Простые sql запросы
Содержание:
- Что такое база данных
- Skillbox
- Отношение один-к-одному
- Ресурсы SQL Server
- Практический курс для новичков по SQL и PostgreSQL на udemy.com
- Бесплатные SQL Server и R книги
- Оператор insert into: добавление записи в таблицу
- Оператор create table: создание таблиц
- Язык структурированных запросов (SQL)
- Оператор join: объединение записей из двух таблиц
- О выборе SQL-баз данных
- Курс «SQL для анализа данных» от Skillbox
- Уровни работы с данными
- Что это такое
- СУРБД и NoSQL
- Курс «Проектирование БД и запросы SQL» от geekbrains
- Роли специалистов по базам данных
- Как хранится информация в БД
- Отношения между таблицами
- Выполнение запросов
- Системы Управления Базами Данных
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Описание курса
- Отношение один-ко-многим
Что такое база данных
Можно с большой степенью достоверности
утверждать, что большинство приложений, которые
предназначены для выполнения хотя бы
какой-нибудь полезной работы, тем или иным
образом используют структурированную
информацию или, другими словами, упорядоченные
данные. Такими данными могут быть, например,
списки заказов на тот или иной товар, списки
предъявленных и оплаченных счетов или список
телефонных номеров ваших знакомых. Обычное
расписание движения автобусов в вашем городе —
это тоже пример упорядоченных данных.
При компьютерной обработке информации
упорядоченные каким либо образом данные принято
хранить в базах данных — особых файлах,
использование которых вместе со специальными
программными средствами позволяет пользователю
как просматривать необходимую информацию, так и,
по мере необходимости, манипулировать ею,
например, добавлять, изменять, копировать,
удалять, сортировать и т.д.
Таким образом, дать простое определение базы
данных можно следующим образом. База данных — это
набор информации, организованной тем, или иным
способом. Пожалуй, одним из самых банальных
примеров баз данных может быть записная книжка с
телефонами ваших знакомых. Наверное, у вас есть
сейчас или когда-либо была эта полезная вещь.
Этот список фамилий владельцев телефонов и их
телефонных номеров, представленный в вашей
записной книжке в алфавитном порядке,
представляет собой, вообще говоря,
проиндексированную базу данных. Использование
индекса — в данном случае фамилии (или имени)
позволяет вам достаточно быстро отыскать
требуемый номер телефона.
Skillbox

Онлайн-курс SQL для анализа данных
Курс для тех, кому нужно работать с базами данных. Вы освоите язык запросов SQL — и с его помощью сможете самостоятельно получать нужные данные, сопоставлять и анализировать их.
Чему вы научитесь
- Пользоваться популярными СУБД
Узнаете особенности работы в MySQL, PostgreSQL, MS SQL. - Писать запросы к базам данных
Освоите основные операторы SQL: SELECT, INSERT, UPDATE, DELETE — и сможете запрашивать, загружать, обновлять и удалять данные. - Выполнять операции над данными
Научитесь фильтровать, сортировать, группировать и объединять данные из разных таблиц, а также применять функции SQL. - Готовить данные для Excel
Научитесь подготавливать данные для сводных таблиц и графиков в Excel.
Вас ждут онлайн-лекции и практические задания на основе реальных данных.
Программа
- Анализ данных и SQL
- Оператор SELECT — выбор колонок
- Оператор SELECT — фильтрация строк
- Сортировка и функции
- Агрегатные функции и группировка
- Объединение
- Модификация таблиц
- Подготовка данных для Excel
- Оконные функции
Отношение один-к-одному
Если между двумя таблицами существует
отношение один-к-одному, то это означает, что
каждая запись в одной таблице соответствует
только одной записи в другой таблице.
Примером такого отношения может служить
отношение между таблицами. Таблица AUTHORS (Авторы)
рассмотрена выше (рис. 1.5 и 1.6) и содержит краткую
информацию о авторах (ФИО и год рождения). Таблица
PERSON (Личность) содержит персональную информацию
о авторах (домашний адрес, телефон, образование и
др.) Структура таблицы PERSON показана на рис.1.10.
Следует отметить, что в базе данных BIBLIO.MDB никакой
таблицы PERSON нет и мы упоминаем о ней только как о
иллюстрации отношения между таблицами —
один-к-одному.
