Заголовки http
Содержание:
- Что значит и где применяется HTTPS-протокол?
- Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
- Почему REST?
- Постскриптум.
- GET Method
- SPDY — 2009
- Формат ответа
- Методы HTTP
- Пример программы
- HTTP GET
- HTML Справочник
- HTML Теги
- Коды состояния
- Examples
- Perform a GET request and get the body of the response
- Adding query parameters
- Using arrays as query parameters
- Working with request/response headers
- Perform a multipart POST request
- Perform a POST request with form data
- Post contents of a file
- Using entity tags for caching
- Using gzip compression
- Ignoring security when using HTTPS
- Configuring an HTTP proxy
- Custom connection factory
- 3.2 Content-Type: multipart/form-data
Что значит и где применяется HTTPS-протокол?
Ну, про обмен данными по протоколу HTTP вы уже все знаете: любая передача данных осуществляется через запросы по этому протоколу-транспорту. А зачем тогда нужен HTTPS и что он из себя представляет? Ведь жили же нормально и без него?
Проблема в том что данные по HTTP не защищаются и передаются в открытом виде. Интернет — глобальная распределенная сеть узлов. И если вы передаете открытые данные по незащищенному протоколу (Wi-Fi в ТРЦ сюда тоже относится), то один из этих узлов может перехватить их.
Не специально конечно, может быть просто взлом усилиями злоумышленников. HTTPS и создан для того чтобы соединение было безопасным, а данные передавались в зашифрованном виде по криптографическому протоколу SSL/TLS. Это специальная «обертка» поверх HTTP, она шифрует данные, делая их недоступными для злоумышленников и посторонних людей.
HTTPS — англ. «безопасный протокол передачи гипертекста».
Так что в отличие от 80 порта, используемого по умолчанию в HTTP, в HTTPS используется TCP-порт 443 и есть ключ для шифрования. Ключ может быть длиной 40, 56, 128 или 256 бит, достаточный уровень безопасности на данный момент начинается со 128-битных ключей.
Сейчас все браузеры поддерживают HTTPS — он включается автоматически, когда есть возможность и этого требует сервер.
Жизненно важно использовать HTTPS в следующих сервисах:
- Электронные платежные системы (банки, электронные деньги и прочее);
- Сервисы принимающие и отправляющие приватную информацию и персональные данные, например у Яндекса это: Паспорт, Такси, Директ, Метрика, Почта, Деньги, Вебмастер и другие;
- Социальные сети и личные кабинеты в интернет-сервисах;
- Поисковые системы.
Работает HTTPS просто. Объясню на примере.
Вы кладете важную информацию (логин, пароль, данные карты, персональные данные) в ячейку, «запираете ее на ключ»: ячейка шифрует ваши данные при помощи этого ключа.
Теперь отправляете ее почтой адресату. Адресат получает ячейку-посылку, но открыть ее не может — у него нет ключа. Тогда он запирает (шифрует) ячейку на второй замок и возвращает посылку вам обратно. Вы получаете посылку с двумя замками, при этом ключ к одному у вас есть. Теперь можно отпереть свой замок (расшифровать данные) и отправить посылку обратно еще раз — первоначальному адресату.
Данные при этом остаются защищенными — ведь они никем не просматривались и не менялись и до момента получения адресатом находятся под защитой зашифрованного им ключа. Адресат получает посылку, уже с одним замком, расшифровывает ее и обрабатывает ваши данные. Например, проводит вашу транзакцию.
Все — вот так просто работает HTTPS.
Фишка тут в том, что при первом таком обмене происходит обмен ключом шифрования, чтобы он был известен обоим конечным адресатам, но не известен ни одному из узлов по маршруту следования данных. После обмена шифром можно свободно обмениваться сообщениями (зашифрованными) без опасений о перехвате этих данных, ведь без ключа-шифра открыть и прочитать их не удастся.
