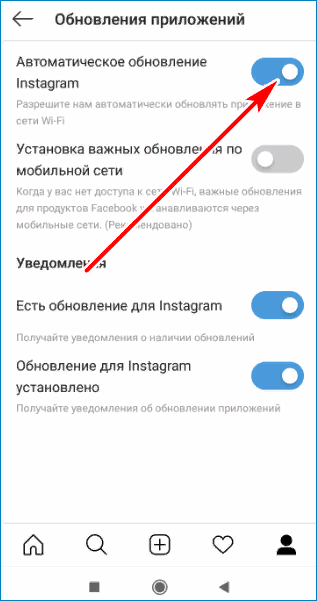
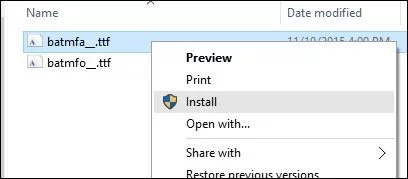
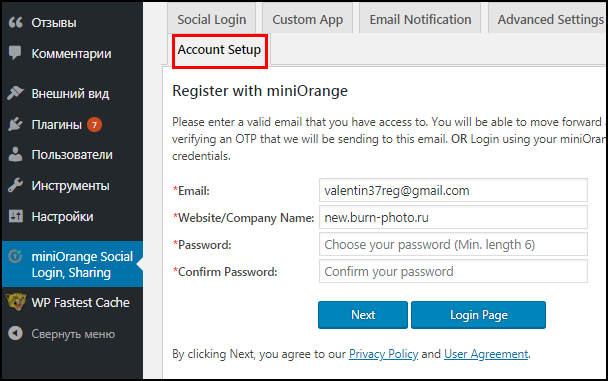
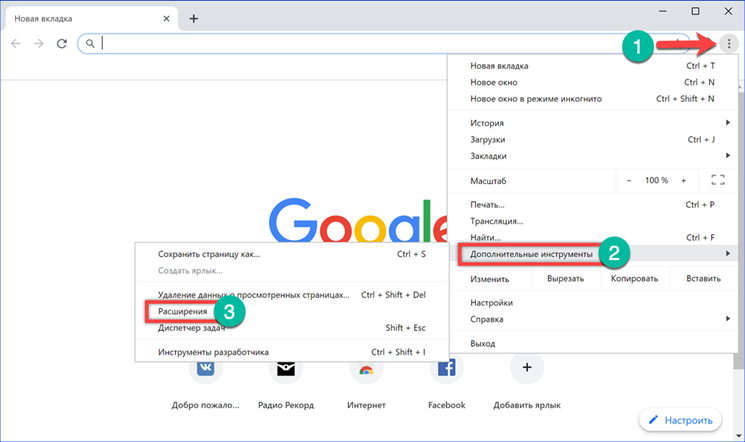
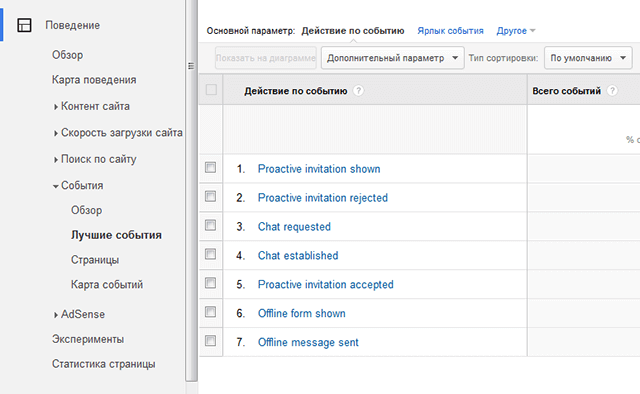
Установка и обновление
Содержание:
Варианты разбора
- Решать задачу в лоб, то есть анализировать посимвольно входящий поток и используя правила грамматики, строить АСД или сразу выполнять нужные нам операции над нужными нам компонентами. Из плюсов — этот вариант наиболее прост, если говорить об алгоритмике и наличии математической базы. Минусы — вероятность случайной ошибки близка к максимальной, поскольку у вас нет никаких формальных критериев того, все ли правила грамматики вы учли при построении парсера. Очень трудоёмкий. В общем случае, не слишком легко модифицируемый и не очень гибкий, особенно, если вы не имплементировали построение АСД. Даже при длительной работе парсера вы не можете быть уверены, что он работает абсолютно корректно. Из плюс-минусов. В этом варианте все зависит от прямоты ваших рук. Рассказывать об этом варианте подробно мы не будем.