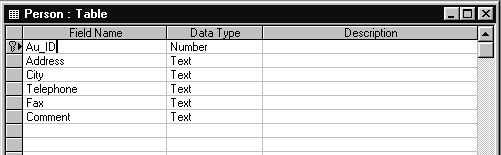 Рис.1.10. Структура таблицы PERSON
Рис.1.10. Структура таблицы PERSONМежду таблицами AUTHORS и PERSON существует отношение
один-к-одному, так как одна запись,
идентифицирующая автора, однозначно
соответствует только одной записи в таблице PERSON,
содержащей персональные данные об авторе.
Связь между таблицами определяется с помощью
совпадающих полей: Au_ID в таблице AUTHORS и в таблице
PERSON.
Ресурсы SQL Server
- Блоги
- SQL Central Blog Scripts
- SQL Central Blog Articles
- SQL Central Blog Stairways
- MSSQLTips
- BRENT OZAR scripts, videos and articles
- Simple-talk Articles
- SQLSentry Blog
- Glenn Berry’s SQL Server Performance
- Kenneth Fisher SQLStudies Blog
- Best SQL Server Perfomance Blog
- Weblogs SQLTeam Blogs
- SQLMag
- SQLShack
- SQLPass
- Vertabelo Blog
- Midnightdba Blog
- Madeiradata Blog
- SQL Server Performance Articles
- SQL and more with KRUTI Blog
- SQL Authority
- TECHNET SQL Server Blog
- SQL Server Database Engine Blog
- SQL Server BI Blog
- Andy Yun SQLBeck Blog
- Curated SQL
- Blog do Ezequiel
- SQLHA Blog
- SQLSecurity Blog
- SQL.ru SQL Server (Русский)
- Безопасность (огромное спасибо Troy Hunt)
- SQL injection
- sqlmap – Инструмент для мониторинга SQL injection тестовых атак для работающего сайта
- Drupal 7 SQL injection flaw of 2014
- Ethical Hacking: SQL Injection – Подробрный курс по SQL Injection (Платно)
- Exploit databases and breach coverage
- seclists.org – Подборка уязвимостей с разных ресурсов
- Exploit Database – Солидная подборка уязвимостей баз данных
- PunkSPIDER – Большой список уязвимостей всех типов для веб ресурсов
- Data Loss DB – Хороший список уязвимостей для баз данных
- Information is Beautiful: World’s Biggest Data Breaches – Интересная географическая визуализация произошедших уязвимостей
- SQL injection
- Бесплатные видео
- IDERA Resource Center
- MSSQLTips SQL Server Webcasts and Videos
- SQL Server Videos
- TECHNET How do I Videos
- Veeam Learn Microsoft SQL Server
- MidnightDBA ITBookWorm Video
- SQL Server Hangouts (by Boris Hristov, Cathrine Wilhelmsen)
- Youtube russianVC (Русский)
- Бесплатные подкасты (на английском)
- SQL Server Radio (by Guy Glantser and Matan Yungman)
- SQL Data Partners (by Carlos L Chacon, César Oviedo and Adrian Miranda)
- Away from the Keyboard (by Cecil Phillip and Richie Rump)
- RunAs Radio (by Richard Campbell and Greg Hughes)
- People Talking Tech (by Denny Cherry)
- NET Rocks! (by Richard Campbell and Carl Franklin)
- SQL Down Under Podcast (by Greg Low)
- Free sql server video tutorials for beginners (by PRAGIM Technologies)
- Курсы
- Бесплатные
- Codecademy Learn SQL (Бесплатно)
- Codecademy SQL: Table Transformation (Бесплатно)
- Codecademy SQL: Analyzing Business Metrics (Бесплатно)
- MVA SQL Server Courses (Бесплатно)
- Платные
- Lynda Courses (Платно)
- Veeam Free Courses (Платно)
- SQLSkills Trainings (Платно)
- Brent Ozar Team Trainings (Платно)
- Pluralsight Courses (Платно)
- Бесплатные
- Обратная Совместимость
- 2016 Backwards Compatibility
- 2014 Backwards Compatibility
- 2012 Backwards Compatibility
- 2008 R2 Backwards Compatibility
- 2008 Backwards Compatibility
- 2005 Backwards Compatibility
- Другое
- SQL Server Management Studio
- Лучшее решение для бэкапов и управления индексами Ola Maintenance Solution
- SQL Server First Responder Kit
- SQL# CLR functions (by Sql Quantum Leap)
- SSIS Performance Benchmarks
- Statistic Parser (by Richie Rump)
- Using Excel to parse Set Statistics IO output (by Vicky Harp)
- SQL Generator (by Richie Rump)
- Columnstore Indexes Scripts Library (by Niko Neugebauer)
- Stackoverflow SQL Server
- DBA Stackexchange SQL Server
- BIMLScript Learn resource
- SQL Server Connection Strings
- SQL Injection Cheat Sheet (by Ferruh Mavituna)
- RSS Most Recent SQL Server KBs
- Stackoverflow SQL Anti Patterns
- SQL Server Latch Classes Library (by Paul S. Randal)
- Azure Speed (by Blair Chen)
- SQLFiddle
- Practical skills of SQL language (Русский)
Практический курс для новичков по SQL и PostgreSQL на udemy.com

| Длительность | 21,5 часа |
| Уровень | С нуля |
| Для кого подходит | Начинающим разработчикам, новичкам |
| Формат | Видеолекции + домашнее задание |
| Итоги | Сертификат |
| Цена | ● Полная – 7 290 рублей; ● гарантия возврата оплаты курса в течение 1 месяца. |
| Ссылка на курс |
Учебный план состоит из следующих тем:
Преподаватели:
Илья Фофанов — инженер-программист, организатор митапов MskDotNet.
