Открытый курс машинного обучения. тема 1. первичный анализ данных с pandas
Содержание:
- Причины
- Как делается merge?
- Read xls with Pandas
- План этой статьи
- Демонстрация основных методов Seaborn и Plotly
- Загрузка данных вручную
- Описательная статистика и пустые значения
- NumPy
- Итерация фреймов данных
- Обзор полезных ресурсов
- Выбор нескольких столбцов
- Python-пакеты для Data Science
- Первые попытки прогнозирования оттока
- Корреляция цен
- Диагностика
Причины
PANDAS-синдром — это скорее группа симптомов, чем определенное заболевание. Точная причина этих симптомов не ясна. Бактерии стрептококка группы А могут вызывать множество различных инфекций, включая ангину, некоторые кожные инфекции и, если человек не получает лечения, то развиваются ревматологические заболевания. Эти инфекции распространяются, имитируя здоровые клетки в организме ребенка. Организм в конце концов распознает эти клетки и вырабатывает антитела, которые их убивают. Однако антитела могут также атаковать здоровые ткани, в том числе головной мозг. Таким образом, стрептококк группы А может вызвать PANDAS-синдром. Дети с PANDAS-синдромом могут иметь генетическую предрасположенность к этому синдрому.
Как делается merge?
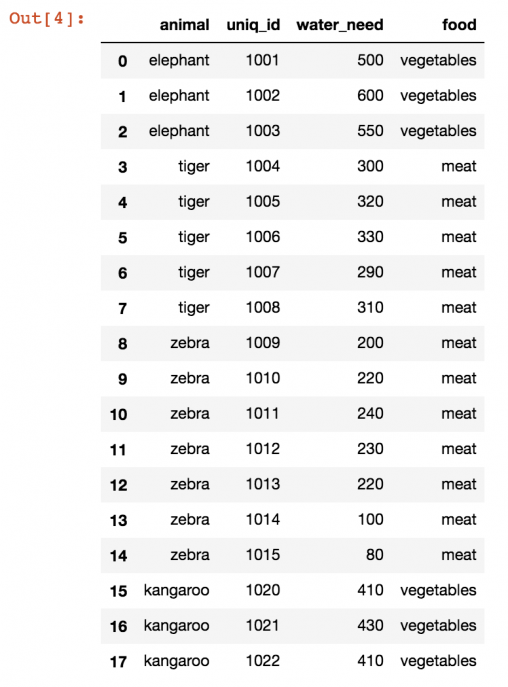
В первую очередь нужно создать DataFrame , потому что уже имеется из прошлых частей. Для упрощения задачи вот исходные данные:
О том, как превратить этот набор в DataFrame, написано в первом уроке по pandas. Но есть способ для ленивых. Нужно лишь скопировать эту длинную строку в , который был создан еще в первой части руководства.
И вот готов DataFrame .
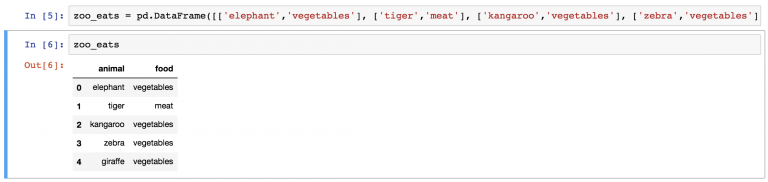
Теперь пришло время метода merge:
(А где же все львы? К этому вернемся чуть позже).
Это было просто, не так ли? Но стоит разобрать, что сейчас произошло:
Сначала был указан первый DataFrame (). Потом к нему применен метод . В качестве его параметра выступает новый DataFrame (). Можно было сделать и наоборот:
Это то же самое, что и:
Разница будет лишь в порядке колонок в финальной таблице.
Способы объединения: inner, outer, left, right

Базовый метод довольно прост. Но иногда к нему нужно добавить несколько параметров.
Один из самых важных вопросов — как именно нужно объединять эти таблицы. В SQL есть 4 типа JOIN.

В случае с в pandas в теории это работает аналогичным образом.
При выборе INNER JOIN (вид по умолчанию в SQL и pandas) объединяются только те значения, которые можно найти в обеих таблицах. В случае же с OUTER JOIN объединяются все значения, даже если некоторые из них есть только в одной таблице.
