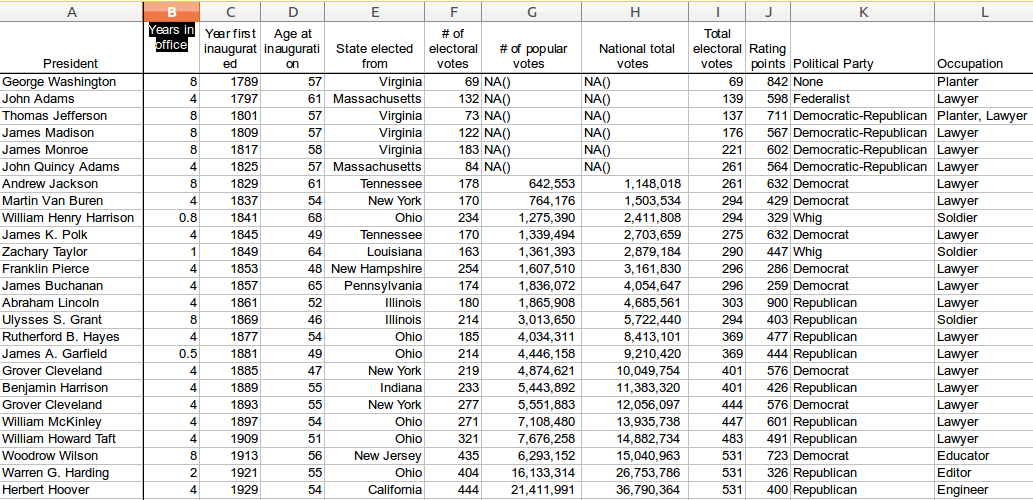
Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
Содержание:
- Литература
- Обучение с учителем и без учителя
- Классификация
- 9 . Бэггинг и случайный лес
- Препроцессинг
- Векторы развития и сценарии использования
- Играемся с 3090 и пробуем MIG на A100
- Способы машинного обучения
- Инструменты для сбора, обработки и визуализации данных
- Обучение с учителем
- 10 . Бустинг и AdaBoost
- О принципах выбора лучшего алгоритма
- Машинное обучение в Python это не сложно
- Как из четырёх минут речи мы воссоздали голос молодого Леонида Куравлёва
- Тестируем комплементарную кросс-энтропию в задачах классификации текста
- Как посмотреть плоские фильмы в 3D
Литература
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: основы моделирования и первичная обработка данных. — М.: Финансы и статистика, 1983.
- Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: исследование зависимостей. — М.: Финансы и статистика, 1985.
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
- Вапник В. Н. Восстановление зависимостей по эмпирическим данным. — М.: Наука, 1979.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. — М.: Фазис, 2006. ISBN 5-7036-0108-8.
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. — Новосибирск: ИМ СО РАН, 1999. ISBN 5-86134-060-9.
- Флах П. Машинное обучение. — М.: ДМК Пресс, 2015. — 400 с. — ISBN 978-5-97060-273-7.
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. — Киев: Наукова думка, 2004. ISBN 966-00-0341-2.
- .
- Mitchell T. Machine Learning. — McGraw-Hill Science/Engineering/Math, 1997. ISBN 0-07-042807-7.
- Ryszard S. Michalski, Jaime G. Carbonell, Tom M. Mitchell (1983), Machine Learning: An Artificial Intelligence Approach, Tioga Publishing Company, ISBN 0-935382-05-4 ( в «Книгах Google»).
- Liang Wang, Li Cheng, Guoying Zhao. Machine Learning for Human Motion Analysis. — IGI Global, 2009. — 318 p. — ISBN 978-1-60566-900-7.
Обучение с учителем и без учителя
Большую часть задач машинного обучения можно разделить на обучение с учителем (supervised learning) и обучение без учителя (unsupervised learning). Если вы представили себе программиста с плёткой в одной руке и куском сахара в другой, вы немного ошиблись. Под «учителем» здесь понимается сама идея вмешательства человека в обработку данных. При обучении с учителем у нас есть данные, на основании которых нужно что-то предсказать, и некоторые гипотезы. При обучении без учителя у нас есть только данные, свойства которых мы и хотим найти. На примерах разницу вы увидите немного яснее.
