Как закрыть сайт от индексации поисковых машин в wordpress
Содержание:
- Проверка файла
- Закрыть весь сайт от индексации в файле .htaccess
- Для чего вообще закрывать внешние ссылки от индексации поисковиками?
- Как в Битрикс закрыть сайт от индексации
- Результаты эксперимента: варианты JS
- Закрытие от индексации элементов на страницах сайта
- Что такое индексация сайта
- Как увидеть http — https проблему индексации?
- Как закрыть сайт от индексации посредством файла htaccess
- Закрытие от индексации страниц сайта
- Настройка файла robots.txt: основные директивы
- Методы, с которыми нужно работать осторожно:
Проверка файла
Если с помощью robots.txt закрыть сайт от индексации у вас получилось, но вы не знаете, сработали ли правильно все ваши директивы, можно проверить корректность работы.
Для начала нужно снова проверить размещение документа. Помните, что он должен быть исключительно в корневой папке. Если он попал в подкорневную папку, то работать не будет. Далее открываем браузер и вводим туда следующий адрес: «http://вашсайт. com/robots.txt» (без кавычек). Если в веб-обозревателе появилась ошибка, значит, файл находится не там, где должен.

Директивы проверить можно в специальных инструментах, которые используют практически все веб-мастера. Речь идет о продуктах Google и Yandex. Например, в Google Search Console есть панель инструментов, где нужно открыть «Сканирование», а после запустить «Инструмент проверки файла robots.txt». В окно необходимо скопировать все данные с документа и запустить сканирование. Точно такую же проверку можно сделать в «Яндекс. Вебмастер».
Закрыть весь сайт от индексации в файле .htaccess
Ну и последний пункт, это использование файла .htaccess. Это один из файлов настройки, который находится в корневой папке хостинга, то есть, там же, где находится и файл robots.txt. Однако, на некоторых хостингах, этот файл может быть недоступным (обычно на бесплатных хостингах, он недоступен).
Для того, чтобы закрыть файл, достаточно прописать в этом файле всего одну строчку:
deny from all
Но не торопитесь этого делать. Дело в том, что данная команда, закрывает вообще весь сайт, и не только от поисковых роботов, но и от людей тоже. И если ваш сайт использует доступ через админскую панель, то и она (админская панель), будет закрыта. Доступ к сайту будет только через FTP.
Но кроме полного закрытия сайта, можно просто поставить пароль на сайт. И это абсолютный метод, благодаря которому, вы сможете закрыть свой сайт от поисковых систем. Ну а как поставить пароль на сайт через файл .htaccess, смотрите в видео.
Для чего вообще закрывать внешние ссылки от индексации поисковиками?
Причин этому несколько, давайте рассмотрим немного подробнее.
1. Внешние ссылки передают вес страниц Вашего блога на страницы на которые Вы ссылаетесь, при этом сами они теряют этот вес.
В основе алгоритма поискового ранжирования с самого начала его существования лежит принцип передачи ссылочного веса. То есть, чем больше авторитетных сайтов ссылаются на Ваш блог, тем более авторитетным в глазах поисковиков становится и Ваш ресурс.
Но есть и обратная сторона этого вопроса, чем больше внешних ссылок ведет с Вашего сайта, тем меньше становится его вес.
Это конечно грубо сказано, есть много других факторов влияющих на вес страниц, но ссылки – один из основных.
Следовательно, чтобы повысить авторитетность своего блога в глазах поисковых систем при равных остальных условиях нужно минимизировать количество внешних ссылок.
Как в Битрикс закрыть сайт от индексации
Для этого нужно использовать метатег <meta name=»robots» content=»noindex, nofollow»>. Для скрытия какой-либо страницы от индексирования нужно, добавляя или изменяя условия, выбрать пункт «Закрыть от индексации».

Кроме того, возможно отключение индексации всех страниц с подключенным компонентом sotbit:seo.meta. Для этого нужно зайти в общие настройки модуля SEO умного фильтра и включить опцию «Отключить индексацию всех страниц».
Приоритетными будут настройки индексации в условии, а не эта опция. То есть в случае отключения в настройках условия опции «Закрыть от индексации» страница, удовлетворяющая этому условию, будет проиндексирована.