Единственный нюанс здесь — надо знать, что вы отправляете данные именно туда, куда нужно. И что конечный пункт и является пунктом назначения. Но нужно подтвердить и точно знать, что конечный адресат существует и управляется тем самым сервером, куда отправляются данные.
Для этого серверы получают в центрах сертификации специальные HTTPS-сертификаты безопасности, которые подтверждают «конечность» пункта назначения (что сайт не является узлом передающим данные дальше) и работоспособность технологии шифрования SSL/TLS, т.е. безопасность соединения.
А вот как выглядит сам сертификат:
На текущий момент HTTPS встроен во все современные браузеры и все что требуется от пользователя для поддержания безопасности отправки данных по HTTPS — регулярно обновлять программное обеспечение для серфинга, приема и отправки важных данных в интернете.
Осуществляя взаимодействие «клиент-сервер» по протоколу HTTPS можно не беспокоиться за сохранность данных — вы надежно защищены от прослушивания сетевого соединения: атак снифферов и man-in-the-middle.
Что означает перечеркнутый значок HTTPS и зеленый значок HTTPS, в чем разница? В безопасности. Зеленый — безопасный, красный и перечеркнутый — небезопасный.
И очень удобно, что перечеркнутый значок HTTPS означает, что несмотря на использование этого протокола, соединение не безопасное. Так происходит когда элементы сайта подгружаются не по HTTPS или истек срок действия сертификата. Пользователю сразу видно — ага, небезопасно. И он может уйти с сайта, либо рисковать своими данными.
Конструктор мобильного клиента Simple WMS Client: способ создать полноценный ТСД без мобильной разработки. Теперь новая версия — Simple UI (обновлено 14.11.2019)
Simple WMS Client – это визуальный конструктор мобильного клиента для терминала сбора данных(ТСД) или обычного телефона на Android. Приложение работает в онлайн режиме через интернет или WI-FI, постоянно общаясь с базой посредством http-запросов (вариант для 1С-клиента общается с 1С напрямую как обычный клиент). Можно создавать любые конфигурации мобильного клиента с помощью конструктора и обработчиков на языке 1С (НЕ мобильная платформа). Вся логика приложения и интеграции содержится в обработчиках на стороне 1С. Это очень простой способ создать и развернуть клиентскую часть для WMS системы или для любой другой конфигурации 1С (УТ, УПП, ERP, самописной) с минимумом программирования. Например, можно добавить в учетную систему адресное хранение, учет оборудования и любые другие задачи. Приложение умеет работать не только со штрих-кодами, но и с распознаванием голоса от Google. Это бесплатная и открытая система, не требующая обучения, с возможностью быстро получить результат.
5 стартмани
Почему REST?
REST — простой способ организации взаимодействия между независимыми системами. Он пользуется популярностью с 2005 года и вдохновляет дизайн сервисов, таких как API Twitter. Благодаря тому, что REST обеспечивает взаимодействие с такими разнообразными клиентами, как мобильные телефоны и другие веб-сайты. Теоретически, REST не привязан к сети, но почти всегда реализован как таковой и был вдохновлен HTTP. В результате REST можно использовать везде, где возможен HTTP.
Альтернативой является создание относительно сложных соглашений поверх HTTP. Часто это принимает форму новых XML-языков. Самый яркий пример — SOAP. Вам нужно выучить совершенно новый набор соглашений, но вы никогда не используете HTTP в полную силу. Поскольку REST был вдохновлён HTTP и играет на его сильные стороны, это лучший способ узнать, как работает HTTP.
После первоначального обзора мы рассмотрим каждый из строительных блоков HTTP: URL-адреса, HTTP-команды и коды ответов. Мы также рассмотрим, как использовать их в RESTful. Попутно мы проиллюстрируем теорию примером приложения, которое имитирует процесс отслеживания данных, связанных с клиентами компании через веб-интерфейс.
Постскриптум.
