Canonical в yoast seo
Содержание:
- Canonical url что это
- Что такое rel=»canonical»?
- Теория и справка от поисковых систем
- Когда канонические ссылки не нужны
- What is a «canonical» URL?
- Основные ошибки использования rel=canonical
- Не индексируемая каноническая страница
- Разные канонические URL для одной страницы
- Неправильное использование абсолютных ссылок
- Использование тега вне блока head
- Канонические ссылки со страниц пагинации на первую страницу
- Тег canonical при использовании hreflang
- Неканонические ссылки в sitemap.xml
- Использование rel=canonical для неидентичных страниц
- Когда нужно использовать канонические ссылки
- Если вы точно знаете в каком случае у вас на сайте появляются дубли
- Когда сложно или невозможно реализовать 301 редирект
- Несколько страниц для одной серии продуктов
- Страница печати
- При использовании партнерской программы у вас на сайте
- При использовании одинакового контента на разных доменах или разных языковых версиях
- What is a canonical tag
- NOT RECOMMENDED
- Что такое rel=”canonical”?
- Что такое канонические страницы и как их настроить?
Canonical url что это
Для начала разберемся что такое canonical url, поймем его действие, узнаем везде ли нужен canonical. Так выглядит в исходном коде.
Атрибут rel canonical помогает вебмастерам и ПС предотвратить проблемы с дублирующимся контентом. Для оптимизации сайта вредно располагать контент с одинаковым содержимым, но разными URL адресами, это называется дублирующийся контент, расценивается как попытка манипуляции. Пример где он располагается в исходном коде ресурса.
Где располагается rel=”canonical” в исходном коде
Наглядным примером служат интернет магазины, в которых один и тот же товар, с одинаковым описанием, расположен по разным адресам.Чтобы не происходило индексации, склейки адресов, понижения в выдаче – используется каноникал, он сразу указывает поисковому роботу, что “эта страница полный клон другой, иди туда”.
Фактически атрибут rel canonical действует как 301 редирект, только для ПС, при обнаружении такого тега робот Яндекс или Гугл не будет сканировать запись, сразу пойдет на каноническую ссылку, взяв только основную информацию тайтл и дескрипшн. Что получаем:
- Нет дублей с одинаковым контентом
- Сохранение структуры сайта без радикальных редиректов
- Повышение статуса канонического (исходного) документа в поиске, за счет удаления дублей
Что такое rel=»canonical»?
rel=»canonical» – это указание канонической страницы сайта. С приходом CMS, динамических сайтов, одна и также страница может находиться по разным адресам, атрибут rel=»canonical» указывает, какой из всех адресов является предпочтительным для индексации.
До вчерашнего дня данный атрибут поддерживал только Google и его использование для русскоязычного интернета было, так сказать, эффективным только наполовину. Не смотря на это, многие активно его использовали на своих сайтах, при этом, кстати, забывая, что атрибут rel=»canonical» является всего лишь рекомендацией, но не правилом, в отличии от правил, которые прописываются в файле robots.txt. Но сейчас речь не об этом
На самом деле я считаю данную новость очень важной для пользователей платформы Blogger и в этой статье объясню почему
Как мы знаем, на Blogger нет доступа к файлу Robots.txt, поэтому мы как могли и на сколько это возможно управляли индексацией блога с помощью мета-тегов. При этом часто сталкивались с проблемой индексации комментариев, как отдельной страницы, когда в индекс попадали URL комментариев:
http://адрес_страницы?showComment=1300141814394#c8988727275282672241
От использования встроенных кнопок социальных сетей в индексе Яндекса появлялись ссылки на сайт такого вида:
http://адрес_страницы?spref=bl
Разработчики платформы по какой-то своей причине каждой кнопке социальной сети приделали свой параметр:
- Blogger — spref=bl
- Twitter — spref=tw
- Facebook — spref=fb и т.д.
Как мы знаем, все подобные страницы создают дублирование контента, что негативно отражается на индексации блога.
Но, если сам Google предусмотрел исключение таких страниц из индекса в панели инструментов для вебмастера, то в Яндексе решить проблему с индексацией этих страниц никак не удавалось.