Результаты эксперимента: варианты JS
После переиндексации экспериментальных документов и на основании изучения текстовой версии сохраненных копий документов в Яндексе и Google, был сделан вывод о том, какие варианты скрытия ссылок поисковые системы не смогли распознать.
Как видит Google?

Рис. 7. Сохраненная копия в Google.
Яндекс и Google распознали в данном блоке ссылки только в 2 из 5 случаев, когда в коде в явном виде был указан URL акцептора. В остальных случаях поисковые системы интерпретировали данные блоки как обычный текст.
На основании полученных данных можно сделать вывод о том, что представленные ниже варианты JavaScript позволяют скрывать ссылки и прочий контент от индексации.
1. <input type=»button» value=»текст» class=»button_buy» onclick=»javascript:window.location=’/samostoyatelno/stati/indeksatsiya/301-redirekt.html'»/>
2. <a href=»#» onclick=»javascript:window.open(‘ht’+’tp’+’://’+’www’+’.pixel’+’plus’+’.’+’ru’)»>анкор</a>
3. <a href=»#» onclick=»javascript:window.location=’/samostoyatelno/stati/indeksatsiya/301-redirekt.html'» >анкор</a>
В качестве дополнительной проверки эффективности методики произведем поиск указанных в эксперименте текстов ссылок в анкор-листе акцепторов используя оператор расширенного поиска Google — allinanchor.
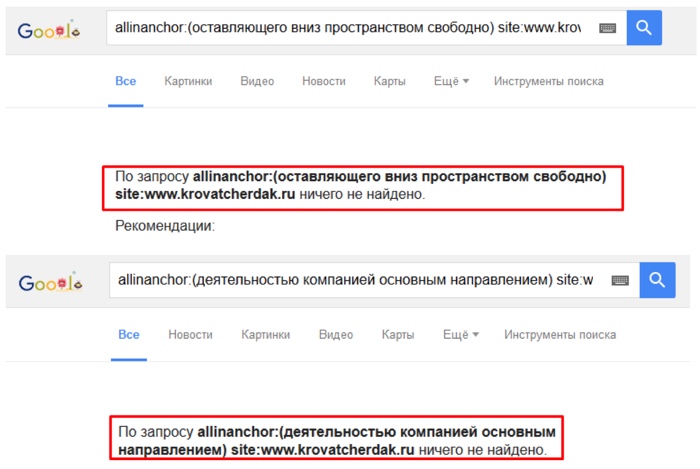
Рис. 8. Проверка наличия текстов ссылок в анкор-листе акцепторов.
Как можно видеть, в анкор-листе страниц акцепторов также отсутствуют тексты анализируемых ссылок.
Закрытие от индексации элементов на страницах сайта
SEO-тег <noindex>
SEO-тег <noindex> не используется в официальной спецификации html, и был придуман Яндексом как альтернатива атрибуту nofollow. Пример корректного использования данного тега:
<!—noindex—>Любая часть страницы сайта: код, текст, который нужно закрыть от индексации<!—/noindex—>
Примеры использования тега <noindex> для закрытия от индексации элементов на страницах сайта:
- нужно скрыть коды счетчиков (liveinternet, тИЦ и прочих служебных);
- запрятать неуникальный или дублирующийся контент (copypast, цитаты и пр.);
- спрятать от индексации динамичный контент (например, контент, который выдается в зависимости от того, с какими параметрами пользователь зашел на сайт);
- чтоб хотя бы минимально обезопасить себя от спам-ботов, необходимо закрывать от индексации формы подписки на рассылку;
- закрыть информацию в сайдбаре (например, рекламный баннер, текстовую информацию, как это сделала Розетка).

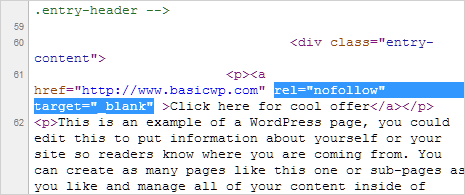
Атрибут rel=»nofollow»
Если к ссылке добавить атрибут rel=»nofollow», тогда все поисковые системы, которые поддерживают стандарты Консорциума Всемирной паутины (а к ним относятся и Яндекс и Google) не будут учитывать вес ссылки при расчете индекса цитирования сайта.
