Javascript метод replace()
Содержание:
- Введение в регулярные выражения
- Значения параметров
- Строковые методы, поиск и замена
- Метод replaceChild()
- Жадность
- Поиск: str.match
- Пример использования
- Пример использования
- JavaScript
- insertAdjacentHTML/Text/Element
- 1. Splitting and joining an array
- Замена элементов
- Backreferences в паттерне и при замене
- Несколько слов о «document.write»
- Реализации
- Флаги
- Удаление элементов
- Итого
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
-
Набор управляющих кодов для идентификации специфических типов символов
-
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
-
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
-
Сделать заглавными первые буквы всех слов
-
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
-
Обеспечить правильную капитализацию предложений
-
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша (\) и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Метасимволы, используемые в регулярных выражениях C#
Символ
Значение
Пример
Соответствует
Классы символов
Любой из символов, указанных в скобках
В исходной строке может быть любой символ английского алфавита в нижнем регистре
Любой из символов, не указанных в скобках
В исходной строке может быть любой символ кроме цифр
.
Любой символ, кроме перевода строки или другого разделителя Unicode-строки
\w
Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п.
\W
Любой символ, не являющийся текстовым символом
\s
Любой пробельный символ из набора Unicode
\S
Любой непробельный символ из набора Unicode
Обратите внимание, что символы \w и \S — это не одно и то же
\d
Любые ASCII-цифры. Эквивалентно
\D
Любой символ, отличный от ASCII-цифр
Эквивалентно
Символы повторения
{n,m}
Соответствует предшествующему шаблону, повторенному не менее n и не более m раз
s{2,4}
«Press», «ssl», «progressss»
{n,}
Соответствует предшествующему шаблону, повторенному n или более раз
s{1,}
«ssl»
{n}
Соответствует в точности n экземплярам предшествующего шаблона
s{2}
«Press», «ssl», но не «progressss»
?
Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным
Эквивалентно {0,1}
+
Соответствует одному или более экземплярам предшествующего шаблона
Эквивалентно {1,}
*
Соответствует нулю или более экземплярам предшествующего шаблона
Эквивалентно {0,}
Символы регулярных выражений выбора
|
Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ).
(…)
Группировка. Группирует элементы в единое целое, которое может использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках.
(?:…)
Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе.
Якорные символы регулярных выражений
^
Соответствует началу строкового выражения или началу строки при многострочном поиске.
^Hello
«Hello, world», но не «Ok, Hello world» т.к. в этой строке слово «Hello» находится не в начале
$
Соответствует концу строкового выражения или концу строки при многострочном поиске.
Hello$
«World, Hello»
\b
Соответствует границе слова, т.е. соответствует позиции между символом \w и символом \W или между символом \w и началом или концом строки.
\b(my)\b
В строке «Hello my world» выберет слово «my»
\B
Соответствует позиции, не являющейся границей слов.
\B(ld)\b
Соответствие найдется в слове «World», но не в слове «ld»
Значения параметров
| Параметр | Описание | ||
|---|---|---|---|
| searchvalue | Объект регулярного выражения или строковое значение. Если аргумент является строкой, а не регулярным выражением, то метод replace() выполняет буквальный поиск строки, а не преобразует его в регулярное выражение с помощью вызова конструктора new RegExp(regexp). | ||
| newValue |
Строка, определяющая текст для замены, или функция, которая вызывается для генерации текста замены. Строка замены может включать следующие специальные шаблоны замены: |
Символы | Замена |
| $1, $2, …, $99 | Текст, соответствующий подвыражению с номером от 1 до 99 внутри регулярного выражения regexp (объекта RegExp). | ||
| $& | Вставляет сопоставившуюся подстроку. | ||
| $` | Вставляет часть строки, предшествующую сопоставившейся подстроке (текст слева от найденной подстроки). | ||
| $’ | Вставляет часть строки, следующую за сопоставившейся подстрокой (текст справа от найденной подстроки). | ||
| $$ | Осуществляет вставку символа доллара. |
Обратите внимание на то, что если аргумент является функцией, то она будет вызываться для каждого найденного соответствия, а возвращаемая ею строка будет использоваться в качестве текста для замены.
