Python массивы
Содержание:
- Операции со срезами matrix в Python
- Срезы
- Python Tutorial
- Python Tutorial
- 1.2. Заполнение данными
- Обработка текста в NumPy на примерах
- Массив нарезки
- Присваивание не копирует массивы в Python
- Ways to print NumPy Array in Python
- Печать массивов
- Двумерные массивы
- 1.1. Автозаполнение массивов
- Array Methods
- Related Pages
- Объединение массивов
- Алгоритм MergeSort
- Добавление нового массива
- Python NumPy
- Ввод-вывод массива
Операции со срезами matrix в Python
Часто мы работаем не с целым массивом, а с его компонентами. Эти операции выполняются с помощью метода слайс (срез). Он пришел на замену циклу for, при котором каждый элемент подвергался перебору. Метод позволяет получать копии matrix, причём манипуляции выполняются в виде . В данном случае start — индекс элемента, с которого берётся отсчёт, stop — последний элемент, step — размер шага или число пропускаемых значений элемента при каждой итерации. Изначально start равен нулю, stop — индексу последнего элемента, step — единице. Если выполнить операции без аргументов, копирование и добавление списка произойдёт полностью.
Допустим, имеем целочисленный массив otus = . Для копирования и вывода используем otus. В итоге произойдёт вывод последовательности . Но если аргументом станет отрицательное значение, допустим, -2, произойдёт вывод уже других данных:
otus-2]; //4
Возможны и другие операции. Например, если добавить ещё одно двоеточие, будет указан шаг копируемых элементов. Таким образом, otus позволит вывести матрицу .
Если ввести отрицательное значение, к примеру, отсчёт начнётся с конца, и в результате произойдёт вывод . Остаётся добавить, что метод среза позволяет гибко работать с матрицами и вложенными списками в Python.
Хотите узнать гораздо больше? Записывайтесь на курс «Разработчик Python»!
Срезы
Часто приходится работать не с целым массивом, а только с некоторыми его элементами. Для этих целей в «Пайтоне» существует метод «Срез» (слайс). Он пришел на замену перебору элементов циклом for.

Метод открывает широкие возможности для получения копии массива в «Питоне». Все манипуляции осуществляются в таком виде . Здесь значение start обозначает индекс элемента, от которого начинается отсчет, значение stop — последний элемент, размер шага — количество пропускаемых элементов при каждой итерации. По умолчанию start равняется нулю, то есть отсчет начинается от нулевого элемента списка, stop равняется индексу последнего элемента в списке, шаг — равен единице, то есть перебирает каждый поочередно. Если передать в функцию без аргументов, список копируется полностью от начала до конца.
Например, у нас есть массив:
mas =
Чтобы его скопировать, используем mas. Функция вернет последовательность элементов . Если аргументом будет отрицательное значение, например -3, функция вернет элементы с индексами от третьего до последнего.
mas; //
После двойного двоеточия указывается шаг элементов, копируемых в массиве. Например, mas вернет массив . Если указано отрицательное значение, например, отсчет будет начинаться с конца, и получим .
Методом среза можно гибко работать с вложенными списками. Для двумерного массива в «Питоне» означает, что вернется каждый третий элемент всех массивов. Если указать — вернутся первые два.
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
1.2. Заполнение данными
- Создает массив NumPy.
- Преобразует последовательность в массив NumPy.
- Преобразует последовательность в массив NumPy, пропуская подклассы ndarray.
- Возвращает непрерывный массив в памяти с организацией порядка элементов в С-стиле.
- Интерпретирует входные данные как матрицу.
- Возвращает копию массива.
- Преобразует буфер в одномерный массив.
- Создает массив из текстового или двоичного файла.
- Создает массив с выполнением указанной функции над каждым элементом.
- Создает одномерный массив из итерируемого объекта.
- Создает одномерный массив из строки.
- Создает массив из данных в текстовом файле.
Обработка текста в NumPy на примерах
Когда дело доходит до текста, подход несколько меняется. Цифровое представление текста предполагает создание некого , то есть инвентаря всех уникальных слов, которые бы распознавались моделью, а также векторно (embedding step). Попробуем представить в цифровой форме цитату из стихотворения арабского поэта Антара ибн Шаддада, переведенную на английский язык:
“Have the bards who preceded me left any theme unsung?”
