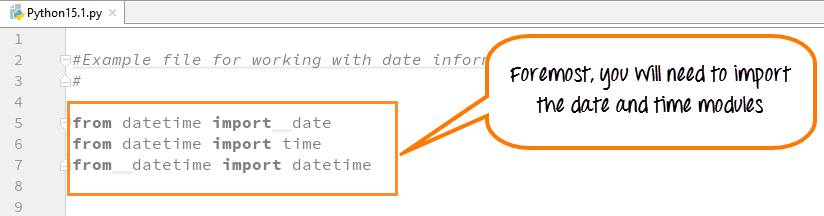
Алгоритмы поиска на python
Содержание:
- Два вида сложности
- Jump Search
- Вводная информация о строках
- Search Sorted
- Что вообще значит обойти дерево?
- Последние добавленные или измененные записи:
- Задания для самоподготовки
- Бинарный поиск
- Функция filter
- Текстовые файлы
- Группирующие скобки (…) и match-объекты в питоне
- re.compile(pattern, repl, string)
- re.match(pattern, string)
- Работа со строками
Два вида сложности
У каждого алгоритма есть временнáя и она же вычислительная сложность (time complexity) — сколько операций нужно выполнить. Также у алгоритма есть затраты памяти (space complexity) — сколько дополнительной RAM ему требуется для работы.
Очень часто эти две величины взаимосвязаны. Например, вас могут попросить уменьшить затраты по памяти, но за это придется заплатить большим количеством вычислений.
Если вы видите два пути решения с различными компромиссами время/память, обязательно проговорите с интервьюером, какой из них предпочтительнее. Интервьюер оценивает, как вы думаете
Поэтому дать понять, что вы делаете осознанный выбор на развилке — часто даже более важно, чем свернуть в нужную сторону
Jump Search
Jump Search похож на бинарный поиск тем, что он также работает с отсортированным массивом и использует аналогичный подход «разделяй и властвуй» для поиска по нему.
Его можно классифицировать как усовершенствованный алгоритм линейного поиска, поскольку он зависит от линейного поиска для выполнения фактического сравнения при поиске значения.
В заданном отсортированном массиве мы ищем не постепенно по элементам массива, а скачкообразно. Если у нас есть размер прыжка, то наш алгоритм будет рассматривать элементы входного списка в следующем порядке: , , , и так далее.
С каждым прыжком мы сохраняем предыдущее значение и его индекс. Когда мы находим множество значений (блок), где < element < , мы выполняем линейный поиск с в качестве самого левого элемента и в качестве самого правого элемента в нашем множестве:
import math
def JumpSearch (lys, val):
length = len(lys)
jump = int(math.sqrt(length))
left, right = 0, 0
while left < length and lys <= val:
right = min(length - 1, left + jump)
if lys <= val and lys >= val:
break
left += jump;
if left >= length or lys > val:
return -1
right = min(length - 1, right)
i = left
while i <= right and lys <= val:
if lys == val:
return i
i += 1
return -1
Поскольку это сложный алгоритм, давайте рассмотрим пошаговое вычисление для следующего примера:
>>> print(JumpSearch(, 5))
- Jump search сначала определит размер прыжка путем вычисления . Поскольку у нас 9 элементов, размер прыжка будет √9 = 3.
- Далее мы вычисляем значение переменной . Оно рассчитывается как минимум из двух значений: длины массива минус 1 и значения , которое в нашем случае будет 0 + 3 = 3. Поскольку 3 меньше 8, мы используем 3 в качестве значения переменной .
- Теперь проверим, находится ли наш искомый элемент 5 между и . Поскольку 5 не находится между 1 и 4, мы идем дальше.
- Затем мы снова делаем расчеты и проверяем, находится ли наш искомый элемент между и , где 6 — это 3 + jump. Поскольку 5 находится между 4 и 7, мы выполняем линейный поиск по элементам между и и возвращаем индекс нашего элемента:
4
Временная сложность jump search равна O(√n), где √n — размер прыжка, а n — длина списка. Таким образом, с точки зрения эффективности jump search находится между алгоритмами линейного и бинарного поиска.
Единственное наиболее важное преимущество jump search по сравнению с бинарным поиском заключается в том, что он не опирается на оператор деления (). В большинстве процессоров использование оператора деления является дорогостоящим по сравнению с другими основными арифметическими операциями (сложение, вычитание и умножение), поскольку реализация алгоритма деления является итеративной
В большинстве процессоров использование оператора деления является дорогостоящим по сравнению с другими основными арифметическими операциями (сложение, вычитание и умножение), поскольку реализация алгоритма деления является итеративной.