Функция принимает следующие аргументы:
- Первый аргумент, передаваемый функции это строка, которая соответствует шаблону (cоответствует шаблону замены $&).
- Следующие за ним аргументы это строки, соответствующие любым подвыражениям внутри шаблона (подобных аргументов может быть от ноля и более).
- Следующий аргумент представляет из себя целое число, указывающее позицию внутри строки, в которой было найдено соответствие.
- Последний аргумент функции замены содержит копию строки по которой происходит замена (содержит ссылку на саму строку).
Важный момент заключается в том, что точное число аргументов зависит от того, был ли первый аргумент объектом RegExp, если да, то сколько подгрупп в нём определено.
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Метод replaceChild()
Метод предназначен для замены одного дочернего узла другим. В качестве результата данный метод возвращает узел, который мы заменили новым узлом.
Синтаксис:
Данный метод имеет 2 обязательных параметра:
- — узел, которым мы хотим заменить существующий узел у родителя. Если в качестве этого узла мы используем существующий узел документа, то он будет удалён.
- — существующий узел у родителя, т.е. тот который мы хотим заменить.
Например, в имеющемся списке заменить первый элемент на новый.
<ul id="myTech"><li>Телефон</li><li>Ноутбук</li><li>Компьютер</li></ul>
//Создать новый элемент li
var elementLI = document.createElement("LI");
//Создать новый текстовый узел, содержащий текст "Смартфон"
var textSmartPhone = document.createTextNode("Cмapтфoн");
//добавить к только что созданному элементу li текстовый узел, содержащий текст "Смартфон"
elementLI.appendChild(textSmartPhone);
//получить элемент ul с id="myTech"
var myTech = document.getElementById("myTech");
//заменим первый дочерний узел (элемент li с индексом О) элемента ul на только что созданный узел
myTech.replaceChild(elementLI,myTech.childNodes);
Например, заменить у элемента с один текстовый узел на другой:
<!--HTML-->
<div id="message" class="alert аlert-warning">Предупреждение</div>
<!--JavaScript-->
<script>
//создать новый текстовый узел
var textMessage = document.createTextNode("Новое предупреждение");
//получить элемент div, имеющий id="message"
var message = document.getElementById("message");
//заменить текстовый узел у элемента div с id="message"
message.replaceChild(textMessage,message.firstChild);
</script>
Жадность
Это не совсем особенность, скорее фича, но все же достойная отдельного абзаца.
Все регулярные выражения в javascript – жадные. То есть, выражение старается отхватить как можно больший кусок строки.
Например, мы хотим заменить все открывающие тэги
На что и почему – не так важно
При запуске вы увидите, что заменяется не открывающий тэг, а вся ссылка, выражение матчит её от начала и до конца.
Это происходит из-за того, что точка-звёздочка в «жадном» режиме пытается захватить как можно больше, в нашем случае – это как раз до последнего .
Последний символ точка-звёздочка не захватывает, т.к. иначе не будет совпадения.
Как вариант решения используют квадратные скобки: :
Это работает. Но самым удобным вариантом является переключение точки-звёздочки в нежадный режим. Это осуществляется простым добавлением знака «» после звёздочки.
В нежадном режиме точка-звёздочка пустит поиск дальше сразу, как только нашла совпадение:
В некоторых языках программирования можно переключить жадность на уровне всего регулярного выражения, флагом.
В javascript это сделать нельзя… Вот такая особенность. А вопросительный знак после звёздочки рулит – честное слово.
Поиск: str.match
Как уже говорилось, использование регулярных выражений интегрировано в методы строк.
Метод для строки возвращает совпадения с регулярным выражением .
