R-studio
Содержание:
- Computational Infrastructure
- Стиль программирования R[править]
- Special Areas of Application
- Инструменты
- Introduction to R
- Форматы данных
- Прозрачность и воспроизводимость
- Доводы в пользу R
- 5.Множество готовых функций статистического анализа
- Python
- Создание функций: три наглядных примера!
- R – отличное средство для визуализации данных
- Особенности
- Коммерческая поддержка R
- Как выглядит среда R?
- Программа R-Keeper: что это такое простыми словами?
- useR! конференции
- R – идеальный инструмент для Big Data и Machine Learning
- Заключение
Computational Infrastructure
Projects focusing on computational infrastructure, user interfaces, web-based services, etc.
Omegahat: Distributed Statistical Computing
Omega is a joint project with the goal of providing a variety of open-source software for statistical applications. The Omega project began with discussions among designers responsible for three current statistical languages (S, R, and Lisp-Stat), with the idea of working together on new directions with special emphasis on web-based software, Java, the Java virtual machine, and distributed computing. Omega encourages participation by anyone wanting to extend computing capabilities in one of the existing languages, to those interested in distributed or web-based statistical software, and to those interested in the design of new statistical languages.
ESS: Emacs speaks Statistics
An Emacs-Lisp interface to interactive statistical programming and data analysis languages, including: S dialects (such as R), LispStat dialects and SAS.
R for Mediawiki
allows to run R programs and display results (graphics, text) within Mediawiki, the software behind Wikipedia and other wiki projects.
TANGO/ALGENCAN
Fortran code for the Augmented Lagrangian method for nonlinear programming problems, with interfaces to AMPL, C/C++, CUTEr, Matlab, Python, Octave and R.
Стиль программирования R[править]
- R — это объектно-ориентированный язык программирования. Это означает, что теоретически всё что угодно может быть сохранено как объект R. Каждый объект имеет свой класс, описывающий что содержит этот объект и что каждая функция может с этими данными делать. Например, plot(x) выводит один результат, если x является регрессией, и другой, если вектором.
- Символом присвоения является «<-». Также возможно использовать классический «=».
Два следующих выражения являются эквивалентными:
- Аргументы передаются в круглых скобках.
- Обычно, лучше использовать кавычки для имён, но это не всегда необходимо.
- Функции можно просто комбинировать. Например, вы можете написать:
«#» используется для комментариев:
Команды отделяются точкой с запятой «;» или символом перевода каретки. Если вы хотите разместить в одной строке более одного выражения, то необходимо использовать разделитель «;».
- Также вы можете разбить одно выражение на несколько строк кода.
- R чувствителен к регистру: «a» и «A» являются двумя разными объектами.
- Традиционно символ подчёркивания «_» не используется в именах. Зачастую лучше использовать символ точки «.». Следует избегать использования символа подчёркивания в качестве первого символа в имени объекта.
Special Areas of Application
Projects focusing on special application areas, statistical models, etc.
Bioconductor: Bioinformatics with R
The broad goals of Bioconductor are to
- provide access to a wide range of powerful statistical and graphical methods for the analysis of genomic data;
- facilitate the integration of biological metadata in the analysis of experimental data: e.g. literature data from PubMed, annotation data from LocusLink;
- allow the rapid development of extensible, scalable, and interoperable software;
- promote high-quality and reproducible research;
- provide training in computational and statistical methods for the analysis of genomic data.
Rgeo: Spatial Statistics with R
This collection of web pages is intended to be a supplement to the Spatial Task View on CRAN. It provides news, and guides to some of the resources for the analysis of spatial data using R, and other associated software.
Robust Statistics with R
This web page contains information about the development of tools in R for methods in Robust Statistics.
Rmetrics: Financial Market Analysis with R http://www.rmetrics.org
Rmetrics is an open source solution for financial market analysis and valuation of financial instruments.
Инструменты
Для удобства работы с R разработан ряд графических интерфейсов, в том числе RStudio, JGR, RKWard, SciViews-R, Statistical Lab, R Commander, Rattle, а также программный пакет Shiny.