Примеры использования атрибута rel=»nofollow» тега <a>:
- поощрение и наказание комментаторов вашего сайта. Т.е. спамерские ссылки в комментариях либо можно удалять, либо закрывать в nofollow (если ссылка тематична, но вы не уверены в ее качестве);
- рекламные ссылки или ссылки, размещенные «по бартеру» (обмен постовыми);
- не передавать вес очень популярному ресурсу, типа Википедии, Одноклассников и пр.;
- приоритезация сканирования поисковыми системами. Лучше закрыть от перехода по ссылкам для ботов Ваши формы регистрации.
SEOhide
Спорная технология, в сути которой с помощью javacript скрывать от поисковиков ненужный с точки зрения SEO-специалиста контент. А это «попахивает» клоакингом, когда пользователи видят одно, а поисковики – другое. Но давайте посмотрим на плючсы и минусы данной технологии:
Плюсы:
+ корректное управление статическим и анкорным весом;
+ борьба с переспамом (уменьшение количества ключевых слов на странице, так называемый показатель «тошноты» текста);
+ можно использовать для всех поисковых систем без ограничений, как в случае с noindex;
Минусы:
— вскоре поисковые системы научатся индексировать JS;
— в данный момент данная технология может быть воспринята поисковиками как клоакинг.
Подробнее об этой технологи смотрите в видео:
https://youtube.com/watch?v=ULUajs3bgN8
Статья написана в соавторстве с Дарьей Мшанецкой, SEO-специалистом маркетингового агентства МАВР
Что такое индексация сайта
Индексация – процесс, результат которого можно сравнить, например, с рентгеновским снимком. Пауки поисковых систем выступают в роли рентген-аппарата, сканируя страницы ресурса и добавляя информацию о них в общую базу данных (или индекс). Краулеры также исполняют роль доктора, в реальной жизни призванного описать снимок. Они не просто фиксируют наличие сайта, но и оценивают контент, юзабилити и другие характеристики, которые напрямую влияют на позиции в рейтинге (или поисковой выдаче). Оценив наполнение и классифицировав ресурс как нечто интересное и полезное, роботы предоставят сайту более выгодные места в выдаче и наоборот.

Получая релевантные ответы на запрос, пользователи даже не задумываются, какой объем работы был проведен роботами поисковых систем для составления перечня ресурсов, на которых представлена требуемая информация. Не догадываются посетители и о трудах, затраченных владельцами сайтов, чтобы интернет-площадки занимали лучшие места в выдаче. Иногда для этого приходится на некоторое время «прятать» ресурс от поисковых ботов для дальнейшей индексации его как полезного и отвечающего всем требованиям посетителей.
У каждой системы разработаны сложнейшие алгоритмы, по которым ведется работа поисковых пауков. Но и «Яндекс», и Google оценивают контент с точки зрения интереса и пользы, приносимой пользователям.
Индексации подвергаются:
текст;
графика (фотографии и картинки);
видео (факт наличия видеоконтента, количество просмотров);
мета-теги (указатели для роботов, позволяющие фиксировать их внимание на важных моментах страницы).
Когда информация о сайте заносится в поисковые базы, ресурс включается в рейтинг, который предстает вниманию пользователя в ответ на соответствующий запрос.

Кажется, совсем недавно достаточно было максимально наполнить текст ключевыми словами, чтобы упростить работу поискового паука и спокойно ожидать появления сайта в ТОПе. Теперь перенасыщение ключами не просто не помогает, а является прямой угрозой попадания под санкции.
Поисковые системы уважают пользователей и заботятся об их удобстве. Разве интересно человеку читать текст, состоящий из ключевых фраз, которые никак не согласуются между собой? Конечно, нет. Более того, не понравится подобный текст и роботам, искусственный интеллект которых развивается в геометрической прогрессии. Они могут «обидеться» всерьез и, признав контент переоптимизированным и бесполезным, отказаться индексировать ресурс вовсе. Наказание может быть и мягким, заключающимся в потере позиций в выдаче, но в любом случае ничего хорошего в некачественном контенте нет. А ведь пауки интересуются еще и навигацией по сайту (удобна ли она пользователям), оценивают юзабилити, ссылочную массу и др.