Конкретный пример: в нет значения . А в нет значения . По умолчанию использовался метод INNER, поэтому и львы, и жирафы пропали из таблицы. Но бывают случаи, когда нужно, чтобы все значения оставались в объединенном DataFrame. Этого можно добиться следующим образом:
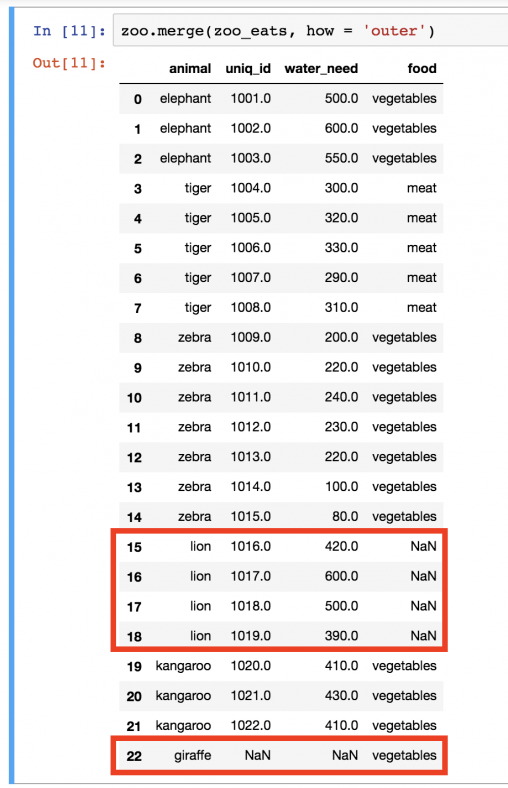
В этот раз львы и жирафы вернулись. Но поскольку вторая таблица не предоставила конкретных данных, то вместо значения ставится пропуск ().
Логичнее всего было бы оставить в таблице львов, но не жирафов. В таком случае будет три типа еды: , и (что, фактически, значит, «информации нет»). Если же в таблице останутся жирафы, это может запутать, потому что в зоопарке-то этого вида животных все равно нет. Поэтому следует воспользоваться параметром при объединении.
Вот так:
Теперь в таблице есть вся необходимая информация, и ничего лишнего. заберет все значения из левой таблицы (), но из правой () использует только те значения, которые есть в левой.
Еще раз взглянем на типы объединения:
Merge в pandas. По какой колонке?
Для использования библиотеке pandas нужны ключевые колонки, на основе которых будет проходить объединение (в случае с примером это колонка ). Иногда pandas не сможет распознать их автоматически, и тогда нужно указать названия колонок. Для этого нужны параметры и .
Например, последний merge мог бы выглядеть следующим образом:
Merge в pandas — довольно сложный метод, но остальные будут намного проще.
Read xls with Pandas
Pandas, a data analysis library, has native support for loading excel data (xls and xlsx).The method read_excel loads xls data into a Pandas dataframe:
read_excel(filename) |
If you have a large excel file you may want to specify the sheet:
df = pd.read_excel(file, sheetname='Elected presidents') |
Related courseData Analysis with Python Pandas
Read excel with PandasThe code below reads excel data into a Python dataset (the dataset can be saved below).
from pandas import DataFrame, read_csvimport matplotlib.pyplot as pltimport pandas as pd file = r'data/Presidents.xls'df = pd.read_excel(file)print(df) |
The dataframe can be used, as shown in the example below:
from pandas import DataFrame, read_csvimport matplotlib.pyplot as pltimport pandas as pd file = r'data/Presidents.xls'df = pd.read_excel(file)df = df != 'n/a']print('Min: ', df.min())print('Max: ', df.max())print('Sum: ', df.sum())
|
DatasetFor purpose of demonstration, you can use the dataset from: depaul.edu.
 A large dataset stored in XLS format
A large dataset stored in XLS format
План этой статьи
Демонстрация основных методов Seaborn и Plotly
В начале как всегда настроим окружение: импортируем все необходимые библиотеки и немного настроим дефолтное отображение картинок.
После этого загрузим в данные, с которыми будем работать. Для примеров я выбрала данные о продажах и оценках видео-игр из Kaggle Datasets.
