Pyexcel-xlsx 0.6.0
Содержание:
- Использование Python и Excel для обработки и анализа данных. Часть 2: библиотеки для работы с данными
- Как работает память в Python
- Данные как ваша отправная точка
- Получение значений нескольких файлов
- Должен ли финансист использовать EXCEL?
- Openpyxl read multiple cells
- Анализ датасета
- Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды +8
- Python Excel Automation
- Настройка строк и столбцов
- Время учиться: дайджест бесплатных образовательных материалов от Mail.Ru Group
- VBA и Python
- В пользу VBA
- Hidden feature: partial read
- О курсе
- 1. Определения и классификация
- Openpyxl dimensions
- В пользу Python (и других внешних языков программирования)
Использование Python и Excel для обработки и анализа данных. Часть 2: библиотеки для работы с данными
Первая часть статьи была опубликована .Как читать и редактировать Excel файлы при помощи openpyxl
ПЕРЕВОД
Оригинал статьи — www.datacamp.com/community/tutorials/python-excel-tutorial
Автор — Karlijn Willems
Эта библиотека пригодится, если вы хотите читать и редактировать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl using pip. Общие рекомендации по установке этой библиотеки — сделать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, содержащую все необходимые файлы, для использования библиотек, которые потребуются для Python.
Перейдите в директорию, в которой находится ваш проект, и повторно активируйте виртуальную среду venv. Затем перейдите к установке openpyxl с помощью pip, чтобы убедиться, что вы можете читать и записывать с ним файлы:
Как работает память в Python
Ни одна компьютерная программа не может работать без данных. А данные, чтобы программа имела к ним доступ, должны располагаться в оперативной памяти вашего компьютера. Но что такое оперативная память на самом деле? Когда произносишь это словосочетание, многие сразу представляют «железную» плашку, вставленную в материнскую плату, на которой написано что-то типа 16Gb DDR4 2666MHz. И они, разумеется, правы — это действительно физический блок оперативной памяти, в котором, в итоге, все данные и оказываются. Но прежде, чем стать доступной внутри вашей программы, на память (как и на всё остальное аппаратное обеспечение) накладывается куча абстракций.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, \, , {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Получение значений нескольких файлов
Давайте посмотрим на другой пример.
Скажем, нам нужно было получить итого только по Москве из каждого отчета о продажах и собрать их в список. Мы знаем, что сумма сохраняется в ячейке в каждой книге.
Для этого примера мы будем использовать другую библиотеку — . Вы можете установить её с помощью pip или conda, используя код ниже:
pip install openpyxl###conda install openpyxl
А теперь посмотрим код и что он выполняет:
# импортируем библиотеку и создаем переменныеimport openpyxlfiles = [] #укажите здесь путь к файламvalues = []# пишем циклfor file in files: wb = openpyxl.load_workbook(file) sheet = wb value = sheet.value values.append(value)
Давайте разберем это шаг за шагом, сначала мы:
- Создаем список (), который содержит ссылки на все наши файлы. В Windows мы можем нажать и использовать Копировать как путь (или, Copy as Path), чтобы получить путь к файлу.
- И создаем пустой список для хранения наших значений ()
- Пишем цикл, который будет выполнять нужные нам манипуляции с каждым файлом:
— с помощью метода загружаем файл
— используем и для ссылки на имя листа, так и на ссылки на ячейки таблицы (на нужном нам листе в рабочей книге)
Если у вас Excel на русском языке, то вместо указывайте .
— и используем атрибут , чтобы извлечь значение ячейки и добавить его в список методом
Должен ли финансист использовать EXCEL?
Так как EXCEL уже вошел в культуру финансовой среды, то знания этого инструмента, на мой взгляд, необходимы. Есть ситуации, когда применение EXCEL является оптимальным даже для тех, кто обладает опытом в Python или других языках программирования, ориентированных на анализ данных (например, R). К таким ситуациям относится:
- Анализ небольших объемов финансовых данных (например, когда все данные умещаются на одном экране)
- Ввод небольшого количества данных «руками»
- Использование EXCEL как продвинутой версии калькулятора
- Необходимо поделиться результатом с теми, кто не владеет тем же Python
Можно придумать еще много ситуаций, когда использование EXCEL вполне оправдано. Но в целом они все сводятся к одному сценарию. EXCEL хорош тогда, когда есть не слишком большой объем анализируемой информации, и когда не требуется применять к данным сложные алгоритмы.