Кроме того, в ряде текстовых и кодовых редакторов предусмотренные специальные режимы для работы с R, в частности в ConTEXT, Emacs (Emacs Speaks Statistics), jEdit, Kate, Notepad++, Syn, TextMate, Tinn-R, Vim, Bluefish, WinEdt (с пакетом RWinEdt), Gedit (с пакетом rgedit/gedit-r-plugin). Для среды разработки Eclipse существует специализированный R-плагин; доступ к функциям и среде выполнения R возможен из Python с использованием пакета RPy; работать с R можно из эконометрического пакета Gretl.
Introduction to R
R is a language and environment for statistical computing and graphics. It is a GNU project which is similar to the S language and environment which was developed at Bell Laboratories (formerly AT&T, now Lucent Technologies) by John Chambers and colleagues. R can be considered as a different implementation of S. There are some important differences, but much code written for S runs unaltered under R.
R provides a wide variety of statistical (linear and nonlinear modelling, classical statistical tests, time-series analysis, classification, clustering, …) and graphical techniques, and is highly extensible. The S language is often the vehicle of choice for research in statistical methodology, and R provides an Open Source route to participation in that activity.
One of R’s strengths is the ease with which well-designed publication-quality plots can be produced, including mathematical symbols and formulae where needed. Great care has been taken over the defaults for the minor design choices in graphics, but the user retains full control.
R is available as Free Software under the terms of the Free Software Foundation’s GNU General Public License in source code form. It compiles and runs on a wide variety of UNIX platforms and similar systems (including FreeBSD and Linux), Windows and MacOS.
Форматы данных
С точки зрения статистики, данные принято делить на типы в зависимости от того, насколько близко их можно представить при помощи известной метафоры числовой прямой. Например, возраст человека легко представить таким образом, за тем исключением, что он не может быть отрицательным. Размер ботинок представить так уже сложнее, поскольку между двумя соседним размерами, как правило, не бывает промежуточного значения. В то время как между двумя любыми числами на числовой прямой всегда можно найти нечто промежуточное. Зато размеры можно хотя бы расположить по возрастающей или по убывающей. А вот пол человека так представить уже совсем не получится: есть только два значения, и «промежуточного» просто не бывает. Мы, конечно, можем обозначить женский пол единицей, а мужской — нулём (или двойкой), но никакой числовой информации эти обозначения нести не будут — их даже нельзя отсортировать. Есть ещё и другие специальные виды данных, например, углы, географические координаты, даты и т. п., но все они так или иначе могут быть представлены с помощью чисел. Таким образом, наиболее принципиальное различие между типами данных — это можно или нельзя их представить при помощи «обычных» чисел. Если нельзя, то такие данные принято называть категориальными. Статистические законы, а, значит, и статистические программы, работают с такими данными, только если заранее указан их тип. Остальные типы данных в разных книгах называют по разному: числовые, счётные, порядковые или некатегориальные. Примем название «числовые» как самое простое.
Итак, основными типами данных являются:
- Числовые векторы
- Факторы
- Пропущенные данные
- Матрицы
- Списки
Прозрачность и воспроизводимость
Поскольку набор инструкций на R – это полноценная программа, она может повторяться с другими данными, достаточно просто читается, расширяется и тиражируется. Программный код выглядит как линейный скрипт, каждую строку которого можно сопроводить поясняющими комментариями. Интерпретация кода, т.е. выполнение инструкций, выполняется линейно, что облегчает мониторинг получения результатов. А если в программу внесены какие-либо изменения, отследить их довольно просто, просмотрев историю команд .
 Линейные инструкции кода на R понятны даже не профессиональному программисту
Линейные инструкции кода на R понятны даже не профессиональному программисту
Доводы в пользу R
R — язык, ориентированный на статистику. Его можно рассматривать в качестве конкурента для таких аналитических систем, как SAS Analytics, не говоря уже о таких более простых пакетах, как StatSoft STATISTICA или Minitab. Многие профессиональные статистики и методисты в правительственных организациях, в коммерческих компаниях и в фармацевтической отрасли решают свои задачи с помощью таких продуктов, как IBM SPSS или SAS, без написания какого-либо кода на языке R. Таким образом, в значительной степени решение об изучении и использовании R — это вопрос корпоративной культуры и профессиональных предпочтений применительно к рабочим инструментам. В своей статистической консультационной практике я использую несколько инструментов, однако большая часть того, что я делаю, сделана на R. Следующие примеры объясняют, почему дело обстоит именно таким образом.