Наиболее популярен среди владельцев вопрос об ускорении индексации сайта, но иногда возникает необходимость в обратном: лишить роботов возможности оценивать ресурс (полностью или отдельные части).
Как увидеть http — https проблему индексации?
1 Набираем в строке поиска Google.com и Google.ru ( так как результаты могут быть разные ! ) site: и затем: сразу, без пробелов url вашего сайта, например, site:moisait.ru
2 Смотрим результат.
3 Если чужих страниц нет, то это хорошо, но рано радоваться … ваши https страницы могут появиться на чужих http сайтах на этом же хостинге, т.е. дубли всё же будут!
4 Если чужие страницы есть в поиске по вашему сайту, то нужно решать эту проблему!
Решение 1
Закрыть https версию сайта в robots.txt
Замечание Перечисленные ниже варианты предназначены для серверов Linux.
5 Создаём, кроме robots.txt в корне сайта и новый файл, например:https.txt, в нём будем запрещать индексирование https страниц стандартным способом:
6 Теперь, пробуем сделать вариант переадресации для https на https.txt, который работает в 50% случаев. Открываем в корне сайта файл .htaccess и сразу же после строки RewriteEngine on добавляем:
7 Проверяем работает переадресация или нет
Набираем в строке http://moisait.ru/robots.txt https://moisait.ru/robots.txt и вы должны увидеть РАЗНЫЕ файлы robots.txt, если не забыли заменить moisait.ru на реальный URL вашего сайта.
Если Решение 1 не работает?
Решение 1.1
8 Внимательно смотрим и сравниваем содержимое файлов robots.txt http://moisait.ru/robots.txt https://moisait.ru/robots.txt если они отличаются, — это или хорошо или очень плохо
нужно выяснить откуда ( с какого URL ) https тянет файл роботс.
Если есть строка Host: — хорошо — вы узнали, какой это сайт ( назовём его, для удобства drygoy-sait.ru) , ещё один простой вариант узнать «где собака зарыта» вместо http://moisait.ru/ открываем https://moisait.ru/, и если это совсем другой сайт (drygoy-sait.ru), то именно в нём и будем проводить правки! Если и это не помогло — … нужно искать поиском или перебором!
Итак, мы нашли https сайт (drygoy-sait.ru)!
И если мы применим в файле .htaccess в корне сайта drygoy-sait.ru стандарное правило из пункта 6, то мы закроем по протоколу https от индексации, как требуется, не только все сайты типа http://moisait.ru/, но и все https сайты, в том числе и нужный нам, или кому-то https://drygoy-sait.ru!!!
Следовательно: вариант 6 не применяем! Что делать ? … и кто виноват? 🙂
9 Задача: разрешить индексацию robots всем https сайтам и запретить индексацию страниц сайта всем сайтам, имеющим http протокол.
Решение: создаем правила типа условное выражение в htaccess такого вида:
10 Подводим Итог
Другими словами, для того, чтобы запретить индексацию на https://moisait.ru вам потребуется открыть drygoy-sait.ru, создать там https.txt с запретом: и там же в файле htacces ( в корне сайта) прописать правила из пункта 9 для каждого вашего сайта: moisait 1, 2, 3.ru
Вот такие пирожки с ….
https://moisait.ru
Решение 1.2
Решение 2
Замечание Предлагаемое решение работает на серверах с Nginx.
Если у вас сервер с NginX делаем подмену файла robots на https.txt
1
пролистываем все location после закрывающей скобки } вставляем :
# редиректим robots.txt для https на https.txt
location = /robots.txt {
if ($server_port = 443) {
rewrite ^ /https.txt last;
}
}
Решение 3
Как закрыть сайт от индексации посредством файла htaccess
Иногда роботы игнорируют данные им рекомендации не сканировать сайт, не обращают внимания на пароли. В таком случае приходится прибегать к глубинным изменениям, касающимся серверных настроек. Главным героем становится файл .htacces, куда вписываются определенные коды, позволяющие ресурсу сказать краулерам: «Стоп!».
Способ 1.