- Используем регулярные выражения! Я не буду сейчас шутить на тему количества проблем и регулярных выражений, но в целом, способ хотя и доступный, но не слишком хороший. В случае сложной грамматики работа с регулярками превратится в ад кромешный, особенно если вы попытаетесь оптимизировать правила для увеличения скорости работы. В общем, если вы выбрали этот способ, мне остается только пожелать вам удачи. Регулярные выражения не для парсинга! И пусть меня не уверяют в обратном. Они предназначены для поиска и замены. Попытка использовать их для других вещей неизбежно оборачивается потерями. С ними мы либо существенно замедляем разбор, проходя по строке много раз, либо теряем мозговые клеточки, пытаясь измыслить способ удалить гланды через задний проход. Возможно, ситуацию чуть улучшит попытка скрестить этот способ с предыдущим. Возможно, нет. В общем, плюсы почти аналогичны прошлому варианту. Только еще нужно знание регулярных выражений, причем желательно не только знать как ими пользоваться, но и иметь представление, насколько быстро работает вариант, который вы используете. Из минусов тоже примерно то же, что и в предыдущем варианте, разве что менее трудоёмко.
- Воспользуемся кучей инструментов для парсинга BNF! Вот этот вариант уже более интересный. Во-первых, нам предлагается вариант типа lex-yacc или flex-bison, во вторых во многих языках можно найти нативные библиотеки для парсинга BNF. Ключевыми словами для поиска можно взять LL, LR, BNF. Смысл в том, что все они в какой-то форме принимают на вход вариацию BNF, а LL, LR, SLR и прочее — это конкретные алгоритмы, по которым работает парсер. Чаще всего конечному пользователю не особенно интересно, какой именно алгоритм использован, хотя они имеют определенные ограничения разбора грамматики (остановимся подробнее ниже) и могут иметь разное время работы (хотя большинство заявляют O(L), где L — длина потока символов). Из плюсов — стабильный инструментарий, внятная форма записи (БНФ), адекватные оценки времени работы и наличие записи БНФ для большинства современных языков (при желании можно найти для sql, python, json, cfg, yaml, html, csv и многих других). Из минусов — не всегда очевидный и удобный интерфейс инструментов, возможно, придется что-то написать на незнакомом вам ЯП, особенности понимания грамматики разными инструментами.
- Воспользуемся инструментами для парсинга PEG! Это тоже интересный вариант, плюс, здесь несколько побогаче с библиотеками, хотя они, как правило, уже несколько другой эпохи (PEG предложен Брайаном Фордом в 2004, в то время как корни BNF тянутся в 1980-е), то есть заметно моложе и хуже выглажены и проживают в основном на github. Из плюсов — быстро, просто, часто — нативно. Из минусов — сильно зависите от реализации. Пессимистичная оценка для PEG по спецификации вроде бы O(exp(L)) (другое дело, для создания такой грамматики придется сильно постараться). Сильно зависите от наличия/отсутствия библиотеки. Почему-то многие создатели библиотек PEG считают достаточными операции токенизации и поиска/замены, и никакого вам AST и даже привязки функций к элементам грамматики. Но в целом, тема перспективная.
Парсите страницы сайтов в структуры данных
Что такое Диггернаут и что такое диггер?

Диггернаут — это облачный сервис для парсинга сайтов, сбора информации и других ETL (Extract, Transform, Load) задач. Если ваш бизнес лежит в плоскости торговли и ваш поставщик не предоставляет вам данные в нужном вам формате, например в csv или excel, мы можем вам помочь избежать ручной работы, сэкономив ваши время и деньги!