DevSchool, Progressive Training Solutions.
Чему вы научитесь после окончания курса:
- работать с запросами и разными типами данных;
- создавать БД и таблицы;
- сортировать и группировать данные;
- обеспечивать безопасность хранения данных.
Мои впечатления: Небольшой курс с практическим уклоном для новичков в программировании. Вы с нуля освоите понятия базы данных и запросов, функций, транзакций и операций с данными. Вы сможете участвовать в разработке безопасных приложений и сервисов. Это ценный навык в современном мире, поэтому вы без работы точно не останетесь!
Бесплатные SQL Server и R книги
SQL Server:
- Avesome Red Gate ebooks
- Microsoft huge collection
- Microsoft large collection
- Microsoft MVA Free ebooks
- OnlineVideoLectures ebooks
- Brent Ozar ebooks
- E-books SQL Server Directory
- TOAD SQL Server ebooks
- Syncfusion Techportal
- Modern Storage Strategies for SQL Server
- Migrating SQL Server Databases to Azure
- SQL Sentry Free eBooks
R:
- FreeComputerBooks R EBooks
- Effective Graphs with Microsoft R Open
- Little Book of R for Time Series (by Avril Coghlan)
- Little Book of R for Biomedical Statistics (by Avril Coghlan)
- Little Book of R for Multivariate Analysis (by Avril Coghlan)
Update 2016-07-21: Добавлены SQLFiddle и sql-ex.ruUpdate 2016-07-19: Добавлен russianVC, спасибо @AlanDentonUpdate 2016-07-19: Исправлены ссылки Backwards Compatibility (и добавлена для SQL Server 2016), спасибо @Tsyoma
Оператор insert into: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
В начале добавим город в таблицу городов:
При добавлении записи не обязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодняшний день.
При определении таблицы weather_log мы решили ссылаться на город, путём записи в поле city_id идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор . Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
Оператор create table: создание таблиц
Создав новую БД, сообщим MySQL, что теперь мы собираемся работать именно с ней.
Выбор активной БД выполняется командой:
Пришло время создать первые таблицы!
Для ведения дневника по всем правилам, понадобится создать три таблицы: города (cities), пользователи (users) и записи о погоде (weather_log).
В подразделе «Запись» этой главы описано, как должна выглядеть структура таблицы weather_log. Переведём это описание на язык SQL:
Чтобы ввести многострочную команду в командной строке используйте символ в конце каждой строки (кроме последней).
Теперь создадим таблицу городов:
MySQL может показать созданную таблицу, если попросить об этом командой: .
В ответе будут перечислены все поля таблицы, их тип и другие характеристики.
Первичный ключ
В примере с созданием новой таблицы при перечислении необходимых полей первым полем идёт .
Это поле называется первичным ключом. Обязательно создавать первичный ключ в каждой таблице.
Первичный ключ — это особенное поле, в котором сохраняется уникальный идентификатор записи. Он нужен, чтобы у программиста и базы данных всегда была возможность однозначно обратиться к одной конкретной записи для её чтения, обновления или удаления.
Если назначить поле первичным ключом, то БД будет следить за тем, чтобы значение в этом поле больше не повторялось в таблице.