Перед переводом данного предложения в нужную цифровую форму модель должна будет проанализировать огромное количество текста. Здесь можно обработать небольшой набор данный, после чего использовать его для создания словаря из 71 290 слов.

Предложение может быть разбито на массив токенов, что будут словами или частями слов в зависимости от установленных общих правил:

Затем в данной таблице словаря вместо каждого слова мы ставим его :

Однако данные все еще не обладают достаточным количеством информации о модели как таковой. Поэтому перед передачей последовательности слов в модель токены/слова должны быть заменены их векторными представлениями. В данном случае используется 50-мерное векторное представление Word2vec.

Здесь ясно видно, что у массива NumPy есть несколько размерностей . На практике все выглядит несколько иначе, однако данное визуальное представление более понятно для разъяснения общих принципов работы.
Для лучшей производительности модели глубокого обучения обычно сохраняют первую размерность для пакета. Это происходит из-за того, что тренировка модели происходит быстрее, если несколько примеров проходят тренировку параллельно. Здесь особенно полезным будет . Например, такая модель, как BERT, будет ожидать ввода в форме: .
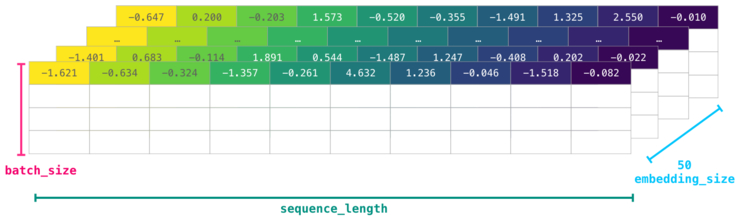
Теперь мы получили числовой том, с которым модель может работать и делать полезные вещи. Некоторые строки остались пустыми, однако они могут быть заполнены другими примерами, на которых модель может тренироваться или делать прогнозы.
(На заметку: Поэма, строчку из которой мы использовали в примере, увековечила своего автора в веках. Будучи незаконнорожденным сыном главы племени от рабыни, Антара ибн Шаддан мастерски владел языком поэзии. Вокруг исторической фигуры поэта сложились мифы и легенды, а его стихи стали частью классической арабской литературы).
Массив нарезки
Все идет нормально; Создание и индексация массивов выглядит знакомо.
Теперь мы подошли к нарезке массивов, и это одна из функций, которая создает проблемы для начинающих массивов Python и NumPy.
Структуры, такие как списки и массивы NumPy, могут быть нарезаны. Это означает, что подпоследовательность структуры может быть проиндексирована и извлечена.
Это наиболее полезно при машинном обучении при указании входных и выходных переменных или разделении обучающих строк из строк тестирования.
Нарезка задается с помощью оператора двоеточия ‘:’ с ‘от’ а также ‘в‘Индекс до и после столбца соответственно. Срез начинается от индекса «от» и заканчивается на один элемент перед индексом «до».
Давайте рассмотрим несколько примеров.
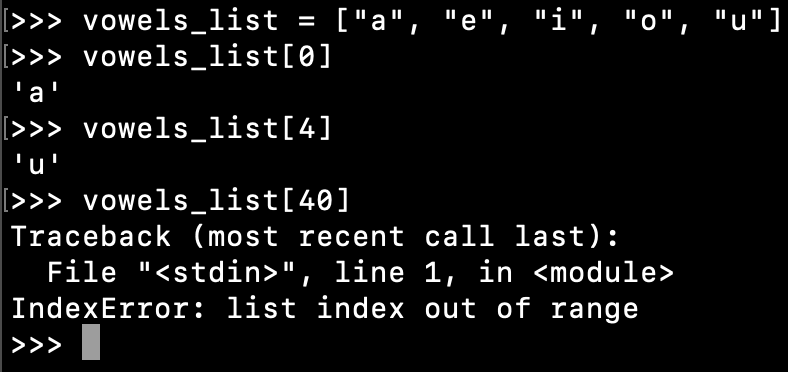
Одномерная нарезка
Вы можете получить доступ ко всем данным в измерении массива, указав срез «:» без индексов.
При выполнении примера печатаются все элементы в массиве.