- R — это мощный скриптовый язык. Недавно меня попросили проанализировать результаты одного масштабного исследования. Исследователи просмотрели 1600 научных работ и закодировали их содержимое по нескольким критериям — количество критериев было действительно большим, особенно с учетом множественных вариаций и ветвлений. После переноса в электронную таблицу Microsoft Excel эти данные содержали более 8000 столбцов, большинство из которых были пустыми. Исследователи хотели подсчитывать общие количества по различным категориям и под разными заголовками. R является мощным скриптовым языком и поддерживает Perl-подобные регулярные выражения для обработки текста. Для обработки неупорядоченных данных требуются возможности языка программирования; продукты SAS и SPSS имеют скриптовые языки для задач, для решения которых недостаточно ниспадающего меню, однако R был создан именно как язык программирования и поэтому является более подходящим инструментом для этой цели.
- R — лидер направления. Многие новые разработки в области статистики сначала появляются как пакеты для платформы R («R-пакеты») и только потом приходят на коммерческие платформы. Недавно я получила данные медицинского исследования по повторным обращениям пациентов. По каждому пациенту в этих данных имелось количество элементов лечения, предложенных врачом, и количество элементов, которые реально запомнил пациент. Естественной моделью для этой ситуации является т. н. бета-биномиальное распределение. Оно известно с 1950-х годов, однако процедуры оценки, связывающие модель с интересующими нас ковариациями, появились лишь недавно. Такие данные обычно обрабатываются с помощью т.н. GEE-методов (Generalized Estimating Equations), однако эти методы являются асимптотическими и исходят из предположения, что выборка имеет большие размеры. Мне требовалась обобщенная линейная модель с бета-биномиальным распределением. Один из недавно появившихся R-пакетов осуществляет оценку согласно этой модели: пакет betabinom, автором которого является Бен Болкер (Ben Bolker). Инструмент SPSS не имеет таких возможностей.
- Интеграция со средствами публикации документов. R органично интегрируется с системами публикации документов, что позволяет встраивать статистические результаты и графику из среды R в документы публикационного качества. Эта возможность не нужна абсолютно всем, однако если вы хотите написать книгу о своем анализе данных или просто не любите копировать свои результаты в документы текстового процессора, то самый короткий и самый элегантный маршрут состоит в использовании R и LaTeX.
- Я — владелец небольшой компании, поэтому мне нравится, что R распространяется свободно. Даже для более крупного предприятия весьма неплохо, когда в случае привлечения нужного специалиста на временной основе оно способно немедленно предоставить такому специалисту рабочую станцию с передовым аналитическим программным обеспечением. При этом нет никакой необходимости волноваться о бюджете.
5.Множество готовых функций статистического анализа
Создание векторов и таблиц, их индексирование, ранжирование, вычисление детерминантов, сложение и умножение, транспонирование – в R есть функции для любых матричных операций. А также расчет дисперсии, корреляции и ковариации, поиск идентичных и отличающихся элементов в выборках и множество других математических и статистических операторов входит в стандартный набор библиотек R. Если необходимы более сложные и специфические вычисления, совсем необязательно разрабатывать их самостоятельно – открытый репозиторий постоянно дополняется новыми пакетами, которые можно загрузить в любой момент и использовать бесплатно .
Python
Совершенно незаметно подкралось тридцатилетие Python. За свою уже немалую историю Python несколько раз перерождался, теряя обратную совместимость, но всегда оставался популярен как среди разработчиков в общем, так, в частности, и среди data scientist’ов. На это есть несколько причин.