А если ещё и добавить аттрибут , то MySQL при добавлении новых записей будет заполнять это поле сама. будет играть роль счётчика — каждая новая запись в таблице получит значение на единицу больше максимального существующего значения.
Язык структурированных запросов (SQL)
После того, как вы выбрали подходящую для вас СУБД и установили её, следующим шагом было бы создание таблиц и управление данными. Для этого мы можем воспользоваться специальным языком SQL.
Создание БД development:
CREATE DATABASE development;
Создание таблицы Users:
CREATE TABLE users ( full_name VARCHAR(100), username VARCHAR(100) );
Добавление записи:
INSERT INTO users (full_name, username) VALUES ("Boris Hadjur", "_DreamLead");
Извлечение всех записей пользователя _DreamLead:
SELECT text, created_at FROM tweets WHERE username="_DreamLead";
Обновление записи:
UPDATE users SET full_name="Boris H" WHERE username="_DreamLead";
Удаление записи:
DELETE FROM users WHERE username="_DreamLead";
SQL очень похож на человеческий язык (английский). В каждом СУБД SQL обладает рядом собственных особенностей и различий, но в целом, все разновидности SQL похожи друг на друга.
Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — .
Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
Важно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (weather_log.city_id) первичному ключу города из тб2 (cities.id).
О выборе SQL-баз данных
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
Курс «SQL для анализа данных» от Skillbox
Сайт — skillbox.ru Длительность обучения — 3 месяца. Стоимость обучения — 29 400 рублей единовременно или 2 450 рублей в месяц в рассрочку на год.
Этот курс предназначен для маркетологов, которые научатся обрабатывать данные без привлечения разработчиков и смогут принимать правильные решения. Менеджеры и бизнесмены смогут самостоятельно получать данные из баз, анализировать их и на основе анализа принимать бизнес-решения. Аналитики освоят БД, научатся делать запросы и смогут работать над сложными проектами и задачами.
Программа курса:
- SQL Server и анализ данных, первые самостоятельные запросы;
- операторы, фильтры, вычисления;
- группировка данных и использование функций;
- агрегатные функции, вложенные запросы, объединение и модификация таблиц;
- подготовка данных и выгрузка их в Excel;
- оконные функции.
Студенты, оплатившие курс, получат доступ к бонусным программам — английский для IT-специалистов, собеседование на английском, бизнес-английский, подготовка к IELTS.
После изучения материалов каждого урока студенты выполняют практические задания, которые проверяет преподаватель. Доступ в закрытый телеграм-чат поможет найти единомышленников и даст возможность разобраться в трудных вопросах.
Уровни работы с данными
- Слой доступа к данным, который удобно использовать из языков программирования;
- Слой хранения. Это отдельный слой, потому что обычно хранить данные удобно другими способами, чем использовать: эффективно по памяти, выравнивать, складывать на диск. Это к вопросу о schemaless: схема, которая удобна для хранения, не удобна для доступа.
- «Железо» — слой, где лежат данные, причем там они организованы еще третьим способом, потому что дисками управляет операционная система, и общаются они только через драйвер. В этот уровень мы не будем сильно вникать.
Для слоя доступатребования
- Универсальность, чтобы возможно было с помощью любой технологии запрашивать данные.
- Оптимальность этого запроса. Метод доступа должен быть такой, чтобы хорошо и удобно доставать данные из базы.
- Параллелизм, потому что сейчас все масштабируются, разные серверы одновременно обращаются к базу за одними и теми же данными. Надо сделать так, чтобы максимально использовать преимущества параллелизма и быстрее обрабатывать данные таким способом.
Для слоя храненияизначального параллелизманадежноДля «железа»доступ к даннымSQLSQL не нуженSQL опять возвращаетсяВся математика оптимизации завязана вокруг реляционной алгебрыВ слое храненияДля «железа»
Что это такое
Sql — язык структурированных запросов. Создан для определения типа данных, предоставления доступа к ним и обработке информации за короткие промежутки времени. Он описывает компоненты или какие-то результаты, которые вы хотите видеть на интернет-проекте.
Если говорить по-простому, то этот язык программирования позволяет добавлять, изменять, искать и отображать информацию в БД. Популярность mysql связана с тем, что он используется для создания динамических интернет-проектов, основа которых составляет база данных. Поэтому для разработки функционального блога вам необходимо выучить этот язык.