В файл .htaccess вписываем следующий код:
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
SetEnvIfNoCase User-Agent «^Yahoo» search_bot
SetEnvIfNoCase User-Agent «^Aport» search_bot
SetEnvIfNoCase User-Agent «^msnbot» search_bot
SetEnvIfNoCase User-Agent «^spider» search_bot
SetEnvIfNoCase User-Agent «^Robot» search_bot
SetEnvIfNoCase User-Agent «^php» search_bot
SetEnvIfNoCase User-Agent «^Mail» search_bot
SetEnvIfNoCase User-Agent «^bot» search_bot
SetEnvIfNoCase User-Agent «^igdeSpyder» search_bot
SetEnvIfNoCase User-Agent «^Snapbot» search_bot
SetEnvIfNoCase User-Agent «^WordPress» search_bot
SetEnvIfNoCase User-Agent «^BlogPulseLive» search_bot
SetEnvIfNoCase User-Agent «^Parser» search_bot.
Запрет боту каждой поисковой системы прописывается отдельной строкой. Ознакомившись со специальным кодом, пауки понимают, что сайт закрыт от индексации, и переходят на другой ресурс.
Способ 2.
Прописать в файле .htaccess ответ сервера для каждой страницы, которую необходимо скрыть:
Ответ сервера – 403. Доступ к ресурсу запрещен — код 403 Forbidden.
Либо:
Ответ сервера — 410. Ресурс недоступен — окончательно удален.
Пароль на запрет индексации предполагает введение в файл .htaccess следующего кода:
AuthType Basic
AuthName «Password Protected Area»
AuthUserFile /home/user/www-auth/.htpasswd
Require valid-user
home/user/www-auth/.htpasswd.
Пароль задается владельцем сайта, которому также следует обозначить себя в коде, добавив имя пользователя (UserName):
htpasswd -c /home/user/www-auth/.htpasswd UserName.
Закрытие от индексации страниц сайта
Существует три способа закрытия от индексации страниц сайта:
- использование мета-тега «robots» (<meta name=»robots» content=»noindex,nofollow» />);
- создание корневого файла robots.txt;
- использование служебного файла сервера Apache.
Это не взаимоисключающие опции, чаще всего их используют вместе.
Закрыть сайт от индексации с помощью robots.txt
Файл robots.txt располагается в корне сайта и используется для управления индексированием сайта поисковыми роботами. С помощью набора инструкций можно разрешить либо запретить индексацию всего сайта, отдельных страниц, каталогов, страниц с параметрами (типа сортировки, фильтры и пр.). Его особенность в том, что в robots.txt можно прописать четкие указания для конкретного поискового робота (User-agent), будь то googlebot, YandexImages и т.д.
 Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Для того, чтобы обратиться сразу ко всем поисковым ботам, необходимо прописать диерективу «User-agent: *». В таком случае, поисковик прочитав весь файл и не найдя конкретных указаний для себя, будет следовать общей инструкции.
Все о файле robots.txt и о том, как его правильно составить читайте здесь, а также рекомендации по использованию этого файла от Яндекс и .
Например, ниже приведен файл robots.txt для сайта «Розетки»:
Как видим, сайт закрыт от индексации для поисковой системы Yahoo!
Зачем закрывать сайт от поисковых систем?
Лучше всего Robots.txt использовать в таких случаях:
- при полном закрытии сайта от индексации во время его разработки;
- для закрытия сайта от нецелевых поисковых систем, как в случае с Розеткой, чтоб не нагружать «лишними» запросами свои сервера.
Во всех остальных случаях лучше использовать методы, описанные ниже.
Запрет индексации с помощью мeтa-тега «robots»
Meta-тег «robots» указывает поисковому роботу можно ли индексировать конкретную страницу и ссылки на странице. Отличие этого тега от файла robots.txt в том, что невозможно прописать отдельные директивы для каждого из поисковых ботов.
Есть 4 способа объяснить поисковику как индексировать данный url.
1. Индексировать и текст и ссылки
<meta name=»robots» content=»index, follow«> (используется по умолчанию) эквивалентна записи <META NAME=»Robots» CONTENT=»ALL»>
<meta name=»robots» content=»noindex, nofollow«>

3. Не индексировать на странице текст, но индексировать ссылки
<meta name=»robots» content=»noindex,follow«>
Такая запись означает, что данную страницу индексировать не надо, а следовать по ссылкам с данной страницы для изучения других страниц можно. Это бывает полезно при распределения внутреннего индекса цитирования (ВИЦ).