Преимущества Python в Data Science
- Простой, но выразительный синтаксис. Знание английского языка на уровне первых классов школы — это уже победа, потому что азы Python можно считать освоенными. Дальше будет не сильно сложнее. Если же вы уже знакомы, например, с Java, то вы будете приятно удивлены тем, как легко сказать миру «привет».
- Богатый выбор библиотек. И речь не только о библиотеках алгоритмов машинного обучения — на Python разрабатывают облачные хранилища, стриминговые сервисы, и даже игры (хоть в них иногда и приходится обыгрывать тормоза как фичу, а не баг).
- Высокая культура документации. Сам Python прекрасно документирован, и обычно библиотеки на нём продолжают эту традицию.
***
При всём своём великолепии, Python не лишён и минусов. Его часто (и иногда заслуженно) называют медленным, ему всё ещё не хватает удобных средств ORM, а написание действительного крупного проекта на нём — довольно тяжёлый труд, требующий хорошей дисциплины
Но как и с любым другим инструментом, важно просто знать, как им пользоваться. Кстати об инструментах
Python-инструменты для data scientist
Как уже упоминалось ранее, Python примечателен своим обширным набором библиотек и инструментов. Говоря о data science, нужно в первую очередь упомянуть следующие:
- Pandas — библиотека для манипулирования данными с огромными возможностями. Позволяет очень быстро провести исследование новых данных, протестировать гипотезы, получить отчёт. Одно из главных преимуществ Python.
- Scikit-learn — большая библиотека алгоритмов машинного обучения и обработки данных. Немалую часть соревнований на Kaggle выиграли пользуясь только ей в паре с Pandas.
- Keras и PyTorch — библиотеки, используемые для обучения глубоких нейронных сетей. Подходят для задач, связанных с изображениями, аудио и видео файлами.
- IPython Notebook — рассказывая о Python нельзя не упомянуть о нём. Стандартная среда разработки не совсем подходит data scientist’у в процессе исследования данных. Есть потребность в таком формате, который позволил бы, например, запустить затратный алгоритм, а когда он завершится — поиграть немного с результатами, исследовать их и построить графики. Здесь на помощь и приходит формат ноутбука. Это графический интерфейс, который открывается в обычном браузере и представляет из себя последовательность ячеек, где можно писать и исполнять код, используя при этом общую память для хранения данных.
Создание функций: три наглядных примера!
Сколько бы функций не существовало в CRAN, рано или поздно придется написать свои собственные. Причин на это может быть несколько: такой функции еще не написано; проще написать свою, чем искать ее в других R пакетах: и т.д. Так или иначе, создать функции совсем не сложно. Для того, чтобы это доказать, я приведу три простых примера, которые помогут понять логику построения функций.
Пример 1: сколько будет 2+2×2?
Создадим простейшую функцию, основанную исключительно на арифметических действиях. Например, вычислим знакомый нам с начальной школы пример: сколько будет 2+2*2? Усложним немного: 12+12*12? Ну и в завершении арифметических упражнений 42+42*42? Как Вы могли заметить, все эти примеры основаны на одной и той же формуле: a+a*a. Создание функции в R будет идеальным решением для подобного рода задач.
Результат вычислений функции отобразится на экране консоли, т.к. для вывода информации мы использовали базовую функцию print() внутри нашей функции. Когда же нам требуется сохранить результат в виде отдельного объекта (переменной), следует воспользоваться функцией return(), что мы сделаем в следующем примере.
Пример 2: от горшка два вершка
В детстве мы все читали русские народные сказки. Меня, например, всегда интересовало что значит фраза «от горшка два вершка», а точнее сколько это в сантиметрах. Думаю, пришло время получить ответ: создадим конвертер вершков в R при помощи новой функции convershok().
Один вершок равен 4.445 см. Пусть программа выводит на экран предложение от том, что столько вершков равняется столько-то сантиметров, используя базовую функцию для объединения текстовых и числовых объектов paste(). Также мы хотим, чтобы полученное значение сохранялись как отдельный объект, для чего в конце функции добавим return(vershok).
Пример 3: ноутбук в кредит, сколько придется переплатить?