Думаю, что о передаче запросов на сервер не стоит рассказывать подробно. Это уже дело чисто РНР техники :-). Достаточно внимательно прочитать раздел о функциях работы с сокетами, или о функциях модуля CURL в официальной документации РНР.
Из выше сказанного, надеюсь теперь понятно, почему вопрос: «Как мне сформировать POST запрос, используя функцию header?» бессмысленен. Функция header(string) добавляет запись только в заголовок запроса, но никак не в тело запроса.
Есть еще один тип запросов Content-Type: multipart/mixed, надеюсь после прочтения данной статьи Вы легко разберетесь с данным типом сами. Подробно изучить его можно Здесь
О запросах других типов можно прочитать в официальной спецификации протокола HTTP 1.0 здесь.
GET Method
A GET request retrieves data from a web server by specifying parameters in the URL portion of the request. This is the main method used for document retrieval. The following example makes use of GET method to fetch hello.htm:
GET /hello.htm HTTP/1.1 User-Agent: Mozilla/4.0 (compatible; MSIE5.01; Windows NT) Host: www.tutorialspoint.com Accept-Language: en-us Accept-Encoding: gzip, deflate Connection: Keep-Alive
The server response against the above GET request will be as follows:
HTTP/1.1 200 OK Date: Mon, 27 Jul 2009 12:28:53 GMT Server: Apache/2.2.14 (Win32) Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT ETag: "34aa387-d-1568eb00" Vary: Authorization,Accept Accept-Ranges: bytes Content-Length: 88 Content-Type: text/html Connection: Closed
<html> <body> <h1>Hello, World!</h1> </body> </html>
SPDY — 2009
Google пошёл дальше и стал экспериментировать с альтернативными протоколами, поставив цель сделать веб быстрее и улучшить уровень безопасности за счёт уменьшения времени задержек веб-страниц. В 2009 году они представили протокол SPDY.
Казалось, что если мы будем продолжать увеличивать пропускную способность сети, увеличится её производительность. Однако выяснилось, что с определенного момента рост пропускной способности перестаёт влиять на производительность. С другой стороны, если оперировать величиной задержки, то есть уменьшать время отклика, прирост производительности будет постоянным. В этом и заключалась основная идея SPDY.
SPDY включал в себя мультиплексирование, сжатие, приоритизацию, безопасность и т.д… Я не хочу погружаться в рассказ про SPDY, поскольку в следующем разделе мы разберём типичные свойства HTTP/2, а HTTP/2 многое перенял от SPDY.
SPDY не старался заменить собой HTTP. Он был переходным уровнем над HTTP, существовавшим на прикладном уровне, и изменял запрос перед его отправкой по проводам. Он начал становиться стандартом дефакто, и большинство браузеров стали его поддерживать.
В 2015 в Google решили, что не должно быть двух конкурирующих стандартов, и объединили SPDY с HTTP, дав начало HTTP/2.
Формат ответа
Формат ответа отличается только статусом и рядом заголовков. Статус выглядит так:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
- HTTP версия
- Код статуса
- Сообщение статуса, понятное для человека
Обычный статус выглядит примерно так:
HTTP/1.1 200 OK
Заголовки ответа могут быть следующими:
response-header = Accept-Ranges
| Age
| ETag
| Location
| Proxy-Authenticate
| Retry-After
| Server
| Vary
| WWW-Authenticate
- Age время в секундах, когда сообщение было создано на сервере.
- ETag MD5 сущности для проверки изменений и модификаций ответа.
- Location используется для перенаправления и содержит новый URL адрес.
- Server определяет сервер, где было сформирован ответ.