Большим преимуществом EXCEL является то, что его можно освоить буквально за несколько часов и пользоваться им уже на приемлемом уровне.
Если вы еще плохо знакомы с EXCEL или совсем его не знаете, можно воспользоваться нашим вводным курсом .
Openpyxl read multiple cells
We have the following data sheet:
Figure: Items
We read the data using a range operator.
read_cells2.py
#!/usr/bin/env python
import openpyxl
book = openpyxl.load_workbook('items.xlsx')
sheet = book.active
cells = sheet
for c1, c2 in cells:
print("{0:8} {1:8}".format(c1.value, c2.value))
In the example, we read data from two columns using a range operation.
cells = sheet
In this line, we read data from cells A1 — B6.
for c1, c2 in cells:
print("{0:8} {1:8}".format(c1.value, c2.value))
The function is used for neat output of data
on the console.
$ ./read_cells2.py Items Quantity coins 23 chairs 3 pencils 5 bottles 8 books 30
This is the output of the program.
Анализ датасета
Теперь пришло время взглянуть на данные более детально. На этом этапе мы погрузимся в анализ данные несколькими способами:
- Размерность датасета
- Просмотр среза данных
- Статистическая сводка атрибутов
- Разбивка данных по атрибуту класса.
Не волнуйтесь, каждый взгляд на данные является одной командой. Это полезные команды, которые можно использовать снова и снова в будущих проектах.
3.1 Размерность датасета
Мы можем получить быстрое представление о том, сколько экземпляров (строк) и сколько атрибутов (столбцов) содержится в датасете с помощью метода shape.
Вы должны увидеть 150 экземпляров и 5 атрибутов:
3.2 Просмотр среза данных
Исследовании данных, стоит сразу в них заглянуть, для этого есть метод head()
Это должно вывести первые 20 строк датасета.
3.3 Статистическая сводка
Давайте взглянем теперь на статистическое резюме каждого атрибута. Статистическая сводка включает в себя количество экземпляров, их среднее, мин и макс значения, а также некоторые процентили.
Мы видим, что все численные значения имеют одинаковую шкалу (сантиметры) и аналогичные диапазоны от 0 до 8 сантиметров.
3.4 Распределение классов
Давайте теперь рассмотрим количество экземпляров (строк), которые принадлежат к каждому классу. Мы можем рассматривать это как абсолютный счет.
Мы видим, что каждый класс имеет одинаковое количество экземпляров (50 или 33% от датасета).
4. Визуализация данных
Теперь когда у нас есть базовое представление о данных, давайте расширим его с помощью визуализаций.
Мы рассмотрим два типа графиков:
- Одномерные (Univariate) графики, чтобы лучше понять каждый атрибут.
- Многомерные (Multivariate) графики, чтобы лучше понять взаимосвязь между атрибутами.
4.1 Одномерные графики
Начнем с некоторых одномерных графиков, то есть графики каждой отдельной переменной. Учитывая, что входные переменные являются числовыми, мы можем создавать диаграмма размаха (или «ящик с усами», по-английски «box and whiskers diagram») каждого из них.
Это дает нам более четкое представление о распределении атрибутов на входе.
Диаграмма размаха атрибутов входных данных
Мы также можем создать гистограмму входных данных каждой переменной, чтобы получить представление о распределении.
Из графиков видно, что две из входных переменных имеют около гауссово (нормальное) распределение. Это полезно отметить, поскольку мы можем использовать алгоритмы, которые могут использовать это предположение.
Гистограммы входных данных атрибутов датасета
4.2 Многомерные графики
Теперь мы можем посмотреть на взаимодействия между переменными.
Во-первых, давайте посмотрим на диаграммы рассеяния всех пар атрибутов. Это может быть полезно для выявления структурированных взаимосвязей между входными переменными.
