙂
Все что описано ниже можно воспроизвести с использованием библиотеки PyMongo для работы с MongoDB из языка программирования Python. Однако скорее всего с аналогичными ситуациями вы можете столкнуться и при использовании других библиотек для других языков программирования.
Run MongoDB Community Edition¶
- ulimit Considerations
-
Most Unix-like operating systems limit the system resources that a
process may use. These limits may negatively impact MongoDB operation,
and should be adjusted. See UNIX ulimit Settings for the recommended
settings for your platform.Note
Starting in MongoDB 4.4, a startup error is generated if the
value for number of open files is under .
- Directories
-
If you installed via the package manager, the data directory
and the log directory are
created during the installation.By default, MongoDB runs using the user account. If
you change the user that runs the MongoDB process, you must also
modify the permission to the data and log directories to give this
user access to these directories. - Configuration File
- The official MongoDB package includes a (). These settings (such as the
data directory and log directory specifications) take effect
upon startup. That is, if you change the configuration file while
the MongoDB instance is running, you must restart the instance for the
changes to take effect.