У него есть три режима работы:
Если у регулярного выражения есть флаг , то он возвращает массив всех совпадений:
Обратите внимание: найдены и и , благодаря флагу , который делает регулярное выражение регистронезависимым.
Если такого флага нет, то возвращает только первое совпадение в виде массива, в котором по индексу находится совпадение, и есть свойства с дополнительной информацией о нём:
В этом массиве могут быть и другие индексы, кроме , если часть регулярного выражения выделена в скобки. Мы разберём это в главе Скобочные группы.
И, наконец, если совпадений нет, то, вне зависимости от наличия флага , возвращается .
Это очень важный нюанс
При отсутствии совпадений возвращается не пустой массив, а именно . Если об этом забыть, можно легко допустить ошибку, например:
Если хочется, чтобы результатом всегда был массив, можно написать так:
Пример использования
Использование флагов g и i с методом replace()
const str = 'Ты кто такой? Что ты делаешь?'; // инициализируем строковое значение const newstr = str.replace(/ты/gi, 'вы'); console.log(newstr); // "вы кто такой? Что вы делаешь?"
Перестановка слов местами
const str = 'Boris Britva'; // инициализируем строковое значение const newstr = str.replace(/(\w+)\s(\w+)/, '$2 $1'); console.log(newstr); // Britva Boris
Перевод первых букв всех слов в верхний регистр с помощью функции замены
const str = 'андрей, артем, иван, вазген'; // инициализируем строковое значение const func = (word) => word.substring(0,1).toUpperCase() + word.substring(1); // инициализируем функцию замены const newstr = str.replace(/(+)/g, func); console.log(newstr); // "Андрей, Артем, Иван, Вазген"
Определенный символ в качестве разделителя числа
const num = 123456789; // инициализируем числовое значение
const re = /\B(?=(\d{3})+(?!\d))/g; // инициализируем регулярное выражение
const newstr = num.toString().replace(re, ','); // запятые в качестве разделителя числа
const newstr2 = num.toString().replace(re, ' '); // пробелы в качестве разделителя числа
console.log(newstr); // "123,456,789"
console.log(newstr2); // "123 456 789"
JavaScript String
Пример использования
<!DOCTYPE html>
<html>
<head>
<title>Использование JavaScript метода .replaceChild()</title>
</head>
<body>
<button onclick = "myFunc()">Replace</button> <!-- добавляем атрибут событий onclick -->
<ul id = "first"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li></ul>
<script>
function myFunc() {
const firstUl = document.getElementById("first"), // находим элемет по id
firstChild = firstUl.firstChild, // выбираем первый прямой дочерний узел указанного узла
newChild = document.createElement("li"), // создаем новый элемент
text = document.createTextNode("New element"); // создаем новый текстовый узел
newChild.appendChild(text); // вставляем созданный текстовый узел в конец списка дочерних узлов родительского узла
firstUl.replaceChild(newChild, firstChild); // заменяем один дочерний узел указанного узла другим
}
</script>
</body>
</html>
В этом примере с использованием атрибута событий onclick при нажатии на кнопку (HTML элемент <button>) вызываем функцию myFunc(), которая:
- С использованием JavaScript метода getElementById() объекта Document выбирает элемент с определенным глобальным атрибутом id и инициализирует переменную этим значением.
- С использованием свойства firstChild выбирает первый прямой дочерний узел элемента <ul> и инициализирует переменную этим значением.
- С использованием JavaScript метода createElement() объекта Document создает новый пустой элемент <li>.
- С использованием JavaScript метода createTextNode() объекта Document создает узел с текстовым содержимым.
- С использованием метода appendChild() объекта Node добавляем узел с текстовым содержимым созданному элементу <li>.
- И наконец, с помощью метода .replaceChild() заменяем один дочерний узел указанного узла другим (первый дочерний элемент элемента <ul> заменяем на созданный).
