Управление нси в эпоху big data: какой mdm нужен современному бизнесу
Содержание:
- Введение
- Почему необходимо становиться Data-driven компанией?
- Как создать data-стратегию
- Карта контекстов
- How to get started with data-driven design
- Работа с системой хранения (Storage)
- Use quantitative and qualitative data together
- Как применить технологии Machine Learning в бизнесе?
- Data-driven менеджмент
- Кейс 3. Автоматизировать обратную связь от потребителей
- Как стать data-driven?
- Event Driven Architecture — архитектура, управляемая событиями
- Summary: Data-driven vs Domain-driven
- Поиск совпадений
- Какие задачи решает data-driven подход?
- Что такое Data—Driven Company (DDC)
Введение
Одной из основных целей бизнеса является увеличение прибыли. Для достижения этой цели компании ставят перед собой различные задачи: для одной компании это увеличение среднего размера продажи в расчете на клиента, для другой — увеличение общего количества клиентов, а для третьей — повышение количества повторных покупок одним и тем же клиентом. Выполнение поставленных задач может позволить компании выйти на новый уровень бизнеса, однако встает главный вопрос — как решать подобные задачи в условиях жесткой конкуренции и повсеместной информатизации и цифровизации?
Одним из наиболее эффективных подходов к развитию бизнеса в указанных условиях является ориентированность компании на работу с данными — так называемый Data-driven подход, подразумевающий использование технологий машинного обучения (Machine Learning). В данной статье мы рассмотрим Data-driven подход, разберемся, что значит быть Data-driven компанией, дадим определение понятию Machine Learning и рассмотрим практический опыт и пользу, которую могут принести ориентированность на данные и машинное обучение практически в любой сфере бизнеса.
Рисунок 1. Этапы монетизации данных
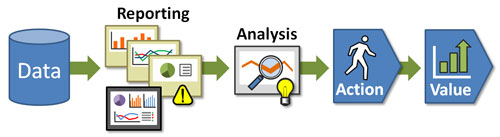
Почему необходимо становиться Data-driven компанией?
Чтобы понять, почему необходимо становится Data-driven компанией, необходимо дать ответ на вопрос: «Что значит быть Data-driven компанией?» Руководство большинства компаний считает, что если их компания создает и использует в своей работе различные отчеты, то она является Data-driven компанией. Однако если взглянуть на работу с данными более комплексно, то в современном цифровом мире недостаточно обладать хорошо структурированными отчетами, содержащими полезную информацию. Зачастую подобные отчеты способны предоставить информацию о том, что на предыдущей неделе произошло снижение продаж, но при этом они не могут дать ответ на самые главные вопросы: «Почему это произошло, и какие меры необходимо предпринять?» Помимо этого, данный отчет, возможно, не достигнет своего адресата из-за недостаточно выстроенных бизнес-процессов и отсутствия конвейеров по сбору и обработке данных. Аналогичная ситуация наблюдается в большинстве компаний в отношении разрабатываемых KPI (Key Performance Indicators), представленных на дашбордах, основывающихся только на статистических данных.
Основное отличие Data-driven компании от любой другой — это умение использовать существующие данные для реализации предиктивной аналитики — аналитики, которая использует текущие данные для получения преимуществ в будущем. Data-driven компания способна реализовать аналитику, нацеленную на будущее, и регулярно давать ответы на такие вопросы, как: «Какие причины привели к данному событию?», «Какие меры необходимо предпринять для решения возникшей проблемы?», «Какой прогноз мы можем построить на основе имеющихся данных?» Таким образом, только дата-ориентированные организации способны монетизировать данные — извлекать и повышать прибыль бизнеса за счет применения практик по анализу данных. За счет этого данные становятся не просто отчетами и визуализациями, а реальным инструментом по построению системы поддержки принятия решений и увеличения прибыли компании.
Как создать data-стратегию
Data-стратегия включает в себя стратегию сбора данных и стратегию активации данных.
Сбор данных подразумевает полное описание источников данных и их сегментацию. Примеры сегментации:
- не вовлечённые, вовлечённые, фанаты;
- AIDA;
- job to be done;
- воронка продаж и так далее.
Эти сегменты можно разбить и на меньшие подгруппы, на которые мы будем по разному воздействовать. Сегментацию можно делать и в процессе активации данных — во время тестирования гипотез и использования алгоритмов машинного обучения для создания сегментов на основе положительных результатов кампаний.