Некоторые признаки, которые считал как , явно приведем к типам или .
Данные есть не для всех игр, поэтому давайте оставим только те записи, в которых нет пропусков, с помощью метода .
Всего в таблице 6825 объектов и 16 признаков для них. Посмотрим на несколько первых записей c помощью метода , чтобы убедиться, что все распарсилось правильно. Для удобства я оставила только те признаки, которые мы будем в дальнейшем использовать.
Прежде чем мы перейдем к рассмотрению методов библиотек и , обсудим самый простой и зачастую удобный способ визуализировать данные из — это воспользоваться функцией .
Для примера построим график продаж видео игр в различных странах в зависимости от года. Для начала отфильтруем только нужные нам столбцы, затем посчитаем суммарные продажи по годам и у получившегося вызовем функцию без параметров.
Реализация функции в основана на библиотеке .
C помощью параметра можно изменить тип графика, например, на . позволяет очень гибко настраивать графики. На графике можно изменить почти все, что угодно, но потребуется порыться в документации и найти нужные параметры. Например, параметр отвечает за угол наклона подписей к оси .
Загрузка данных вручную
Здравствуйте и вновь добро пожаловать на занятия по теме «Инструментарий Numpy на языке Python».
Существует огромное количество неструктурированных данных. Примером тому может служить сам интернет. Если бы можно было написать программу для сбора всех данных в интернете, то у нас появилось бы колоссальное количество данных для экспериментов. Разумеется, это также потребовало бы колоссальных вычислительных ресурсов и само по себе было бы сложной технической задачей. Поэтому не будем это обсуждать.
Бывает, что данные являются частично структурированными. К примеру, если мы подключимся к веб-серверу и посмотрим на логи сервера Apache, то увидим, что каждый запрос идёт отдельной строкой, но данные в этой строке весьма неоднородны.
В других случаях данные полностью структурированы. Такое встречается, если обратиться к размеченным наборам данных. Например, Kaggle.com – сайт, на котором проводятся состязания в сфере обработки данных, предоставляет структурированные данные. Известнейшая база данных MNIST, представляющая собой набор рукописных цифр, является набором структурированных данных.
Чаще всего структурированные данные представляются в форме CSV-файлов. CSV расшифровывается как comma separated values – значения, разделённые запятыми. Это значит, что каждая строка представляет запись, а каждая ячейка в записи отделяется запятыми. CSV-файлы можно открыть в программах вроде Excel, поскольку формат CSV по сути является таблицей. Впрочем, для нас, специалистов по обработке данных, таблица на самом деле является матрицей, а мы любим матрицы, так как они позволяют проводить математические операции.
Ввиду этого нас интересует, как получить матрицу, состоящую из чисел, из файла в формате CSV. В этой, первой лекции данной части, мы используем обычные программные средства языка Python, чтобы преобразовать CSV в матрицу. Это включает в себя построчное считывание данных из файла, разделение каждой строки запятой и помещение каждого из значений в список. Файл, с которым мы будем работать, называется data_2d.csv; он находится в том же репозитарии Github, но в папке linear_regression_class, так что если вы изучали мой курс по линейной регрессии, то в действительности вы уже работали с этим файлом.
Сделаем краткий обзор файла. Как вы можете видеть, файл содержит 100 строк, а в каждой строке по три значения. Следовательно, в итоге мы будем работать с матрицей размерности 100×3. Конечно же, не хотелось бы задавать жёсткий размер 100×3, так что считывать файл будем таким образом, будто мы не знаем значений размерности.
Итак, заходим в папку linear_regression_class и запускаем Python. Но прежде, чем что-то делать, мы должны озаботиться о списке, в котором будут храниться полученные значения. Поэтому создадим пустой список, а также импортируем библиотеку Numpy:
X = []
import numpy as np
Итак, прежде всего мы должны пройтись по каждой строке, а после этого разделить их запятыми. Переменная row будет содержать список, состоящий из строк, которые, в свою очередь, представляют значения действительных чисел. Поскольку в итоге мы хотим получить числовые значения, необходимо преобразовать эти строки в действительные числа, для чего используем функцию map. И последнее – добавляем текущий пример в наш список:
for line in open(‘’data_2d.csv’’):
row = line.split(‘,’)
sample = map(float, row)
X.append.sample
Теперь у нас есть список списков. Как вы уже знаете, мы можем преобразовать его в массив Numpy:
X = np.array(X)
Проверим размерность X:
X.shape
Размерность правильная – 100×3.