Первый элемент массива можно разрезать, указав фрагмент, который начинается с индекса 0 и заканчивается индексом 1 (один элемент перед индексом «до»)
Выполнение примера возвращает подмассив с первым элементом.
Мы также можем использовать отрицательные индексы в срезах. Например, мы можем нарезать последние два элемента в списке, начав срез с -2 (второй последний элемент) и не указав индекс «до»; это берет ломтик до конца измерения.
Выполнение примера возвращает подмассив только с двумя последними элементами.
Двумерная нарезка
Давайте рассмотрим два примера двумерного среза, которые вы, скорее всего, будете использовать в машинном обучении.
Разделение функций ввода и вывода
Распространено загруженные данные на входные переменные (X) и выходную переменную (y).
Мы можем сделать это, разрезая все строки и все столбцы до, но перед последним столбцом, затем отдельно индексируя последний столбец.
Для входных объектов мы можем выбрать все строки и все столбцы, кроме последнего, указав ‘:’ в индексе строк и: -1 в индексе столбцов.
Для выходного столбца мы можем снова выбрать все строки, используя ‘:’, и индексировать только последний столбец, указав индекс -1.
Собрав все это вместе, мы можем разделить 3-колоночный 2D-набор данных на входные и выходные данные следующим образом:
При выполнении примера печатаются разделенные элементы X и y
Обратите внимание, что X — это двумерный массив, а y — это одномерный массив
Сплит поезд и тестовые ряды
Обычно загруженный набор данных разбивают на отдельные наборы поездов и тестов.
Это разделение строк, где некоторая часть будет использоваться для обучения модели, а оставшаяся часть будет использоваться для оценки мастерства обученной модели.
Для этого потребуется разрезать все столбцы, указав «:» во втором индексе измерения. Набор обучающих данных будет содержать все строки от начала до точки разделения.
Тестовым набором данных будут все строки, начиная с точки разделения до конца измерения.
Собрав все это вместе, мы можем разделить набор данных в надуманной точке разделения 2.
При выполнении примера выбираются первые две строки для обучения и последняя строка для набора тестов.
Присваивание не копирует массивы в Python