Обратите внимание на диагональ некоторых пар атрибутов. Это говорит о высокой корреляции и предсказуемой взаимосвязи
Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды +8
- 27.06.17 10:51
•
Dmitry21
•
#331746
•
Хабрахабр
•
•
7600
Python, Разработка веб-сайтов, Блог компании Отус

Если Вы только начинаете свой путь знакомства с возможностями Python, ваши познания еще имеют начальный уровень — этот материал для Вас. В статье мы опишем, как можно извлекать информацию из данных, представленных в Excel файлах, работать с ними используя базовый функционал библиотек. В первой части статьи мы расскажем про установку необходимых библиотек и настройку среды. Во второй части — предоставим обзор библиотек, которые могут быть использованы для загрузки и записи таблиц в файлы с помощью Python и расскажем как работать с такими библиотеками как pandas, openpyxl, xlrd, xlutils, pyexcel.
В какой-то момент вы неизбежно столкнетесь с необходимостью работы с данными Excel, и нет гарантии, что работа с таким форматами хранения данных доставит вам удовольствие. Поэтому разработчики Python реализовали удобный способ читать, редактировать и производить иные манипуляции не только с файлами Excel, но и с файлами других типов. Отправная точка — наличие данных
Когда вы начинаете проект по анализу данных, вы часто сталкиваетесь со статистикой собранной, возможно, при помощи счетчиков, возможно, при помощи выгрузок данных из систем типа Kaggle, Quandl и т. д. Но большая часть данных все-таки находится в Google или репозиториях, которыми поделились другие пользователи. Эти данные могут быть в формате Excel или в файле с .csv расширением.
Данные есть, данных много. Анализируй — не хочу. С чего начать? Первый шаг в анализе данных — их верификация. Иными словами — необходимо убедиться в качестве входящих данных.
В случае, если данные хранятся в таблице, необходимо не только подтвердить качество данных (нужно быть уверенным, что данные таблицы ответят на поставленный для исследования вопрос), но и оценить, можно ли доверять этим данным.Проверка качества таблицы
Чтобы проверить качество таблицы, обычно используют простой чек-лист. Отвечают ли данные в таблице следующим условиям:
- данные являются статистикой;
- различные типы данных: время, вычисления, результат;
- данные полные и консистентные: структура данных в таблице — систематическая, а присутствующие формулы — работающие.
Бест-практикс табличных данных
- первая строка таблицы зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- избегайте имен, значений или полей с пробелами. В противном случае, каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов в строке в наборе данных. Лучше использовать подчеркивания, регистр (первая буква каждого раздела текста — заглавная) или соединительные слова;
- отдавайте предпочтение коротким названиям;
- старайтесь избегать использования названий, которые содержат символы ?, $,%, ^, &, *, (,),-,#, ?,,,<,>, /, |, \, ,{, и };
- удаляйте любые комментарии, которые вы сделали в файле, чтобы избежать дополнительных столбцов или полей со значением NA;
- убедитесь, что любые недостающие значения в наборе данных отображаются как NA.
Подготовка рабочего пространства
Установка пакетов для чтения и записи Excel файлов
здесь Установка AnacondaPython, R и Scala сюдасюдаЗагрузка файлов Excel как Pandas DataFrame
документацииКак записывать Pandas DataFrame в Excel файл
здесьИспользование виртуальной среды
Python Excel Automation
If you want to Read, Write and Manipulate(Copy, cut, paste, delete or search for an item etc) Excel files in Python with simple and practical examples I will suggest you to see this simple and to the point
Excel Openpyxl Course with examples about how to deal with MS Excel files in Python. This video course teaches efficiently how to manipulate excel files and automate tasks.
Everything you do in Microsoft Excel, can be automated with Python. So why not use the power of Python and make your life easy. You can make intelligent and thinking Excel sheets, bringing the power of logic and thinking of Python to Excel which is usually static, hence bringing flexibility in Excel and a number of opportunities.
Python excel relationship is flourishing with every day. First I want to ask a simple question:
What
if you get it automated: the task of reading data from excel file and
writing it into a text file, another excel file, an SPSS file, for data analysis or doing
data
analysis with Python Pandas on that data.
Most
of people who work in office usually have to deal with a spreadsheet
software. Ofcourse a spreadsheet is helpful for many purposes. Some of
the common tasks are writing sequential data in spreadsheet, like
writing names of employees, their salaries, and other details.