Итак, это один из способов загрузки данных. Если в наличии имеется набор неструктурированных данных или нужно сделать выборочное считывание, то это то, что надо. В следующей лекции мы рассмотрим куда более простой способ загрузки данных с использованием библиотеки Pandas.
Описательная статистика и пустые значения
Для числовых значений можно получить описательную статистику методом :
data.describe()
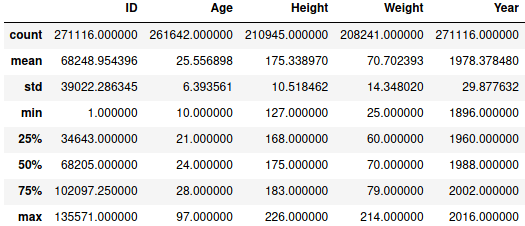 Описательная статистика
Описательная статистика
Пробежимся по атрибутам описательной статистики:
- сount обозначает количество записей,
- mean – среднее арифметическое,
- std – стандартное отклонение,
- min – минимальное значение,
- n-ый (25, 50, 75) % – n-ый квартиль,
- max – максимальное значение.
Строки с пустыми (NaN)значениями отбрасываются методом . У drop есть параметр subset, уточняющий, в каком столбце удалять; если его не указать, то отбросятся строки с NaN’ами каждого из столбцов. Удалим пустые значения Medal:
>>> data.dropna(subset=) 3 Gold 37 Bronze 38 Bronze 40 Bronze 41 Bronze ... 271078 Silver 271080 Bronze 271082 Bronze 271102 Bronze 271103 Silver Name: Medal, Length: 39783, dtype: object
Как можно заметить, этот столбец имеет только 39.783 не NaN значений тогда, когда всего 271.116.
После всех манипуляций с данными не забудьте переприсвоить изменения. Вышеперечисленные методы создают новый DataFrame, а не изменяют старый. Например, чтобы в дальнейшем иметь дело с тремя столбцами, пишем:
data = data]
NumPy
NumPy (Numerical Python) является фундаментальным пакетом для численных расчетов в Python, который включает в себя мощный объект N-мерного массива. Он имеет около 18 000 коммитов на GitHub и активное сообщество из 700 участников. Numpy является универсальным пакетом обработки, который дает возможность работы с высокопроизводительными многомерными объектами, называемыми массивами, а также предоставляет сопутствующие инструменты для этого. Благодаря этим массивам, а также функциям и операторам, которые с ними работают, Numpy частично решает проблему медленной работы Python.
Особенности:
- Использование быстрых, предварительно скомпилированных функции для числовых операций
- Высокая эффективность вычислений основанных на операциях с массивами
- Поддержка объектно-ориентированного подхода
- Компактные и быстрые вычисления с использованием векторов
Области использования:
- Широкое использование в анализе данных
- Создание больших N-мерных массивов
- Формирование базы для других библиотек, таких как SciPy и scikit-learn.
- Для замены MATLAB при использовании вместе с SciPy и matplotlib
Из видео вы также узнаете, как создать простой массив и изменить его форму с помощью функций NumPy arange и reshape.
Итерация фреймов данных
Итерация данных дает следующие результаты для трех структур данных:
- Серия: набор значений;
- DataFrame: метки столбца;
- Панель: ярлыки предметов.
Следующие функции могут использоваться для итерации DataFrame:
- iteritems() — перебирает данные и дает пары (ключ, значение);
- iterrows() — перебирает строки и приводит к парам (индекс, серия);
- itertuples() — выполняет итерацию по строкам данных и приводит к именованным кортежам или namedtuple.