Я отдельно не писала про исключение подобных URL из индекса Google, поэтому сейчас вкратце расскажу об этом. В инструментах для вебмастера Google – Конфигурация сайта – Настройки – вкладка Обработка параметров. На этой вкладке Google уже большинство параметров сам определил и исключил из поиска, указав команду Пропускать. Если какого либо из параметров там не указано, а страница с ним в URL есть в индексе, то добавляем по аналогии параметр и сохраняем настройки.
Яндекс пока такие настройки в Яндекс Вебмастер не предусмотрел, но теперь, когда Яндекс стал учитывать rel=»canonical», я очень надеюсь, из индекса этого поисковика исчезнут все дублирующиеся страницы имеющие в URL различные параметры, которые придумал Google.
При этом нам для этого специально делать ничего не нужно. Если вы посмотрите исходный код любой страницы своего блога, то увидите, что на каждой из них уже присутствует rel=»canonical».
<link href=’URL_страницы’ rel=’canonical’/>
Даже если вы посмотрите страницу по ссылкам с комментариями или параметрами социальных кнопок, то на этих страницах стоит именно канонический адрес страницы, что означает, что Яндекс будет индексировать только одну, каноническую страницу, остальные будут проигнорированы.
Не совсем про Яндекс, но про канонические страницы. Если вы пользуетесь стандартной постраничной навигацией в блоге, и при листании главной страницы у вас образуются такие ссылки:
http://адрес_блога/search?updated-max=2011-05-10T23%3A14%3A00%2B03%3A00&max-results=4
То канонический адрес страницы получается таким же:
<link href=’http://адрес_блога/search?updated-max=2011-05-10T23%3A14%3A00%2B03%3A00&max-results=4′ rel=’canonical’/>
Чтобы независимо от листания страниц канонический адрес страницы оставался URL главной страницы блога, нужно добавить условную конструкцию после открывающего тега <head>
<b:if cond=’data:blog.pageType == "index"’> <link expr:href=’data:blog.homepageUrl’ rel=’canonical’/> </b:if>
После этого любая страница, на которую мы попадаем по ссылкам Предыдущие – Следующие будет иметь канонический адрес главной страницы блога.
На этом все. Статья получилась компактной, но от этого не менее полезной. Удачи в продвижении.
Теория и справка от поисковых систем
Привожу ссылки на официальную позицию поисковых систем:
Google об атрибуте rel=»canonical» и Яндекс про атрибут rel=»canonical» тега . Разумеется, и mail.ru тут как тут – про значение canonical в теге — не могли же они отстать от Яндекса, но это и хорошо, все под копирку, нам же проще.
Что такое каноническая страница?
Это рекомендуемый экземпляр из набора страниц с очень похожим содержанием.
Зачем нужно указывать каноническую страницу?
Если поисковая система видит, что страницы очень похожи или одинаковы, то согласно алгоритмам в результатах поиска появится только одна предпочтительная страница, которая, по мнению поисковой системы, лучше всего отвечает на запрос пользователя.
А как мы знаем, поисковик не всегда угадывает наши желания, потому лучше перестраховаться и указать нужную страницу самостоятельно. Сделать это можно добавив ссылку rel=»canonical» в раздел
Еще оказывается, можно указывать каноническую ссылку для не HTML содержимого
, а, например, для pdf, doc или других файлов при помощи заголовков. Типа как X-Robots-Tag HTTP header, только тут будет Link HTTP header. Но это уже совсем для гик-маньяков, так что рассказывать об этом не буду.
Что будет, если атрибут rel=»canonical» указывает на несуществующую страницу? А если каноническими назначено несколько страниц набора?
В этом случае поисковая система просто проигнорирует данные правила и будет поступать, как и раньше — вычислять подходящий экземпляр из набора страниц согласно алгоритмам.
Можно ли использовать атрибут rel=»canonical» для указания канонического URL на другом домене?
Можно, но не нужно
Важно понимать, что атрибут canonical это всего лишь подсказка или рекомендация, а не строгое правило в отличие от редиректа, который и стоит использовать в данном случае
На основании всего вышенаписанного, а так же по информации из других официальных источников (блоги поисковых систем и блоги их сотрудников) можно сделать выводы о том, что тег link rel=»canonical»:
- Это рекомендация, а не правило, а потому может быть проигнорирован в следующих случаях:
- Документ по каноническому адресу не существует, отдает ответ 404;
- Каноническая страница закрыта от индексации в robots.txt или мета-тегом;
- В html-коде страницы указано сразу несколько атрибутов rel canonical;
- Адрес канонического документа указывает на другой домен или поддомен;
- Присутствует цепочка назначений rel=»canonical», т.е. для документа А каноническим указан документ Б, а в это время для документа Б указан каноническим документ В;
- Необходимо указывать только для дублирующих или очень схожих страниц, а не для склейки двух разных страниц или передачи веса;
- Адрес канонической страницы может указывать сам на себя;
- Поддерживается всеми поисковыми системами: в Яндексе с 23 мая 2011 года, в Google с 12 февраля 2009.