Что выбрать мета-тег «robots» или robots.txt?
Параллельное использование мeтa-тега «robots» и файла robots.txt дает реальные преимущества.
Дополнительная гарантия, что конкретная страница не будет проиндексирована. Но это все равно не застрахует вас от произвола поисковых систем, которые могут игнорировать обе директивы. Особенно любит пренебрегать правилами robots.txt Google, выдавая вот такие данные в SERP (страница с результатами поиска):
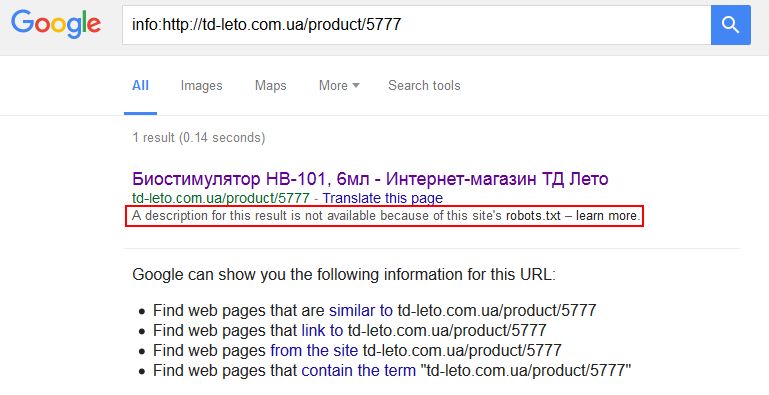
В случае, когда в robots.txt мы закрываем какой-то каталог, но определенные страницы из этого каталога нам все-таки нужны для индексации, мы можем использовать мета-тег «robots». Это же работает и в обратном порядке: в индексируемой папке (каталоге сайта) есть страницы, которые нужно запретить для индексации.
Вобщем, необходимо запомнить правило: мета-тег robots является преимущественным по сравнению с файлом robots.txt.
Подробнее об использовании мета-тегов читайте у Яндекса и .
Закрыть сайт от индексации с помощью .htaccess
.htaccess – это служебный файл веб-сервера Apache. Мэтт Каттс, бывший руководитель команды Google по борьбе с веб-спамом, утверждает, что использовать .htaccess для закрытия сайта от индексации – это самый лучший вариант и в видео рисует довольный смайлик.
С помощью регулярных выражений можно закрыть весь сайт, его части (разделы), ссылки, поддомены.
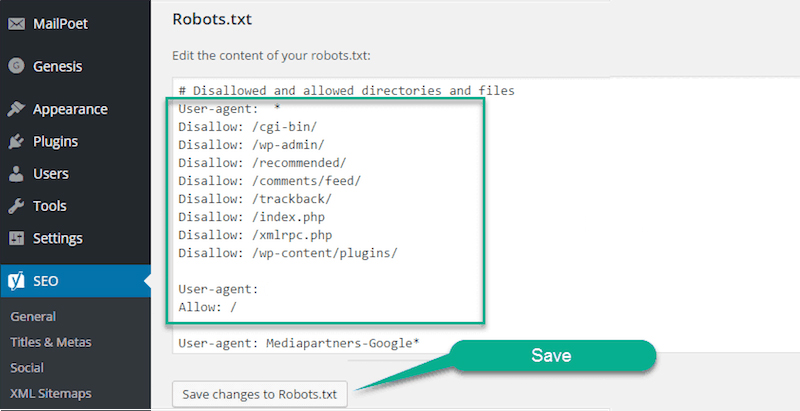
Настройка файла robots.txt: основные директивы
Чтобы правильно настроить файл robots.txt, необходимо знать директивы – команды, которые воспринимают роботы поисковых систем. Ниже рассмотрим основные директивы для настройки индексации сайта в файле robots.txt:
| Директива | Назначение |
| User-agent: | Указывает робота поисковой системы, для которого предназначены команды ниже. Названия роботов можно посмотреть в справочной информации, которую предоставляют поисковые системы. |
Директива User-agent: * обозначает, что команды ниже предназначены для всех роботов, для которых нет персональных команд в файле.