Обучение с учителем
У нас есть данные о 10 000 квартирах в Москве, причём известна площадь каждой квартиры, количество комнат, этаж, на котором она расположена, район, наличие парковки, расстояние до ближайшей станции метро и так далее. Кроме того, известна стоимость каждой квартиры. Нашей задачей является построение модели, которая на основе данных признаков будет предсказывать стоимость квартиры. Это классический пример обучения с учителем, где у нас есть данные (10 000 квартир и различные параметры для каждой квартиры, называемые признаками) и отклики (стоимость квартиры). Такая задача называется задачей регрессии. О том, что это такое, мы поговорим чуть позже.
Другие примеры: на основании различных медицинских показателей предсказать наличие у пациента рака. Или на основании текста электронного письма предсказать вероятность того, что это спам. Такие задачи являются задачами классификации.
Обучение без учителя
Интереснее ситуация обстоит с обучением без учителя, где нам неизвестны «правильные ответы». Пусть нам известны данные о росте и весе некоторого числа людей. Необходимо сгруппировать данные на 3 категории, чтобы для каждой категории людей выпустить рубашку подходящего размера. Такая задача называется задачей кластеризации.
Еще одним примером можно взять ситуацию, когда у нас каждый объект описывается, скажем, 100 признаками. Проблема таких данных заключается в том, что построить графическую иллюстрацию таких данных, мягко говоря, затруднительно, поэтому мы можем уменьшить количество признаков до двух-трёх. Тогда можно визуализировать данные на плоскости или в пространстве. Такая задача называется задачей уменьшения размерности.
Классификация
Задача классификации — это задача присвоения меток объектам. Например, если объекты — это фотографии, то метками может быть содержание фотографий: содержит ли изображение пешехода или нет, изображен ли мужчина или женщина, какой породы собака изображена на фотографии. Обычно есть набор взаимоисключающих меток и сборник объектов, для которых эти метки известны. Имея такую коллекцию данных необходимо автоматически расставлять метки на произвольных объектах того же типа, что были в изначальной коллекции. Давайте формализуем это определение.
Допустим, есть множество объектов . Это могут быть точки на плоскости, рукописные цифры, фотографии или музыкальные произведения. Допустим также, что есть конечное множество меток . Эти метки могут быть пронумерованы. Мы будем отождествлять метки и их номера. Таким образом в нашей нотации будет обозначаться как . Если , то задача называется задачей бинарной классификации, если меток больше двух, то обычно говорят, что это просто задача классификации. Дополнительно, у нас есть входная выборка . Это те самые размеченные примеры, на которых мы и будем обучаться проставлять метки автоматически. Так как мы не знаем классов всех объектов точно, мы считаем, что класс объекта — это случайная величина, которую мы для простоты тоже будем обозначать . Например, фотография собаки может классифицироваться как собака с вероятностью 0.99 и как кошка с вероятностью 0.01. Таким образом, чтобы классифицировать объект, нам нужно знать условное распределение этой случайной величины на этом объекте .
Задача нахождения при данном множестве меток и данном наборе размеченных примеров называется задачей классификации.
9 . Бэггинг и случайный лес
Случайный лес — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом.
Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения.
В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению.
В алгоритме случайного леса для всех выборок из тренировочных данных строятся деревья решений. При построении деревьев для создания каждого узла выбираются случайные признаки. В отдельности полученные модели не очень точны, но при их объединении качество предсказания значительно улучшается.
Если алгоритм с высокой дисперсией, например, деревья решений, показывает хороший результат на ваших данных, то этот результат зачастую можно улучшить, применив бэггинг.
Препроцессинг
- Создание векторного пространства признаков, где будут жить примеры обучающей выборки. По сути, это процесс приведения всех данных в числовую форму. Это избавляет нас от категорийных, булевых и прочих не числовых типов.