Все, что вам нужно сделать — создать парсер (диггер), крошечного робота, который будет парсить сайты по вашему запросу, извлекать данные, нормализовать и обрабатывать их, сохранять массивы данных в облаке, откуда вы сможете скачать их в любом из доступных форматов (например, CSV, XML, XLSX, JSON) или забрать в автоматическом режиме через наш API.
Какую информацию может добывать Диггернаут?

- Цены и другую информацию о товарах, отзывы и рейтинги с сайтов ритейлеров.
- Данные о различных событиях по всему миру.
- Новости и заголовки с сайтов различных новостных агентств и агрегаторов.
- Данные для статистических исследований из различных источников.
- Открытые данные из государственных и муниципальных источников. Полицейские сводки, документы по судопроизводству, росреест, госзакупки и другие.
- Лицензии и разрешения, выданные государственными структурами.
- Мнения людей и их комментарии по определенной проблематике на форумах и в соцсетях.
- Информация, помогающая в оценке недвижимости.
- Или что-то иное, что можно добыть с помощью парсинга.
Должен ли я быть экспертом в программировании?

Если вы никогда не сталкивались с программированием, вы можете использовать наш специальный инструмент для построения конфигурации парсера (диггера) — Excavator. Он имеет графическую оболочку и позволяет работать с сервисом людям, не имеющих теоретических познаний в программировании. Вам нужно лишь выделить данные, которые нужно забрать и разместить их в структуре данных, которую создаст для вас парсер. Для более простого освоения этого инструмента, мы создали серию видео уроков, с которыми вы можете ознакомиться в документации.
Если вы программист или веб-разработчик, знаете что такое HTML/CSS и готовы к изучению нового, для вас мы приготовили мета-язык, освоив который вы сможете решать очень сложные задачи, которые невозможно решить с помощью конфигуратора Excavator. Вы можете ознакомиться с документацией, которую мы снабдили примерами из реальной жизни для простого и быстрого понимания материала.
Если вы не хотите тратить свое время на освоение конфигуратора Excavator или мета-языка и хотите просто получать данные, обратитесь к нам и мы создадим для вас парсер в кратчайшие сроки.
Обновление SelfParser 1.3
- Добавлена возможность парсить сайты через прокси.Список прокси указывается в файле selfparser/data/proxy.txt в формате (IP:port). Каждый новые прокси с новой строки. Не оставляйте пустых строк.Если файл пустой, то парсер работает в обычном режиме.
- Добавлен функционал, который умеет заменять или вырезать слова, фразы или код из полученных данных.Есть как простая замена так и с регулярными выражениями, что позволяет очень гибко настроить получение нужных данных.
- Реализованы все страницы: логи, процессы, настройки, прямая ссылка на запуск, faq.Логи показывают такие данные как:- старт парсера;- запуск, остановка парсера;- прокси и время получения данных в секундах;- ссылка на источник, ID новости с ссылкой на новость, которая уже есть на сайте (информация о том, что новость не была добавлена);- информация о переключении шаблона или о невозможности получить контент;- размер файла логов на первой строке. При достижении 1Mb удаляется первая строка и добавляется новая, что позволяет предотвратить нагрузку. Файл обновляется автоматически (через AJAX). Есть кнопка пауза, что бы остановить обновление и просмотреть нужную строчку в логов.
- Добавлена возможность сохранения картинок на сайт в дополнительные поля как одного изображения, так и галереи, читайте далее.
- Выбираете получить элемент -> картинки.
- В поле название поля если указать XF-fieldname | свое название, то полученные изображения будут добавляться в доп поле fieldname. При этом в поле код должен быть указан путь к картинке, например .sidebar img:eq(0) — найдет первую картинку из элемента с классом sidebar.