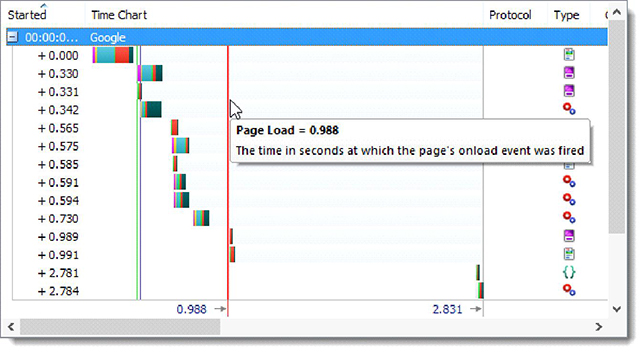
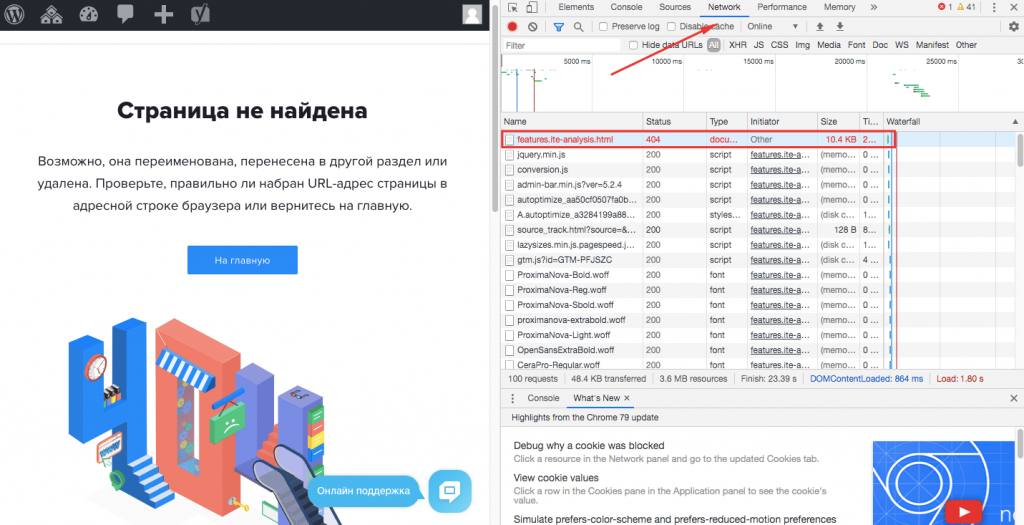
Думаю, на сегодня теории достаточно. Теперь давайте взглянем на инструменты, которыми мы можем пользоваться для мониторинга HTTP сообщений.
Методы HTTP
— getById
В случае успеха сервер возвращает с полями объекта в формате JSON в теле ответа (без дополнительного оборачивания в какой-либо объект)
В случае, если объект с такими id не существует, сервер возвращает
В ответе обязательно должны быть заголовки, касающиеся политики кэширования, т.к. браузеры активно кешируют GET и HEAD запросы. При остутствии какой-либо политики управления кэшем должно быть:
— списочный get
Простой случай: в случае успеха сервер возвращает с массивом объектов в формате JSON в теле ответа (т.е. ответ начинается с и заканчивается ).
Если массив получился пустой, всё равно вовзращается с пустым масивом в теле ответа.
Более сложный вариант: возвращается объект, в одном из полей которого — искомый массив. В остальных полях — данные о пагинации, фильтры, счётчики и пр. Только держите это консистентным по всем api.
— запрос заголовков
Полный аналог GET с таким же URI, но не возвращает тело ответа, а только HTTP-заголовки.
Реализация поддержки HEAD запросов веб-сервером обязательна.
Активно используется браузерами в качестве автоматических pre-flight запросов перед выполнением потенциально опасных, по их мнению, операций. Например, браузер Chrome активно кидается head-запросами для получения политик CORS при кросс-доменных операциях (виджеты и пр). При этом ошибка обработки такого head-запроса приведёт к тому, что основной запрос вообще не будет выполнен браузером.
Может использоваться для проверки существования объекта без его передачи (например, для больших объектов типа мультимедиа-файлов).
— создаёт новый объект типа :entity
В теле запроса должны быть перечислены поля объекта в формате JSON без дополнительного заворачивания, т.е.