К слову об активации данных
Сегодня такая триггерная коммуникация уже возможна в медийной рекламе с колоссальными охватами. И даже без знания таких персональных данных, как электронная почта или телефон. А со знанием номера телефона или адреса почтового ящика реклама может ещё лучше попадать в сознание потребителя.
Правильно построить data-стратегию невозможно без трезвой оценки качества данных, особенно если вы заказываете их у подрядчиков. Тут нужно уметь правильно задавать вопросы. Никто вас не обманет, если скажет, что работает с данными — ведь было бы очень странно, если бы современная digital-компания с данными не работала в принципе. Но встаёт вопрос о качестве данных, которые вам продают.
Карта контекстов
(Partnership). Когда команды в двух достигают успеха и терпят неудачу вместе, возникает отношение сотрудничества. Они должны сотрудничать в процессе эволюции своих интерфейсов, чтобы учитывать потребности обеих систем.
(Shared kernel). Общая часть модели и кода образует тесную взаимосвязь. Обозначается четкая граница подмножества модели предметной области, которую команды согласны считать общей. Ядро должно быть маленьким. Оно не может изменяться без консультации с другой командой. Необходимо согласовывать команд.
(Customer-supplier development). Когда две команды находятся в отношении «нижестоящий и вышестоящий», и команды вышестоящие учитывают приоритеты нижестоящих команд.
(Conformist). Когда две команды находятся в отношении «вышестоящий и нижестоящий», причем вышестоящая команда не имеет причин учитывать потребности нижестоящей команды. Нижестоящая команда учитывает сложность трансляции между ограниченными контекстами, беспрекословно подчиняясь модели вышестоящей команды.
(Anticorruption layer). Если управление и коммуникация не соответствуют общему ядру, партнеру, или отношению «Заказчик-поставщик», то трансляция является сложной. Нижестоящий клиент должен создать изолирующий слой, чтобы обеспечить свою систему вышестоящей системы в терминах своей модели предметной области. Этот уровень общается с другой системой с помощью существующего интерфейса, не требуя или почти не требуя модификаций другой системы.
(Open host service). Определяется протокол, который предоставляет доступ к системе как к набору служб. Для учета новых требований интеграции этот протокол расширяется и уточняется.
(Published language). Трансляция между моделями двух требует общего языка. В качестве среды для коммуникации используется хорошо документированный общий язык, который может выразить необходимую информацию о предметной области, выполняя при необходимости перевод информации с другого языка на этот.
(Separate ways)
Если между двумя наборами функциональных возможностей нет важного отношения, их можно полностью отсоединить друг от друга. Интеграция всегда дорого стоит, а выгоды бывают незначительны.
(Big ball of mud)
Существуют части системы, в которых модели перемешаны, а границы стерты. Необходимо нарисовать границу такой смеси и назвать ее .
статьи
How to get started with data-driven design
If your team doesn’t currently incorporate much (or any) data into its methods, the idea of starting can seem overwhelming. The truth? It’s a big commitment to adopt data-driven practices. Fortunately, there’s a huge payoff.
Start by analyzing your existing customers. Look at your site’s in-page analytics, behavior flow, and site content to get a bird’s eye view of what people are doing. After that, dive into your audience analytics and demographic data to get a sense of their personas.
Read more about personas: Predictive personas
You can then flesh out this information with focus groups, customer surveys, and/or interviews. Once you’ve gotten a 360-degree view of your customers, use the common themes and trends to create user personas.
User personas allow you to run user tests with participants who match your ideal customers as closely as possible. Use them during the wireframing or prototyping stage to get early feedback on your site. Use them during your beta stage to identify bugs and potential issues. And use them to test your final design for problems and areas of improvement.
As you refine and iterate, user research comes into play again to confirm or negate your assumptions.
Meanwhile, A/B tests let you isolate specific variables of your user experience and find the most effective options. Run them when you add, change, or subtract an element of your interface—or want to increase conversions.
It doesn’t matter how much a designer or museum curator loves a creation. It only matters what the audience thinks. To build user-focused online experiences, use a data-driven approach.