Результат нашего примера:
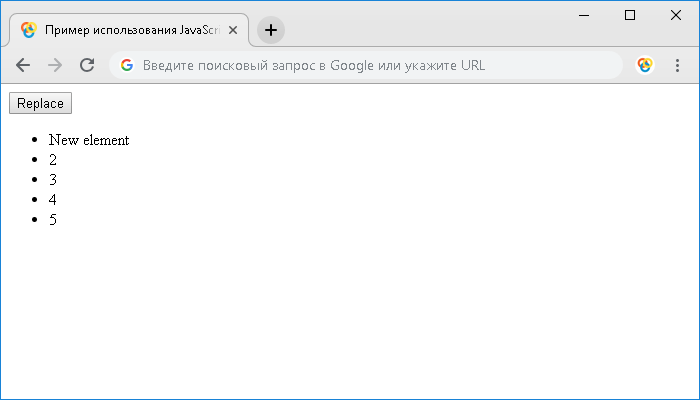
Пример использования JavaScript метода .replaceChild()
В следующем примере мы рассмотрим с Вами ситуацию при которой мы с помощью метода .replaceChild() будем вставлять для замены уже существующий элемент:
<!DOCTYPE html>
<html>
<head>
<title>Использование JavaScript метода .replaceChild() (удаление и вставка элемента)</title>
</head>
<body>
<button onclick = "myFunc()">Replace</button> <!-- добавляем атрибут событий onclick -->
<ul id = "first"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li></ul>
<script>
function myFunc() {
const firstUl = document.getElementById("first"), // находим элемет по id
firstChild = firstUl.firstChild, // выбираем первый прямой дочерний узел указанного узла
lastChild = firstUl.lastChild; // выбираем последний прямой дочерний узел указанного узла
firstUl.replaceChild(firstChild, lastChild); // заменяем один дочерний узел указанного узла другим
}
</script>
</body>
</html>
В этом примере с использованием атрибута событий onclick при нажатии на кнопку (HTML элемент <button>) вызываем функцию myFunc(), которая:
С использованием JavaScript метода getElementById() объекта Document выбирает элемент с определенным глобальным атрибутом id и инициализирует переменную этим значением.
С использованием свойства firstChild и lastChild выбирает первый и последний прямой дочерний узел элемента
- и инициализирует переменные этими значениями.
С использованием метода .replaceChild() заменяем один дочерний узел указанного узла другим (первый дочерний элемент элемента- заменяем на последний)Обратите внимание на то, что при замене первый дочерний элемент сначала удаляется, а затем вставляется вместо последнего дочернего элемента.
Результат нашего примера:
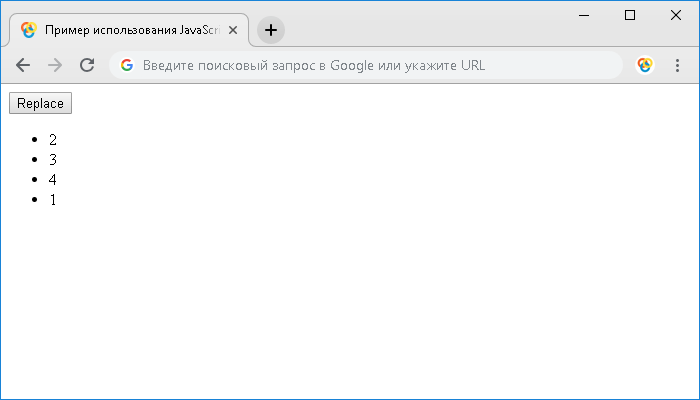
Пример использования JavaScript метода .replaceChild() (удаление и вставка элемента)JavaScript Node
JavaScript
JS Array
concat()
constructor
copyWithin()
entries()
every()
fill()
filter()
find()
findIndex()
forEach()
from()
includes()
indexOf()
isArray()
join()
keys()
length
lastIndexOf()
map()
pop()
prototype
push()
reduce()
reduceRight()
reverse()
shift()
slice()
some()
sort()
splice()
toString()
unshift()
valueOf()
JS Boolean
constructor
prototype
toString()
valueOf()
JS Classes
constructor()
extends
static
super
JS Date
constructor
getDate()
getDay()
getFullYear()
getHours()
getMilliseconds()
getMinutes()
getMonth()
getSeconds()
getTime()
getTimezoneOffset()
getUTCDate()
getUTCDay()
getUTCFullYear()
getUTCHours()
getUTCMilliseconds()
getUTCMinutes()
getUTCMonth()
getUTCSeconds()
now()