Стоимость сама по себе очень мала, но когда количество искомых элементов очень велико, а количество необходимых операций деления растет, стоимость может постепенно увеличиваться. Поэтому jump search лучше бинарного поиска, когда в системе имеется большое количество элементов: там даже небольшое увеличение скорости имеет значение.
Чтобы ускорить jump search, мы могли бы использовать бинарный поиск или какой-нибудь другой алгоритм для поиска в блоке вместо использования гораздо более медленного линейного поиска.
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Search Sorted
There is a method called which performs a binary search in the array,
and returns the index where the specified value would be inserted to maintain the
search order.
The method is assumed to be
used on sorted arrays.
Example
Find the indexes where the value 7 should be inserted:
import numpy as nparr = np.array()
x =
np.searchsorted(arr, 7)print(x)
Example explained: The number 7 should be inserted on index 1 to remain the sort order.
The method starts the search from the left and returns the first index where the number
7 is no longer larger than the next value.
Example
Find the indexes where the value 7 should be inserted, starting from the
right:
import numpy as nparr = np.array()
x =
np.searchsorted(arr, 7, side=’right’)print(x)
Example explained: The number 7 should be inserted on index 2 to remain the sort order.
The method starts the search from the right and returns the first index where the number
7 is no longer less than the next value.
Example
Find the indexes where the values 2, 4, and 6 should be inserted:
import numpy as nparr = np.array()
x =
np.searchsorted(arr, )print(x)
The return value is an array: containing the three indexes where 2, 4, 6 would be inserted
in the original array to maintain the order.
❮ Previous
Next ❯
Что вообще значит обойти дерево?
Поскольку деревья — это разновидность графа, их обход, иначе называемый поиск по дереву, является видом обхода графа. Тем не менее для дерева этот процесс отличается меньшей масштабностью.
Обход дерева обычно известен как проверка (посещение) или обновление каждого узла по одному разу без повторений. Поскольку все узлы связаны рёбрами, начинаем мы всегда с корневого. Это означает, что нельзя произвольно обратиться к любому узлу дерева.
К выполнению обхода существует три подхода:
- прямой;
- симметричный;
- обратный.
Прямой обход
В этом способе мы сначала считываем данные с корневого узла, затем перемещаемся к левому поддереву, а потом к правому. В связи с этим посещаемые нами узлы (а также вывод их данных) следуют тому же шаблону, в котором сначала мы выводим данные корневого узла, затем данные его левого поддерева, а затем правого.
Алгоритм:
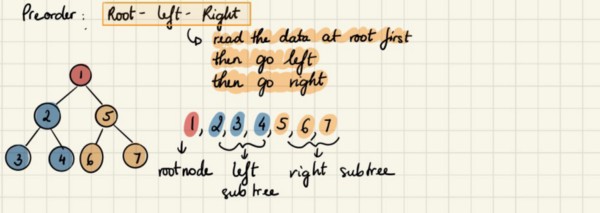 Прямой обход
Прямой обход
Мы начинаем с корневого узла и, следуя прямому порядку обхода, сначала посещаем сам этот узел, а затем переходим к его левому поддереву, которое обходим по тому же принципу. Это продолжается, пока все узлы не будут посещены. В итоге порядок вывода будет таким: .
Симметричный обход
При симметричном обходе мы проходим по пути к самому левому потомку, затем возвращаемся к корню, посещаем его и следуем к правому потомку.
Алгоритм:
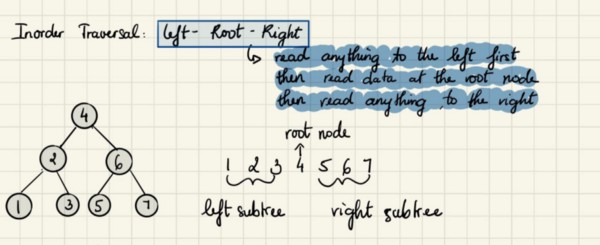 Симметричный обход
Симметричный обход
Начав от корневого узла 4, мы рекурсивно перебираем его левое поддерево, используя такой же симметричный порядок, затем посещаем сам корневой узел и далее перебираем правое поддерево.