Когда канонические ссылки не нужны
Использование канонических ссылок полностью исключается в двух случаях:
Когда делается 301 редирект.
Если нужно автоматически перекидывать пользователя с одной страницы на другую (например, того, кто пришел по старой или «мертвой» ссылке, на актуальную страницу), применяют 301 редирект, а не канонические ссылки. В SEO для этих целей иногда используют канонические ссылки, что неправильно.
Редирект – это принудительный перевод пользователя на определенную страницу, которая является единственным местом, где содержится нужный контент. Потребность в редиректе возникает, когда был перенесен на новый домен весь сайт или скорректирована его структура, вследствие чего изменились URL’ы и на старых местах уже нет искомых страниц. Кроме того, с помощью 301 редиректа можно отправлять пользователя к версии без www или с ним (чтобы убедиться в том, что на сайт не будут пытаться зайти по неправильным ссылкам).
Канонические же ссылки позволяют иметь на сайте (и на сторонних ресурсах) одно и то же содержимое, причем все эти источники открыты для пользователя и доступны для просмотра, и при этом один из них назначается оригиналом, первоисточником.
В 2001 году Рэндом Фишкиным был проделан любопытный эксперимент с указанием канонического URL’а в тегах head на всех страницах старого домена. Он надеялся таким способом улучшить позиции новой версии сайта, размещенной на другом домене, и достиг своей цели. Об этом он рассказал в видеоролике, попутно объяснив, какую заметную роль играют канонические ссылки в кросс-доменной синдикации содержимого сайтов. Не факт, что вам удастся повторить удачный эксперимент Фишкина, но попробовать можно.
Когда необходимо закрыть страницу от поисковых систем.
Имейте в виду, что атрибут rel=«canonical» не решает всех проблем, связанных с копиями контента. Алгоритмы работы поисковиков сложны и многообразны. Во многих случаях оптимальным решением является запрет индексации тех или иных страниц сайта посредством файла robots. Кстати, в плагине WordPress SEO эта опция тоже есть.
SEO-специалисты в один голос советуют прописывать правило no-index для служебных страниц, не несущих полезной для пользователей информации, как-то: страницы входа в личный кабинет и админку, Termsand Conditions и т. п. Всего этого не должно быть в поисковой выдаче, надо сосредоточить усилия на продвижении действительно ценного контента: продающих страниц, описаний продуктов, статей в блоге.
Кроме того, закрывают от индексации страницы с мизерным количеством текста – они делают сайт пустым, недостаточно содержательным – и архивы, где дублируется контент: в CMS WordPress к таковым относятся архивы по авторам, датам и меткам (все их содержимое уже есть в архивах рубрик, не нужно плодить лишние сущности). Отдельные архивы публикаций и некоторые их типы тоже желательно закрыть от поисковиков, если оригинального контента на них нет, только копии с прочих страниц сайта.
Учтите, что все страницы, которые вы запретили индексировать в robots, нужно будет также убрать и из карты сайта. Если этого не сделать, возникнут ошибки в GoogleWebmasterTools.
What is a «canonical» URL?
So first off, what we’re trying to say is this URL is the one that we want Google and the other search engines to index and to rank. These other URLs that potentially have similar content or that are serving a similar purpose or perhaps are exact duplicates, but, for some reason, we have additional URLs of them, those ones should all tell the search engines, «No, no, this guy over here is the one you want.»
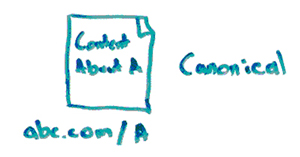
So, for example, I’ve got a canonical URL, ABC.com/a.
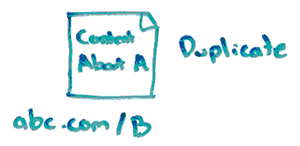
Then I have a duplicate of that for some reason. Maybe it’s a historical artifact or a problem in my site architecture. Maybe I intentionally did it. Maybe I’m doing it for some sort of tracking or testing purposes. But that URL is at ABC.com/b.