Итак, простое присваивание никаких копий массива не выполняет, и это первое, что стоит уяснить. Может показаться, что это всего лишь прихоть создателей Python и NumPy, но всё не так просто. Если бы ситуация обстояла иначе, мы бы работали с памятью напрямую, а отсутствие автоматического копирования во время присваивания — совсем небольшая плата за лёгкость и простоту языка программирования Python.
Давайте приведём ещё парочку примеров на эту тему:

Обратите внимание, что массивы a и b в действительности являются одним и тем же массивом с такими же данными и типом данных

Таким образом, у нас есть массив b и массив a, но нельзя забывать о том, что это, по сути, один и тот же массив.
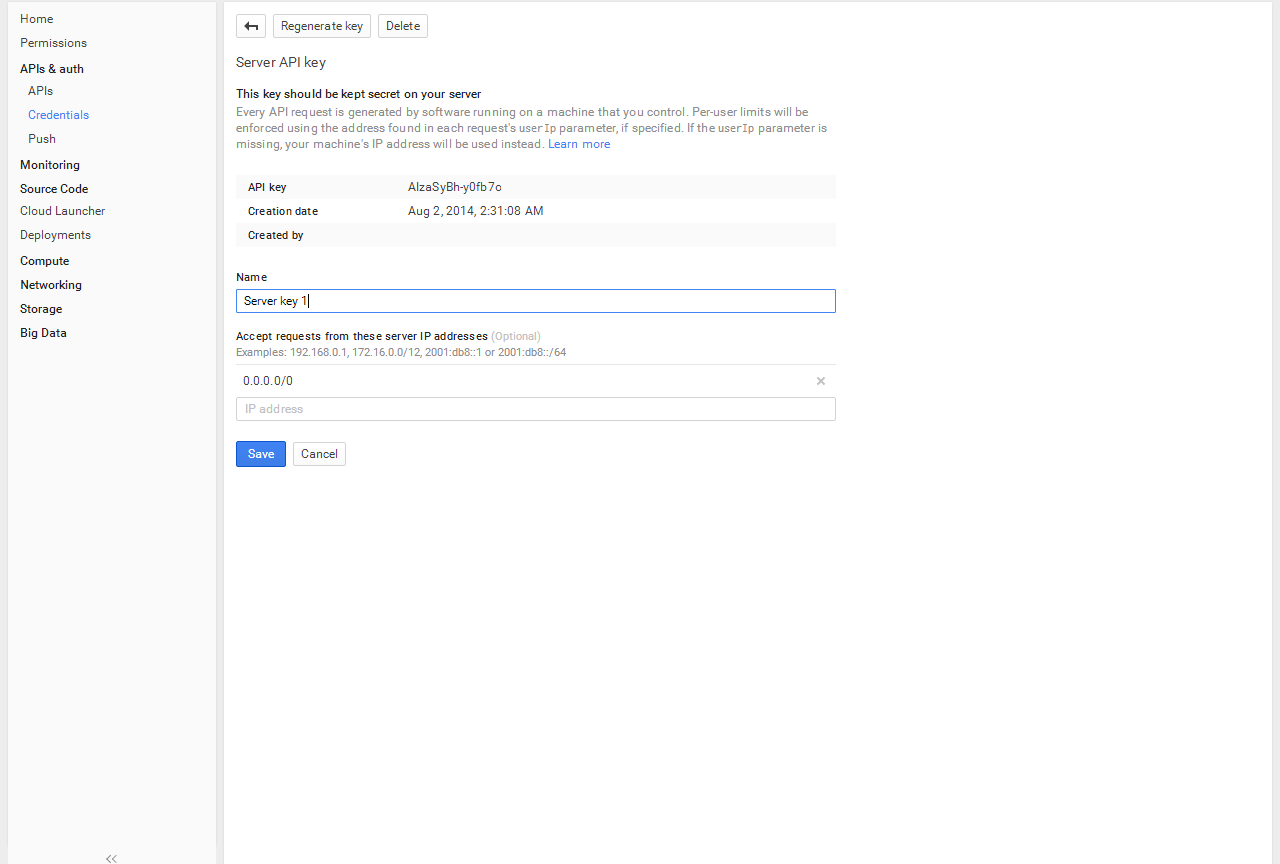
Ways to print NumPy Array in Python
As mentioned earlier, we can also implement arrays in Python using the NumPy module. The module comes with a pre-defined array class that can hold values of same type.
These NumPy arrays can also be multi-dimensional. So, let us see how can we print both 1D as well as 2D NumPy arrays in Python.
Using print() method
Similar to the case of arrays implemented using lists, we can directly pass NumPy array name to the method to print the arrays.
import numpy as np
arr_2d = np.array(,,])
arr = np.array()
print("Numpy array is: ", arr) #printing the 1d numpy array
print("Numpy 2D-array is: ", arr_2d) #printing the 2d numpy array
Output:
Numpy array is: Numpy 2D-array is: ]
Here, and are one 1D and one 2D NumPy arrays respectively. We pass their names to the method and print both of them. Note: this time also the arrays are printed in the form of NumPy arrays with brackets.
Using for loops
Again, we can also traverse through NumPy arrays in Python using loop structures. Doing so we can access each element of the array and print the same. This is another way to print an array in Python.
Look at the example below carefully.
import numpy as np
arr = np.array()
arr_2d = np.array(,,,])
#printing the numpy array
print("The Numpy Array is : ")
for i in arr:
print(i, end = ' ')
#printing the numpy 2D-Array
print("\nThe Numpy 2D-Array is:")
for i in arr_2d:
for j in i:
print(j, end=" ")
print()
Output:
The Numpy Array is : 11 22 33 44 The Numpy 2D-Array is: 90 20 76 45 44 87 73 81
Here also we print the NumPy array elements in our desired way(without brackets) by accessing the elements of the 1D and 2D array individually.
Печать массивов
Если массив слишком большой, чтобы его печатать, NumPy автоматически скрывает центральную часть массива и выводит только его уголки.