Пример:
import pandas
import numpy
input = {'Name':pandas.Series(),
'Marks':pandas.Series(),
'Roll_num':pandas.Series()
}
data_frame = pandas.DataFrame(input)
#using the iteritems() function
for key,value in data_frame.iteritems():
print(key,value)
print("\n")
#using the iterrows() function
for row_index,row in data_frame.iterrows():
print(row_index,row)
print("\n")
#using the itertuples() function
for row in data_frame.itertuples():
print(row)
Выход:
Name 0 John 1 Bran 2 Caret 3 Joha 4 Sam Name: Name, dtype: object Marks 0 44 1 48 2 75 3 33 4 99 Name: Marks, dtype: int64 Roll_num 0 1 1 2 2 3 3 4 4 5 Name: Roll_num, dtype: int64 0 Name John Marks 44 Roll_num 1 Name: 0, dtype: object 1 Name Bran Marks 48 Roll_num 2 Name: 1, dtype: object 2 Name Caret Marks 75 Roll_num 3 Name: 2, dtype: object 3 Name Joha Marks 33 Roll_num 4 Name: 3, dtype: object 4 Name Sam Marks 99 Roll_num 5 Name: 4, dtype: object Pandas(Index=0, Name='John', Marks=44, Roll_num=1) Pandas(Index=1, Name='Bran', Marks=48, Roll_num=2) Pandas(Index=2, Name='Caret', Marks=75, Roll_num=3) Pandas(Index=3, Name='Joha', Marks=33, Roll_num=4) Pandas(Index=4, Name='Sam', Marks=99, Roll_num=5)
Обзор полезных ресурсов
- Перевод этой статьи на английский – Medium story
- Видеозапись лекции по мотивам этой статьи
- В первую очередь, конечно же, официальная документация Pandas. В частности, рекомендуем короткое введение 10 minutes to pandas
- Русский перевод книги «Learning pandas» + репозиторий
- PDF-шпаргалка по библиотеке
- Презентация Александра Дьяконова «Знакомство с Pandas»
- Серия постов «Modern Pandas» (на английском языке)
- На гитхабе есть подборка упражнений по Pandas и еще один полезный репозиторий (на английском языке) «Effective Pandas»
- scipy-lectures.org — учебник по работе с pandas, numpy, matplotlib и scikit-learn
- Pandas From The Ground Up – видео с PyCon 2015
Статья написана в соавторстве с yorko (Юрием Кашницким).
Выбор нескольких столбцов
Что если мы хотим знать только тип жалобы и район, а остальное нам неинтересно? Pandas позволяет легко выбрать подмножество столбцов: просто проиндексируйте списком столбцов.
In :
complaints]
Out:
| Complaint Type | Borough | |
|---|---|---|
| Noise — Street/Sidewalk | QUEENS | |
| 1 | Illegal Parking | QUEENS |
| 2 | Noise — Commercial | MANHATTAN |
| 3 | Noise — Vehicle | MANHATTAN |
| 4 | Rodent | MANHATTAN |
| 5 | Noise — Commercial | QUEENS |
| 6 | Blocked Driveway | QUEENS |
| 7 | Noise — Commercial | QUEENS |
| 8 | Noise — Commercial | MANHATTAN |
| 9 | Noise — Commercial | BROOKLYN |
| 10 | Noise — House of Worship | BROOKLYN |
| 11 | Noise — Commercial | MANHATTAN |
| 12 | Illegal Parking | MANHATTAN |
| 13 | Noise — Vehicle | BRONX |
| 14 | Rodent | BROOKLYN |
| 15 | Noise — House of Worship | MANHATTAN |
| 16 | Noise — Street/Sidewalk | STATEN ISLAND |
| 17 | Illegal Parking | BROOKLYN |
| 18 | Street Light Condition | BROOKLYN |
| 19 | Noise — Commercial | MANHATTAN |
| 20 | Noise — House of Worship | BROOKLYN |
| 21 | Noise — Commercial | MANHATTAN |
| 22 | Noise — Vehicle | QUEENS |
| 23 | Noise — Commercial | BROOKLYN |
| 24 | Blocked Driveway | STATEN ISLAND |
| 25 | Noise — Street/Sidewalk | STATEN ISLAND |
| 26 | Street Light Condition | BROOKLYN |
| 27 | Harboring Bees/Wasps | MANHATTAN |
| 28 | Noise — Street/Sidewalk | MANHATTAN |
| 29 | Street Light Condition | STATEN ISLAND |
| … | … | … |
| 111039 | Noise — Commercial | MANHATTAN |
| 111040 | Noise — Commercial | MANHATTAN |
| 111041 | Noise | BROOKLYN |
| 111042 | Noise — Street/Sidewalk | MANHATTAN |