Работа с системой хранения (Storage)
Бизнес требователен к доступности вашего приложения. Зачем кому-то нужен ваш сервис, если в нужный момент мы не можем его использовать? Для обеспечения целостности данных мы фиксируем изменение состояния бизнес-объекта после каждой обработки.
Чтобы извлечь объект из хранилища, не требуется обращение к бизнес-логике. Представим, что мы автоматизируем деятельность сети отелей и у нас есть журнал постояльцев на стойке регистрации. Мы решили посмотреть информацию о посетителе.
Работа с системой хранения в виде графической схемы:
Как мы можем заметить общение между уровнем, отвечающим за Хранение, и уровнем, отвечающим за представление данных, реализовано через Response model. Данная модель не принадлежит ни одному из этих слоев. По факту, это бизнес-объект и он находится на слое, отвечающим за бизнес-логику.
Use quantitative and qualitative data together
Many UX practitioners believe that data only means numbers. This is a common myth. While quantitative data is the foundation of data-driven design, you shouldn’t rely on it solely when making your decision. When it comes to designing with data, it’s recommended to use a combination of quantitative and qualitative methods. Why? Because quantitative data will tell you what actions users take when using your product, while qualitative data will tell you why they do it and, even more important, how they feel about the overall experience.
It’s also important to remember that using just one method of research isn’t going to give you the depth of insight needed to make useful changes. So let’s explore popular quantitative and qualitative methods.
Как применить технологии Machine Learning в бизнесе?
Разобравшись с идеологией подхода Data-driven и определением понятия Machine Learning, необходимо понять, как выстроить процессы, направленные на дата-ориентированность, и интегрировать методы и технологии Machine Learning. Ключевым и самым важным моментом является наличие самих данных. Современная компания должна уметь находить необходимые данные, осуществлять правильный сбор, обработку и их анализ. Отсюда вытекает главная задача, которая стоит перед потенциальной Data-driven-компанией, — данные необходимо собирать на постоянной основе, обеспечивать к ним соответствующий доступ и использовать их для предиктивной аналитики и real-time-мониторинга. Помимо этого, используемые данные должны обладать свойствами взаимосвязанности, доступности, полноты и точности, и это далеко не полный список.
Рисунок 2. Схема сбора, обработки и анализа данных
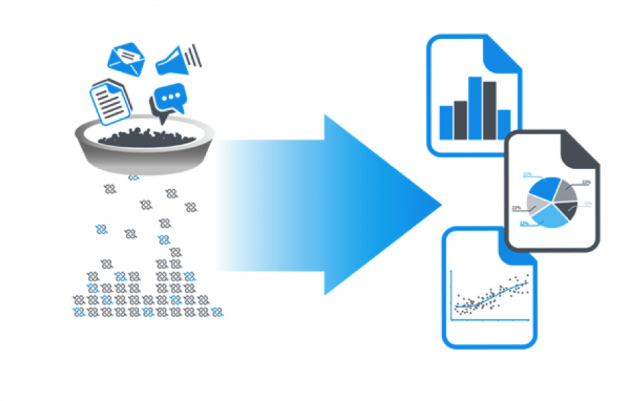
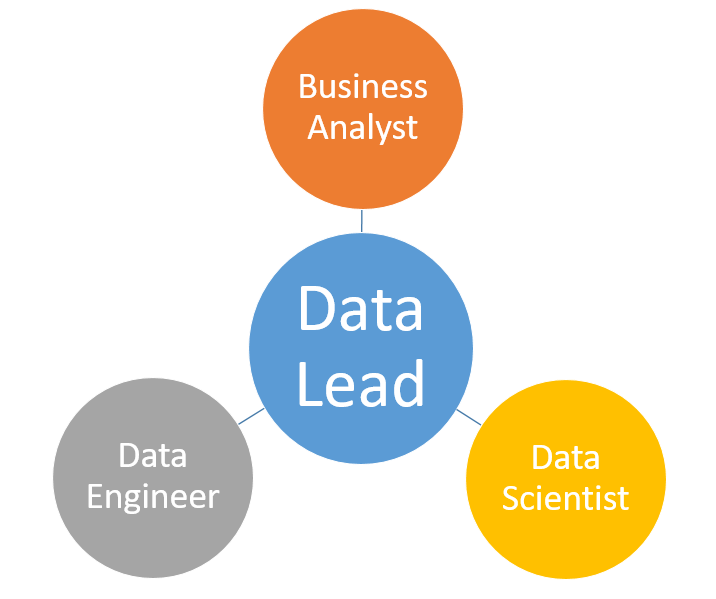
Указанная выше задача порождает перед компанией следующий барьер — отсутствие профильных специалистов, которые бы занимались работой с данными, начиная их сбором и заканчивая построением высокоуровневой аналитики. Команда специалистов по работе с данными в базовом варианте имеет следующий состав: Data Engineer, занимающийся сбором и обработкой данных, Data Scientist, отвечающий за создание математических моделей, использующих методы Machine Learning, и Business Analyst, решающий задачи по непосредственному анализу подготовленных данных с доменными знаниями в определенной области. Кроме этого, команде нужен Data Lead, который может организовать необходимые процессы по работе с данными и выстроить культуру, основная идея которой — это высочайшая ценность данных как ресурса развития компании и достижения ее стратегических целей.