Допустим, у студента сломался ноутбук. На данный момент у него нет свободных денег на покупку нового, и он решил взять его в кредит. В банке ему предложили кредит на сумму 30.000 рублей с процентной ставкой 35% годовых и возможностью преждевременного погашения. Рассчитаем сколько денег нужно выплатить за ноутбук при погашении кредита через месяц, три месяца и год.
Для расчетов я использую процентов, начисленных за пользование кредитом в течение n месяцев.
sp = p * (t + 1) / 24, где:
sp — сумма процентаp — годовая процентная ставкаt — срок кредита (месяцев).
Реализуем эту формулу в R, после чего добавим к цене ноутбука (n) высчитанный суммарный процент (sp), помноженный на цену ноутбука товара (n):
Как Вы видите, 35% годовых отнють не означает, что студент будет платить за кредит 35% от текущей стоимости ноутбука: в реальности за год он переплатит на 19%. Другой интересный вывод в том, что кредитный процент на один месяц гораздо выше, чем усредненный месячный процент на три месяца и тем более на год. То есть брать кредиты на долгий срок «выгодно» 🙂
А главное, наш студент может использовать эту же функцию для своих будущих расчетов, если решит брать кредит в другом банке с другой процентной ставкой или выбрать ноутбук в другой ценовой категории. Для этого ему лишь надо изменить значения аргументов в функции.
R – отличное средство для визуализации данных
Круговые и ящичные диаграммы, матрицы рассеивания, двумерные и трехмерные зависимости, графики интегральных функций распределения и другие более сложные способы визуализации данных – множество встроенных математических функций и средств их реализации позволят вам изобразить любую взаимосвязь различных переменных, например:
- статистика эффективности работы командной работы;
- динамика квартальных продаж группы продуктов по филиалам компании;
- котировки фондовой биржи;
- вероятности снижения и повышения спроса на ваши услуги при появлении новых конкурентов.
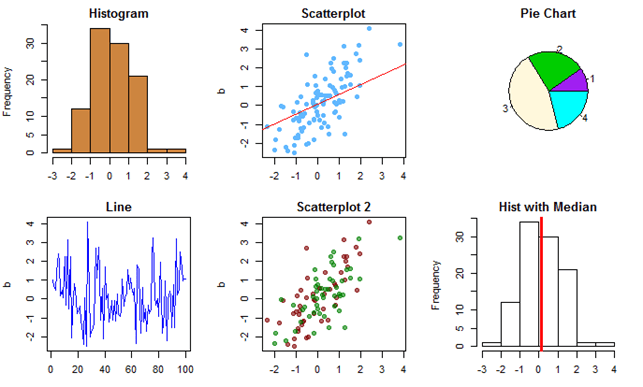 R поддерживает различные виды графиков
R поддерживает различные виды графиков
Особенности
R — интерпретируемый язык программирования, основным способом работы с которым является командный интерпретатор. Язык является регистрозависимым, в плане синтаксиса он похож, с одной стороны, на функциональные языки типа Scheme, с другой — на типичные современные сценарные языки, с простым синтаксисом и небольшим набором основных конструкций. Язык объектный: любой программный объект в нём имеет набор атрибутов — именованный список значений, определяющих его.
Язык поддерживает минимальный набор примитивных типов данных: символьный (character), числовой (numeric), логический (logical) и комплексный (complex). Числовые переменные, помимо обычных чисел, могут принимать специальные значения NaN (Not a Number — «не число») и Inf (Infinity — «бесконечность»). Бесконечность (положительная или отрицательная) получается при выходе результата вычислений за пределы представимого реализацией диапазона, NaN — при операциях с неопределённым результатом
Помимо этих, имеется ещё одно очень важное специальное значение, NA (Not Available — «не доступно»). Оно может быть использовано для фиксации того факта, что соответствующее значение, участвующее в вычислениях, по какой-либо причине не было получено (достаточно обычная в статистических расчётах ситуация, когда из-за сбоев в сборе данных некоторые наблюдения остаются без результатов).