- Нормализация данных. Процесс, при котором мы добиваемся, например того, чтобы среднее значение каждого признака по всем данным было нулевым, а дисперсия — единичной. Вот самый классический пример нормализации данных: X = (X — μ)/σ
- Изменение размерности векторного пространства. Если векторное пространство признаков слишком велико (миллионы признаков) или мало (менее десятка), то можно применить методы повышения или понижения размерности пространства:
- Для повышения размерности можно использовать часть обучающей выборки как опорные точки, добавив в вектор признаков расстояние до этих точек. Этот метод часто приводит к тому, что в пространствах более высокой размерности множества становятся линейно разделимыми, и это упрощает задачу классификации.
- Для понижения размерности чаще всего используют PCA. Основная задача метода главных компонент — поиск новых линейных комбинаций признаков, вдоль которых максимизируется дисперсия значений проекций элементов обучающей выборки.
One-Hotстатьей о вкусовой сенсорной системе
| class: | red: | green: | blue: | bitter: | sweet: | salti: | sour: | weight: | solid: |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.23 | 1 | ||||||
| 1 | 1 | -0.85 | |||||||
| 1 | 1 | 1 | 0.14 | 1 | |||||
| 1 | 1 | 1 | 0.38 | ||||||
| 1 | 1 | -0.48 |
Таблица 2 — Пример данных обучающей выборки после препроцессингаkk
Векторы развития и сценарии использования
-
поиск объектов и паттернов (людей и их поведения на фото, видео и в тексте) — «поиск»,
-
искажение или полное удаление объектов — «клоакинг»
-
генерация и поиск «искусственных объектов» — «фейки» (создание и поиск).
Что здесь примечательно, так это две стороны одной и той же медали. С одной стороны, эти инструменты позволяют создавать новую информацию. А с другой, проверять ее на соответствие реальности. Это похоже на противоборство между созданием объектов и их дальнейшим детектированием. Как пример, создание фейковых новостей и их поиск среди реальных событий или поиск людей на фото (видео) против защиты от этого поиска.
Что касается «поиска», первое, что приходит на ум для поиска людей по фото это сервис FindFace. О нём известно с 2016 года. Сейчас этот проект переключился на b2b.
Но на рынке есть похожие компании, боты и сервисы. Их услугами могут пользоваться и частные лица.
Для защиты от инструментов поиска по фото Вы можете воспользоваться разными инструментами и сервисами.
Среди которых:
-
«Photo Protection» от D-ID
-
«Face Anonymization API» от DeepAI
Современные инструменты искусственного интеллекта и машинного обучения привносят в нашу жизнь новые возможности, новый контент и новые знания. А знание — это сила, даже если знание получено посредством искусственно созданных объектов.
Фейковые новости могут быть использованы не только для управления людьми, но и для выявления значимых настроений и мнений людей, до реальных событий. Например, чтобы узнать мнение людей до создания закона.
А искажение («cloaking») фото может позволить найти компромисс между публичностью и приватностью, сохранением персональных данных.
Играемся с 3090 и пробуем MIG на A100
Канал «Этот Компьютер» очень сильно недооценен, но автор не занимается ML. А в целом при анализе сравнений акселераторов для ML в глаза как правило бросаются несколько вещей:
- Авторы учитывают как правило только «адекватность» для рынка новых карт в США;
- Рейтинги далеки от народа и делаются на весьма стандартных сетках (что наверное в целом хорошо) без деталей;
- Популярная мантра тренировать все более гигантские сетки вносит свои коррективы в сравнения;
Не нужно быть семи пядей во лбу, чтобы знать очевидный ответ на вопрос «а какая карта лучше?»: карточки серии 20* в массы не пошли, 1080 Ti с Авито до сих очень привлекательны (и не особо дешевеют как ни странно, вероятно по этой причине).
- Стоит ли свеч обновление на Ampere? (спойлер для нетерпеливых — да);
- Стоят ли своих денег A100 (спойлер — в общем случае — нет);
- Есть ли кейсы, когда A100 все-таки интересны (спойлер — да);
- Полезна ли технология MIG (спойлер — да, но для инференса и для очень специфичных случаев для обучения);
За деталями прошу под кат.