parse()
prototype
setDate()
setFullYear()
setHours()
setMilliseconds()
setMinutes()
setMonth()
setSeconds()
setTime()
setUTCDate()
setUTCFullYear()
setUTCHours()
setUTCMilliseconds()
setUTCMinutes()
setUTCMonth()
setUTCSeconds()
toDateString()
toISOString()
toJSON()
toLocaleDateString()
toLocaleTimeString()
toLocaleString()
toString()
toTimeString()
toUTCString()
UTC()
valueOf()
JS Error
name
message
JS Global
decodeURI()
decodeURIComponent()
encodeURI()
encodeURIComponent()
escape()
eval()
Infinity
isFinite()
isNaN()
NaN
Number()
parseFloat()
parseInt()
String()
undefined
unescape()
JS JSON
parse()
stringify()
JS Math
abs()
acos()
acosh()
asin()
asinh()
atan()
atan2()
atanh()
cbrt()
ceil()
clz32()
cos()
cosh()
E
exp()
expm1()
floor()
fround()
LN2
LN10
log()
log10()
log1p()
log2()
LOG2E
LOG10E
max()
min()
PI
pow()
random()
round()
sign()
sin()
sqrt()
SQRT1_2
SQRT2
tan()
tanh()
trunc()
JS Number
constructor
isFinite()
isInteger()
isNaN()
isSafeInteger()
MAX_VALUE
MIN_VALUE
NEGATIVE_INFINITY
NaN
POSITIVE_INFINITY
prototype
toExponential()
toFixed()
toLocaleString()
toPrecision()
toString()
valueOf()
JS OperatorsJS RegExp
constructor
compile()
exec()
g
global
i
ignoreCase
lastIndex
m
multiline
n+
n*
n?
n{X}
n{X,Y}
n{X,}
n$
^n
?=n
?!n
source
test()
toString()
(x|y)
.
\w
\W
\d
\D
\s
\S
\b
\B
\0
\n
\f
\r
\t
\v
\xxx
\xdd
\uxxxx
JS Statements
break
class
continue
debugger
do…while
for
for…in
for…of
function
if…else
return
switch
throw
try…catch
var
while
JS String
charAt()
charCodeAt()
concat()
constructor
endsWith()
fromCharCode()
includes()
indexOf()
lastIndexOf()
length
localeCompare()
match()
prototype
repeat()
replace()
search()
slice()
split()
startsWith()
substr()
substring()
toLocaleLowerCase()
toLocaleUpperCase()
toLowerCase()
toString()
toUpperCase()
trim()
valueOf()
insertAdjacentHTML/Text/Element
С этим может помочь другой, довольно универсальный метод: .
Первый параметр – это специальное слово, указывающее, куда по отношению к производить вставку. Значение должно быть одним из следующих:
- – вставить непосредственно перед ,
- – вставить в начало ,
- – вставить в конец ,
- – вставить непосредственно после .
Второй параметр – это HTML-строка, которая будет вставлена именно «как HTML».
Например:
…Приведёт к:
Так мы можем добавлять произвольный HTML на страницу.
Варианты вставки:
Мы можем легко заметить сходство между этой и предыдущей картинкой. Точки вставки фактически одинаковые, но этот метод вставляет HTML.
У метода есть два брата:
- – такой же синтаксис, но строка вставляется «как текст», вместо HTML,
- – такой же синтаксис, но вставляет элемент .