Обратный обход
При обратном подходе мы сначала посещаем левого потомка, затем правого и по завершении обхода поддеревьев считываем корень.
Алгоритм:
 Обратный обход
Обратный обход
Становится ясно, что алгоритмы классифицируются на основе последовательности посещения узлов.
Здесь я снова упомяну, что есть две основных техники, которые мы можем использовать для обхода и посещения каждого узла исключительно по одному разу: поиск в глубину или поиск в ширину.
Последние добавленные или измененные записи:
Метод file.writelines() в Python, пишет список строк в файл. Метод файла file.writelines() записывает последовательность строк в файл file.
Функция max() в Python, максимальное значение элемента. Функция max() вернет наибольшее число из итерируемого объекта или самое большое из двух или более переданных позиционных аргументов
Функция run() модуля subprocess в Python. Функция run() модуля subprocess запускает команду с аргументами, ждет завершения команды, а затем возвращает экземпляр CompletedProcess() с результатами работы.
Класс Popen() модуля subprocess в Python. Класс Popen() модуля subprocess выполняет дочернюю программу в новом процессе. В POSIX класс использует os.execvp() подобное поведение для выполнения дочерней программы. В Windows класс использует функцию Windows CreateProcess().
Метод file.readline() в Python, читает файл построчно. Метод файла file.readline() читает одну целую строку из файла. Конечный символ новой строки \n сохраняется в строке.
Класс Counter() модуля collections в Python. Для удобных и быстрых подсчетов в последовательностях предусмотрен класс collections.Counter(). Это коллекция, в которой элементы хранятся в виде словарных ключей, а их счетчики хранятся в виде значений словаря.
Задания для самоподготовки
1. Написать
программу корректности ввода телефонного номера по шаблону:
x(xxx)xxxxxx
где x – любая цифра от
0 до 9. Данные представлены в виде строки.
2. Написать
программу изменения строки
«2+3+6.7 +
82 + 5.7 +1»
на строку, в
которой все «+» заменены на «-» и удалены все пробелы
3. Написать
программу вывода чисел 0; -100; 5.6; -3 в виде столбца:
0 -100 5.6 -3
в котором все
строки выровнены по правому краю (подсказка: воспользуйтесь методом rjust).
4. В строке «abrakadabra» найдите все
индексы подстроки «ra» и выведите их (индексы) в консоль.
Видео по теме
Python 3 #1: установка и запуск интерпретатора языка
Python 3 #2: переменные, оператор присваивания, типы данных
Python 3 #3: функции input и print ввода/вывода
Python 3 #4: арифметические операторы: сложение, вычитание, умножение, деление, степень
Python 3 #5: условный оператор if, составные условия с and, or, not
Python 3 #6: операторы циклов while и for, операторы break и continue
Python 3 #7: строки — сравнения, срезы строк, базовые функции str, len, ord, in
Python 3 #8: методы строк — upper, split, join, find, strip, isalpha, isdigit и другие
Python 3 #9: списки list и функции len, min, max, sum, sorted
Python 3 #10: списки — срезы и методы: append, insert, pop, sort, index, count, reverse, clear
Python 3 #11: списки — инструмент list comprehensions, сортировка методом выбора
Python 3 #12: словарь, методы словарей: len, clear, get, setdefault, pop
Python 3 #13: кортежи (tuple) и операции с ними: len, del, count, index
Python 3 #14: функции (def) — объявление и вызов
Python 3 #15: делаем «Сапер», проектирование программ «сверху-вниз»
Python 3 #16: рекурсивные и лямбда-функции, функции с произвольным числом аргументов
Python 3 #17: алгоритм Евклида, принцип тестирования программ
Python 3 #18: области видимости переменных — global, nonlocal
Python 3 #19: множества (set) и операции над ними: вычитание, пересечение, объединение, сравнение
Python 3 #20: итераторы, выражения-генераторы, функции-генераторы, оператор yield
Python 3 #21: функции map, filter, zip
Python 3 #22: сортировка sort() и sorted(), сортировка по ключам
Python 3 #23: обработка исключений: try, except, finally, else
Python 3 #24: файлы — чтение и запись: open, read, write, seek, readline, dump, load, pickle
Python 3 #25: форматирование строк: метод format и F-строки
Python 3 #26: создание и импорт модулей — import, from, as, dir, reload
Python 3 #27: пакеты (package) — создание, импорт, установка (менеджер pip)
Python 3 #28: декораторы функций и замыкания
Python 3 #29: установка и порядок работы в PyCharm
Python 3 #30: функция enumerate, примеры использования
Бинарный поиск
Бинарный поиск работает по принципу «разделяй и властвуй». Он быстрее, чем линейный поиск, но требует, чтобы массив был отсортирован перед выполнением алгоритма.
Предполагая, что мы ищем значение в отсортированном массиве, алгоритм сравнивает со значением среднего элемента массива, который мы будем называть .
- Если — это тот элемент, который мы ищем (в лучшем случае), мы возвращаем его индекс.
- Если нет, мы определяем, в какой половине массива мы будем искать дальше, основываясь на том, меньше или больше значение значения , и отбрасываем вторую половину массива.
- Затем мы рекурсивно или итеративно выполняем те же шаги, выбирая новое значение для , сравнивая его с и отбрасывая половину массива на каждой итерации алгоритма.
Алгоритм бинарного поиска можно написать как рекурсивно, так и итеративно. , потому что она требует выделения новых кадров стека.
Поскольку хороший алгоритм поиска должен быть максимально быстрым и точным, давайте рассмотрим итеративную реализацию бинарного поиска:
def BinarySearch(lys, val):
first = 0
last = len(lys)-1
index = -1
while (first <= last) and (index == -1):
mid = (first+last)//2
if lys == val:
index = mid
else:
if val<lys:
last = mid -1
else:
first = mid +1
return index
Если мы используем функцию для вычисления:
>>> BinarySearch(, 20)
То получим следующий результат, являющийся индексом искомого значения:
1
На каждой итерации алгоритм выполняет одно из следующих действий:
- Возврат индекса текущего элемента.
- Поиск в левой половине массива.
- Поиск в правой половине массива.
Мы можем выбрать только одно действие на каждой итерации. Также на каждой итерации наш массив делится на две части. Из-за этого временная сложность двоичного поиска равна O(log n).
Одним из недостатков бинарного поиска является то, что если в массиве имеется несколько вхождений элемента, он возвращает индекс не первого элемента, а ближайшего к середине:
>>> print(BinarySearch(, 4))
После выполнения этого фрагмента кода будет возвращен индекс среднего элемента:
2
Для сравнения: выполнение линейного поиска по тому же массиву вернет индекс первого элемента:
Однако мы не можем категорически утверждать, что двоичный поиск не работает, если массив содержит дубликаты. Он может работать так же, как линейный поиск, и в некоторых случаях возвращать первое вхождение элемента. Например:
>>> print(BinarySearch(, 4)) 3
Бинарный поиск довольно часто используется на практике, потому что он эффективен и быстр по сравнению с линейным поиском. Однако у него есть некоторые недостатки, такие как зависимость от оператора . Существует много других алгоритмов поиска, работающих по принципу «разделяй и властвуй», которые являются производными от бинарного поиска. Некоторые из них мы рассмотрим далее.
Функция filter
Следующая
аналогичная функция – это filter. Само ее название говорит, что
она возвращает элементы, для которых, переданная ей функция возвращает True:
filter(func, *iterables)
Предположим, у
нас есть список
a=1,2,3,4,5,6,7,8,9,10
из которого
нужно выбрать все нечетные значения. Для этого определим функцию:
def odd(x): return x%2
И далее, вызов
функции filter:
b = filter(odd, a) print(b)
На выходе
получаем итератор, который можно перебрать так:
print( next(b) ) print( next(b) ) print( next(b) ) print( next(b) )
Или, с помощью
цикла:
for x in b: print(x, end=" ")
Или же
преобразовать итератор в список:
b = list(filter(odd, a)) print(b)
Конечно, в
качестве функции здесь можно указывать лямбда-функцию и в нашем случае ее можно
записать так:
b = list(filter(lambda x: x%2, a))
И это бывает гораздо
удобнее, чем объявлять новую функцию.
Функцию filter можно применять
с любыми типами данных, например, строками. Пусть у нас имеется вот такой
кортеж:
lst = ("Москва", "Рязань1", "Смоленск", "Тверь2", "Томск")
b = filter(str.isalpha, lst)
for x in b:
print(x, end=" ")
и мы вызываем
метод строк isalpha, который
возвращает True, если в строке
только буквенные символы. В результате в консоли увидим:
Москва Смоленск
Тверь Томск
Текстовые файлы
Последнее обновление: 21.06.2017
Запись в текстовый файл
Чтобы открыть текстовый файл на запись, необходимо применить режим w (перезапись) или a (дозапись). Затем для записи применяется метод write(str),
в который передается записываемая строка. Стоит отметить, что записывается именно строка, поэтому, если нужно записать числа, данные других типов, то их
предварительно нужно конвертировать в строку.