Способы машинного обучения
Раздел машинного обучения, с одной стороны, образовался в результате разделения науки о нейросетях на методы обучения сетей и виды топологий их архитектуры, с другой стороны — вобрал в себя методы математической статистики. Указанные ниже способы машинного обучения исходят из случая использования нейросетей, хотя существуют и другие методы, использующие понятие обучающей выборки — например, дискриминантный анализ, оперирующий обобщённой дисперсией и ковариацией наблюдаемой статистики, или байесовские классификаторы. Базовые виды нейросетей, такие как перцептрон и многослойный перцептрон (а также их модификации), могут обучаться как с учителем, так и без учителя, с подкреплением и самоорганизацией. Но некоторые нейросети и большинство статистических методов можно отнести только к одному из способов обучения. Поэтому, если нужно классифицировать методы машинного обучения в зависимости от способа обучения, будет некорректным относить нейросети к определенному виду, правильнее было бы типизировать алгоритмы обучения нейронных сетей.
Обучение с учителем — для каждого прецедента задаётся пара «ситуация, требуемое решение»:
-
Искусственная нейронная сеть
- Глубокое обучение
- Метод коррекции ошибки
- Метод обратного распространения ошибки
- Метод опорных векторов
Обучение без учителя — для каждого прецедента задаётся только «ситуация», требуется сгруппировать объекты в кластеры, используя данные о попарном сходстве объектов, и/или понизить размерность данных:
- Альфа-система подкрепления
- Гамма-система подкрепления
- Метод ближайших соседей
Обучение с подкреплением — для каждого прецедента имеется пара «ситуация, принятое решение»:
- Генетический алгоритм.
- Активное обучение — отличается тем, что обучаемый алгоритм имеет возможность самостоятельно назначать следующую исследуемую ситуацию, на которой станет известен верный ответ:
- Обучение с частичным привлечением учителя (англ. semi-supervised learning) — для части прецедентов задается пара «ситуация, требуемое решение», а для части — только «ситуация»
- Трансдуктивное обучение (англ. transduction (machine learning)) — обучение с частичным привлечением учителя, когда прогноз предполагается делать только для прецедентов из тестовой выборки
- Многозадачное обучение (англ. multi-task learning) — одновременное обучение группе взаимосвязанных задач, для каждой из которых задаются свои пары «ситуация, требуемое решение»
- Многовариантное обучение (англ. multiple-instance learning) — обучение, когда прецеденты могут быть объединены в группы, в каждой из которых для всех прецедентов имеется «ситуация», но только для одного из них (причем, неизвестно какого) имеется пара «ситуация, требуемое решение»
- Бустинг (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
- Байесовская сеть
Инструменты для сбора, обработки и визуализации данных
Здесь мы собираем данные с различных сайтов и создаём датасет, который потом используем для обучения алгоритма. Сбор данных с сайтов ещё называют веб-скрейпингом (ранее мы подробно рассказывали об инструментах для веб-скрейпинга).
После того, как собрали данные, их нужно обработать, чтобы избавиться от ошибок, шума и несогласованностей, которые приведут к ситуации «мусор на входе — мусор на выходе»
Это очень важно, так как от корректности данных будет зависеть точность результатов алгоритма
Конференция DataArt IT NonStop 2020
3–5 декабря, Онлайн, До 1500 ₽
tproger.ru
События и курсы на tproger.ru
Визуализация поможет определить линейность структуры данных, существенные признаки и аномалии. Для этих задач можно воспользоваться готовыми веб-сервисами, либо написать собственный код.
После того как мы почистили наш датасет, нужно поделить его на 80% — для обучения модели, — и 20% — для её проверки и тестирования.
pandas: библиотека для обработки и анализа данных
Она построена поверх NumPy, о котором поговорим чуть дальше. Это наши группировки, сортировки, извлечения и трансформации. Для работы с файлами CSV, JSON и TSV pandas превращает их в структуру данных DataFrame со строками и столбцами. Выглядит, как обычная таблица в Excel, и работать с ней легче, чем с for-циклами для прохода по элементам списков и словарей.