В случае успеха сервер должен возвращать с пустым телом, но с дополнительным заголовком
указывающим на месторасположение созданного объекта.
Возвращать тело ответа чаще всего не требуется, так как у клиента есть все необходимые данные, а id созданного объекта он может получить из Location.
Также метод POST используется для удалённого вызова процедур (RPC), в этом случае ответ будет иметь статус и результаты в теле. Вообще смешивать REST и RPC в одном api — идея сомнительная, но всякое бывает.
Единственный неидемпотентный некешируемый метод, т.е. повтор двух одинаковых POST запросов создаст два одинаковых объекта.
— изменяет объект целиком
В запросе должны содержаться все поля изменяемого объекта в формате JSON.
В случае успеха должен возвращать с пустым телом, т.к. у клиента есть все необходимые данные.
Идемпотентный запрос, т.е. повторный PUT с таким же телом не приводит к каким-либо изменениям в БД.
— изменяет отдельные поля объекта
В запросе должны быть перечислены только поля, подлежащие изменению.
В случае успеха возвращает с телом, аналогичным запросу getById, со всеми полями изменённого объекта.
Используется с осторожностью, т.к. два параллельных PATCH от двух разных клиентов могут привести объект в невалидное состояние
Идемпотентный запрос.
— удаляет объект, если он существует.
В случае успеха возвращает с пустым телом, т.к. возвращать уже нечего.
Идемпотентный запрос, т.е. повторный DELETE с таким же адресом не приводит к ошибке 404.
Получает список методов, доступных по данному URI.
Сервер должен ответить с дополнительным заголовком
Некешиуремый необязательный метод.
Пример программы
Здесь мы приведем только код функций кнопок с сетевыми запросами, а весь код программы для удобства мы разместили в репозитории сервиса GitHub
- https://github.com/flutter-tutorial/test_http — репозиторий
- github.com/flutter-tutorial/test_http/blob/master/lib/main.dart — основной код программы, при необходимости можно просмотреть без загрузки репозитория целиком
_sendRequestGet() {
if(_formKey.currentState.validate()) {
_formKey.currentState.save();//запуск функции сохранения данных из формы в переменную _url
http.get(_url).then((response){
_status = response.statusCode;
_body = response.body;
setState(() {});//перестраиваем виджет окна для отображения изменений _status и _body
}).catchError((error){
_status = 0;
_body = error.toString();
setState(() {});//перестраиваем виджет окна в случае сетевой ошибки
});
}
}//_sendRequestGet
_sendRequestPost() async {
if(_formKey.currentState.validate()) {
_formKey.currentState.save();//запуск функции сохранения
try {
var response = await http.post(_url);
_status = response.statusCode;
_body = response.body;
} catch (error) {
_status = 0;
_body = error.toString();
}
setState(() {});//перестраиваем виджет окна
}
}//_sendRequestPost
_sendRequestPostBodyHeaders() async {
if(_formKey.currentState.validate()) {
_formKey.currentState.save();//запуск функции
try {
var response = await http.post(_url,
body: {‘name’:’test’,’num’:’10’},
headers: {‘Accept’:’application/json’}
);
_status = response.statusCode;
_body = response.body;
} catch (error) {
_status = 0;
_body = error.toString();
}
setState(() {});//перестраиваем виджет окна
}
}//_sendRequestPost
Скопируйте репозиторий с помощью командыgit clone https://github.com/flutter-tutorial/test_http.gitили скачайте как zip архив.
Так как в репозитории нет всех файлов для построения android и ios приложения, выполните команду, после загрузки, как при создании нового проекта:flutter create test_httptest_http — имя директории скопированного проекта.
Если вы скопировали проект в Android Studio, то после команды «flutter create …», необходимо нажать на кнопку Restart Dart Analysis Server, иначе ошибки не убрать.
Подробнее про копирование существующих Flutter проектов с помощью git, мы опишем в отдельном уроке.