Рисунок 3. Основные роли в команде специалистов по работе с данными
Data-driven менеджмент
Менеджмент, основанный на данных, выполняет несколько важных функций:
- Максимизация эффективности вложений в бизнес. Микросегментация, управление количеством касаний, привлечение новой аудитории с учетом изменения пользовательского опыта и многое другое повышают эффективность вложений начиная от логистики и заканчивая кадровой политикой.
- Сокращение маркетинговых издержек. Рекламные кампании поддаются анализу вплоть до оценки эффективности конкретного рекламного объявления с учетом LTV привлеченных пользователей.
- Максимальная клиентоориентированность. Детальный анализ целевой аудитории, персональная коммуникация с клиентом, мониторинг отзывов, оценки удовлетворенности клиентов, проведение опросов, –– все это извлекается из данных.
- Оперативная реакция на изменения рынка. Отслеживание данных в режиме реального времени уже никого не удивляет, а грамотно настроенный мониторинг позволяет принимать решения молниеносно.
- Максимизация прибыли за счет всего вышеперечисленного.
В качестве примера рассмотрим крупнейшую в мире оптово-розничную сеть Walmart. 12 000 торговых точек, 2 миллиона сотрудников – без больших данных этого гиганта ждала бы участь динозавров. Однако у Walmart все хорошо. Компания отслеживает ситуацию во всех торговых точках, использует 200 внутренних и внешних источников информации и обрабатывает 2,5 петабайт данных в течение часа. Walmart оперативно корректирует цены на товары в соответствии с изменениями в поведении покупателей.
Кейс 3. Автоматизировать обратную связь от потребителей
Ещё одному нашему клиенту — компания-производитель дверей — не хватало информации о продукте от конечного потребителя.
Несколько месяцев мы изучали целевую аудиторию, проводили опросы, собирали данные по продукции. В итоге создали инструмент «Гуру». В нём клиент самостоятельно подбирает дверь, отвечая на ряд вопросов и используя фильтры по параметрам продукции.
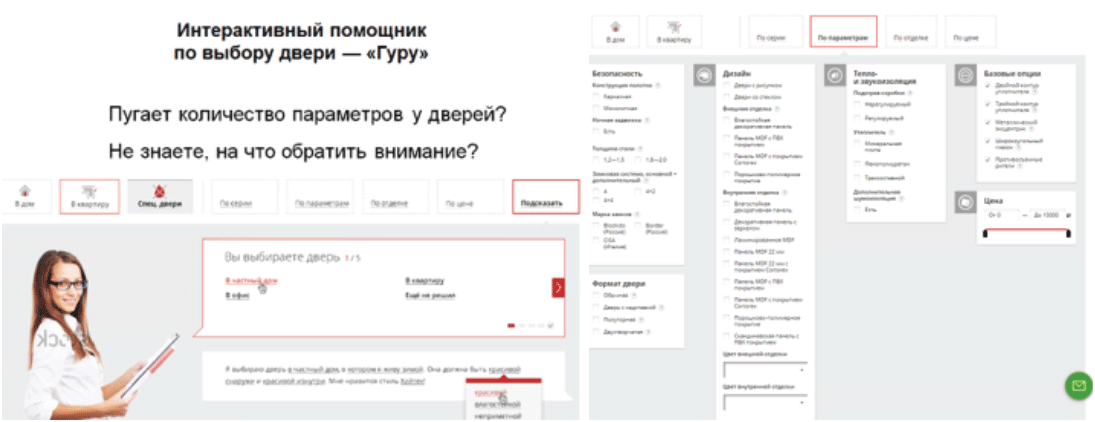
Потом настроили события в Google Analytics на эти фильтры, собрали данные в единую таблицу для анализа и прогнозирования спроса:
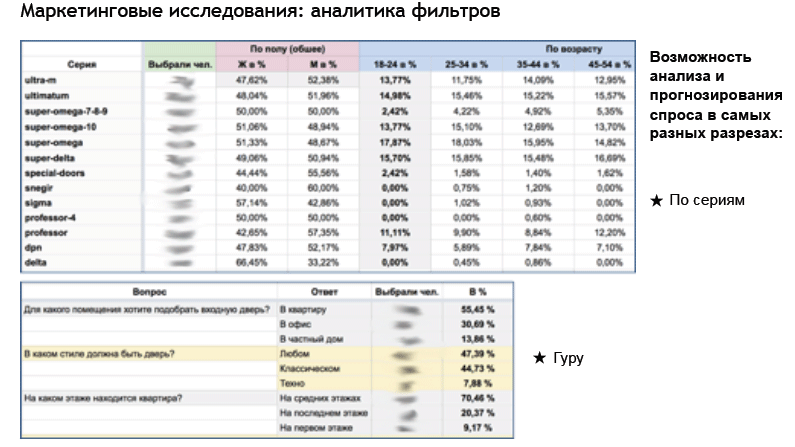
Теперь наш клиент знает:
Когда клиент получил эти данные, директор производства перестроил одну линейку продукции на заводе. А мы перенастроили рекламные кампании и увеличили эффективность каналов.
Как стать data-driven?
Сама культура принятия решений, основанная исключительно на данных, может выглядеть простой с точки зрения внедрения, но руководителю и всей команде необходимо пройти определенные шаги и разобрать важные вопросы.