Then I have this other version, ABC.com/a?ref=twitter. What’s going on there? Well, that’s a URL parameter. The URL parameter doesn’t change the content. The content is exactly the same as A, but I really don’t want Google to get confused and rank this version, which can happen by the way. You’ll see URLs that are not the original version, that have some weird URL parameter ranking in Google sometimes. Sometimes this version gets more links than this version because they’re shared on Twitter, and so that’s the one everybody picked up and copied and pasted and linked to. That’s all fine and well, so long as we canonicalize it.

Or this one, it’s a print version. It’s ABC.com/aprint.html. So, in all of these cases, what I want to do is I want to tell Google, «Don’t index this one. Index this one. Don’t index this one. Index this one. Don’t index this one. Index this one.»
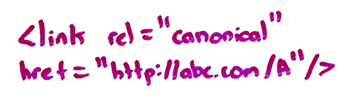
I can do that using this, the link rel=canonical, the href telling Google, «This is the page.» You put this in the header tag of any document and Google will know, «Aha, this is a copy or a clone or a duplicate of this other one. I should canonicalize all of my ranking signals, and I should make sure that this other version ranks.»
By the way, you can be self-referential. So it is perfectly fine for ABC.com/a to go ahead and use this as well, pointing to itself. That way, in the event that someone you’ve never even met decides to plug in question mark, some weird parameter and point that to you, you’re still telling Google, «Hey, guess what? This is the original version.»
Great. So since I don’t want Google to be confused, I can use this canonicalization process to do it. The rel=canonical tag is a great way to go. By the way, FYI, it can be used cross-domain. So, for example, if I republish the content on A at something like a Medium.com/@RandFish, which is, I think, my Medium account, /a, guess what? I can put in a cross-domain rel=canonical telling them, «This one over here.» Now, even if Google crawls this other website, they are going to know that this is the original version. Pretty darn cool.
Основные ошибки использования rel=canonical
Канонические URL поддерживают большинство популярных поисковых систем: Google, Яндекс, Yahoo, Bing. Но вы все равно продолжаете видеть в индексе неканонические страницы вашего сайта? Первое что нужно сделать — проверить не была ли допущена ошибка при настройке rel=canonical. Ниже перечень наиболее распространенных ошибок:
Не индексируемая каноническая страница
Проверьте может ли робот поисковой системы проиндексировать страницу, на которую вы ссылаетесь как на каноническую. Удостоверьтесь, что:
- страница отдает ответ сервера 200;
- на странице не установлен мета-тег robots со значением noindex;
- страница не закрыта от индексирования в файле robots.txt.
Разные канонические URL для одной страницы
Довольно часто устанавливаемые на сайт модули добавляют в код канонические ссылки. Это может привести в появлению нескольких rel=canonical на странице. Если ссылки в тегах указаны на разные URL, то, вероятнее всего, Google и другие поисковики просто проигнорируют ваши рекомендации. Таким образом, все усилия по установке канонических страниц могут быть сведены на нет. Почаще проверяйте исходный код ваших страниц, чтобы убедиться в наличии только одной канонической ссылки.
Неправильное использование абсолютных ссылок
Распространенной ошибкой является указание канонической ссылки без протокола http:// или https://, как показано на примере ниже:
<link rel=“canonical” href=“ururu.com/ololo.html”>
Допустимо указывать относительные ссылки:
<link rel=“canonical” href=“/ololo.html”>
либо полный абсолютный путь с протоколом:
<link rel=“canonical” href=“http://ururu.com/ololo.html”>
Использование тега вне блока head
Для корректного восприятия поисковыми системами, особенно это касается Google, тег rel=canonical должен находиться в рамках области head кода вашей страницы. Кроме того, данный тег стоит размещать настолько близко к началу HTML кода, насколько это возможно.
Канонические ссылки со страниц пагинации на первую страницу
Такое решение вполне дееспособно для борьбы с дублями. Однако, может негативно повлиять на индексацию страниц, ссылки на которые как раз и расположены на страницах пагинации. Например на странице http://example.com/dresses.html?page=3 расположены ссылки на 20 товаров — они не будут проиндексированы поисковым роботом непосредственно по ссылкам с этой страницы.