Sometimes we have to copy a particular data from one file to another
file. Your job might required going through hundreds of excel files,
for searching and sorting data, selecting a particular section of data,
cleaning it, and then presenting it in a different form. Manually done,
it may take days or weeks, but if you know how to deal with excel files
in python, you can write a simple code and all of this tedious boring
stuff will be done in seconds, in a most efficient manner, while you
taking a sip of coffee. Lovely idea, isn’t it? Yes ofcourse. So why not
read this tutorial and learn some valuable skills which help you in the
short run as well as in the long run, making your life less boring,
less hectic and more exiting. More often you dont have to write python
scripts or python code from scratch, it is always in abundance and
freely available, you just modify it according to your needs and thats
it! To take the above mentioned benefits and much much more, stay tuned
to this site and Master the skill of accessing excel with
python.
Python excel relationship is very beneficial for data analysis,
for people who do data mining and those who are involved in machine
learning. Most of the data exists in the form of spreadsheets. Now to
go through thousands or millions of spreadsheets is not an easy task.
And not only going through those files, finding useful data, just by
watching your comupter monitor makes the task troublesome. Data
scientists can use python, and bingo! work done in almost no time, with
much much better efficiency and millions of cells of data from
spreadsheet is read without missing even one cell. Humans can not do
this task to this level of efficiency, or if they would do it will take
so much time that the utility of such data might be outdated. Hence
many Data analysts and data scientists are using python to do their
task and enjoy relaxed time at office and at home with their family. Do
you want to do the same????
If you are ready to make your life easier, read about the
available python packages for excel given below and start with Openpyxl Tutorial,
the most used package with very easy interface and suitable for
beginners dealing with all types of excel spredsheets. This is starting place for python excel world
Настройка строк и столбцов
С помощью модуля OpenPyXL можно задавать высоту строк и ширину столбцов таблицы, закреплять их на месте (чтобы они всегда были видны на экране), полностью скрывать из виду, объединять ячейки.
Настройка высоты строк и ширины столбцов
Объекты имеют атрибуты и , которые управляют высотой строк и шириной столбцов.
sheet'A1' = 'Высокая строка' sheet'B2' = 'Широкий столбец' sheet.row_dimensions1.height = 70 sheet.column_dimensions'B'.width = 30
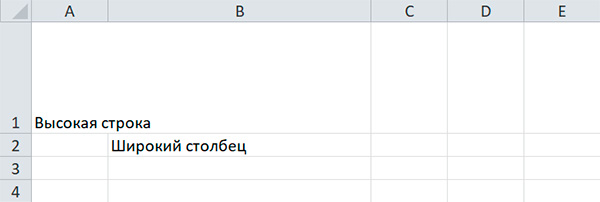
Атрибуты s и представляют собой значения, подобные словарю. Атрибут содержит объекты , а атрибут содержит объекты . Доступ к объектам в осуществляется с использованием номера строки, а доступ к объектам в — с использованием буквы столбца.
Для указания высоты строки разрешено использовать целые или вещественные числа в диапазоне от 0 до 409. Для указания ширины столбца можно использовать целые или вещественные числа в диапазоне от 0 до 255. Столбцы с нулевой шириной и строки с нулевой высотой невидимы для пользователя.
Объединение ячеек
Ячейки, занимающие прямоугольную область, могут быть объединены в одну ячейку с помощью метода рабочего листа:
sheet.merge_cells('A1:D3')
sheet'A1' = 'Объединены двенадцать ячеек'
sheet.merge_cells('C5:E5')
sheet'C5' = 'Объединены три ячейки'

Чтобы отменить слияние ячеек, надо вызвать метод :
sheet.unmerge_cells('A1:D3')
sheet.unmerge_cells('C5:E5')
Закрепление областей
Если размер таблицы настолько велик, что ее нельзя увидеть целиком, можно заблокировать несколько верхних строк или крайних слева столбцов в их позициях на экране. В этом случае пользователь всегда будет видеть заблокированные заголовки столбцов или строк, даже если он прокручивает таблицу на экране.