- Четко опишите свои бизнес-данные и аналитическую стратегию.
- Что собираем? Где храним? Сколько храним? Сколько это стоит? Какой результат нам даст?
- Не страшно, если компания решит начать с небольшого проекта. Только такие гиганты, как Facebook или Amazon, могут себе позволить хранить все подряд постоянно и без потерь.
- Оцените стоимость информационно-технической экосистемы, позволяющей получать доступ к данным, и количество ее пользователей.
- Сейчас всю обработку данных можно доверить облакам, так вам не нужно будет капитально вкладываться в оборудование, которое может устареть быстрее, чем трансформируется культура компании.
- Распишите план действий по переходу от бизнес-отчетности к глобальной аналитике: отчетность – результат, аналитика – процесс, хотя и там, и там заказчик – бизнес.
- Актуализируйте курс и скорость трансформации раз в квартал: нужно, чтобы все сотрудники компании жили ею, а не просто смотрели на цифры в формальных документах.
- CDO берет на себя роль центра всей «аналитики»: создает для каждого из потребителей данных в компании инфраструктуру самостоятельного доступа.
- Объедините всех единой целью изменения культуры работы с данными: необходимо тесно взаимодействовать с ИТ-специалистами и другими участниками С-круга вашей компании.
Учитывая все вышесказанное, можно сделать вывод, что переход к культуре data-driven необходим не всем.
Например, компании, основанные на сильном брендинге в качестве источника основного дохода, могут не видеть особой ценности в том, чтобы стать data-driven, поскольку решения по брендингу не требуют большого количества данных.

Фото: Unsplash
Отличным примером применения трансформации data-driven на уровне всей компании является Uber: обширно используются данные, которые компания получает от пассажиров и водителей.
В компании такого уровня вся работа с данными требовала бы найма огромного штата дата-сайентистов и их погружения в бизнес-контекст. Вместо этого компания пошла по пути построения платформы управления данными, которая позволила использовать продвинутые аналитические инструменты широкому кругу пользователей.
Но стоить помнить, что и к сотрудникам, даже высокоуровневым, в таких условиях предъявляются высокие требования. Как минимум ожидается владение базовым инструментарием аналитика:
- SQL,
- основы Python,
- BI-инструментов.
Подводя итог, можно сказать, что руководителям, «пощупавшим» данные, гораздо проще находить со своими аналитиками общий язык в дальнейшем.