Они существуют, в основном, чтобы унифицировать синтаксис. На практике часто используется только . Потому что для элементов и текста у нас есть методы – их быстрее написать, и они могут вставлять как узлы, так и текст.
Так что, вот альтернативный вариант показа сообщения:
1. Splitting and joining an array
If you google how to “replace all string occurrences in JavaScript”, most likely the first approach you’d find is to use an intermediate array.
Here’s how it works:
- Split the into by the string:
- Then join the pieces putting the string in between:
For example, let’s replace all spaces with hyphens in string:
splits the string into pieces: .
Then the pieces are joined by inserting in between them, which results in the string .
Here’s a generalized helper function that uses splitting and joining approach:
This approach requires transforming the string into an array, and then back into a string. Let’s continue looking for better alternatives.
Замена элементов
С помощью методов, описанных в таблице ниже, можно заменить один набор элементов другим:
| Метод | Описание |
|---|---|
| replaceWith(HTML), replaceWith(jQuery), replaceWith(HTMLElement[]) | Заменяет элементы, содержащиеся в объекте jQuery, указанным содержимым |
| replaceAll(jQuery), replaceAll(HTMLElement[]) | Заменяет элементы, заданные аргументом, элементами, содержащимися в объекте jQuery |
| replaceWith(функция) | Выполняет динамическую замену элементов, содержащихся в объекте jQuery, с использованием функции |
Методы replaceWith() и replaceAll() работают одинаковым образом, за исключением того, что объект jQuery и аргумент играют в них противоположные роли. Пример использования обоих методов приведен ниже:
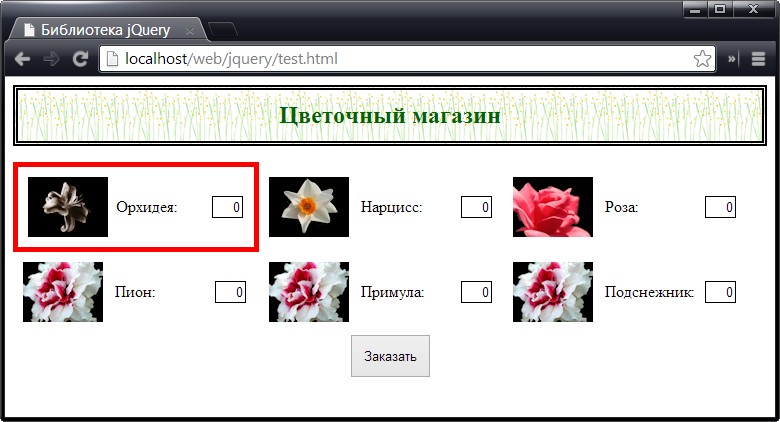
В этом сценарии сначала создается набор элементов, а затем в документе выполняется поиск элемента div, атрибут id которого равен row1, и его первый дочерний элемент заменяется новым содержимым с помощью метода replaceWith() (что в конечном счете приводит к замене элементов, соответствующих астрам, элементами, соответствующими орхидеям). Наконец, с помощью метода replaceAll() все элементы img, являющиеся потомками элемента, атрибут id которого равен row2, заменяются изображениями гвоздики.
Вид страницы в окне браузера представлен на рисунке:
Передавая функцию методу replaceWith(), можно выполнять динамическую замену элементов. Аргументы этой функции не передаются, однако переменная this внутри нее ссылается на обрабатываемый элемент. Соответствующий пример приведен ниже:
В этом сценарии мы выполняем замену элементов img на основании значений их атрибутов src. Если этот атрибут элемента img содержит rose, то данный элемент заменяется другим, которому соответствует изображение carnation.png. Если же атрибут src элемента содержит peony, то данный элемент заменяется другим, которому соответствует изображение lily.png. Оба замененных элемента выделяются рамкой красного цвета, чтобы сделать эффект более заметным. Страница в окне браузера показана на рисунке:

Если замена элемента нежелательна, можете просто вернуть его клон. Если не клонировать элемент, то jQuery полностью удалит его из документа. Конечно, этой проблемы можно избежать путем усечения выбранного набора, но такая возможность не всегда имеется.