В следующем уроке по HTTP запросам мы рассмотрим создание своего пакета для сетевого общения с сервером, и посмотрим как заменить http.post, http.get и т.д.
HTTP GET
Use GET requests to retrieve resource representation/information only – and not to modify it in any way. As GET requests do not change the state of the resource, these are said to be safe methods. Additionally, GET APIs should be idempotent, which means that making multiple identical requests must produce the same result every time until another API (POST or PUT) has changed the state of the resource on the server.
If the Request-URI refers to a data-producing process, it is the produced data which shall be returned as the entity in the response and not the source text of the process, unless that text happens to be the output of the process.
For any given HTTP GET API, if the resource is found on the server, then it must return HTTP response code – along with the response body, which is usually either XML or JSON content (due to their platform-independent nature).
In case resource is NOT found on server then it must return HTTP response code . Similarly, if it is determined that GET request itself is not correctly formed then server will return HTTP response code .
Example request URIs
- HTTP GET http://www.appdomain.com/users
- HTTP GET http://www.appdomain.com/users?size=20&page=5
- HTTP GET http://www.appdomain.com/users/123
- HTTP GET http://www.appdomain.com/users/123/address
HTML Справочник
HTML Теги по алфавитуHTML Теги по категорииHTML АтрибутыHTML Глобальные атрибутыHTML Атрибуты событийHTML ЦветаHTML CanvasHTML Аудио/ВидеоHTML Наборы символовHTML DoctypeHTML URL кодированиеHTML Коды языковHTML Коды странHTTP СообщенияHTTP МетодыPX в EM КонвертерГорячие клавиши
HTML Теги
<!—>
<!DOCTYPE>
<a>
<abbr>
<acronym>
<address>
<applet>
<area>
<article>
<aside>
<audio>
<b>
<base>
<basefont>
<bdi>
<bdo>
<big>
<blockquote>
<body>
<br>
<button>
<canvas>
<caption>
<center>
<cite>
<code>
<col>
<colgroup>
<data>
<datalist>
<dd>
<del>
<details>
<dfn>
<dialog>
<dir>
<div>
<dl>
<dt>
<em>
<embed>
<fieldset>
<figcaption>
<figure>
<font>
<footer>
<form>
<frame>
<frameset>
<h1> — <h6>
<head>
<header>
<hr>
<html>
<i>
<iframe>
<img>
<input>
<ins>
<kbd>
<label>
<legend>
<li>
<link>
<main>
<map>
<mark>
<meta>
<meter>
<nav>
<noframes>
<noscript>
<object>
<ol>
<optgroup>
<option>
<output>
<p>
<param>
<picture>
<pre>
<progress>
<q>
<rp>
<rt>
<ruby>
<s>
<samp>
<script>
<section>
<select>
<small>
<source>
<span>
<strike>
<strong>
<style>
<sub>
<summary>
<sup>
<svg>
<table>
<tbody>
<td>
<template>
<textarea>
<tfoot>
<th>
<thead>
<time>
<title>
<tr>
<track>
<tt>
<u>
<ul>
<var>
<video>
<wbr>
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
Examples
Perform a GET request and get the body of the response
String response = HttpRequest.get("http://google.com").body();
System.out.println("Response was: " + response);
Adding query parameters
HttpRequest request = HttpRequest.get("http://google.com", true, 'q', "baseball gloves", "size", 100);
System.out.println(request.toString()); // GET http://google.com?q=baseball%20gloves&size=100
Using arrays as query parameters
int[] ids = new int[] { 22, 23 };
HttpRequest request = HttpRequest.get("http://google.com", true, "id", ids);
System.out.println(request.toString()); // GET http://google.com?id[]=22&id[]=23
Working with request/response headers
String contentType = HttpRequest.get("http://google.com")
.accept("application/json") //Sets request header
.contentType(); //Gets response header
System.out.println("Response content type was " + contentType);
Perform a multipart POST request
HttpRequest request = HttpRequest.post("http://google.com");
request.part("status", "Making a multipart request");
request.part("status", new File("/home/kevin/Pictures/ide.png"));