XF-…поддержку
Основные понятия
- входной символьный поток (далее входной поток или поток) — поток символов для разбора, подаваемый на вход парсера
- parser/парсер (разборщик, анализатор) — программа, принимающая входной поток и преобразующая его в AST и/или позволяющая привязать исполняемые функции к элементам грамматики
- AST(Abstract Syntax Tree)/АСД(Абстрактное синтаксическое дерево) (выходная структура данных) — Структура объектов, представляющая иерархию нетерминальных сущностей грамматики разбираемого потока и составляющих их терминалов. Например, алгебраический поток (1 + 2) + 3 можно представить в виде ВЫРАЖЕНИЕ(ВЫРАЖЕНИЕ(ЧИСЛО(1) ОПЕРАТОР(+) ЧИСЛО(2)) ОПЕРАТОР(+) ЧИСЛО(3)). Как правило, потом это дерево как-то обрабатывается клиентом парсера для получения результатов (например, подсчета ответа данного выражения)
- CFG(Context-free grammar)/КСГ(Контекстно-свободная грамматика) — вид наиболее распространенной грамматики, используемый для описания входящего потока символов для парсера (не только для этого, разумеется). Характеризуется тем, что использование её правил не зависит от контекста (что не исключает того, что она в некотором роде задает себе контекст сама, например правило для вызова функции не будет иметь значения, если находится внутри фрагмента потока, описываемого правилом комментария). Состоит из правил продукции, заданных для терминальных и не терминальных символов.
- Терминальные символы (терминалы) — для заданного языка разбора — набор всех (атомарных) символов, которые могут встречаться во входящем потоке
- Не терминальные символы (не терминалы) — для заданного языка разбора — набор всех символов, не встречающихся во входном потоке, но участвующих в правилах грамматики.
- язык разбора (в большинстве случаев будет КСЯ(контекстно-свободный язык)) — совокупность всех терминальных и не терминальных символов, а также КСГ для данного входного потока. Для примера, в естественных языках терминальными символами будут все буквы, цифры и знаки препинания, используемые языком, не терминалами будут слова и предложения (и другие конструкции, вроде подлежащего, сказуемого, глаголов, наречий и т.п.), а грамматикой собственно грамматика языка.
-
BNF(Backus-Naur Form, Backus normal form)/БНФ(Бэкуса-Наура форма) — форма, в которой одни синтаксические категории последовательно определяются через другие. Форма представления КСГ, часто используемая непосредственно для задания входа парсеру. Характеризуется тем, что определяемым является всегда ОДИН нетерминальный символ. Классической является форма записи вида:
Так же существует ряд разновидностей, таких как ABNF(AugmentedBNF), EBNF(ExtendedBNF) и др. В общем, эти формы несколько расширяют синтаксис обычной записи BNF. - LL(k), LR(k), SLR,… — виды алгоритмов парсеров. В этой статье мы не будем подробно на них останавливаться, если кого-то заинтересовало, внизу я дам несколько ссылок на материал, из которого можно о них узнать. Однако остановимся подробнее на другом аспекте, на грамматиках парсеров. Грамматика LL/LR групп парсеров является BNF, это верно. Но верно также, что не всякая грамматика BNF является также LL(k) или LR(k). Да и вообще, что значит буква k в записи LL/LR(k)? Она означает, что для разбора грамматики требуется заглянуть вперед максимум на k терминальных символов по потоку. То есть для разбора (0) грамматики требуется знать только текущий символ. Для (1) — требуется знать текущий и 1 следующий символ. Для (2) — текущий и 2 следующих и т.д. Немного подробнее о выборе/составлении BNF для конкретного парсера поговорим ниже.
- PEG(Parsing expression grammar)/РВ-грамматика — грамматика, созданная для распознавания строк в языке. Примером такой грамматики для алгебраических действий +, -, *, / для неотрицательных чисел является:
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Возможности
- Независимая админка.
- Парсер работает не зависимо, то есть сам по себе и не зависит от того, какая CMS установлена.
- Возможность создавать неограниченное количество шаблонов (сайтов для парсинга).
- Может получать данные как с сайтов кодировка которых windows-1251 так и UTF-8, а так же конвертировать все полученные данные или отдельный контент в UTF-8.