Тег canonical при использовании hreflang
Если вы внедряете hreflang на своем проекте, то обязательно убедитесь, что все канонические ссылки указывают на страницы этой же языковой версии. Несоответствие этому правилу может привести как к проблемам с ранжированием языковых версий, так и к неправильному пониманию поисковиками приоритетных для ранжирования дублирующихся страниц.
Неканонические ссылки в sitemap.xml
Файл sitemap.xml помогает поисковому роботу понять какие страницы вашего сайта нужно индексировать и ранжировать в поисковой выдаче. Именно поэтому не стоит добавлять в карту сайта закрытые любым способом от индексирования либо неканонические страницы.
Использование rel=canonical для неидентичных страниц
Данный атрибут был разработан специально для указания приоритетной страницы среди страниц-дублей. Судя по всему, поисковики допускают определенную степень расхождения в контенте страницы. Но это абсолютно не значит, что можно ставить каноническую ссылку на просто схожую по тематике страницу. Если Google заметит вас в неправильном использовании канонических ссылок, это может повлиять на его отношение к rel=canonical для всего вашего домена и тогда пострадают даже верно настроенные страницы.
Канонические ссылки (атрибут тега link rel canonical) позволяет указать какую именно страницу из группы похожих или одинаковых страниц нужно индексировать. Полезность данного инструмента сложно переоценить и глупо игнорировать. Ведь именно к правильному толкованию страниц сайта поисковыми системами, в значительной степени и сводится SEO сайта. Тем более, что канонические ссылки поддерживаются практически любой современной CMS вроде Joomla или WordPress.
Не дублируйте контент и ставьте правильные ссылки!
Когда нужно использовать канонические ссылки
Если вы точно знаете в каком случае у вас на сайте появляются дубли
Если вы четко понимаете причину возникновения похожих или очень схожих страниц у вас на сайте и, при этом, каждая такая страница должна существовать на сайте, то желательно определиться какая из этих страниц серии является основной и со всех других страниц проставить канонические ссылки на эту одну главную.
Когда сложно или невозможно реализовать 301 редирект
В общем лучше всего использовать 301 редирект, но если это довольно сложно или долго реализовывать, то можно воспользоваться и атрибутом rel=”canonical”. По заявлениям Google, передаваем вес через канонические ссылки абсолютно идентичный весу, который передает 301 редирект.
Несколько страниц для одной серии продуктов
Если у вас в интернет магазине есть серия товаров, которая отличается, например, только цветом, то лучше выбрать один товар в качестве главного (типичного) и на него проставить канонические ссылки с других продуктов.
Если на вашем сайте товары можно сортировать разными способами и параметр сортировки указывается в урле:
http://site.com/dresses.html?sort=price
то, необходимо, со всех различных комбинаций сортировок, проставлять канонические ссылки на каталог с сортировкой по умолчанию. Обычно, это URL категории без параметров, которые отвечают за сортировку товаров:
<link rel="canonical" href="http://site.com/dresses.html" />
По рекомендациям Google (https://support.google.com/webmasters/answer/1663744?hl=ru), способ при котором вы со всех страниц каталога вы делаете каноническую ссылку на страницу со всеми товарами/статьями, является оптимальным для индексации как страниц каталога сайта, так и всех товаров/статей сайта. При этом способе, для каждого раздела сайта необходимо создать страницу «Смотреть всё» и с каждой страницы пагинации проставить каноническую ссылку на страницу «Смотреть всё».

https://seoprofy.ua/blog/optimizaciya-sajtov/pagination-for-seo
Страница печати
Если печать страниц на сайте реализована через дополнительный параметр, например,
http://site.com/news-1.html?print=yes
то, необходимо, проставить каноническую ссылку на основную версию страницы
<link rel="canonical" href="http://site.com/news-1.html" />
При использовании партнерской программы у вас на сайте
Если на вашем сайте есть партнерская система или любая другая реферальная система, то тут очень важно не забывать прописывать канонические ссылки для всех страниц на которые могут стоять партнерские ссылки. Если забыть проставить, то очень быстро могут появится в индексе поисковых страниц десятки, а то и сотни дублей страниц сайта, так как по внешним ссылкам поисковые роботы довольно быстро проиндексируют не нужные страницы
Поэтому, для всех страниц на которые стоят партнерские ссылки
http://site.com/dresses.html?partner=dkfEi3dj1
мы прописываем следующую инструкцию:
<link rel="canonical" href="http://site.com/dresses.html" />
Кроме этого, вы можете указать Google все не нужные параметры для индексации через Параметры URL (в Google Webmasters раздел Сканирование). В данном случаем необходимо указать параметр partner, как такой, что не изменяет содержимое страницы.