Backreferences в паттерне и при замене
Иногда нужно в самом паттерне поиска обратиться к предыдущей его части.
Например, при поиске BB-тагов, то есть строк вида , и . Или при поиске атрибутов, которые могут быть в одинарных кавычках или двойных.
Обращение к предыдущей части паттерна в javascript осуществляется как \1, \2 и т.п., бэкслеш + номер скобочной группы:
Обращение к скобочной группе в строке замены идёт уже через доллар: . Не знаю, почему, наверное так удобнее…
P.S. Понятно, что при таком способе поиска bb-тагов придётся пропустить текст через замену несколько раз – пока результат не перестанет отличаться от оригинала.
Несколько слов о «document.write»
Есть ещё один, очень древний метод добавления содержимого на веб-страницу: .
Синтаксис:
Вызов записывает на страницу «прямо здесь и сейчас». Строка может быть динамически сгенерирована, поэтому метод достаточно гибкий. Мы можем использовать JavaScript, чтобы создать полноценную веб-страницу и записать её в документ.
Этот метод пришёл к нам со времён, когда ещё не было ни DOM, ни стандартов… Действительно старые времена. Он всё ещё живёт, потому что есть скрипты, которые используют его.
В современных скриптах он редко встречается из-за следующего важного ограничения:
Вызов работает только во время загрузки страницы.
Если вызвать его позже, то существующее содержимое документа затрётся.
Например:
Так что после того, как страница загружена, он уже непригоден к использованию, в отличие от других методов DOM, которые мы рассмотрели выше.
Это его недостаток.
Есть и преимущество. Технически, когда запускается во время чтения HTML браузером, и что-то пишет в документ, то браузер воспринимает это так, как будто это изначально было частью загруженного HTML-документа.
Поэтому он работает невероятно быстро, ведь при этом нет модификации DOM. Метод пишет прямо в текст страницы, пока DOM ещё в процессе создания.
Так что, если нам нужно динамически добавить много текста в HTML, и мы находимся на стадии загрузки, и для нас очень важна скорость, это может помочь. Но на практике эти требования редко сочетаются. И обычно мы можем увидеть этот метод в скриптах просто потому, что они старые.
Реализации
- NFA (англ. nondeterministic finite-state automata — недетерминированные конечные автоматы) используют жадный алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA, выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
- DFA (англ. deterministic finite-state automata — детерминированные конечные автоматы) работают линейно по времени, поскольку не используют откаты и никогда не проверяют какую-либо часть текста дважды. Они могут гарантированно найти самую длинную строку из возможных. DFA содержит только конечное состояние, следовательно, не обрабатывает обратных ссылок, а также не поддерживает конструкций с явным расширением, то есть не способен обработать и подвыражения. DFA используется, например, в lex и egrep.
Флаги
Регулярные выражения могут иметь флаги, которые влияют на поиск.
В JavaScript их всего шесть:
- С этим флагом поиск не зависит от регистра: нет разницы между и (см. пример ниже).
- С этим флагом поиск ищет все совпадения, без него – только первое.
- Многострочный режим (рассматривается в главе Многострочный режим якорей ^ $, флаг «m»).
- Включает режим «dotall», при котором точка может соответствовать символу перевода строки (рассматривается в главе Символьные классы).
- Включает полную поддержку юникода. Флаг разрешает корректную обработку суррогатных пар (подробнее об этом в главе Юникод: флаг «u» и класс \p{…}).