- Может получать картинки и файлы из контента. Обработчик DLE их сохраняет вам на сервер и заменяет пути картинок в контенте на ваши, и файлы сохраняет к вам на сервер в папку uploads/files/… как положено и добавляет вложения в конец полной новости.
- При создании шаблона, можно проверить его работу, как он получает контент.
- Парсить контент как с HTML тегами, так и без них.
- Включение / выключение шаблонов.
- Ведение логов.
- Статус активности.
- Возможность парсить данные через прокси SOCKS5 типа.
- Возможность удалять скрипты или не удалять.
- Возможность удалять ненужные элементы из полученного контента.
- Возможность заменять или вырезать слова, фразы, код из полученного контента как по точному совпадению, так и по регулярному выражению.
- Парсер обходит каждый созданный Вами шаблон по очереди и проходится по всем новостям или товарам донора. Обработчик DLE сохраняет новость если такой ещё нет (сверяется по заголовку). Если новость уже есть, он переходит к парсингу нового шаблона и так по кругу.
- Работа по крону через простой HTTP запрос.
- Адаптивная панель управления.
- Для DLE:- возможность добавлять полученные данные в доп поля (текст, картинки, галерею и т.д.)- добавлять данные как в одну, так и сразу в несколько категорий на сайт.- добавлять новые посты сразу или ставить на модерацию.
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Интегрировано с
Zapier автоматически перемещает данные между вашими веб-приложениями.
Zapier |
Использование
Tableau — Business Intelligence платформа, лидер рынка платформ для бизнес-аналитики.
Tableau |
Использование
Еще один сервис с помощью которого вы сможете обходить капчи любой сложности.
rucaptcha |
Использование
С помощью сервиса Anti-captcha вы можете обходить капчи любой сложности.
Anti-captcha |
Использование
Luminati, это прокси сервис, который позволит вам иметь любое количество IP адресов.
Luminati |
Использование
С помощью сервиса Death by Captcha вы можете обходить капчи любой сложности.
Deathbycaptcha |
Использование
Proxy-Sellers предоставляют прокси из более чем 100 сетей и 300 различных подсетей.
Proxy-Seller |
Использование
Общие выводы
- Не так страшен чёрт, как его малюют. Создание парсера с помощью инструмента, дело, в общем, посильное. Достаточно изучить общие принципы и потратить полдня на изучение конкретного инструмента, после чего в дальнейшем все уже будет намного проще. А вот велосипеды изобретать — не надо. Особенно, если вам не особенно важна скорость парсинга и оптимизации.
- Грамматики имеют собственную ценность. Имея перед глазами грамматику, гораздо проще оценить, будут ли при использовании составленного по ней парсера возникать ошибки.
- Инструмент можно найти всегда. Возможно, не на самом привычном языке, но почти на всех они есть. Если не повезло, и его все-таки нет, можно взять что-нибудь легко используемое (что-то на js, python, lua или ruby — тут уж кому что больше нравится). Да, получится “почти stand-alone в рамках проекта”, но в большинстве случаев этого достаточно.
- Все инструменты (немного) различаются. Иногда это “:” вместо “=” в BNF, иногда различия более обширны. Не надо этого пугаться. В крайнем случае, переделка грамматики под другой инструмент займет у вас минут 20. Так что если есть возможность достать где-то грамматику, а не писать её самому, лучше это сделать. Но перед использованием все равно лучше её проверьте. Все мы люди, всем нам свойственно ошибаться…
- При прочих равных, лучше используйте более “разговорчивый” инструмент. Это поможет избежать ошибок составления грамматики и оценить, что и как будет происходить.
- Если для вас в первую очередь важна скорость разбора, боюсь, вам придется либо пользоваться инструментом для C (например, Bison), либо решать проблему “в лоб”. Так же, следует задуматься о том, нужен ли вам именно парсинг (об этом стоит задуматься в любом случае, но в случае скоростных ограничений — особенно). В частности, для многих задач подходит токенизация — разбиение строки на подстроки с использованием заданного разделителя или их набора. Возможно, это ваш случай.