СУРБД и NoSQL
В наши дни у вас есть выбор из двух основных СУБД. Это либо старая добрая реляционная СУБД, либо новая, но уже обкатанная NoSQL система. Если вдруг вы не понимает о чём идёт речь, я объясню основы каждой системы.
СУРБД — Система Управления Реляционными Базами Данных. Согласно Википедии, реляционная модель — это модель организации данных, в одной или нескольких таблицах, состоящих из строк и столбцов, где каждая строка имеет уникальный идентификационный ключ. Если вы совершенно не понимает о чём идёт речь, представьте себе простую электронную таблицу из строк и столбцов.
Электронные таблицы не сравнятся с мощью СУБД, это лишь упрощённая аналогия, для визуального представления. Связанные между собой данные, хранятся в таблицах внутри базы данных.
Базы данных NoSQL — это группы, различных по типу СУБД, которые хранят связанные данные вместе. Базы данных NoSQL предлагают нам механизм хранения и извлечения данных, отличный от табличного, который используют реляционные базы.
Базы NoSQL можно представить, как большой JSON-документ, или хранилище «ключей». За этим скрыто намного больше, но в качестве введения — этого достаточно. Если вы понятия не имеете, что такое JSON, ключи и значения ― что же, нам предстоит немало потрудиться. И мы сделаем это.
Я рекомендую сначала изучить СУРБД и набраться опыта. После того как вы освоитесь в большинстве баз этого типа, можете переходить к изучению NoSQL.
Ознакомьтесь с этими базами данных: PostgreSQL, MS SQL Server, и MySQL.
Курс «Проектирование БД и запросы SQL» от geekbrains

| Длительность | 20 часов |
| Уровень | Начинающие |
| Для кого подходит | Начинающим аналитикам и разработчикам |
| Формат | Видеолекции + домашнее задание + обратная связь от ментора |
| Итоги | Сертификат + проекты в портфолио |
| Цена | 5 500 рублей |
| Ссылка на курс |
Учебный план состоит из следующих тем:
- проектирование базы данных;
- SQL-команды;
- согласованность данных и ключи;
- объединение данных с помощью операторов;
- агрегирующие функции;
- индексы и транзакции.
После окончания курса вы сможете:
- проектировать базы данных;
- писать SQL-запросы;
- устанавливать и работать с СУБД MySql;
- редактировать БД в визуальном режиме.
Мои впечатления: Программа обучения рассчитана на тех, кто хочет за короткий срок освоить новую профессию в сфере аналитики. Вы научитесь работать с MySQL, что поможет вам занять своё место в разработке игр, сайтов и сервисов. Вы поработаете с инструментом для визуального проектирования баз данных и писать SQL-запросы. Трудоустройства не предоставляется, но полезные практические знания у вас точно будут!
Получить скидку →
Роли специалистов по базам данных
- Администратор баз данных ― как системный администратор, только по базам данных. Администратор ― наблюдает, настраивает, делает резервные копии, поддерживает и обновляет СУБД, которые вы используете каждый день.
- Разработчик баз данных ― проектирует решения. Такой специалист проводит дни напролёт, погрузившись в базах данных с головой. Пишет ПО, для работы с большими, и не очень, массивами данных. Разработчик проектирует базы данных, а администратор обслуживает их.
- ETL разработчик ― занимается перемещением данных из одной системы в другую. Аббревиатура ETL расшифровывается, как Extract, Transform, Load (извлечь, преобразовать и загрузить). Данные, извлечённые из одной базы, должны «вписаться» в другую. Для решения таких задач существует специальное ПО, но за три года работы на этой должности, я никогда не использовал его. Мы создавали собственные PL/SQL пакеты в Oracle, которые делали тоже, что и дорогое стороннее ПО. Но разработчики тоже стоят не дёшево, так была ли экономия?
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Отношения между таблицами
Отношения между таблицами устанавливают связь
между данными находящимися в разных таблицах
базы данных.
Отношения между таблицами определяются
отношением между группами объектов
соответствующего типа. Например, один автор
может написать несколько книг и издать их в
разных издательствах. Или издательство может
опубликовать несколько книг разных авторов.
Таким образом, между авторами и названиями книг
существует отношение один-ко-многим, а между
издательствами и авторами существует отношение
много-ко-многим.
Отношения между таблицами базы данных BIBLIO.MDB
показаны на рис.1.9.