Значения примитивных типов могут объединяться в векторы (vector), списки (list), матрицы или массивы (matrix), в том числе многомерные; эти комбинированные типы хранят наборы данных одного и того же примитивного типа. Помимо этого язык содержит понятие факторов (factor) — наборов категориальных или шкальных данных, принимающих строго определённый набор значений. Наконец, могут создаваться таблицы (data frame) — структуры данных, которые для каждой строки (индивида) хранят набор различных (и имеющих разные типы) параметров (признаков). Особенностью R является то, что операции с векторами и матрицами поддерживаются на уровне самого языка, как, например, в APL.
Существует операция извлечения и записи данных (аналог присваивания) «», а также обычные операции работы с данными, в том числе арифметические. Доступ по индексу к элементам векторов и массивов осуществляется с помощью квадратных скобок, доступ к атрибутам списков — посредством оператора «». Имеется минимальный набор обычных конструкций императивного программирования: условный оператор , циклы и . Выражения на R можно описывать как отдельные объекты и вычислять по мере необходимости. На этом же механизме основано описание функций. Имеются встроенные в язык средства применения выражений и функций к векторам и массивам.
Функции R могут объединяться в пакеты — загружаемые модули, которые подключаются к любой программе и предоставляют объединённые в них вычислительные средства. Пакеты для R могут разрабатываться на других языках программирования, в том числе на Си, что позволяет, с одной стороны, скомпенсировать ограниченность изобразительных средств самого языка R, а с другой — при необходимости достигнуть высоких показателей вычислительной производительности.
Сам язык имеет довольно ограниченные и не слишком удобные средства описания данных, но это компенсируется наличием библиотечных средств, которые позволяют загружать в виде таблиц R наборы данных, представленных в большинстве открытых и многих проприетарных форматах. Так, в R могут быть легко загружены таблицы в простом текстовом формате, таблицы Excel различных версий, данные в форматах CSV, XML и многих других.
В целом, как язык программирования, R довольно прост и даже примитивен. Его наиболее сильная сторона — возможность неограниченного расширения с помощью пакетов. В базовую поставку R включен основной набор пакетов, а всего по состоянию на 2019 год доступно более 15 316 пакетов. В R реализованы практически все актуальные средства универсальных статистических вычислений, такие как регрессионный анализ и анализ временных рядов, а также множество специфических алгоритмов для решения узкоспециализированных задач и исследований в отдельных областях.
Ещё одна особенность языка — возможность создания качественной графики типографского уровня, которая может быть экспортирована в распространённые графические форматы и использована для презентаций или публикаций. Имеются готовые пакеты, связывающие R с GUI-фреймворками (например, основанными на Tcl/Tk) и позволяющие создавать специализированные утилиты статистического анализа с графическим интерфейсом пользователя и отображением результатов в виде графиков и диаграмм.
Коммерческая поддержка R
В 2007, Revolution Analytics была создана для обеспечения коммерческой поддержки Revolution R, её распространения R, которое также включает в себя компоненты, разработанные компанией. Основные дополнительные компоненты включают в себя: ParallelR, R Productivity Environment IDE, RevoScaleR для bigdata анализа, RevoDeployR, фреймворк для веб сервисов и возможность для чтения и записи данных в формате SAS.
В 2015, Microsoft завершила сделку по приобретению Revolution Analytics.
В Октябре 2011, Oracle анонсировали Big Data Appliance, который интегрирован в R, Apache Hadoop, Oracle Linux, и NoSQL базы данных.
Oracle R один из двух компонент «Oracle Advanced Analytics Option» (другой компонент — Oracle Data Mining).
IBM предлагает поддержку в Hadoop исполнении R, и обеспечивает модель программирования для параллельного аналитического анализа информации баз данных в R.
Другие крупные коммерческие системы программного обеспечения, поддерживающие интегразции с R:
JMP,
Mathematica,
MATLAB,
Spotfire,
SPSS,
STATISTICA,
Platform Symphony,
SAS,
Tableau, and
Dundas.
Tibco предлагает runtime версию R как часть Spotfire.
Как выглядит среда R?