Важно проверять, чтобы файлы в каталоге типа index.html не приводили к дублям: это может произойти, когда открыты для индексации 2 таких адреса http://site.com/dresses/ и http://site.com/dresses/index.html. В таких случаях, для решения данной проблемы, легче всего в файле http://site.com/dresses/index.html прописать такую каноническую ссылку
<link rel="canonical" href="http://site.com/dresses/" />
При использовании одинакового контента на разных доменах или разных языковых версиях
Когда вы создаете похожие сайты или делаете разные языковые версии вашего контента, но при этом на разных сайтах/языковых версиях используете один и тот же контент, то в таком случае необходимо применение rel=”canonical” на основную версию контента.
What is a canonical tag
At the moment, eliminating the problem of duplicate content for SEO is one of the most important when optimizing the site. In most cases, to solve this problem, it is best to use 301 redirect. But, when we either can not use 301 redirects, or we need pages for viewing by users, then the rel=”canonical” attribute comes to our rescue. But what is canonicalization, where and why it has to be used? The answers to all these questions you will find in this article.
First of all, canonicalization is the process that determines (from several duplicate pages under different links within one resource) the main URL address for subsequent indexing by a search engine. There is one more definition exists, it connects to IP canonicalization. It occurs automatically (according to the specified algorithms), however, to avoid errors, it is necessary to use canonical meta tag in conjunction with 301 redirections to the correct hyperlinks. With this attribute, you can quickly resolve duplicate content problems.
A canonical URL is the URL of the page that Google thinks is most representative from a set of duplicate pages on your site. For example, if you have URLs for the same page (for example: example.com?dress=1234 and example.com/dresses/1234), Google chooses one as canonical. Note that the pages do not need to be absolutely identical; minor changes in sorting or filtering of list pages do not make the page unique (for example, sorting by price or filtering by item color). The canonical can be in a different domain than a duplicate.Google Search Console Help
NOT RECOMMENDED
I do not recommend…
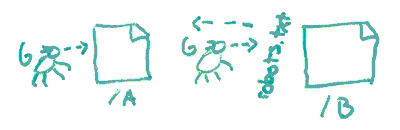
5. Blocking Google from crawling one URL but not the other version.
Because guess what? Even if you use robots.txt and you block Googlebot’s spider and you send them away and they can’t reach it because you said robots.txt disallow /b, Google will not know that /b and /a have the same content on them. How could they?
They can’t crawl it. So they can’t see anything that’s here. It’s invisible to them. Therefore, they’ll have no idea that any ranking signals, any links that happen to point there, any engagement signals, any content signals, whatever ranking signals that might have helped A rank better, they can’t see them. If you canonicalize in one of these ways, now you’re telling Google, yes, B is the same as A, combine their forces, give me all the rankings ability.

6. I would also not recommend blocking indexation.
So you might say, «Ah, well Rand, I’ll use the meta robots no index tag, so that way Google can crawl it, they can see that the content is the same, but I won’t allow them to index it.» Guess what? Same problem. They can see that the content is the same, but unless Google is smart enough to automatically canonicalize, which I would not trust them on, I would always trust yourself first, you are essentially, again, preventing them from combining the ranking signals of B into A, and that’s something you really want.
7. I would not recommend using the 302, the 307, or any other 30x other than the 301.
This is the guy that you want. It is a permanent redirect. It is the most likely to be most successful in canonicalization, even though Google has said, «We often treat 301s and 302s similarly.» The exception to that rule is but a 301 is probably better for canonicalization. Guess what we’re trying to do? Canonicalize!
8. Don’t 40x the non-canonical version.
So don’t take /b and be like, «Oh, okay, that’s not the version we want anymore. We’ll 404 it.» Don’t 404 it when you could 301. If you send it over here with a 301 or you use the rel=canonical in your header, you take all the signals and you point them to A. You lose them if you 404 that in B. Now, all the signals from B are gone. That’s a sad and terrible thing. You don’t want to do that either.