>>> print(np.arange(, 3000, 1))
Если вам действительно нужно увидеть весь массив, используйте функцию numpy.set_printoptions:
np.set_printoptions(threshold=np.nan)
И вообще, с помощью этой функции можно настроить печать массивов «под себя». Функция numpy.set_printoptions принимает несколько аргументов:
precision : количество отображаемых цифр после запятой (по умолчанию 8).
threshold : количество элементов в массиве, вызывающее обрезание элементов (по умолчанию 1000).
edgeitems : количество элементов в начале и в конце каждой размерности массива (по умолчанию 3).
linewidth : количество символов в строке, после которых осуществляется перенос (по умолчанию 75).
suppress : если True, не печатает маленькие значения в scientific notation (по умолчанию False).
nanstr : строковое представление NaN (по умолчанию ‘nan’).
infstr : строковое представление inf (по умолчанию ‘inf’).
formatter : позволяет более тонко управлять печатью массивов. Здесь я его рассматривать не буду, можете почитать здесь (на английском).
И вообще, пользуйтесь официальной документацией по numpy, а в этом пособии я постараюсь описать всё необходимое. В следующей части мы рассмотрим базовые операции над массивами.
Подписывайтесь, чтобы не пропустить 🙂
Двумерные массивы
Выше везде элементами массива были числа. Но на самом деле элементами массива может быть что угодно, в том числе другие массивы. Пример:
a = b = c = z =
Что здесь происходит? Создаются три обычных массива , и , а потом создается массив , элементами которого являются как раз массивы , и .
Что теперь получается? Например, — это элемент №1 массива , т.е. . Но — это тоже массив, поэтому я могу написать — это то же самое, что , т.е. (не забывайте, что нумерация элементов массива идет с нуля). Аналогично, и т.д.
То же самое можно было записать проще:
z = , , ]
Получилось то, что называется двумерным массивом. Его можно себе еще представить в виде любой из этих двух табличек:
Первую табличку надо читать так: если у вас написано , то надо взять строку № и столбец №. Например, — это элемент на 1 строке и 2 столбце, т.е. -3. Вторую табличку надо читать так: если у вас написано , то надо взять столбец № и строку №. Например, — это элемент на 2 столбце и 1 строке, т.е. -3. Т.е. в первой табличке строка — это первый индекс массива, а столбец — второй индекс, а во второй табличке наоборот. (Обычно принято как раз обозначать первый индекс и — второй.)
Когда вы думаете про таблички, важно то, что питон на самом деле не знает ничего про строки и столбцы. Для питона есть только первый индекс и второй индекс, а уж строка это или столбец — вы решаете сами, питону все равно
Т.е. и — это разные вещи, и питон их понимает по-разному, а будет 1 номером строки или столбца — это ваше дело, питон ничего не знает про строки и столбцы. Вы можете как хотите это решить, т.е. можете пользоваться первой картинкой, а можете и второй — но главное не запутайтесь и в каждой конкретной программе делайте всегда всё согласованно. А можете и вообще не думать про строки и столбцы, а просто думайте про первый и второй индекс.
Обратите, кстати, внимание на то, что в нашем примере (массив, являющийся вторым элементом массива ) короче остальных массивов (и поэтому на картинках отсутствует элемент в правом нижнем углу). Это общее правило питона: питон не требует, чтобы внутренние массивы были одинаковой длины
Вы вполне можете внутренние массивы делать разной длины, например:
x = , , , [], ]
здесь нулевой массив имеет длину 4, первый длину 2, второй длину 3, третий длину 0 (т.е. не содержит ни одного элемента), а четвертый длину 1. Такое бывает надо, но не так часто, в простых задачах у вас будут все подмассивы одной длины.
(На самом деле даже элементы одного массива не обязаны быть одного типа. Можно даже делать так: , здесь нулевой элемент массива — сам является массивом, а еще два элемента — просто числа. Но это совсем редко бывает надо.)
1.1. Автозаполнение массивов
- Возвращает новый массив заданной формы и типа без инициированных записей.
- Возвращает новый массив с формой и типом данных указанного массива без инициированных записей.
- Возвращает новый массив в котором диагональные элементы равны единице, а все остальные равны нулю.
- Возвращает новый квадратный массив с единицами по главной диагонали.
- Возвращает новый массив заданной формы и типа, заполненный единицами.
- Возвращает новый массив с формой и типом данных указанного массива, заполненный единицами.
- Возвращает новый массив заданной формы и типа, заполненный нулями.
- Возвращает новый массив с формой и типом данных указанного массива, заполненный нулями.
- Возвращает новый массив заданной формы и типа все элементы которого равны указанному значению.
- Возвращает новый массив с формой и типом данных указанного массива, все элементы которого равны указанному значению.