- Режим поиска на конкретной позиции в тексте (описан в главе Поиск на заданной позиции, флаг «y»)
Цветовые обозначения
Здесь и далее в тексте используется следующая цветовая схема:
- регулярное выражение –
- строка (там где происходит поиск) –
- результат –
Удаление элементов
В дополнение к возможности вставки и замены элементов библиотека jQuery предлагает ряд методов для удаления элементов из DOM. Краткое описание этой группы методов приведено в таблице ниже:
| Метод | Описание |
|---|---|
| detach(), detach(селектор) | Удаляет элементы из DOM. Данные, связанные с элементами, сохраняются |
| empty() | Удаляет все дочерние узлы каждого из элементов, содержащихся в объекте jQuery |
| remove(), remove(селектор) | Удаляет элементы из DOM. По мере удаления элементов связанные с ними данные уничтожаются |
| unwrap() | Удаляет родительские элементы каждого из элементов, содержащихся в объекте jQuery |
Пример использования метода remove() для удаления элементов приведен ниже:
В этом сценарии мы выбираем элементы img, атрибуты src которых содержат daffodil и snow, получаем их родительские элементы, а затем удаляем их. Можно также отфильтровать удаляемые элементы, передав селектор методу remove():
Оба сценария приводят к одному и тому же результату:

Как показывает мой опыт работы с методом remove(), не все селекторы способны выполнять функцию фильтра. Я рекомендую тщательно тестировать каждый шаг и отдавать предпочтение исходному набору выбранных элементов, если только это возможно.
Удаление элементов с сохранением данных
Метод detach() работает аналогично методу remove() с тем лишь отличием, что связанные с удаляемыми элементами данные сохраняются. О связывании данных с элементами подробно говорится в одной из следующих статей, а на данном этапе вам достаточно знать лишь то, что если планируется последующая вставка удаленных элементов в другое место документа, то обычно предпочтение следует отдавать методу detach().
Пример использования метода detach() приведен ниже:
В этом сценарии удаляется родительский элемент элемента img, атрибут src которого содержит astor. Затем элементы вновь вставляются в документ с помощью рассмотренного нами ранее метода append(). Я стараюсь избегать такого подхода, поскольку использование метода append() без вызова метода detach() дает тот же эффект.
Очистка элементов
Метод empty() удаляет все элементы-потомки и текст из элементов, содержащихся в объекте jQuery. Сами элементы остаются в документе. Соответствующий пример приведен ниже:
В этом сценарии из дочерних элементов элемента с атрибутом id, равным row1, выбирается элемент с индексом, равным 1, и вызывается метод empty(). Чтобы сделать изменение более заметным, соответствующая позиция в документе заключена в красную рамку. Страница в окне браузера показана на рисунке:

Метод unwrap()
Метод unwrap() удаляет родительские элементы для элементов, содержащихся в объекте jQuery. Выбранные элементы становятся дочерними элементами родителей своих бывших родительских элементов. Пример использования метода unwrap() приведен ниже:
В этом сценарии выбираются элементы div, являющиеся потомками элемента с атрибутом id, равным row1, и вызывается метод unwrap(), что приводит к удалению элемента row1, как показано на рисунке:

Изменение расположения на странице элементов, лишенных своих прежних родительских элементов, обусловлено тем, что в определение используемых стилей CSS, обеспечивающих расположение элементов в виде таблицы, входит идентификатор row1.
Итого
-
Методы для создания узлов:
- – создаёт элемент с заданным тегом,
- – создаёт текстовый узел (редко используется),
- – клонирует элемент, если , то со всеми дочерними элементами.
-
Вставка и удаление:
- – вставляет в в конец,
- – вставляет в в начало,
- – вставляет прямо перед ,
- – вставляет сразу после ,
- – заменяет .
- – удаляет .
-
Устаревшие методы:
Все эти методы возвращают .
-
Если нужно вставить фрагмент HTML, то вставляет в зависимости от :
- – вставляет прямо перед ,
- – вставляет в в начало,
- – вставляет в в конец,
- – вставляет сразу после .
Также существуют похожие методы и , они вставляют текстовые строки и элементы, но они редко используются.
-
Чтобы добавить HTML на страницу до завершения её загрузки:
document.write(html)
После загрузки страницы такой вызов затирает документ. В основном встречается в старых скриптах.