У объекта имеется атрибут , значением которого может служить объект или строка с координатами ячеек. Все строки и столбцы, расположенные выше и левее, будут заблокированы.
| Значение атрибута freeze_panes | Заблокированные строки и столбцы |
|---|---|
| Строка 1 | |
| Столбец A | |
| Столбцы A и B | |
| Строка 1 и столбцы A и B | |
| Закрепленные области отсутствуют |
Время учиться: дайджест бесплатных образовательных материалов от Mail.Ru Group
Кадр из к/ф «Операция Ы и другие приключения Шурика»
Как говорят, «кризис — пора возможностей». И поэтому сейчас самое время начать вкладывать в саморазвитие, осваивать новую профессию или повышать свою квалификацию. Займитесь изучением языков программирования, обретением навыков разработки, тестирования и вообще всячески прокачивайте свой IT-скилл. Ведь чем больше вы знаете, тем прочнее будете стоять на ногах. А чтобы вам было легче сориентироваться и выбрать направление, мы сделали подборку наших бесплатных образовательных материалов, курсов и инициатив за 2015–2016 годы.
VBA и Python
VBA (Visual Basic for Applications), де-факто, самый популярный язык для автоматизации Microsoft Office. Доступен из коробки, помимо Excel, работает в PowerPoint, Outlook, Access, Project и других приложениях.
Если задать вопрос: «Какой язык программирования выбрать первым», то где-то в 90% всех случаев будет предложен Python. На практике здесь может быть и любой другой язык, но, исходя из популярности языка и своего опыта, буду сравнивать с ним.
В общем виде можно описать ситуацию через подобный график:

Детального сравнения не будет, рассмотрим основные killer-фичи, в ситуации, когда junior-программист/офисный сотрудник хочет автоматизировать что-либо, связанное с MS Office, и у него есть возможность выбора между языками.
Если в силу разных причин возможности выбора нет, то и сравнивать нечего.
В пользу VBA
- Отличная работа с объектной моделью Excel и других приложений MS Office. Написание кода на VBA для большинства внутренних операций тривиально. У Python, в сравнении с VBA, поддержка объектной модели Office очень слабая.
- Поддержка разных форматов MS Office. Самая большая проблема для внешних языков — это работа с разными форматами файлов MS Office. Например, xls, xlsx, xlsm файлы могут требовать разных библиотек, так как каждая хорошо работает только со своим форматом файла. Для VBA — это все “файл Excel”, работа с которыми в целом одинаково хороша.
- Работа с MS Exchange. Если необходимо обеспечить работу с корпоративной почтой/календарем на Exchange, то далеко не каждом языке есть нормальная библиотека для работы протоколом Exchange. В VBA это решается относительно просто через использование в макросе объектной модели MS Outlook.
- Легкая установка и дистрибуция. К уже установленному офису не надо ничего устанавливать. Чтобы коллега мог воспользоваться программой, достаточно передать ему файл с макросом. Легко сделать надстройку, которая позволит “установить” модель макроса в фон офиса.
- Интерактивность внутри приложений MS Office. Внутри офисных программ можно как просто поставить кнопки запуска макросов, так и (чуть сложнее) сделать целый отдельный UI. Сюда же относится написание своих формул в Excel и то, что макросы могут воздействовать на объекты внутри документов Office в реальном времени.
- Запись макросов. Удобный инструмент, который позволяет записать действия человека в готовый код, для последующего редактирования использования.
Hidden feature: partial read
When you are dealing with huge amount of data, e.g. 64GB, obviously you would not
like to fill up your memory with those data. What you may want to do is, record
data from Nth line, take M records and stop. And you only want to use your memory
for the M records, not for beginning part nor for the tail part.
Hence partial read feature is developed to read partial data into memory for
processing.
You can paginate by row, by column and by both, hence you dictate what portion of the
data to read back. But remember only row limit features help you save memory. Let’s
you use this feature to record data from Nth column, take M number of columns and skip
the rest. You are not going to reduce your memory footprint.
Why did not I see above benefit?
This feature depends heavily on the implementation details.
Hence, during the partial data is been returned, the memory consumption won’t
differ from reading the whole data back. Only after the partial
data is returned, the memory comsumption curve shall jump the cliff. So pagination
code here only limits the data returned to your program.
In addition, pyexcel’s csv readers can read partial data into memory too.