Tableau, Power BI, Google Data Studio: простая онлайн-визуализация без кода
Инструменты для бизнес-аналитики и людей без особых навыков программирования. Ключевое слово здесь — визуализация. Загружаем датасет и пользуемся встроенными функциями, фильтрами и аналитикой в реальном времени. Эти сервисы быстро собирают инсайты и представляют их в наглядной форме. И Tableau, и Power BI, и Google Data Studio имеют как платные подписки, так и бесплатные версии (само собой, с ограничениями).
Matplotlib: библиотека для построения 2D-графиков
Matplotlib в связке с библиотеками seaborn, ggplot и HoloViews позволяет строить разнообразные графики: гистограммы, диаграммы рассеяния, круговые и полярные диаграммы, и много других. Для большинства из них достаточно написать всего пару строк.
Обучение с учителем
Методы обучения с учителем применяются тогда, когда для имеющихся объектов обучающей выборки мы знаем так называемые ответы, а для новых объектов мы хотим их предсказать. Ответы также называются зависимой переменной. В этом классе задач в свою очередь выделяется несколько типов.
В первом типе ответами являются значения некоторой численной величины, как было в нашей истории с кофе: для каждого объекта обучающей выборки мы знали количество выпитого кофе, а для нового объекта Никиты модель это значение предсказывала. Этот тип задач, когда зависимая переменная является вещественным числом (то есть может принимать любые значения на всей числовой прямой), называется задачей регрессии.
В задачах второго типа ответы принадлежат ограниченному набору возможных категорий (или классов). Продолжим наши офисные аналогии: представьте, что офис-менеджер Михаил закупил два вида подарков для коллег к Новому году – футболки и блокноты. Чтобы не испортить сюрприз, Михаил хочет построить модель, которая предсказывала бы, какой подарок хочет получить сотрудник, на основе данных из личных профилей (внимательный читатель заметит, что в реальности для построения модели Михаилу все же пришлось бы спросить о желаемом подарке у части коллег, чтобы сформировать обучающую выборку). Такой тип задач, когда необходимо относить объекты к одной из нескольких возможных категорий, то есть когда зависимая переменная принимает конечное число значений, называется задачей классификации. Пример с подарками относится к бинарной классификации: классов всего два – «футболки» и «блокноты»; в противном случае, когда классов больше, говорят о многоклассовой классификации.
Пожалуй, самый актуальный пример классификации – задача кредитного скоринга. Принимая решение, выдать вам кредит или нет, ваш банк ориентируется на предсказание модели, натренированной по множеству признаков определять, способны ли вы вернуть запрашиваемую сумму. Такими признаками являются возраст, уровень заработной платы, различные параметры кредитной истории.
Еще один тип обучения с учителем – задача ранжирования. Она решается, когда вы ищете что-то в поисковике вроде : есть множество документов и необходимо отсортировать их в порядке их релевантности (смысловой близости) запросу.
10 . Бустинг и AdaBoost
Бустинг — это семейство ансамблевых алгоритмов, суть которых заключается в создании сильного классификатора на основе нескольких слабых. Для этого сначала создаётся одна модель, затем другая модель, которая пытается исправить ошибки в первой. Модели добавляются до тех пор, пока тренировочные данные не будут идеально предсказываться или пока не будет превышено максимальное количество моделей.
AdaBoost был первым действительно успешным алгоритмом бустинга, разработанным для бинарной классификации. Именно с него лучше всего начинать знакомство с бустингом. Современные методы вроде стохастического градиентного бустинга основываются на AdaBoost.
AdaBoost используют вместе с короткими деревьями решений. После создания первого дерева проверяется его эффективность на каждом тренировочном объекте, чтобы понять, сколько внимания должно уделить следующее дерево всем объектам. Тем данным, которые сложно предсказать, даётся больший вес, а тем, которые легко предсказать, — меньший. Модели создаются последовательно одна за другой, и каждая из них обновляет веса для следующего дерева. После построения всех деревьев делаются предсказания для новых данных, и эффективность каждого дерева определяется тем, насколько точным оно было на тренировочных данных.