The only time I might do this is if the page is very new or it was just an error. You don’t think it has any ranking signals, and you’ve got a bunch of other problems. You don’t want to deal with having to maintain the URL and the redirect long term. Fine. But if this was a real URL and real people visited it and real people linked to it, guess what? You need to redirect it because you want to save those signals.
Что такое rel=”canonical”?
Ранее, практически, на каждом втором сайте втором сайте можно было встретить несколько совершенно одинаковых страниц с различными URL адресами. Недавно мною была опубликована статья, в которой я рассказывал вам о том, что в структуре WordPress существует некий тег rel=”Shortlink”, который формирует универсальную ссылку на каждую страницу – это дубль, его можно удалить физически. Еще есть страницы комментариев, ответов на комментарии replytocom и т.д. Но не все страницы с дублированным контентом можно ликвидировать.
У меня на блоге большинство из таких страниц вычищены, но они могут появляться в самых разных местах. Допустим, вы поставили ограничение в 50 комментариев, одновременно выводимых на странице поста – ссылка на страницу со остальными комментариями будет иметь полный дубль контента (за исключением самих комментов.
Для поисковых систем, будь это Яндекс или Google, эти страницы являются совершенно разными, но при этом имеющие одинаковый контент. Довольно давно не является секретом тот факт, что страницы имеющие одинаковый контент плохо ранжируются поисковыми системами, то есть их позиции по ключевым словам снижаются.
Не все дубли можно убрать, но для всех можно указать главную страницу.
Избежать возникновения этой проблемы можно при помощи тега rel=”canonical”. Основной функцией “canonical” является указание поисковому роботу, какая из дублированных страниц будет основной. Все остальные будут удалены из поискового индекса и не будут мешать продвижению основы.
Вот наглядный пример, как нужно использовать тег rel=”canonical”. А именно, здесь показано то, как canonical сообщает поисковому роботу о том, что страница https://dmitriyzhilin.ru/9-luchshih-plaginov-zashhity-ot-spama/ является канонической (оригинальной). А страница типа https://dmitriyzhilin.ru/9-luchshih-plaginov-zashhity-ot-spama/comment-page-2 ее копией.
<html> <head> <title>Как называется пост</title> <link rel='canonical' href='https://dmitriyzhilin.ru/9-luchshih-plaginov-zashhity-ot-spama/' /> </head> <body> текст статьи </body> </html>
Ссылка, указанная в теге canonical будет одинакова на всех страницах дублей, она будет показывать поисковику, какой URL должен попадать в индекс.
Что такое канонические страницы и как их настроить?
Итак, термин «canonical» в общем смысле означает «принятый за образец», «соответствующий канонам». В нашем случае каноническими можно считать базовые странички в ряду других с похожим содержанием, но с разными адресами (URL).
Канонические страницы в пределах сайта призваны выявлять дублированный контент, который в этом случае просто не будет учитываться поисковиками
Поначалу rel canonical признавался только Гуглом и крупными «буржуйскими» поисковиками Bing и Yahoo, но на данном этапе и лидер рунета Яндекс сподобился обратить на него свое внимание, так что вебмастерам это упрощает задачу
Поясню на примере применение каноникал. В процессе работы тот же Вордпресс может генерировать веб-страницы с отчасти или полностью идентичным контентом. Возьмем главную страницу, на которую выводятся анонсы (начальные фрагменты текста постов). По мере наполнения блога статьями число таких анонсов будет, естественно, постоянно увеличиваться.
В какой-то момент их количество будет таким, что они уже не будут умещаться на одной веб-странице. Ведь абсолютно непродуктивно впихивать их все в одно место, тем более, что ресурс будет развиваться и насыщаться новыми материалами.
Для этого в Вордпрессе предусмотрено разбиение главной на несколько частей, каждая из которых будет по сути самостоятельной страничкой с указанием, в том числе в составе URL, ее номера в текущей пагинации.
Это не что иное как нумерация этих самых страничек в составе главной. Кстати, вы можете создать свою собственную красивую постраничную навигацию по своему желанию на пример такой:

Вот, например, какие пронумерованные страницы с анонсами постов присутствуют на этом блоге:
//goldbusinessnet.com/ - первая //goldbusinessnet.com/page/2/ - вторая //goldbusinessnet.com/page/3/ - третья и т.д.
Какие же это дубли, спросите вы? Ведь содержание всех анонсов коренным образом отличается, поскольку они являются фрагментами разных статей. Так-то оно так, но ведь название и описание этих страниц будет идентичным (для главной или категорий, например).