Существует много «оболочек» для R, внешний вид и функциональность которых могут сильно отличаться. Но мы коротко рассмотрим лишь три наиболее популярных варианта: Rgui, Rstudio и R, запущенный в терминале Linux/UNIX в виде командной строки.
Rgui — это стандартный графический интерфейс (https://cran.r-project.org/), встроенный в R по умолчанию. Эта оболочка имеет вид командной строки в окне, называемым консолью. Командная строка работает по принципу «вопрос-ответ».
Например:> 2 + 2 * 2 # наш вопрос/запрос 6 # ответ компьютера
Однако, для записи сложного алгоритма команд в Rgui существует дополнительное скриптовое окно, где пишется программа (скрипт). Третьим элементом данной оболочки является графический модуль, который появляется при необходимости отображения графиков.
На приведенном ниже рисунке, показана полная версия Rgui: консоль (слева), скриптовое окно и графический модуль (справа).

Rstudio — интегрированная среда разработки (IDE) (https://www.rstudio.com/). В отличие от Rgui, у данной оболочки есть заранее разделенные области и дополнительные модули (например, история команд, рабочая область). По мнению некоторых пользователей, Rstudio имеет более удобный интерфейс, упрощающий работу с R. Ряд особенностей, таких как цветовая подсветка и автоматическое завершение кода, удобная навигация по скрипту и другие, делают Rstudio привлекательной не только для новичков, но и для опытных программистов.

R в терминале Linux/UNIX. Данный вариант предпочтителен для анализа большого объема данных через сервер, суперкластер или суперкомпьютер. Большинство из них работают на операционных системах класса Linux/UNIX, доступ к которым осуществляется через терминал команд (например, bash). R в терминале представляет собой приложение, запущенное в виде командной строки (можете попрактиковаться здесь).
Программа R-Keeper: что это такое простыми словами?
Пандемия рано или поздно, но закончится. Посетители начнут ходить в кафе, бары и рестораны. Будем надеяться, что всё произойдёт в ближайшее время. Снова понадобится вести автоматизированный учёт в сфере общепита. В этом могут пригодиться современные технологии.
В далёком уже 1992-ом году была разработана российской компанией UCS система «R_keeper», которая позволяет сделать работу и учёт более прибыльной и комфортной. Она значительно упрощает работу бухгалтеров, поваров, официанток и работников склада. Ну а наблюдая за отчётностью и анализируя данные, менеджеры и управляющие могут эффективней принимать решения и всё держать под своим контролем.
Приобрести её можно у официального дилера ЗДЕСЬ.
Предлагаем Вашему вниманию небольшое видео на нашу сегодняшнюю тему:
Основные опции
Зачем же она нужна и в что в ней такого интересного? Она позволяет:
- Собирает, обрабатывает и систематизирует информацию, получаемую от сотрудников.
- Позволяет разрабатывать разные программы повышения лояльности, как для постоянных, так и для новых клиентов.
- Получает и обобщает сведения о действиях клиентов.
- Подвергает анализу проведённые акции (скидки, бонусы и т. п.), а также программы лояльности.
- Контролирует продажи. Можно выбирать функции по наименованию продукции, разным точкам или клиентам.
- Может вносить в базу данных связь с посетителями и взаимодействовать с ними в дальнейшем. Поздравлять с днём рождения, праздниками, сообщать об акциях и т.д.
Ещё одно полезное видео:
R-Keeper CRM
Начав пользоваться ею Вы сможете значительно повлиять на покупательную способность своих посетителей. Является отличным инструментом для расширения бизнеса и увеличения прибыли. Алгоритм довольно-таки прост. Зная предпочтения посетителей, мы сможем увеличить размер среднего чека, мотивируя его использовать акционные и бонусные предложения.
Умело пользуясь этим приложением можно добиться многого. Разработчики постоянно совершенствуют его. Опытные специалисты технической поддержки всегда окажут необходимую помощь. Десятки тысяч пользователей по всему миру уже давно оценили возможности, успешно пользуются.
Пользуясь данным приложением «R-Keeper CRM» Вы добьётесь значительных результатов. Кроме того, сэкономите массу времени, сил, нервов.