Так как в этом алгоритме большое внимание уделяется исправлению ошибок моделей, важно, чтобы в данных отсутствовали аномалии
О принципах выбора лучшего алгоритма
Никогда не знаешь, какой алгоритм машинного обучения будет давать лучший результат на конкретных данных. Но, понимая задачу, можно определить набор наиболее подходящих алгоритмов, чтобы не перебирать все существующие. Выбор алгоритма машинного обучения, который будет использоваться для решения задачи, осуществляется через сравнение качества работы алгоритмов на обучающей выборке.
Что считать качеством алгоритма, зависит от задачи, которую вы решаете. Выбор метрики качества — отдельная большая тема. В рамках классификации заявок была выбрана простая метрика: точность (accuracy). Точность определяется как доля объектов в выборке, для которых алгоритм дал верный ответ (поставил верную категорию заявки)
Таким образом, мы выберем тот алгоритм, который будет давать бОльшую точность в предсказании категорий заявок.
Важно сказать о таком понятии, как гиперпараметр алгоритма. Алгоритмы машинного обучения имеют внешние (т.е
такие, которые не могут быть выведены аналитически из обучающей выборки) параметры, определяющие качество их работы. Например в алгоритмах, где требуется рассчитать расстояние между объектами, под расстоянием можно понимать разные вещи: манхэттенское расстояние, классическую евклидову метрику и т.д.
У каждого алгоритма машинного обучения свой набор гиперпараметров. Выбор лучших значений гиперпараметров осуществляется, как ни странно, перебором: для каждой комбинации значений параметров вычисляется качество алгоритма и далее для данного алгоритма используется лучшая комбинация значений. Процесс затратный с точки зрения вычислений, но куда деваться.
Для определения качества алгоритма на каждой комбинации гиперпараметров используется кросс-валидация. Поясню, что это такое. Обучающая выборка разбивается на N равных частей. Алгоритм последовательно обучается на подвыборке из N-1 частей, а качество считается на одной отложенной. В итоге каждая из N частей 1 раз используется для подсчета качества и N-1 раз для обучения алгоритма. Качество алгоритма на комбинации параметров считается как среднее между значениями качества, полученными при кросс-валидации. Кросс-валидация необходима для того, чтобы мы могли больше доверять полученному значению качества (при усреднении мы нивелируем возможные “перекосы” конкретного разбиения выборки). Чуть подробнее сами знаете где.
Итак, для выбора наилучшего алгоритма для каждого алгоритма:
- Перебираются все возможные комбинации значений гиперпараметров (у каждого алгоритма свой набор гиперпараметров и их значений);
- Для каждой комбинации значений гиперпараметров с использование кросс-валидации вычисляется качество алгоритма;
- Выбирается тот алгоритм и с той комбинацией значений гиперпараметров, что показывает наилучшее качество.
С точки зрения программирования описанного выше алгоритма нет ничего сложного. Но и в этом нет потребности. В библиотеке Scikit-learn есть готовый метод подбора параметров по сетке (метод GridSearchCV модуля grid_search). Все что нужно — передать в метод алгоритм, сетку параметров и число N (количество частей, на которые разбиваем выборку для кросс-валидации; их ещё называют «folds»).
В рамках решения задачи было выбрано 2 алгоритма: k ближайших соседей и композиция случайных деревьев. О каждом из них рассказ далее.
Машинное обучение в Python это не сложно
Проработайте примеры из урока, это не займет дольше 10-15 минут.
Вам не обязательно сразу все понимать. Ваша цель состоит в том, чтобы запустить ряд скриптов описанных в уроке и получить конечный результат. Вам не нужно понимать все при первом проходе. Записывайте свои вопросы параллельно с тем как пишите код. Рекомендуем использовать справку («FunctionName») в Python чтобы разобраться глубже во всех функциях, которые вы используете.