Несмотря на то, что это неполные дубли по своей сути, ввиду вырисовывается серьезная проблема, которую необходимо устранить.
Rel canonical, как я отмечал в начале статьи, указывается в блоке служебных элементов HTML кода, которые находятся в составе тега head, являясь атрибутом служебной ссылки link. Открыть исходный код можно с помощью сочетания , действующего для всех популярных браузеров (Хром, Мазила, Опера и Интернет Эксплорер).
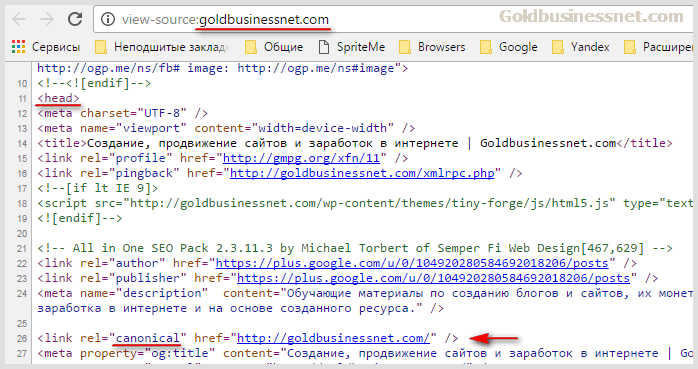
На скриншоте выше отображен HTML код первой страницы пагинации главной, для которой прописан каноникал, содержание которого указывает, что именно она сама является канонической:
<link rel="canonical" href="//goldbusinessnet.com/" />
Если откроем код второй странички, то там будет указан точно такой же тег каноникал (для простоты его часто называют так, хотя по сути это параметр атрибута rel, как вы знаете):
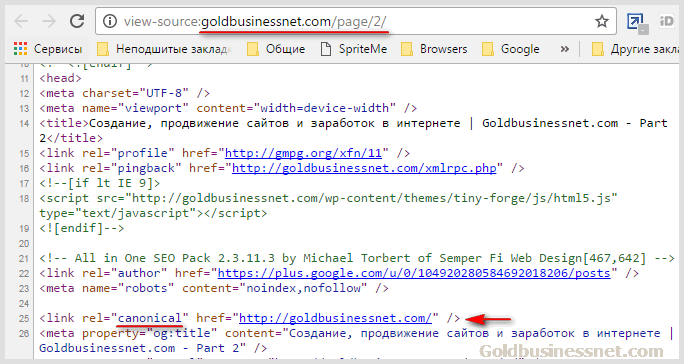
Аналогично каноническая страница определяется для каждой из рубрик, а также для разделенных на несколько страничек объемных статей, где также будет присутствовать постраничная навигация.
Именно в таком виде должен присутствовать rel canonical для каждой страницы блога WordPress. Любой другой вариант будет неверным. Проверьте исходный код для всех основных страниц своего блога, включая записи (статьи). Вполне может оказаться, что вы увидите вот такой каноникал:
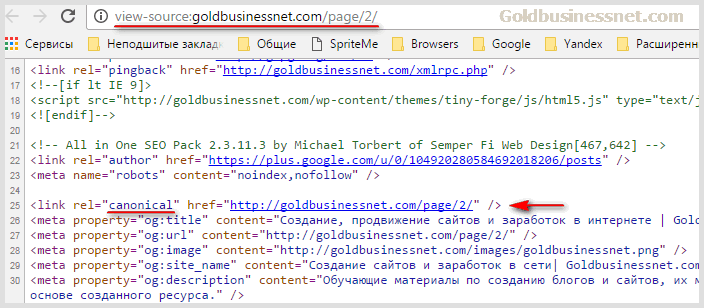
То есть для второй страницы пагинации в качестве атрибута href прописан URL этой же странички, хотя должен присутствовать адрес первой. Если внимательно посмотрите на исходный код, то для вас станет очевидным, что виноват во всем плагин All in One SEO Pack.
Без этого расширения, конечно, никуда, но иногда при его работе приходится следить за ситуацией. В данном случае, ежели вы увидели такую же картину, как на предоставленном выше скриншоте, либо у вас установлена совсем старая версия AiOSP, либо не правильно выставлены его настройки. Значит, время бить тревогу и исправлять ситуацию, о чем мы и поговорим ниже.