Array Methods
Python has a set of built-in methods that you can use on lists/arrays.
| Method | Description |
|---|---|
| append() | Adds an element at the end of the list |
| clear() | Removes all the elements from the list |
| copy() | Returns a copy of the list |
| count() | Returns the number of elements with the specified value |
| extend() | Add the elements of a list (or any iterable), to the end of the current list |
| index() | Returns the index of the first element with the specified value |
| insert() | Adds an element at the specified position |
| pop() | Removes the element at the specified position |
| remove() | Removes the first item with the specified value |
| reverse() | Reverses the order of the list |
| sort() | Sorts the list |
Note: Python does not have built-in support for Arrays,
but Python Lists can be used instead.
Related Pages
Python Array Tutorial
Array
What is an Array
Access Arrays
Array Length
Looping Array Elements
Add Array Element
Remove Array Element
Объединение массивов
NumPy предоставляет множество функций для создания новых массивов из существующих массивов.
Давайте рассмотрим две наиболее популярные функции, которые вам могут понадобиться или с которыми вы столкнетесь.
Вертикальный стек
Имея два или более существующих массива, вы можете сложить их вертикально, используя функцию vstack ().
Например, учитывая два одномерных массива, вы можете создать новый двумерный массив с двумя строками, сложив их вертикально.
Это продемонстрировано в примере ниже.
Выполнение примера сначала печатает два отдельно определенных одномерных массива. Массивы вертикально сложены, что приводит к новому массиву 2 × 3, содержимое и форма которого печатаются.
Горизонтальный стек
Имея два или более существующих массива, вы можете разместить их горизонтально, используя функцию hstack ().
Например, учитывая два одномерных массива, вы можете создать новый одномерный массив или одну строку со сцепленными столбцами первого и второго массивов.
Это продемонстрировано в примере ниже.
Выполнение примера сначала печатает два отдельно определенных одномерных массива. Затем массивы располагаются горизонтально, что приводит к созданию нового одномерного массива с 6 элементами, содержимое и форма которого печатаются
Алгоритм MergeSort
Алгоритм использует восходящий подход Divide and Conquer, сначала разделяя исходный массив на подмассивы, а затем объединяя индивидуально отсортированные подмассивы, чтобы получить окончательный отсортированный массив.
В приведенном ниже фрагменте кода метод выполняет фактическое разделение на подмассивы, а метод perform_merge() объединяет два ранее отсортированных массива в новый отсортированный.
import array
def mergesort(a, arr_type):
def perform_merge(a, arr_type, start, mid, end):
# Merges two previously sorted arrays
# a and a
tmp = array.array(arr_type, )
def compare(tmp, i, j):
if tmp <= tmp:
i += 1
return tmp
else:
j += 1
return tmp
i = start
j = mid + 1
curr = start
while i<=mid or j<=end:
if i<=mid and j<=end:
if tmp <= tmp:
a = tmp
i += 1
else:
a = tmp
j += 1
elif i==mid+1 and j<=end:
a = tmp
j += 1
elif j == end+1 and i<=mid:
a = tmp
i += 1
elif i > mid and j > end:
break
curr += 1
def mergesort_helper(a, arr_type, start, end):
# Divides the array into two parts
# recursively and merges the subarrays
# in a bottom up fashion, sorting them
# via Divide and Conquer
if start < end:
mergesort_helper(a, arr_type, start, (end + start)//2)
mergesort_helper(a, arr_type, (end + start)//2 + 1, end)
perform_merge(a, arr_type, start, (start + end)//2, end)
# Sorts the array using mergesort_helper
mergesort_helper(a, arr_type, 0, len(a)-1)
Прецедент:
a = array.array('i', )
print('Before MergeSort ->', a)
mergesort(a, 'i')
print('After MergeSort ->', a)
Вывод:
Before MergeSort -> array('i', )
After MergeSort -> array('i', )
Добавление нового массива
Перед процессом создание нового массива, необходимо выполнить некоторые действия. Для начала, стоит произвести импорт библиотеки, которая отвечает за работу с подобными объектами. Чтобы выполнить это действие, нужно добавить в файл программы следующую строку: from array import *.
Исходя из того, что массивы предназначены для работы с одним типом данных, то и, соответственно, размер ячеек этих данных также будет одинаков.