Вам не нужно знать, как работают алгоритмы
Важно знать об ограничениях и о том, как настроить алгоритмы машинного обучения. Более подробное узнать о конкретных алгоритмах можно и позже
Вы должны постепенно накапливать знания о работе алгоритмы. Сегодня, начните с того что поймете как его использовать в Python.
Вам не нужно быть программистом Python. Синтаксис языка Python может быть интуитивно понятным, даже если вы новичок в нем. Как и на других языках, сосредоточьтесь на вызовах функций (например,function()) и назначениях (например, a = «b»). Если вы являетесь разработчиком, вы итак уже знаете, как подобрать основы языка очень быстро.
Вам не нужно быть экспертом по машинного обучению
Вы можете узнать о преимуществах и ограничениях различных алгоритмов гораздо позже, и есть много информации в интернете, о более глубинных тонкостях алгоритмов и этапах проекта машинного обучения и важности оценки точности с помощью перекрестной валидации
Как из четырёх минут речи мы воссоздали голос молодого Леонида Куравлёва
Всем привет! Меня зовут Олег Петров, я руковожу группой R&D в Центре речевых технологий. Мы давно работаем не только над распознаванием речи, но и умеем синтезировать голоса. Самый простой пример, для чего это нужно бизнесу: чтобы для каждого нового сценария, которому обучают голосовых роботов, не нужно было организовывать новую запись с человеком, который его когда-то озвучил. Ещё мы развиваем продукты на основе голосовой и лицевой биометрии и аналитики по голосовым данным. В общем, работаем над серьёзными и сложными задачами для разного бизнеса.
Но недавно к нам пришли коллеги из Сбера с предложением поучаствовать в развлекательной истории — «озвучить» героя Леонида Куравлёва в новом ролике. Для него лицо Куравлева было воссоздано по кадрам из фильма «Иван Васильевич меняет профессию» и наложено на лицо другого актера с помощью технологии Deepfake. Чтобы мы смогли не только увидеть, но и услышать в 2020 году Жоржа Милославского, мы решили помочь коллегам. Ведь с годами голос у всех нас меняется и даже если бы Леонид Вячеславович озвучил героя, эффект был бы не тот.
Под катом я расскажу, почему эта, уже во многом привычная задача голосового синтеза, оказалась чуть сложнее, чем мы ожидали, и поясню, почему такие голоса не смогут обмануть качественные системы биометрической авторизации.
Тестируем комплементарную кросс-энтропию в задачах классификации текста
Ранее в этом году И. Ким совместно с соавторами опубликовали статью , в которой предложили новую функцию потерь для задач классификации. По оценке авторов, с её помощью можно улучшить качество моделей как в сбалансированных, так и в несбалансированных задачах классификации в сочетании со стандартной кросс-энтропией.
Классификация бывает необходима, например, при создании рекомендательных систем, поэтому описанный метод интересен как с академической точки зрения, так и в контексте решения бизнес-задач.
В нашей статье мы проверим, как комплементарная кросс-энтропия влияет на задачу классификации текста на несбалансированном наборе данных. Наша цель заключается не в проведении широкого экспериментального исследования или создании решения, готового к применению, а в оценке его перспектив
Просим обратить внимание, что код, описанный в статье, может не подходить для применения на проекте и требовать определенной доработки
Как посмотреть плоские фильмы в 3D
Это сильно расширенная версия моей публикации на Medium
Недавно я сидел в баре с другом зашел разговор о том, в каких задачах в принципе может быть эффективен нейросетевой подход, а где они совершенно излишни. Один класс примеров, где нейросети часто наголову превосходят классические алгоритмы — обработка изображений. Точность решения задачи распознования объектов на изображении может даже превосходить человеческое восприятие. Кроме того, интересны и задачи переноса стиля, генерации реалистичных изображений, superresolution итд. Нейросети могут быть очень эффективны также в задачах типа pixtopix, когда происходит генерация одного изображения из другого. Тогда у меня и возникла идея попробовать применить данные алгоритмы для преобразования 2d фильмов в 3d.