Важно соблюдать последовательность команд в файле. В начале прописываются команды для конкретных роботов (Yandex, Googlebot и т.д.), потом – для всех остальных.. Существуют другие директивы, которые используется реже
Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь
Disallow:
Данная директива в файле robots.txt закрывает индексацию определенной страницы или раздела на сайте. Сама страница или раздел указываются от корневой папки сайта, без домена (см. скриншот в начале статьи).
Allow:
Разрешает индексацию определенной страницы или раздела на сайте. Директивы Allow необходимо располагать ниже директив Disallow.
Host:
Указывает главное зеркало сайта (либо с www, либо без www). Учитывается только Яндексом.
Sitemap:
В данной директиве необходимо прописать путь к карте сайта, если она имеется на сайте.
Существуют другие директивы, которые используется реже. Посмотреть информацию обо всех директивах, которые можно настроить в файле robots.txt, можно здесь.
Частные случаи команд в файле robots.txt
Разберем некоторые команды, которые потребуются Вам в работе:
| Команда | Что обозначает |
| User-agent: Yandex | Начало блока команд для основного робота поисковой системы Яндекс. |
| User-agent: Googlebot | Начало блока команд для основного робота поисковой системы Google. |
| User-agent: *Disallow: / | Данная команда в файле robots.txt полностью закрывает сайт от индексации всеми поисковыми системами. |
| User-agent: *Disallow: /Allow: /test.html | Данные команды закрывают все документы на сайте от индексации, кроме страницы /test.html |
| Disallow: /*.doc | Данная команда запрещает индексировать файлы MS Word на сайте. Если на сайте содержится конфиденциальная информация в файлах определенного типа, имеет смысл закрыть такие файлы от индексации. |
| Disallow: /*.pdf | Данная команда в robots.txt запрещает индексировать на сайте файлы в формате PDF. Если Вы выкладываете на сайте какие-либо файлы, доступные для скачивания после оплаты или после авторизации, имеет смысл закрыть их от индексации. В ином случае данные файлы смогут найти в поисковых системах. |
| Disallow: /basket/ | Команда запрещает индексировать все документы в разделе /basket/. |
| Host: www.yandex.ru | Команда задает для сайта yandex.ru основным зеркалом адрес сайта с www. Соответственно, в поиске с высокой вероятностью будут выводиться адреса страниц с www. |
| Host: yandex.ru | Данная команда задает для сайта yandex.ru в качестве основного зеркала адрес yandex.ru (без www). |
Методы, с которыми нужно работать осторожно:
Также существует достаточно грубый метод Закрытия чего — либо от роботов, а именно запрет на уровне сервера на доступ робота к конкретному контенту.
1. Блокируем все запросы от нежелательных User Agents
Это правило позволяет заблокировать нежелательные User Agent, которые могут быть потенциально опасными или просто перегружать сервер ненужными запросами.
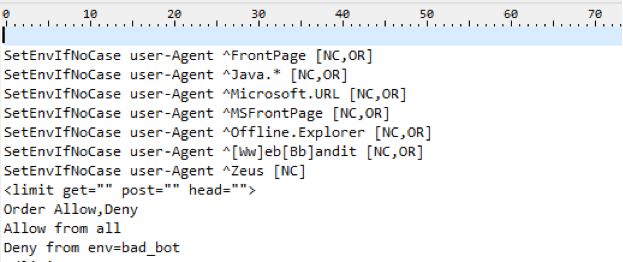
В данному случае плохим ботом можно указать Любую поисковую машину, парсер либо что либо еще.
Подобные техники используются например для скрытия от робота Ахрефса ссылки с сайта, который был создан/сломан, чтобы конкуренты сеошники не увидели истинных источников ссылочной массы сайта.
Однако это метод стоит использовать если вы точно знаете, что хотите сделать и здраво оцениваете последствия от этих действий.
Использование HTTP-заголовка X-Robots-Tag
Заголовок X-Robots-Tag, выступает в роли элемента HTTP-заголовка для определенного URL. Любая директива, которая может использоваться в метатеге robots, применима также и к X-Robots-Tag.
В X-Robots-Tag перед директивами можно указать название агента пользователя. Пример HTTP-заголовка X-Robots-Tag, который запрещает показ страницы в результатах поиска различных систем: