Собеседование по data science: что нужно знать и где это изучить
Содержание:
- Что знает, умеет и сколько стоит Data Scientist
- Что знают и умеют дата-сайентисты
- Профессия Data Scientist от Skillbox
- Проекты
- Практика
- Визуализация данных
- Ссылки на интересные материалы
- Чем занимается Data Scientist?
- Data Science (Исследователь данных)
- Ключ — в самоорганизации
- 2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
- Опыт работы в качестве дата-сайентиста
- MVP лучше, чем долгосрочное исследование
- Machine Learning Engineer (MLE)
- Data Scientist – это кто вообще?
- Проанализируем данные
- Вакансии data scientist
- Специалисты по изучению данных (data scientist)
- A/B-тесты важнее обучения модели
- Data Analytics (Аналитик данных)
Что знает, умеет и сколько стоит Data Scientist
Специалисты в области Data Science называются учеными или исследователями по данным (Data Scientist’ами). В настоящее время это одна из самых востребованных и высокооплачиваемых ИТ-профессий. Например, в Москве на январь 2020 года месячный труд ученого по данным оценивается около 200 тысяч рублей (от 70 до 250 т.р.). В США оплата выше — $110 — $140 тысяч в год .
Основная практическая цель работы ученого по данным – это извлечение полезных для бизнеса сведений из больших массивов информации, выявление закономерностей, разработка и проверка гипотез путем моделирования и разработки нового программного обеспечения .
Для достижения этой цели Data Scientist использует следующие инструменты:
- пакеты статистического моделирования (R-Studio, Matlab);
- технологии больших данных (Apache Hadoop, HDFS, Spark, Kafka), NoSQL-СУБД (Cassandra, HBase, MongoDB, DynamoDB и прочие нереляционные решения);
- SQL для работы с классическими реляционными базами данных и формирования структурированных запросов к NoSQL-решениям с помощью Apache Phoenix, Drill, Impala, Hive и пр.
- языки программирования (Python, R, Java, Scala) для разработки моделей машинного обучения и прототипов программного обеспечения;
- информационные системы класса Business Intelligence (дэшборды, витрины данных) для визуализации бизнес-показателей из информационных массивов.
Таким образом, можно сделать вывод, что Data Science включает следующие области знаний:
- математика: математический анализ, матстатистика и матлогика;
- информатика: разработка программного обеспечения, баз данных, моделей и алгоритмов машинного обучения (нейросети, байесовские алгоритмы, регрессионные ряды и пр.), Data Mining;
- системный анализ (методы анализа предметной области, Business Intelligence).
Подробнее о профессии Data Scientist’a и его отличиях от инженера и аналитика данных (Data Engineer и Data Analyst) мы писали здесь.
Портрет профессиональных компетенций ученого по данным
Источники
- https://ru.wikipedia.org/wiki/Наука_о_данных
- https://www.profguide.io/professions/data_scientist.html
- https://chernobrovov.ru/articles/analitika-dannyh-i-data-science-shodstva-i-razlichiya.html
Что знают и умеют дата-сайентисты
Вот начальный список навыков, знаний и умений, которые нужны любому дата-сайентисту для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое.
Есть те, кто говорит, что это всё не нужно, и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну, вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Мы уже писали, что Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
R и статистика в действии. Картинка с Хабра.
Умение получать и визуализировать данные. Не всем дата-сайентистам везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего они сами должны выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Второй важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Профессия Data Scientist от Skillbox
Для анализа больших и неоднородных массивов данных используется технология Big Data. Машинные технологии научились делать выводы и использовать инфографику для визуализации данных. На услуги Data Scientist предъявляют спрос банки, мобильные операторы, производители программных продуктов. Уровень оплаты в Big Data стабильно высок. Обучиться профессии с нуля могут новички, а опытные программисты прокачают свои навыки. Курс от Skillbox задействует разные инструменты — языки кода, фреймворки, библиотеки и базы данных.
Освоение новых знаний происходит в контакте с наставником. Сообщество профессионалов Skillbox даёт обратную связь при выполнении заданий и помогает выпускникам с трудоустройством.

Проекты
Можете ли вы поделиться своим опытом на GitHub? Опыт участия в соревновании Kaggle или стороннем проекте будет очень полезен и даст возможность оценить лаконичность кода, типы предобработки данных, выбор алгоритма и многое другое.
Добавьте в резюме ссылки на профиль на GitHub или Kaggle. Если у вас немного опыта, вероятно, вам зададут вопросы о ваших проектах. Убедитесь, что размещаете качественные работы — лучше иметь 2-3 хороших, чем 8-10 средних или плохих.
Если вы хотите получить работу в дата-сайенс, убедитесь, что в вашем резюме есть эти пункты. Чем их больше, тем выше шансы, что ваше резюме не останется незамеченным.
Практика
Теперь можно приступить к третьей части программы — практическому опыту. Чтобы отточить полученные скиллы, их нужно задействовать в проектах — желательно, чтобы они были похожи на какие-то уже существующие приложения. Попутно перед вами будут возникать разные сложности, но справляясь с ними, вы очень хорошо «прощупаете» предмет и прокачаете свои знания.
Kaggle
Конкурсы по машинному обучению — отличная возможность потренироваться создавать модели. Там есть доступ к множеству датасетов, предназначенных для решения отдельных задач. По турнирной таблице можно сравнивать свои успехи с другими участниками. А ещё по результатам вам будет видно, в каких темах у вас пробелы и что нужно подтянуть.
Помимо Kaggle, есть разные другие платформы, где можно попробовать свои силы. Например Analytics Vidhya и DrivenData.
ML-репозиторий UCI
UCI Machine Learning Repository — огромный клад публичных датасетов, которые можно использовать в домашних ML-проектах. Создайте портфолио на GitHub и размещайте проекты в нём. Оно будет не только демонстрировать ваши способности и достижения, но и в дальнейшем может помочь найти работу.
Вклад в Open Source
Участвуйте в чужих проектах. Очень многие Python-библиотеки поддерживаются опенсорс-сообществом. В рамках митапов и конференций часто проводят хакатоны, куда приглашают даже новичков. Это хорошая возможность для взаимного «обмена премудростями»: здесь можно и чему-то научиться у других, и поделиться знаниями. Один из вариантов — хакатон, спонсируемый фондом NumFOCUS.
Практические ресурсы хорошо разнообразят книги по Data Science из этого списка. Все можно найти в открытых источниках.
Визуализация данных
Хорошо построенный график или схема может показать то, на что ушло бы несколько абзацев текста.
Есть множество платных и бесплатных инструментов для визуализации данных, например, Plotly, Tableau, Chartio, d3.js и другие. Если вам нужно быстро набросать таблицу, не отказывайтесь от таких проверенных средств, как Excel или Google Sheets.

Фото: Unsplash
Когда вы создаете график, важно, чтобы на нем отображался максимум информации, но при этом сохранялась его «читабельность». Хорошая схема понятна с первого взгляда
Больше информации о том, как лучше составлять диаграммы и схемы вы найдете в книге Эдварда Тафти «Визуальное представление больших объемов информации».
Ссылки на интересные материалы
Ссылки на интересные материалы, касающиеся профессии дата-сайентиста:
- “Кто такой Data Scientist глазами работодателя” — интервью с Авито и Spice IT;
- Интересная статья “Как стать датасайнтистом, если тебе за 40 и ты не программист”;
- Статья “Дорога в Data Science глазами новичка” на Пикабу;
- Авторская статья “Как стать Data Scientist в 2019 году”;
- Интересный материал “Рутина дата-сайентистов. Про их рабочий день и нужные навыки”;
- Занимательная глава из книги “Наука данных. Базовый курс”, посвященная истории профессии;
- Ретроспектива автора на Хабре о том, каково это было — изучать дата сайнс в 2019 году;
- Статья “Один день из жизни дата-сайентиста”, написанная в 2018 году;
- История дата-сайентиста Саши, написанная простым языком;
- Несколько историй о том, как гуманитарии стали специалистами в работе с данными.
Эта профессия как минимум входит в число самых перспективных, поэтому в последние годы многие с удовольствием изучают data science. Конечно, как и в других отраслях, здесь есть свои недостатки и трудности, которые особенно заметны в начале обучения, но при должном старании любой сможет пополнить ряды ученого по данным. Так что дерзайте!
Чем занимается Data Scientist?
В Data Science обучении стоит отталкиваться от задач, поставленных перед специалистом. При этом задачи Data Scientist могут отличаться в зависимости от сферы деятельности компании. Вот несколько примеров:
- обнаружение аномалий — например нестандартных действий с банковской картой, мошенничества;
- анализ и прогнозирование — показатели эффективности, качество рекламных кампаний;
- системы баллов и оценок — обработка больших объёмов данных для принятия решения, например, о выдаче кредита;
- базовое взаимодействие с клиентом — автоматические ответы в чатах, голосовые помощники, сортировка писем по папкам.
Но для любой из вышеперечисленных задач всегда нужно выполнять примерно одни и те же шаги:
- Сбор данных — поиск источников и способов получения информации, а также сам процесс сбора.
- Проверка — валидация, удаление аномалий.
- Анализ — изучение данных, построение предположений, выводов.
- Визуализация — приведение данных в вид, понятный для человека (графики и диаграммы).
- Результат — принятие решений на основе анализируемых данных, например об изменении маркетинговой стратегии или увеличении бюджета на какую-либо деятельность компании.
Data Science (Исследователь данных)
В обсуждении «Data Analytics и Data Scientist» наука о данных считается более сложной из двух. Это происходит потому, что эта профессия по сравнению с анализом данных включает в себя некоторые дополнительные сложные задачи. Но давайте рассматривать все по порядку — что делают ученые данных?
На первый взгляд, наука о данных очень похожа на аналитику данных. Эти специальности имеют дело с одним и тем же — огромные объемы информации представлены в цифрах. Однако основное различие между ними заключается в степени ответственности.
Мы уже поняли, что аналитики данных (как следует из названия) извлекают и анализируют информацию, а затем представляют ее компании. Обязанности ученых-исследователей данных распространяются на оба этих процесса. Прежде всего, хотя аналитику данных задается конкретная проблема, ожидается, что ученые, работающие с данными, сформулируют проблему самостоятельно. Чтобы дать вам пример, мы могли бы вернуться в ранее упомянутую кофейню.
Если бы вы наняли аналитика данных, вам нужно было бы задать им конкретный вопрос, на который вы хотите получить ответ. Примером такого вопроса может быть «покупает ли группа людей Х больше кофе, чем группа Y?». Аналитик данных ответит на ваш вопрос и найдет ответ, основываясь на результатах вашей компании. Тем не менее, в сравнении Data Scientist и Data Analyst вам не нужно формулировать какие-либо вопросы для специалиста по данным. Скорее, это будет обязанность этого человека взглянуть на бизнес-модель вашей компании, вычесть возможные (и потенциальные) проблемы и решить вопрос самостоятельно.
Однако это не единственное в обсуждении Data Scientist, где исследователи данных отлично справляются со своими обязанностями. Эти люди также имеют более широкие обязанности. В то время как аналитик данных завершит свою работу там, ученый должен также сделать определенные выводы из представленных данных и разработать дальнейший бизнес-план действий для компании.
Итак, после всего вышесказанного вы теперь знаете не только то, что делают исследователи данных, но и основные различия между двумя профессиями. Теперь, прежде чем мы начнем обсуждать фактическое сравнение Data Scientist и Data Analyst, давайте кратко рассмотрим критерии, которые мы будем использовать для анализа обеих профессий.
Ключ — в самоорганизации
Я проходил собеседования в Google (и DeepMind), Uber, Facebook, Amazon. Все на должность Data Scientist, и состояли они в основном из таких тем:
- Разработка программного обеспечения.
- Прикладная статистика.
- Машинное обучение.
- Обработка и визуализация данных.
От вас не требуется космический уровень во всех темах сразу. Тем не менее, нужно убедить интервьюеров, что вы справитесь со своими задачами. Требуемый уровень знаний зависит от конкретной вакансии, но в условиях растущей конкуренции чем больше знаешь — тем лучше, и любой новый опыт — на вес золота.
Чтобы хорошо подготовиться, записывайте всё, что изучаете. Я вёл конспекты в Notion. Каждый день просматривал материалы
Особенно важно так делать перед самым собеседованием, чтобы загрузить ключевую информацию в свою оперативную память. И это помогало — я отвечал на вопросы без лишнего мычания и траты времени
2017: Высшая школа экономики будет обучать Data Culture на всех программах бакалавриата
НИУ ВШЭ первым из российских университетов начнет формировать компетенции по Data Science у всех студентов, обучающихся на программах бакалавриата. В рамках проекта Data Culture расширится набор дисциплин и появятся образовательные треки по анализу больших данных.
Data Culture – это общий термин для обозначения навыков и культуры работы с данными. Высшая школа экономики считает, что запуск проекта, направленного на воспитание у студентов таких навыков, сейчас актуален из-за огромного потенциала использования больших данных и трансформации профессий, которые, так или иначе, используют или могут использовать большие массивы информации. Потребность рынка в специалистах с компетенциями по анализу данных, перерастает в необходимость воспитания во всех предметных областях профессионалов, понимающих возможности и ограничения массивов данных, потенциал и особенности методов машинного обучения, а в ряде направлений и умеющих пользоваться этими технологиями и инструментами.
Проект Data Culture станет продолжением интеграции в образовательные программы НИУ ВШЭ элементов, направленных на воспитание у студентов культуры и умений работы с данными. Он расширит возможности студентов уже абсолютно всех образовательных программ по формированию компетенций, связанных с Data Science. Это позволит выпускникам в перспективе быстро и эффективно интегрироваться в решение профессиональных задач на стыке предметных областей и компьютерных технологий, которые сегодня являются передовыми, но уже в ближайшей перспективе станут привычной практикой.
Проект включает разработку отдельных курсов по Data Science так или иначе кастомизированных под специфику образовательных программ, а также формирование специализированных образовательных треков из таких курсов с разной степенью сложности: начального, базового, продвинутого, профессионального и экспертного уровней. Это связано с большим разнообразием образовательных программ, студенты которых дифференцированы по базовым компетенциям в сфере математики и информатики. Для программ или их блоков будет предложена система курсов Data Culture в определенной вилке «сквозного уровня продвинутости». Более того, эти системы курсов определятся спецификой предметных областей.
Внедрение дисциплин Data Culture будет происходить поэтапно. В 2017/2018 учебном году будут включены в учебные планы обязательные и элективные курсы по направлению Data Science для части образовательных программ, но таковых будет более половины. Например, у студентов-гуманитариев, юристов и дизайнеров появится вводный курс по цифровой грамотности, программы экономистов дополнятся дисциплиной по машинному обучению, политологов – анализу социальных сетей, у статистиков появится курс по программированию и извлечению и анализу интернет-данных. С 2018 года к проекту примкнут все образовательные программы.
Для реализации проекта Data Culture предполагается привлечение преподавательского состава как из академической среды (преподаватели факультета компьютерных наук, сотрудники департамента математики факультета экономических наук и общеуниверситетской кафедры высшей математики и т.д.), так и из индустрии (участники сообществ по анализу данных, участники тематических мероприятий по анализу данных, проводимых в IT-компаниях). Более того, преподаватели факультетов, которые уже погружены в работу с данными в рамках своей профессиональной деятельности, также будут разрабатывать курсы в рамках проекта Data Culture для студентов своих и смежных факультетов.
Опыт работы в качестве дата-сайентиста
Скорее всего, рекрутер будет быстро просматривать резюме и искать опыт работы в таких должностях, как дата-сайентист/Data Scientist, инженер по машинному обучению/Machine Learning Engineer, ученый-исследователь/Research Scientist или инженер алгоритмов/Algorithm Engineer. Сюда не относится должность аналитик данных/Data Analyst — это слишком широкое понятие, а спектр его задач отличается от работы дата-сайентиста.
Если вы выполняете функции дата-сайентиста на текущем месте работы, лучше изменить название должности на дата-сайентиста. Это стоит сделать, даже если в резюме описываются проекты, над которыми вы работали.
Участие в буткампе по дата-сайенс или степень магистра также можно считать началом карьеры дата-сайентиста.
MVP лучше, чем долгосрочное исследование
Мир технологий конкурентоспособен и изменчив. В большинстве случаев у компаний нет времени ждать идеального решения, которое достигло бы наилучшего уровня производительности. Вместо этого они начинают проект с минимально жизнеспособного продукта (minimum viable product, MVP) и развивают его. MVP должен удовлетворять самым основным потребностям проекта — ни больше, ни меньше.
Перфекционистам и людям, внимательным к деталям (то есть большинству Data Science-энтузиастов), зачастую сложно работать над MVP. Обычно исследователи стремятся тщательно проанализировать данные, опробовать множество различных моделей и найти наилучшее решение. Наука о данных по сути ориентирована именно на такой подход, однако мы не зря говорим о прикладной области Data Science.
Нужно понимать, что в разработке самый важный актив — время. Никто не может предсказать путь, по которому пойдёт продукт. Возможно, со временем проект приостановят или полностью закроют. MVP создаётся, чтобы свести риски к минимуму. Даже если продукт гарантированно будет развиваться, поначалу ему может не хватать необходимых ресурсов. Построение простой модели и её постепенное развитие с появляющимися новыми данными и технологиями даёт более надёжные результаты.
Machine Learning Engineer (MLE)
Как можно догадаться, основная разница с предыдущим подвидом инженера как раз связана с машинным обучением. Пока дата инженер больше работает с подготовкой данных, обычно больших, и собственно модели не обучает, для Machine Learning Engineer это важная часть работы. Вкратце — это software engineer с уклоном в машинное обучение, который может выполнить полный цикл — от сбора данных для модели до деплоймента ее как части продакшен-приложения.
Следовательно, требования к MLE чем-то похожи на требования к дата инженеру: в первую очередь, это просто компетентный разработчик, знающий и алгоритмы, и инженерные практики (может ответить, зачем нужен CI, и рассказать пару баек, почему выкатываться в пятницу может быть плохой идеей). При этом он более или менее понимает теорию машинного обучения (например, понимает bias-variance tradeoff и может написать градиентный спуск с нуля). Хороший MLE знает современные алгоритмы машинного обучения, но не спешит использовать самые горячие новинки. Ему обычно не нужно изобретать что-то с нуля, но слегка адаптировать существующий подход под свою задачу — довольно часто.
В зависимости от домена, у MLE могут быть специфические навыки. Например, для обработки видео на телефоне в реальном времени нужно уметь написать сколько-то быстрый код на C++, а для разработки классического бэкенд-приложения обычно полезно быть «на ты» с Docker.
Зачем победитель Kaggle и TopCoder переехал в Минск из Питера
По теме
Зачем победитель Kaggle и TopCoder переехал в Минск из Питера
«Мне 30, а я в Ангарске». Сисадмин-самоучка из Сибири попал в топ Kaggle и теперь тренирует нейросети в минской Mapbox (+список курсов по Computer Vision)
По теме
«Мне 30, а я в Ангарске». Сисадмин-самоучка из Сибири попал в топ Kaggle и теперь тренирует нейросети в минской Mapbox (+список курсов по Computer Vision)
«Никто не хотел брать меня в команду». Как 24-летний белорусский Data Scientist объединился с «парнем из Японии» и выиграл $50 тысяч на Kaggle
По теме
«Никто не хотел брать меня в команду». Как 24-летний белорусский Data Scientist объединился с «парнем из Японии» и выиграл $50 тысяч на Kaggle
«Я проработал так 4 месяца». Кирилл Жданович ушёл из шведского Spotify, чтобы организовать себе трёхдневку «с сохранением зарплаты». Говорим про ML, труд, май
По теме
«Я проработал так 4 месяца». Кирилл Жданович ушёл из шведского Spotify, чтобы организовать себе трёхдневку «с сохранением зарплаты». Говорим про ML, труд, май
Data Scientist – это кто вообще?
Data Scientist’ы — это эксперты по анализу массивов данных. Такие специалисты часто обладают математическим складом ума, владеют статистическим анализом, умеют видеть закономерности и находить их. Задача Data Scientist’ов — создание моделей для совершенствования рабочих процессов, используя анализ данных и не только.
Как правило, Data Scientist’ы занимаются:
— сбором больших массивов данных, их видоизменением;
— решением бизнес-задач, используя анализ данных;
— работой с языками SAS, R, Python;
— работой со статистикой;
— аналитикой, машинным обучением;
— выявлением различных закономерностей и т. п.
Соответственно, хороший специалист должен владеть:
• статистикой, машинным обучением;
• языками программирования SAS, R либо Python;
• базами данных MySQL, Postgres;
• технологиями визуализации данных;
• Hadoop and MapReduce.
Это, конечно, далеко не всё, но, как бы там ни было, всем этим технологиям можно научиться, а зарплата Data Scientist того стоит.
Проанализируем данные
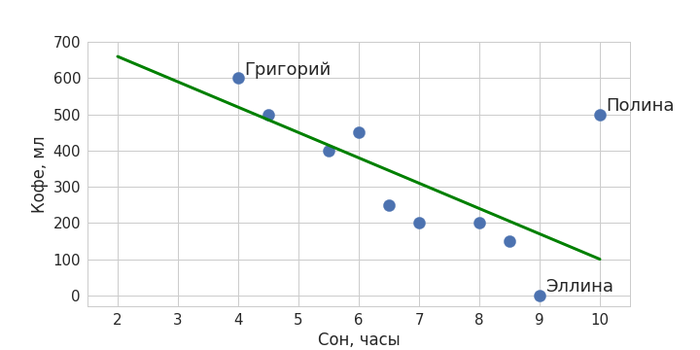
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример – любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
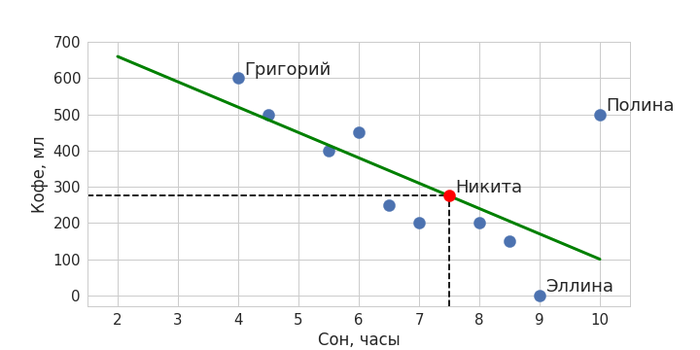
Зеленая линия – и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель – ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Вакансии data scientist
Количество вакансий для эксперта по аналитике увеличивается, поскольку данные — ценнейший ресурс. Сотрудников не хватает, особенно на руководящих должностях (Lead/Chief data scientist). Топовые позиции предполагают наличие у кандидата специальных качеств, необходимых в конкретной сфере. С практикантами и специалистами уровня junior проще: data science — модное направление, в котором многие хотят попробовать себя.
Как составить резюме data scientist
В резюме нужно сосредоточиться на технических навыках и кратко рассказать о своем опыте. На выходе документ должен получиться простым и лаконичным. Стоит перечислить навыки (начиная с тех, которыми кандидат владеет лучше всего), проекты и достижения.
Специалисту обязательно нужно портфолио. Желательно взять несколько проектов с реальными наборами данных — это может конкурсное или тестовое задание, собственный проект. Результаты можно разместить на GitHub.
Хорошее резюме и портфолио — не гарантия получения должности мечты. Собеседования часто состоят из нескольких этапов, кандидаты выполняют тестовые задания в условиях довольно жесткой конкуренции.
Специалисты по изучению данных (data scientist)
Специалист по Data Science — это эксперт по данным, который часто имеет высшее образование в области математики или статистики и нередко умеет программировать на R или Python. Наиболее востребованные датасайентисты также обладают знаниями в соответствующих областях бизнеса.
Хотя наборы навыков у разных людей разнятся, задача специалиста по данным состоит в том, чтобы помочь их работодателю решить сложные проблемы, часто связанные с поиском инсайтов, оптимизацией бизнес-процессов и построением предиктивных моделей. Эта роль может рассматриваться как часть ИТ, или же она может быть интегрирована в один из департаментов компании. Из всех возможных ролей, связанных с данными, датасайентисты, как правило, являются наиболее опытными экспертами.
Основные задачи Data Scientist:
- умение извлекать необходимую информацию из разнообразных источников
- использовать информационные потоки в режиме реального времени
- устанавливать скрытые закономерности в массивах данных
- статистически анализировать их для принятия грамотных бизнес-решений.
Основное отличие специалистов по изучению данных от, например, аналитиков, — это умение видеть логические связи в системе собранной информации, и на основании этого разрабатывать те или иные бизнес-решения. Специалисты по изучению данных собирают информацию, строят модели на ее основании и активно применяют количественный анализ.
Именно это редкое сочетание компетенций определяет зарплату специалиста по изучению данных: в США она составляет $110 тыс. — $140 тыс. в год. «Эта вакансия становится все более востребованной,- отмечает на страницах IT World Лора Келли (Laura Kelley), вице-президент агентства по ИТ-консалтингу и подбору персонала Modis (США). — Компании уделяют все больше внимания информации и приложениям. Им требуются специалисты, способные управлять большим количеством данных`.
Майкл Раппа (Michael Rappa), директор Института аналитики в Университете Северной Каролины, вместе со своими коллегами уже 6 лет разрабатывает курс, на котором будут готовить специалистов по изучению данных. «Эти специалисты должны уметь извлекать нужную информацию из всевозможных источников, включая информационные потоки в режиме реального времени, и анализировать ее для дальнейшего принятия бизнес-решений, — говорит он. — Дело не только в объеме обрабатываемой информации, но также в ее разнородности и скорости обновления».
Компании, которые пытаются решить эту задачу силами специалистов по статистике, компьютерных или бизнес-аналитиков, не добиваются нужного результата. Необходимо объединить все эти навыки в одном человеке. Например, бизнес-аналитики воспринимают такие показатели, как разработка и менеджмент продукта, но не способны анализировать и адекватно интерпретировать данные. Математикам и специалистам по статистике недостает знаний в области бизнеса. Именно поэтому, по мнению Раппы, специалистам по изучению данных требуется междисциплинарное образование – они должны уметь решать бизнес-проблемы и составлять информационные модели.
100% выпускников разработанного Институтом аналитики курса для специалистов по изучению данных получили предложения о работе еще до того, как завершили обучение. Раппа также отмечает, что сама специальность — специалист по изучению данных — звучит более привлекательно, чем `специалист по статистике` или `компьютерный аналитик`.
Почему Data Scientist сексуальнее, чем BI-аналитик
В связи с ростом популярности data science (DS) возникает два совершенно очевидных вопроса. Первый – в чем состоит качественное отличие этого недавно сформировавшегося научного направления от существующего несколько десятков лет и активно используемого в индустрии направления business intelligence (BI)? Второй — возможно более важный с практической точки зрения — чем различаются функции специалистов двух родственных специальностей data scientist и BI analyst? В материале, подготовленном специально для TAdviser, на эти вопросы отвечает журналист Леонид Черняк.
A/B-тесты важнее обучения модели
Вы обучили и настроили новую модель, и она дала потрясающие результаты в каждой тестовой метрике, превзойдя предыдущий алгоритм. Вам нужно немедленно отправить её в продакшн, верно? К сожалению, нет.
Важным процессом в Agile и Data Science являются A/B-тесты. Ваша модель может превзойти предыдущее решение во время обучения, но может не работать в реальной жизни. Обучающие данные — это лишь подмножество реальных данных. Они могут быть устаревшими и содержать ошибки. Поэтому модель выпускается в продакшн только в том случае, если она показывает лучшие результаты во время A/B-тестирования.
Data Analytics (Аналитик данных)
Когда мы сравниваем аналитика данных и исследователя данных, интеллектуальный анализ данных, безусловно, является более популярным из двух. Это в основном потому, что это немного проще и встречается чаще. Итак, что же делает аналитик данных?
Data Analyst (Аналитики данных) — это люди, которые работают с огромным количеством информации. Их работа заключается в том, чтобы взять часть данных и затем «перевести» цифры на повседневный язык. Это делается для того, чтобы аналитик мог затем представить данные своим работодателям, которые затем приняли бы адекватные бизнес-решения на основе результатов анализа.
Аналитики данных являются важными членами любой команды, которая хочет развивать свой бизнес. Тем не менее, эти люди чаще всего встречаются в огромных корпорациях, которые ежедневно обрабатывают огромные объемы данных. Хотя это может показаться непонятным, аналитики данных имеют очень конкретные и четкие должностные обязанности (что не может не радовать!). Их главная ответственность заключается в том, чтобы иметь возможность разбирать предоставленную информацию и делать четкие решения, которые затем могут быть интерпретированы компанией.
Теперь, с учетом всего вышесказанного — почему важно наше сравнение? Или, скорее, почему аналитика данных важна для успеха компании? Позвольте мне привести пример. Представьте, что у вас есть небольшая компания, которая продает определенный тип кофе
Вы следуете всем золотым правилам маркетинга, рекламируете как традиционно, так и в Интернете, тратите много времени на свою аудиторию и т. д. Проходит месяц, и вы хотите узнать, как работает ваш бизнес. Это не значит просто посмотреть на доход (который вы надеетесь получить!). Если вы хотите, чтобы ваш бизнес был успешным, вам нужно будет определить возможные узкие места и проблемы, выяснить, какие группы вашей целевой аудитории не покупают продукт (и почему), а затем принять определенные решения, основанные на предоставленной информации. Однако вся информация, которая вам потребуется, генерируется в виде числовых строк — вам нужно обладать определенными знаниями, чтобы понимать данные. Здесь начинает работать «специалист по анализу данных и интеллектуальный анализ данных» — аналитики данных возьмут всю эту информацию, проанализируют ее и затем вернутся к вам с результатами
Представьте, что у вас есть небольшая компания, которая продает определенный тип кофе. Вы следуете всем золотым правилам маркетинга, рекламируете как традиционно, так и в Интернете, тратите много времени на свою аудиторию и т. д. Проходит месяц, и вы хотите узнать, как работает ваш бизнес. Это не значит просто посмотреть на доход (который вы надеетесь получить!). Если вы хотите, чтобы ваш бизнес был успешным, вам нужно будет определить возможные узкие места и проблемы, выяснить, какие группы вашей целевой аудитории не покупают продукт (и почему), а затем принять определенные решения, основанные на предоставленной информации. Однако вся информация, которая вам потребуется, генерируется в виде числовых строк — вам нужно обладать определенными знаниями, чтобы понимать данные. Здесь начинает работать «специалист по анализу данных и интеллектуальный анализ данных» — аналитики данных возьмут всю эту информацию, проанализируют ее и затем вернутся к вам с результатами.
Несмотря на то, что это очень простая версия (пример) ответа на вопрос «что делает аналитик данных?» у вас теперь должно быть достаточно приличное представление об обязанностях этих профессионалов. С учетом вышесказанного давайте перейдем к следующей части нашей статьи о сравнении «аналитик данных и специалист по данным» и поговорим о том, что делают ученые.