Аналитик обязан «видеть цифру за каждым человеком, и человека за каждой цифрой», а также уметь продать свое видение коллегам, которые могут иметь очень разный опыт и отношение к аналитике в целом. Эта роль даже в продуктовой компании предполагает максимальное количество общения с неаналитиками.

Фото: Unsplash
Именно культура работы с данными помогает договориться о правилах игры, терминах, визуализации метрик, выводах и дальнейших рекомендациях. Но руководителю нужно учиться пониманию роли аналитики и ее результатов в бизнес-процессах компании.
Это будет происходить небыстро, даже если, на первый взгляд, культура data-driven близка компании. Менеджерам необходимо понимать, как интерпретировать данные в стратегии, строить работающие гипотезы на их основе и при этом контролировать работу специалистов по аналитике. С 27 мая в «Нетологии» стартует курс «Аналитика для руководителей», на котором будут разбираться все эти вопросы и подход data-driven в целом.
Материалы по теме:
Event Driven Architecture — архитектура, управляемая событиями
Когда наши сервисы взаимодействуют в стиле RPC, все понятно: у нас есть сервис, который связывает всю бизнес-логику, собирает данные из других сервисов и возвращает их, но что делать в случае архитектуры, управляемой событиями? Мы не знаем, куда идти, — у нас есть только сообщения.
В силу того, что сервисы работают только со своими хранилищами, у нас часто возникает ситуация, когда изменения в одном сервисе требуют изменений в другом. Например, у нас есть какой-то заказ (order), и нам нужно проверить лимиты, хранящиеся в другом сервисе (customer service):
У этой проблемы есть два решения.
Решение 1
Когда вы инициируете процесс создания заказа, посылаете в шину сообщение о создании сущности:
Сервис, который заинтересован в этих событиях, подписывается на них и получает идентификацию:
Затем он выполняет какое-то внутреннее действие и возвращает ответ, который потом прилетает в сервис заказов, в шину:
Все это называется конечной согласованностью (eventual consistency). Происходит это не атомарно, а за счет технологии гарантированной доставки Message Bus. При этом взаимодействие сервисов с шиной — транзакционное, и шина обеспечивает доставку всех сообщений. Поэтому мы можем быть уверены, что в конце концов до наших сервисов все долетит (если, конечно, не решим почистить сообщения брокера через консоль администрирования).
Если стандартная модель называется ACID, такая транзакционная модель называется BASE — Basically Available, Soft state, Eventual consistency, что расшифровывается примерно так: состояние, которое вы в итоге получаете, называется “soft state”, потому что вы не до конца уверены, что это состояние действительно актуально.
Решение 2
Есть и второй способ. Может оказаться, что для принятия решений в этой системе вам не хочется (или вы не можете в силу каких-то требований) каждый раз отправлять сообщение в другой сервис, ведь время отклика здесь будет большим. В такой ситуации сервис, который владеет некой информацией, — по кредитному лимиту, как в нашем примере, — в момент изменения кредитного лимита оповещает всех заинтересованных, что информация по данному клиенту поменялась. Сервис, которому нужно проверять кредитный лимит, его проверяет и сохраняет себе проекцию нужных данных, т. е. только те поля, которые ему нужны. Конечно, это будет дубликат данных, но позволит сервису никуда не обращаться, когда будет заказ.
Здесь снова срабатывает конечная согласованность: вы можете получить заказ, проверить его кредитный лимит и учесть его как выполненный. Но т. к. в этот момент кредитный лимит мог поменяться, может оказаться, что он не соответствует заказу, и вам придется выстраивать блоки компенсации — писать дополнительный код, который будет реагировать на такие внештатные ситуации. В этом вся сложность сервисных архитектур — нужно заранее понимать, что данные, которыми вы оперируете, могут оказаться устаревшими, что может привести к неправильным действиям.
Есть еще и третий, очень серьезный подход — Event Sourcing. Это большая тема, требующая отдельного обсуждения. В Event Sourcing вы не храните состояния объектов — вы их строите в реальном времени, а храните только изменения объектов (фактически, намерения пользователей что-то поменять). Допустим, происходит что-то в UI, например, пользователь хочет сделать заказ. Тогда вы сохраняете не изменение заказа, не новое состояние, а отдельно сохраняете внешние запросы: от пользователя, от других сервисов и вообще откуда угодно. Зачем это нужно? Это нужно для ситуации компенсации — тогда вы можете откатить состояние системы назад и действовать иначе.