Let’s assume the following file is a huge csv file:
>>> import datetime >>> import pyexcel as pe >>> data = ... 1, 21, 31], ... 2, 22, 32], ... 3, 23, 33], ... 4, 24, 34], ... 5, 25, 35], ... 6, 26, 36 ... >>> pe.save_as(array=data, dest_file_name="your_file.csv")
And let’s pretend to read partial data:
>>> pe.get_sheet(file_name="your_file.csv", start_row=2, row_limit=3) your_file.csv +---+----+----+ | 3 | 23 | 33 | +---+----+----+ | 4 | 24 | 34 | +---+----+----+ | 5 | 25 | 35 | +---+----+----+
And you could as well do the same for columns:
>>> pe.get_sheet(file_name="your_file.csv", start_column=1, column_limit=2) your_file.csv +----+----+ | 21 | 31 | +----+----+ | 22 | 32 | +----+----+ | 23 | 33 | +----+----+ | 24 | 34 | +----+----+ | 25 | 35 | +----+----+ | 26 | 36 | +----+----+
Obvious, you could do both at the same time:
>>> pe.get_sheet(file_name="your_file.csv", ... start_row=2, row_limit=3, ... start_column=1, column_limit=2) your_file.csv +----+----+ | 23 | 33 | +----+----+ | 24 | 34 | +----+----+ | 25 | 35 | +----+----+
The pagination support is available across all pyexcel plugins.
Note
No column pagination support for query sets as data source.
О курсе
Мы не ставим себе задачу разработать еще один исчерпывающий вводный курс по машинному обучению или анализу данных (т.е. это не замена специализации Яндекса и МФТИ, дополнительному образованию ВШЭ и прочим фундаментальным онлайн- и оффлайн-программам и книжкам). Цель этой серии статей — быстро освежить имеющиеся у вас знания или помочь найти темы для дальнейшего изучения. Подход примерно как у авторов книги Deep Learning, которая начинается с обзора математики и основ машинного обучения — краткого, максимально ёмкого и с обилием ссылок на источники.
Если вы планируете пройти курс, то предупреждаем: при подборе тем и создании материалов мы ориентируемся на то, что наши слушатели знают математику на уровне 2 курса технического вуза и хотя бы немного умеют программировать на Python. Это не жёсткие критерии отбора, а всего лишь рекомендации — можно записаться на курс, не зная математики или Python, и параллельно навёрстывать:
- базовую математику (математический анализ, линейную алгебру, оптимизацию, теорвер и статистику) можно повторить по этим конспектам Yandex & MIPT (делимся с разрешения). Кратко, на русском – то что надо. Если подробно, то матан – Кудрявцев, линал – Кострикин, оптимизация – Boyd (англ.), теорвер и статистика – Кибзун. Плюс отличные онлайн-курсы МФТИ и ВШЭ на Coursera;
- по Python хватит небольшого интерактивного туториала на Datacamp или этого репозитория по Python и базовым алгоритмам и структурам данных. Что-то более продвинутое – это, например, курс питерского Computer Science Center;
- что касается машинного обучения, то есть классический (но слегка устаревший) курс Andrew Ng «Machine Learning»(Stanford, Coursera). На русском языке есть отличная специализация МФТИ и Яндекса «Машинное обучение и анализ данных». А вот и лучшие книги: «Pattern recognition and Machine Learning» (Bishop), «Machine Learning: A Probabilistic Perspective » (Murphy), «The elements of statistical learning» (Hastie, Tibshirani, Friedman), «Deep Learning» (Goodfellow, Bengio, Courville). Книга Goodfellow начинается с обзора математики и понятного и интересного введения в машинное обучение и внутреннее устройство его алгоритмов. Приятно, что теперь про глубокое обучение есть книга и на русском языке – «Глубокое обучение: погружение в мир нейронных сетей» (Николенко С. И., Кадурин А. А., Архангельская Е. О.).
Также про курс рассказано в этом анонсе.
Какое ПО нужно
Для прохождения курса нужен ряд Python-пакетов, большинство из них есть в сборке Anaconda с Python 3.6. Чуть позже понадобятся и другие библиотеки, об этом будет сказано дополнительно. Полный список можно посмотреть в Dockerfile.
Также можно воспользоваться Docker-контейнером, в котором все необходимое ПО уже установлено. Подробности – на странице Wiki репозитория.