Для создания нового массива данных используется такая функция, как «array». Ниже представлен пример того, как заполняется массив с помощью перечисленных действий:
from array import *data = array(‘i’, )
Функция «array» способна принимать два аргумента, одним из них является вид массива, который создается, другим – исходный перечень значений массива. В этом примере i является числом, размер которого составляет 2 б. Стоит отметить, что можно использовать не только этот примитив, но и другие – c, f и т. д.
Действия для добавления нового элемента
Для того, чтобы в массиве появился новый элемент, необходимо воспользоваться таким методом, как «insert». Это делается с помощью ввода в созданный ранее объект двух значений, являющихся аргументами. Цифра 3 представляет собой не что иное, как само значение, а 4 указывает на место в массиве, где будет располагаться элемент, т. е. его индекс.
Действия для удаления нового элемента
В рассматриваемом языке программирования избавиться от лишних элементов можно посредством такого метода, как «pop». Данный метод имеет аргумент (3) и может быть вызван через объект, который создавался ранее, т. е. способом, аналогичным добавлению нового элемента.
data.pop(3)
После того, как произошло удаление лишнего, в массиве происходит сдвиг его содержимого таким образом, чтобы число свободных ячеек памяти совпало с текущим количеством элементов.
Проверка
Зачастую возникает необходимость проверки данных при работе с любой программой, которая проводится путем вывода на экран. Эта операция может быть совершена с помощью такой команды, как «print». Аргументом для этой функции является элемент массива, созданного ранее.
В нижеприведенном примере видно, что обработка массива происходит с помощью цикла «for», в котором любой элемент массива идентификатором i для передачи в «print».
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Ввод-вывод массива
Как вам считывать массив? Во-первых, если все элементы массива задаются в одной строке входного файла. Тогда есть два способа. Первый — длинный, но довольно понятный:
a = input().split() # считали строку и разбили ее по пробелам
# получился уже массив, но питон пока не понимает, что в массиве числа
for i in range(len(a)):
a = int(a) # прошли по всем элементам массива и превратили их в числа
Второй — покороче, но попахивает магией:
a = list(map(int, input().split()))
Может показаться страшно, но на самом деле вы уже встречали в конструкции
x, y = map(int, input().split())
когда вам надо было считать два числа из одной строки. Это считывает строку (), разбивает по пробелам (), и превращает каждую строку в число (). Для чтения массива все то же самое, только вы еще заворачиваете все это в , чтобы явно сказать питону, что это массив.
Какой из этих двух способов использовать для чтения данных из одной строки — выбирать вам.
Обратите внимание, что в обоих способах вам не надо знать заранее, сколько элементов будет в массиве — получится столько, сколько чисел в строке. В задачах часто бывает что задается сначала количество элементов, а потом (обычно на следующей строке) сами элементы
Это удобно в паскале, c++ и т.п., где нет способа легко считать числа до конца строки; в питоне вам это не надо, вы легко считываете сразу все элементы массива до конца строки, поэтому заданное число элементов вы считываете, но дальше не используете:
n = int(input()) # больше n не используем a = list(map(int, input().split()))
Еще бывает, что числа для массива задаются по одному в строке. Тогда вам проще всего заранее знать, сколько будет вводиться чисел. Обычно как раз так данные и даются: сначала количество элементов, потом сами элементы. Тогда все вводится легко:
n = int(input())
a = [] # пустой массив, т.е. массив длины 0
for i in range(n):
a.append(int(input())) # считали число и сразу добавили в конец массива
Более сложные варианты — последовательность элементов по одному в строке, заканчивающаяся нулем, или задано количество элементов и сами элементы в той же строке — придумайте сами, как сделать (можете подумать сейчас, можете потом, когда попадется в задаче). Вы уже знаете все, что для этого надо.
Как выводить массив? Если надо по одному числу в строку, то просто:
for i in range(len(a)):
print(a)
Если же надо все числа в одну строку, то есть два способа. Во-первых, можно команде передать специальный параметр , который обозначает «заканчивать вывод пробелом (а не переводом строки)»:
for i in range(len(a)):
print(a, end=" ")
Есть другой, более простой способ:
print(*a)
Эта магия обозначает вот что: возьми все элементы массива и передай их отдельными аргументами в одну команду . Т.е. получается .