Вообще, Message Bus — очень большая тема, в рамках которой очень многое можно рассказать о согласовании событий. Например, можно упомянуть Saga — маленький воркфлоу, который сейчас реализуют, по крайней мере, NServiceBus и MassTransit. Saga — по сути, машина состояний, которая реагирует на внешние изменения, благодаря которой вы знаете, что происходит с системой. При этом из любого состояния вы можете сделать блок компенсации. Т. ч. Saga — хороший инструмент реализации конечной согласованности.
Summary: Data-driven vs Domain-driven
Data-driven
Pros
- Allows you to quickly develop an application or prototype
- Convenient to design (code generation, scheme, etc.)
- Can be a good solution for small or medium-sized projects
Cons
- Can lead to anti-patterns and loss of the OOP
- Leads to chaos on large projects, complex support, etc.
Domain-driven
Pros
- Use the power of OOP
- Allows you to control the complexity of the scope (domain)
- There are a number of advantages that are not described in the article, for example, the creation of the domain of language and the use of BDD
- Provides a powerful tool for developing complex and large solutions
Cons
- Requires significantly more resources for the development, which leads to greater solutions cost
- Certain parts are becoming harder to support (mapper data, etc.)
Unfortunately, there is no single answer. Analyze your problem, resources, prospects, goals and objectives. The right choice is always a compromise.
Поиск совпадений
Класс UsingMatchers
Можно заметить, что код в выглядит не очень элегантно. Переменная в листинге 11 отрицательно влияет на читаемость кода (). Этого можно избежать, используя класс и расширив специальный базовый класс , предоставляемые JBehave. В этом подходе последняя строка в листинге 11 будет выглядеть более читабельно: .
В листинге 11 проверяется, что метод возвращает значение . При использовании класса из JBehave часто оказывается, что необходим более функциональный способ для определения ожидаемых значений. Для решения этой проблемы JBehave предлагает класс для реализации сложных ожидаемых значений. В нашем случае мы воспользуемся классом из набора JBehave (переменная в листинге 11), чтобы получить доступ к таким методам, как , , и другим сложным способfм для построения ожидаемых значений в более «литературном» стиле.
Переменная в листинге 11 — это статический элемент класса , как показано в листинге 12.
Листинг 12. Использование класса UsingMatchers в классе для проверки функциональности
private static final UsingMatchers m = new UsingMatchers(){};
Теперь можно запустить новый метод для проверки поведения из листинга 11, но при этом происходит ошибка, как показано в листинге 13.
Листинг 13. Новый метод для проверки поведения не работает
Failures: 1. 1) StackBehavior should pop pushed value: java.lang.RuntimeException: nothing to pop
В чем же проблема? Дело в том, что метод реализован не до конца. Если помните, в , я ограничился минимальной реализацией, чтобы запустить код для проверки функциональности. Теперь пришло время закончить работу и действительно добавлять принимаемые значения во внутренний контейнер (если эти значения не ). Реализация этого метода приведена в листинге 14.
Листинг 14. Реализация метода push
public void push(E value) {
if(value == null){
throw new RuntimeException("Can't push null");
}else{
this.list.add(value);
}
}
Однако если запустить код для проверки этого поведения, все равно происходит ошибка!
Листинг 15. JBehave сообщает о значении null вместо того, чтобы выдавать исключение
1) StackBehavior should pop pushed value: VerificationException: Expected: same instance as <test> but got: null:
По крайней мере, ошибка из листинга 15 отличается от ошибки из листинга 13. В данном случае произошло не исключение, а не было обнаружено ожидаемое значение : вместо этого из стека был возвращен . Если посмотреть на , станет понятна причина: метод изначально был закодирован так, чтобы возвращать , если во внутреннем контейнере есть элементы. Эту проблему достаточно просто исправить.
Листинг 16. Окончательная реализация метода pop
public E pop() {
if(this.list.size() > 0){
return this.list.remove(this.list.size());
}else{
throw new RuntimeException("nothing to pop");
}
}
Но если запустить код для проверки поведения, то возникает новая ошибка.
Листинг 17. Опять ошибка
1) StackBehavior should pop pushed value: java.lang.IndexOutOfBoundsException: Index: 1, Size: 1
После изучения листинга 17 проблема становится понятной: при работе необходимо вести отсчет элементов с .