Запишем некоторую информацию в файл «hello.txt»:
with open("hello.txt", "w") as file:
file.write("hello world")
Если мы откроем папку, в которой находится текущий скрипт Python, то увидем там файл hello.txt. Этот файл можно открыть в любом текстовом редакторе и при желании изменить.
Теперь дозапишем в этот файл еще одну строку:
with open("hello.txt", "a") as file:
file.write("\ngood bye, world")
Дозапись выглядит как добавление строку к последнему символу в файле, поэтому, если необходимо сделать запись с новой строки, то можно использовать эскейп-последовательность «\n».
В итоге файл hello.txt будет иметь следующее содержимое:
hello world good bye, world
Еще один способ записи в файл представляет стандартный метод print(), который применяется для вывода данных на консоль:
with open("hello.txt", "a") as hello_file:
print("Hello, world", file=hello_file)
Для вывода данных в файл в метод print в качестве второго параметра передается название файла через параметр file. А первый параметр представляет записываемую
в файл строку.
Чтение файла
Для чтения файла он открывается с режимом r (Read), и затем мы можем считать его содержимое различными методами:
-
readline(): считывает одну строку из файла
-
read(): считывает все содержимое файла в одну строку
-
readlines(): считывает все строки файла в список
Например, считаем выше записанный файл построчно:
with open("hello.txt", "r") as file:
for line in file:
print(line, end="")
Несмотря на то, что мы явно не применяем метод для чтения каждой строки, но в при переборе файла этот метод автоматически вызывается
для получения каждой новой строки. Поэтому в цикле вручную нет смысла вызывать метод readline. И поскольку строки разделяются символом перевода строки «\n», то чтобы исключить излишнего переноса на другую строку в функцию
print передается значение .
Теперь явным образом вызовем метод для чтения отдельных строк:
with open("hello.txt", "r") as file:
str1 = file.readline()
print(str1, end="")
str2 = file.readline()
print(str2)
Консольный вывод:
hello world good bye, world
Метод readline можно использовать для построчного считывания файла в цикле while:
with open("hello.txt", "r") as file:
line = file.readline()
while line:
print(line, end="")
line = file.readline()
Если файл небольшой, то его можно разом считать с помощью метода read():
with open("hello.txt", "r") as file:
content = file.read()
print(content)
И также применим метод readlines() для считывания всего файла в список строк:
with open("hello.txt", "r") as file:
contents = file.readlines()
str1 = contents
str2 = contents
print(str1, end="")
print(str2)
При чтении файла мы можем столкнуться с тем, что его кодировка не совпадает с ASCII. В этом случае мы явным образом можем указать кодировку с помощью
параметра encoding:
filename = "hello.txt"
with open(filename, encoding="utf8") as file:
text = file.read()
Теперь напишем небольшой скрипт, в котором будет записывать введенный пользователем массив строк и считывать его обратно из файла на консоль:
# имя файла
FILENAME = "messages.txt"
# определяем пустой список
messages = list()
for i in range(4):
message = input("Введите строку " + str(i+1) + ": ")
messages.append(message + "\n")
# запись списка в файл
with open(FILENAME, "a") as file:
for message in messages:
file.write(message)
# считываем сообщения из файла
print("Считанные сообщения")
with open(FILENAME, "r") as file:
for message in file:
print(message, end="")
Пример работы программы:
Введите строку 1: hello Введите строку 2: world peace Введите строку 3: great job Введите строку 4: Python Считанные сообщения hello world peace great job Python
НазадВперед
Группирующие скобки (…) и match-объекты в питоне
Match-объекты
| Метод | Описание | Пример |
|---|---|---|
| , | Подстрока, соответствующая шаблону | |
| Индекс в исходной строке, начиная с которого идёт найденная подстрока | ||
| Индекс в исходной строке, который следует сразу за найденной подстрока |
Группирующие скобки
Если в шаблоне регулярного выражения встречаются скобки без , то они становятся группирующими. В match-объекте, который возвращают , и , по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует , а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок , то вывод был бы таким:
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
Группы и
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки .