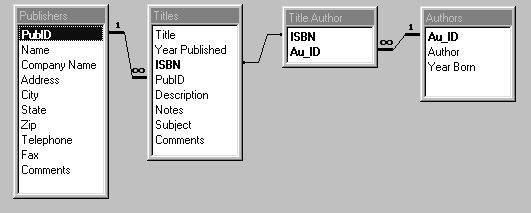 Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.
Рис.1.9. Отношения между таблицами базы данных BIBLIO.MDB.Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
- Откройте командную строку (Выполнить: cmd.exe).
- Перейдите в каталог с установленной MySQL: .
- Выполните: .
- Введите пароль, заданный при установке.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой
Системы Управления Базами Данных
Теперь, когда у нас есть реляционная БД, каким образом мы можем её имплементировать? Для этого мы можем воспользоваться системами управления базами данных (СУБД). Существует целый набор подобных программ, как платных, так и бесплатных. Среди платных можно выделить Oracle Database, IBM DB2 и Microsoft SQL Server. Бесплатные: MySQL, SQLite и PostgreSQL.
Чаще всего различные компании используют MySQL. Twitter в этом смысле — не исключение.
SQLite чаще используется при разработке приложений для iOS и Android, где хранится различного рода конфиденциальная информация. Браузер Google Chrome использует SQLite для хранения истории просмотров, кукисов, изображений…
PostgreSQL используется реже. Для неё существует полезное расширение PostGIS, которое делает данную СУБД удобной для хранения геолокационных данных. К примеру сервис OpenStreetMap исользует PostgreSQL.
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Описание курса
Курс по SQL на Self-Learning.ru – это уникальный курс по SQL, который ориентирован на изучение языка SQL как стандарта, чтобы после прохождения курса можно было использовать язык SQL в любой СУБД.
Дело в том, что SQL – это вроде как стандарт, который должен быть реализован во всех СУБД, но каждая СУБД отклоняется от этого стандарта и применяет свою реализацию SQL, свой диалект SQL, т.е. свой синтаксис. Даже синтаксис казалось бы стандартных конструкций в разных СУБД может отличаться и человеку, который прошёл курс по SQL на примере какой-то одной СУБД, придётся доучиваться и обновлять свои знания, в случае если у него возникнет необходимость работать с другой СУБД, отличной от той, которая использовалась на курсе.
Поэтому я решил создать универсальный курс по SQL, который не будет привязан к какой-то конкретной СУБД, иными словами, после прохождения которого можно было бы работать с SQL в любой СУБД.
Если в каких-то даже стандартных возможностях языка SQL есть отклонения в той или иной СУБД, то на курсе все это подробно комментируется и показывается реализация для нескольких популярных СУБД.
Данный курс предназначен для начинающих, в нем используется последовательная методика обучения, поэтому начинать Вы будете с основ, плавно переходя к более сложным темам.
После прохождения курса Вы научитесь писать универсальные SQL запросы, которые будут выполняться во всех популярных СУБД: и в MySQL, и в PosrgreSQL, и в Microsoft SQL Server, тем самым Вам не нужно будет задумываться о том, с какой СУБД Вам предстоит работать.
Именно это и нужно большинству программистов, которые разрабатывают сайты и небольшие клиентские приложения, т.е. им нужны базовые знания языка SQL, чтобы уметь взаимодействовать с базами данных.
При разработке этого курса я учел все замечания и пожелания, которые получал от студентов курса по T-SQL. Например, при опросе своих студентов я всегда спрашиваю, чего им не хватает, и что бы они добавили на курс, и многие отвечали, что им не хватает практики, в частности каких-то реальных заданий, в этом курсе я все это учел, и курс по SQL включает очень много заданий, он включает очень много проверочных тестов, он включает итоговый экзамен, на котором студенту предстоит очень серьезное испытание, состоящее из двух этапов:
- Теоретический (тестирование)
- Практический (реализация итогового проекта)
Отношение один-ко-многим
Хорошим примером отношения между таблицами
один-ко-многим является отношение между авторами
и названиями книг (таблицы AUTHORS и TITLES), так как
каждый автор может иметь отношение к созданию
нескольких книг. Связь между таблицами AUTHORS и TITLES
осуществляется с помощью совпадающих полей Au_ID в
обеих таблицах.
Аналогичное отношение существует между
издательствами и названиями изданных книг,
организацией и работающими в ней сотрудниками,
автомобилем и деталями, из которых он состоит и
т.п. Понятно, что подобный тип отношения между
таблицами наиболее часто встречается при
проектировании структуры баз данных.