| 111043 | Noise — Commercial | BROOKLYN |
| 111044 | Noise — Street/Sidewalk | MANHATTAN |
| 111045 | Water System | MANHATTAN |
| 111046 | Noise | BROOKLYN |
| 111047 | Illegal Parking | QUEENS |
| 111048 | Noise — Street/Sidewalk | MANHATTAN |
| 111049 | Noise — Commercial | BROOKLYN |
| 111050 | Noise | MANHATTAN |
| 111051 | Noise — Commercial | MANHATTAN |
| 111052 | Water System | MANHATTAN |
| 111053 | Derelict Vehicles | QUEENS |
| 111054 | Noise — Street/Sidewalk | BROOKLYN |
| 111055 | Noise — Commercial | BROOKLYN |
| 111056 | Street Sign — Missing | QUEENS |
| 111057 | Noise | MANHATTAN |
| 111058 | Noise — Commercial | BROOKLYN |
| 111059 | Noise — Street/Sidewalk | MANHATTAN |
| 111060 | Noise | MANHATTAN |
| 111061 | Noise — Commercial | QUEENS |
| 111062 | Water System | MANHATTAN |
| 111063 | Water System | MANHATTAN |
| 111064 | Maintenance or Facility | BROOKLYN |
| 111065 | Illegal Parking | QUEENS |
| 111066 | Noise — Street/Sidewalk | MANHATTAN |
| 111067 | Noise — Commercial | BROOKLYN |
| 111068 | Blocked Driveway | BROOKLYN |
111069 rows × 2 columns
Посмотрим первые 10 строк:
In :
complaints][:10
Out:
| Complaint Type | Borough | |
|---|---|---|
| Noise — Street/Sidewalk | QUEENS | |
| 1 | Illegal Parking | QUEENS |
| 2 | Noise — Commercial | MANHATTAN |
| 3 | Noise — Vehicle | MANHATTAN |
| 4 | Rodent | MANHATTAN |
| 5 | Noise — Commercial | QUEENS |
| 6 | Blocked Driveway | QUEENS |
| 7 | Noise — Commercial | QUEENS |
| 8 | Noise — Commercial | MANHATTAN |
| 9 | Noise — Commercial | BROOKLYN |
Python-пакеты для Data Science
- NumPy
- SciPy
- Pandas
- StatsModels
- Matplotlib
- Seaborn
- Plotly
- Bokeh
- Scikit-Learn
- Keras
▍1. NumPy
Особенности NumPy
- Пакет можно использовать как для выполнения простых, так и достаточно сложных научных расчётов.
- Он поддерживает многомерные массивы, расширяя возможности Python.
- В пакете имеется множество встроенных методов, которые можно применять для выполнения различных вычислений на многомерных массивах.
- Пакет позволяет выполнять различные преобразования данных.
- Пакет поддерживает работу не только с числовыми, но и с другими типами данных.
▍2. SciPy
Особенности SciPy
- Пакет SciPy основан на NumPy.
- Он поддерживает вычисления, основанные на эффективных структурах данных NumPy.
- Этот пакет, помимо возможностей NumPy, задействует и возможности других пакетов.
- SciPy представляет собой набор подпакетов, в которых реализованы различные вычислительные механизмы. Среди них, например, подпакеты, реализующие быстрое преобразование Фурье, обработку изображений, решение дифференциальных уравнений, механизмы линейной алгебры.
▍3. Pandas
Особенности Pandas
- Он поддерживает объект DataFrame, предназначенный для работы с индексированными массивами.
- Этот пакет является одним из лучших инструментов для исследования данных.
- Его можно использовать для работы с большими наборами данных. В частности, речь идёт о слиянии и объединении наборов данных, о создании срезов данных, о группировке данных, об их визуализации.
- Пакет может работать с различными источниками данных. Например — с CSV- и TSV-файлами, с базами данных.
▍4. StatsModels
Особенности StatsModels
- Многие дата-сайентисты используют этот пакет для проведения статистических вычислений.
- В его состав входят некоторые методы, которые знакомы тем, кто пользуется языком R.
- С его помощью создают и исследуют, например, обобщённые линейные модели, он позволяет проводить одномерный и двумерный анализ данных, применяется для проверки гипотез.