Работайте с ней и у Вас появится возможность:
- Привлечь в свои заведения много новых людей.
- Увеличить количество постоянных завсегдатаев.
- Сформировать интерес и повысить покупательскую способность.
- Определить условия, благодаря которым количества продаж возрастут.
- Анализировать продажи, внедрять новые методы, служащие мотивацией для увеличения прибыли.
Всего хорошего!
useR! конференции
Официальное ежегодное собрание пользователей R называется «useR!». Первым таким мероприятием было useR! 2004 г., май 2004 г., Вена , Австрия. Пропустив 2005 год, файл useR! конференция проводится ежегодно, как правило, чередуя места в Европе и Северной Америке. Последующие конференции включали:
- useR! 2006, Вена, Австрия
- useR! 2007, Эймс, Айова, США
- useR! 2008, Дортмунд, Германия
- useR! 2009, Ренн, Франция
- useR! 2010, Гейтерсбург, Мэриленд, США
- useR! 2011, Ковентри, Великобритания
- useR! 2012, Нэшвилл, Теннесси, США
- useR! 2013, Альбасете, Испания
- useR! 2014, Лос-Анджелес, Калифорния, США
- useR! 2015, Ольборг, Дания
- useR! 2016, Стэнфорд, Калифорния, США
- useR! 2017, Брюссель, Бельгия
- useR! 2018, Брисбен, Австралия
- useR! 2019, Тулуза, Франция
- useR! 2020, Сент-Луис, Миссури, США (Отменено)
На будущее запланированы следующие конференции:
useR! 2021, Цюрих, Швейцария
R – идеальный инструмент для Big Data и Machine Learning
Если вам, например, необходимо быстро обработать данные по 1000 сотрудникам или найти средний бал выпускников ВУЗа по 5 специальностям за последние 10 лет, несколько инструкций на языке R справятся с этой задачей за пару секунд. Благодаря наличию множества статистических функций, R отлично решает классические задачи машинного обучения :
- кластеризация, например, разделить всех клиентов по уровню платёжеспособности, отнести космический объект к той или иной категории (планета, звезда, чёрная дыра и т. п.);
- регрессия – числовой прогноз на основе выборки объектов с различными признаками, например, предполагаемая цена квартиры, стоимость ценной бумаги по прошествии полугода, ожидаемый доход магазина на следующий месяц, качество вина при слепом тестировании и т.д.;
- выявление аномалий – поиск малого количества специфических случаев в большой выборке, например, мошеннические действия с банковскими картами.
Заключение
Таким образом, в настоящее время язык R является одним из ведущих статистических инструментов в мире. Он активно применяется в генетике, молекулярной биологии и биоинформатике, науках об окружающей среде (экология, метеорология) и сельскохозяйственных дисциплинах. Также R все больше используется в обработке медицинских данных, вытесняя с рынка такие коммерческие пакеты, как SAS и SPSS.
Достоинства среды R:
- бесплатная и кроссплатформенная;
- богатый арсенал стат. методов;
- качественная векторная графика;
- более 7000 проверенных пакетов;
- гибкая в использовании:- позволяет создавать/редактировать скрипты и пакеты,- взаимодействует с другими языками, такими: C, Java и Python,- может работать с форматами данных для SAS, SPSS и STATA;
- активное сообщество пользователей и разработчиков;
- регулярные обновления, хорошая документация и тех. поддержка.
Недостатки:
- небольшой объем информации на русском языке (хотя за последние пять лет появилось несколько обучающих курсов и интересных книг);
- относительная сложность в использовании для пользователя, незнакомого с языками программирования. Частично это можно сгладить работая в GUI оболочке Rcmdr, о которой я писал выше, но для нестандартных решений все же необходимо использовать командную строку.
Список полезных источников
P.S. Надеюсь, эта статья помогла разобраться в том, что такое R и с чем его едят! Если Вы хотите задать вопрос об R или обсудить содержание самой статьи, то оставьте свой комментарий под этим постом. Если Вы думаете, что она может быть полезной и интересной для Ваших знакомых, то поделитесь ей с помощью социальных кнопок, расположенных ниже.