Листинг 18. Решение проблемы: начинаем отсчет элементов с 0
public E pop() {
if(this.list.size() > 0){
return this.list.remove(this.list.size()-1);
}else{
throw new RuntimeException("Nothing to pop");
}
}
Какие задачи решает data-driven подход?
На этапе создания нового продукта (сайта, приложения, нового функционала в имеющемся проекте) принимается масса решений: каким именно он будет, для какой целевой аудитории, как будет выглядеть и нужен ли вообще.
Решения принимаются командой экспертов: владельцами бизнеса, маркетологами, дизайнерами, разработчиками. Этот момент – лучшее время применить data-driven подход.
В результате получаем ответы на важные вопросы:
- Какую долю целевой аудитории продукта составляет тот или иной сегмент?
- Какую прибыль принесет этот сегмент?
- Какие задачи пользователя решит продукт?
- Какой функционал будет востребован и насколько?
- Каким количеством пользователей?
- У каких конкурентов есть похожие реализации?
После необходимых исследований и анализа результатов получаем массу неожиданных инсайтов. Приходит понимание того, зачем создавать ту или иную фичу, какую цель она преследует и какой результат принесет.
Решение о редизайне или доработке имеющегося продукта также следует принимать, основываясь на данных.
В первую очередь нужна объективация ситуации, подтвержденная цифрами. В зависимости от специфики бизнеса, метрики, отражающие реальную картину, могут быть разными, но они должны быть. На этом же этапе оценивают степень удовлетворенности клиентов. Узнают, как именно они пользуются продуктом, какой функционал наиболее востребован, с какими проблемами сталкиваются, что хотели бы улучшить.
Гипотезы, появившиеся после обработки данных предыдущего этапа, нужно подтверждать цифрами с помощью количественных исследований.
Желание улучшить продукт или повысить конверсию приводит к разнообразным гипотезам. Решение об их внедрении принимают на основании данных. К таким данным относится информация о покупательском поведении имеющихся клиентов, совершенных покупках, составе заказов, среднем чеке и периодичности покупок. Анализ отзывов, жалоб, писем в клиентскую службу и техподдержку –– данные, из которых тоже можно получить важные инсайты.
Выстраивая эту информацию в единую картину, мы получаем точный и полный портрет каждого клиента. Грамотно выстроенная коммуникация – это максимальное удобство клиента и максимальная прибыль бизнеса.
Самые яркие и интересные решения data-driven подхода – в кейсах Яндекса и на портале Think With Google.
Что такое Data—Driven Company (DDC)
Data—Driven Company – это предприятие, гибкое управляемое данными – дата-ориентированная Agile-компания, бизнес-процессы и организационная структура которой построены на основе сквозной интеграции информационных потоков и их непрерывной, в т.ч. прогнозной предиктивной, аналитике. При этом цепочка создания ценности (основного продукта) выглядит следующим образом :
- большие данные о рабочих процессах и продуктах, текущем и прогнозном состояниях внешней среды, настоящих и будущих клиентских потребностях и пр. постоянно собираются на сервера Apache Hadoop из множества источников (интернет, технологическое оборудование, корпоративные системы и хранилища данных);
- программные инструменты Big Data (Spark, Hive, Impala Python и т.д.) автоматически обрабатывают и анализируют собранную информацию, предоставляя аналитикам и руководству краткие и понятные отчеты с вариантами ситуативных решений «что-если»;
- на основе предложенных аналитических и прогнозных моделей машинного обучения (Machine Learning) менеджмент компании принимает управленческие решения, которые позволят увеличить прибыль компании или сократить ее затраты.
Например, в Альфа-Банке на основе анализа поведения индивидуальных предпринимателей строятся стратегии работы с малым бизнесом: разрабатываются финансовые программы специально для этого сегмента потребителей , а страховые компании предлагают индивидуальные варианты страховых полисов.
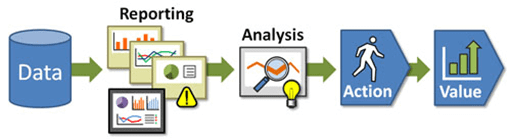 Цепочка создания ценности Data-Driven Company
Цепочка создания ценности Data-Driven Company