Группы и
Если в шаблоне нет группирующих скобок, то работает очень похожим образом на . А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
re.compile(pattern, repl, string)
Следующий метод позволяет собирать регулярные выражения в отдельный объект, а потом использовать его для поиска. Такое решение избавляет от переписывания одних и тех же выражений.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Итог:
'AV', 'AV' 'AV'
Итак, мы рассмотрели поиск определённой последовательности символов. Однако бывает, что у нас нет конкретного шаблона, а нам необходимо вернуть набор символов из строки, которая отвечает некоторым правилам (извлечь нужную информацию из строк). В таких ситуациях нам пригодятся специальные символы:

Дополнительную информацию о спецсимволах можно найти в официальной документации.
По материалам «Beginners Tutorial for Regular Expressions in Python».
re.match(pattern, string)
Метод осуществляет поиск в начале строки по заданному шаблону. Вызвав match() на строке «AV Analytics AV» с шаблоном «AV», мы получим успешный результат поиска. Но если будем искать «Analytics», результат будет отрицательным. Давайте посмотрим, как метод работает:
import re result = re.match(r'AV', 'AV Analytics Vidhya AV') print result
Итог:
<_sre.SRE_Match object at 0x0000000009BE4370>
Итак, искомая подстрока найдена. Если мы хотим вывести её содержимое, пригодится метод group()
Обратите внимание, что мы применяем «r» перед строкой шаблона, дабы показать, что это «сырая» строка
result = re.match(r'AV', 'AV Analytics Vidhya AV') print result.group()
Итог:
AV
А теперь поищем в данной строке «Analytics». Но, как уже было сказано выше, т. к. строка начинается на «AV», результат будет отрицательный:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV') print result
Итог:
None
Кроме того, существуют методы start() и end(), позволяющие узнать начальную и конечную позиции найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV') print result.start() print result.end()
Итог:
2
Данные методы бывают весьма полезны при работе со строками.
Работа со строками
Последнее обновление: 02.05.2017
Строка представляет последовательность символов в кодировке Unicode. И мы можем обратиться к отдельным символам строки по индексу в квадратных скобках:
string = "hello world" c0 = string # h print(c0) c6 = string # w print(c6) c11 = string # ошибка IndexError: string index out of range print(c11)
Индексация начинается с нуля, поэтому первый символ строки будет иметь индекс 0. А если мы попытаемся обратиться к индексу, которого нет в строке, то
мы получим исключение IndexError. Например, в случае выше длина строки 11 символов, поэтому ее символы будут иметь индексы от 0 до 10.
Чтобы получить доступ к символам, начиная с конца строки, можно использовать отрицательные индексы. Так, индекс -1 будет представлять последний символ, а -2 — предпоследний символ и так далее:
string = "hello world" c1 = string # d print(c1) c5 = string # w print(c5)
При работе с символами следует учитывать, что строка — это неизменяемый (immutable) тип, поэтому если мы попробуем изменить какой-то отдельный символ строки, то мы получим
ошибку, как в следующем случае:
string = "hello world" string = "R"
Мы можем только полностью переустановить значение строки, присвоив ей другое значение.
Получение подстроки
При необходимости мы можем получить из строки не только отдельные символы, но и подстроку. Для этого используется следующий синтаксис:
-
: извлекается последовательность символов начиная с 0-го индекса по индекс end
-
: извлекается последовательность символов начиная с индекса start по индекс end
-
: извлекается последовательность символов начиная с индекса start по индекс end через шаг step
Используем все варианты получения подстроки:
string = "hello world" # с 0 до 5 символа sub_string1 = string print(sub_string1) # hello # со 2 до 5 символа sub_string2 = string print(sub_string2) # llo # со 2 по 9 символ через один символ sub_string3 = string print(sub_string3) # lowr
Функции ord и len
Поскольку строка содержит символы Unicode, то с помощью функции ord() мы можем получить числовое значение для символа в кодировке Unicode:
print(ord("A")) # 65
Для получения длины строки можно использовать функцию len():
string = "hello world" length = len(string) print(length) # 11
Поиск в строке
С помощью выражения можно найти подстроку term в строке string. Если подстрока найдена, то выражение вернет значение
, иначе возвращается значение :
string = "hello world" exist = "hello" in string print(exist) # True exist = "sword" in string print(exist) # False
Перебор строки
С помощью цикла for можно перебрать все символы строки:
string = "hello world"
for char in string:
print(char)
НазадВперед