▍5. Matplotlib
Особенности Matplotlib
- С помощью этого пакета можно очень просто и удобно строить различные графики и диаграммы.
- Графические представления данных, создаваемые этим пакетом, поддаются глубокой настройке.
- Он поддерживает объектно-ориентированный API, позволяющий интегрировать его в различные приложения.
▍6. Seaborn
Особенности Seaborn
- Встроенные возможности исследования данных.
- Поддержка различных форматов данных.
- Он умеет строить графики моделей линейной регрессии.
- Его используют для создания сложных визуализаций.
- Он поддерживает различные способы настройки внешнего вида графиков.
▍7. Plotly
Особенности Plotly
- Этот пакет поддерживает все необходимые дата-сайентисту виды графиков. Среди них — линейные диаграммы, круговые диаграммы, пузырьковые диаграммы, точечные диаграммы, древовидные диаграммы.
- Он, кроме того, поддерживает специфические виды диаграмм, используемые в статистике и науке.
- Пакет поддерживает трёхмерные визуализации.
- Он экспортирует данные в формат JSON, подходящий для использования в других приложениях.
▍8. Bokeh
Особенности Bokeh
- Поддерживает визуализацию наборов данных, которые обычно используются в статистике и науке.
- Поддерживает различные форматы выходных данных.
- Существуют версии Bokeh для разных языков программирования.
- Пакет хорошо интегрируется с такими Python-фреймворками, как Django и Flask.
▍9. Scikit-Learn
Особенности Scikit-Learn
- На основе этого пакета можно создавать спам-детекторы и системы классификации изображений.
- Поддерживает различные алгоритмы регрессии.
- Позволяет создавать модели машинного обучения с учителем и без учителя.
- Поддерживает механизмы кросс-валидации для оценки моделей.
- Поддерживает широкий набор нейросетевых моделей.
- Содержит встроенные средства для работы с изображениями.
- Поддерживает популярные алгоритмы глубокого обучения.
- Отличается высоким уровнем расширяемости, что позволяет, при необходимости, оснащать его новым функционалом.
Первые попытки прогнозирования оттока
Посмотрим, как отток связан с признаком «Подключение международного роуминга» (International plan). Сделаем это с помощью сводной таблички crosstab, а также путем иллюстрации с Seaborn (как именно строить такие картинки и анализировать с их помощью графики – материал следующей статьи).
| International plan | False | True | All |
|---|---|---|---|
| Churn | |||
| 2664 | 186 | 2850 | |
| 1 | 346 | 137 | 483 |
| All | 3010 | 323 | 3333 |
Видим, что когда роуминг подключен, доля оттока намного выше – интересное наблюдение! Возможно, большие и плохо контролируемые траты в роуминге очень конфликтогенны и приводят к недовольству клиентов телеком-оператора и, соответственно, к их оттоку.
Далее посмотрим на еще один важный признак – «Число обращений в сервисный центр» (Customer service calls). Также построим сводную таблицу и картинку.
| Customer service calls | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | All | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Churn | |||||||||||
| 605 | 1059 | 672 | 385 | 90 | 26 | 8 | 4 | 1 | 2850 | ||
| 1 | 92 | 122 | 87 | 44 | 76 | 40 | 14 | 5 | 1 | 2 | 483 |
| All | 697 | 1181 | 759 | 429 | 166 | 66 | 22 | 9 | 2 | 2 | 3333 |
Может быть, по сводной табличке это не так хорошо видно (или скучно ползать взглядом по строчкам с цифрами), а вот картинка красноречиво свидетельствует о том, что доля оттока сильно возрастает начиная с 4 звонков в сервисный центр.
Добавим теперь в наш DataFrame бинарный признак — результат сравнения . И еще раз посмотрим, как он связан с оттоком.
| Churn | 1 | All | |
|---|---|---|---|
| Many_service_calls | |||
| 2721 | 345 | 3066 | |
| 1 | 129 | 138 | 267 |
| All | 2850 | 483 | 3333 |
Объединим рассмотренные выше условия и построим сводную табличку для этого объединения и оттока.
| Churn | 1 | |
|---|---|---|
| row_0 | ||
| False | 2841 | 464 |
| True | 9 | 19 |
Значит, прогнозируя отток клиента в случае, когда число звонков в сервисный центр больше 3 и подключен роуминг (и прогнозируя лояльность – в противном случае), можно ожидать около 85.8% правильных попаданий (ошибаемся всего 464 + 9 раз). Эти 85.8%, которые мы получили с помощью очень простых рассуждений – это неплохая отправная точка (baseline) для дальнейших моделей машинного обучения, которые мы будем строить.
В целом до появления машинного обучения процесс анализа данных выглядел примерно так. Прорезюмируем:
- Доля лояльных клиентов в выборке – 85.5%. Самая наивная модель, ответ которой «клиент всегда лоялен» на подобных данных будет угадывать примерно в 85.5% случаев. То есть доли правильных ответов (accuracy) последующих моделей должны быть как минимум не меньше, а лучше, значительно выше этой цифры;
- С помощью простого прогноза, который условно можно выразить такой формулой: «International plan = True & Customer Service calls > 3 => Churn = 1, else Churn = 0», можно ожидать долю угадываний 85.8%, что еще чуть выше 85.5%. Впоследствии мы поговорим о деревьях решений и разберемся, как находить подобные правила автоматически на основе только входных данных;
- Эти два бейзлайна мы получили без всякого машинного обучения, и они служат отправной точной для наших последующих моделей. Если окажется, что мы громадными усилиями увеличиваем долю правильных ответов всего, скажем, на 0.5%, то возможно, мы что-то делаем не так, и достаточно ограничиться простой моделью из двух условий;
- Перед обучением сложных моделей рекомендуется немного покрутить данные и проверить простые предположения. Более того, в бизнес-приложениях машинного обучения чаще всего начинают именно с простых решений, а потом экспериментируют с их усложнениями.
Корреляция цен
| books.ru | labirint.ru | ozon.ru | my-shop.ru | read.ru | bookvoed.ru | book-stock.ru | setbook.ru | |
|---|---|---|---|---|---|---|---|---|
| books.ru | 1.000000 | 0.971108 | 0.969906 | 0.965291 | 0.978453 | 0.970747 | 0.965809 | 0.966226 |
| labirint.ru | 0.971108 | 1.000000 | 0.973731 | 0.968637 | 0.979923 | 0.970600 | 0.969971 | 0.965970 |
| ozon.ru | 0.969906 | 0.973731 | 1.000000 | 0.973783 | 0.979620 | 0.967151 | 0.974792 | 0.971946 |
| my-shop.ru | 0.965291 | 0.968637 | 0.973783 | 1.000000 | 0.976491 | 0.956980 | 0.996946 | 0.970588 |
| read.ru | 0.978453 | 0.979923 | 0.979620 | 0.976491 | 1.000000 | 0.974892 | 0.976164 | 0.974129 |
| bookvoed.ru | 0.970747 | 0.970600 | 0.967151 | 0.956980 | 0.974892 | 1.000000 | 0.958787 | 0.961217 |
| book-stock.ru | 0.965809 | 0.969971 | 0.974792 | 0.996946 | 0.976164 | 0.958787 | 1.000000 | 0.972701 |
| setbook.ru | 0.966226 | 0.965970 | 0.971946 | 0.970588 | 0.974129 | 0.961217 | 0.972701 | 1.000000 |
Диагностика
В настоящее время ни один лабораторный тест не может диагностировать PANDAS-синдром. Вместо этого врачи ориентируются на симптомы и историю болезни ребенка.
Врач проверит горло ребенка на наличие стрептококковой инфекции. Если тест отрицательный, инфекция может скрываться в другом месте, например, в гениталиях. Поэтому врач может использовать другие методы диагностики, если у ребенка есть или ранее были симптомы стрептококкового заболевания.
Родители должны рассказать врачу обо всех симптомах и предшествующих инфекциях
Также важно отметить, появились ли симптомы внезапно или развились с течением времени
Врач будет использовать следующие шаги для диагностики PANDAS-синдрома
- искать доказательства ОКР, тиков или того и другого вместе;
- ребенок должен соответствовать возрастным требованиям для PANDAS-синдрома, так как симптомы проявляются в возрасте от 3 лет до полового созревания;
- искать признаки стрептококковой инфекции;
- проверить на наличие любых неврологических отклонений.