Как подключиться к курсу
Никакой формальной регистрации не требуется, подключиться к курсу можно в любой момент после начала (01.10.18 г.), но дедлайны по домашним заданиям жесткие.
Но чтоб мы о вас больше знали:
- Заполните опрос, указав в нем реальное ФИО;
- Вступите в сообщество OpenDataScience, обсуждение курса ведется в канале #mlcourse.ai.
1. Определения и классификация
1.1 Что и зачем
- Генераторы выражений предназначены для компактного и удобного способа генерации коллекций элементов, а также преобразования одного типа коллекций в другой.
- В процессе генерации или преобразования возможно применение условий и модификация элементов.
- Генераторы выражений являются синтаксическим сахаром и не решают задач, которые нельзя было бы решить без их использования.
1.2 Преимущества использования генераторов выражений
- Более короткий и удобный синтаксис, чем генерация в обычном цикле.
- Более понятный и читаемый синтаксис чем функциональный аналог сочетающий одновременное применение функций map(), filter() и lambda.
- В целом: быстрее набирать, легче читать, особенно когда подобных операций много в коде.
1.3 Классификация и особенности
- выражение-генератор (generator expression) — выражение в круглых скобках которое выдает создает на каждой итерации новый элемент по правилам.
- генератор коллекции — обобщенное название для генератора списка (list comprehension), генератора словаря (dictionary comprehension) и генератора множества (set comprehension).
Openpyxl dimensions
To get those cells that actually contain data, we can use dimensions.
dimensions.py
#!/usr/bin/env python
from openpyxl import Workbook
book = Workbook()
sheet = book.active
sheet = 39
sheet = 19
rows =
for row in rows:
sheet.append(row)
print(sheet.dimensions)
print("Minimum row: {0}".format(sheet.min_row))
print("Maximum row: {0}".format(sheet.max_row))
print("Minimum column: {0}".format(sheet.min_column))
print("Maximum column: {0}".format(sheet.max_column))
for c1, c2 in sheet:
print(c1.value, c2.value)
book.save('dimensions.xlsx')
The example calculates the dimensions of two columns of data.
sheet = 39
sheet = 19
rows =
for row in rows:
sheet.append(row)
We add data to the worksheet. Note that we start adding from
the third row.
print(sheet.dimensions)
The property returns the top-left and bottom-right
cell of the area of non-empty cells.
print("Minimum row: {0}".format(sheet.min_row))
print("Maximum row: {0}".format(sheet.max_row))
Witht the and properties, we get the minimum
and maximum row containing data.
print("Minimum column: {0}".format(sheet.min_column))
print("Maximum column: {0}".format(sheet.max_column))
With the and properties, we get the minimum
and maximum column containing data.
for c1, c2 in sheet:
print(c1.value, c2.value)
We iterate through the data and print it to the console.
$ ./dimensions.py A3:B9 Minimum row: 3 Maximum row: 9 Minimum column: 1 Maximum column: 2 39 19 88 46 89 38 23 59 56 21 24 18 34 15
This is the output of the example.
В пользу Python (и других внешних языков программирования)
- Приятный синтаксис и синтаксический сахар. Если коротко, то VBA не отличается выразительностью и удобством. Это вопрос личного вкуса, но для меня Python намного удобнее.
- Богатая экосистема библиотек. Огромный выбор готовых библиотек для работы с внешним миром. Пытаться сделать на VBA программу, взаимодействующую с каким-нибудь внешним API, та еще боль. Занимательно, что как раз для работы с файлами Office библиотеки того же Python — откровенно «на троечку».
- Хорошие средства разработки. Можно выбрать из огромного выбор программ, которые облегчают процесс разработки. Стандартный редактор VBA из Office предлагает очень бедный функционал и, в сравнении с альтернативами из мира Python, откровенно неудобен. Писать код VBA в внешнем редакторе, а потом копировать внутрь офиса для отладки — тоже неудобно.
- Скорость работы. Не проверял скорость однопоточной работы, но, предположу, что в случае однопоточной работы преимущество будет за Python. В любом случае, достаточно тривиально организуется многопоточная обработка данных/файлов, что позволяет говорить в большей достижимой скорости.