if (request.ok())
System.out.println("Status was updated");
Perform a POST request with form data
Map<String, String> data = new HashMap<String, String>();
data.put("user", "A User");
data.put("state", "CA");
if (HttpRequest.post("http://google.com").form(data).created())
System.out.println("User was created");
Post contents of a file
File input = new File("/input/data.txt");
int response = HttpRequest.post("http://google.com").send(input).code();
File latest = new File("/data/cache.json");
HttpRequest request = HttpRequest.get("http://google.com");
//Copy response to file
request.receive(latest);
//Store eTag of response
String eTag = request.eTag();
//Later on check if changes exist
boolean unchanged = HttpRequest.get("http://google.com")
.ifNoneMatch(eTag)
.notModified();
Using gzip compression
HttpRequest request = HttpRequest.get("http://google.com");
//Tell server to gzip response and automatically uncompress
request.acceptGzipEncoding().uncompress(true);
String uncompressed = request.body();
System.out.println("Uncompressed response is: " + uncompressed);
Ignoring security when using HTTPS
HttpRequest request = HttpRequest.get("https://google.com");
//Accept all certificates
request.trustAllCerts();
//Accept all hostnames
request.trustAllHosts();
Configuring an HTTP proxy
HttpRequest request = HttpRequest.get("https://google.com");
//Configure proxy
request.useProxy("localhost", 8080);
//Optional proxy basic authentication
request.proxyBasic("username", "p4ssw0rd");
Custom connection factory
Looking to use this library with OkHttp?
Read here.
HttpRequest.setConnectionFactory(new ConnectionFactory() {
public HttpURLConnection create(URL url) throws IOException {
if (!"https".equals(url.getProtocol()))
throw new IOException("Only secure requests are allowed");
return (HttpURLConnection) url.openConnection();
}
public HttpURLConnection create(URL url, Proxy proxy) throws IOException {
if (!"https".equals(url.getProtocol()))
throw new IOException("Only secure requests are allowed");
return (HttpURLConnection) url.openConnection(proxy);
}
});
3.2 Content-Type: multipart/form-data
Как только интернет мир понял, что неплохо бы было через формы отсылать еще и файлы, так W3C консорциум взялся за доработку формата POST запроса. К тому времени уже достаточно широко применялся формат MIME (Multipurpose Internet Mail Extensions многоцелевые расширения протокола для формирования Mail сообщений), поэтому, чтобы не изобретать велосипед заново, решили использовать часть данного формата формирования сообщений для создания POST запросов в протоколе HTTP.
Каковы же основные отличия этого формата от типа application/x-www-form-urlencoded?
Главное отличие в том, что Entity-Body теперь можно поделить на разделы, которые разделяются границами (boundary). Что самое интересное каждый раздел может иметь свой собственный заголовок для описания данных, которые в нем хранятся, т.е. в одном запросе можно передавать данные различных типов (как в Mail письме Вы одновременно с текстом можете передавать файлы).
Итак, приступим. Рассмотрим опять все тот же пример с передачей логина и пароля, но теперь в новом формате.
POST http://www.site.ru/news.html HTTP/1.0Host: www.site.ruReferer: http://www.site.ru/index.htmlCookie: income=1Content-Type: multipart/form-data; boundary=1BEF0A57BE110FD467AContent-Length: 209
–1BEF0A57BE110FD467A Content-Disposition: form-data; name=»login» Petya Vasechkin –1BEF0A57BE110FD467A Content-Disposition: form-data; name=»password» qq –1BEF0A57BE110FD467A–
Теперь давайте разбираться в том что написано. Я специально выделил некоторые символы
жирным, чтобы они не сливались с данными. Присмотревшись внимательно можно заметить поле boundary после Content-Type. Это поле задает разделитель разделов границу. В качестве границы может быть использована строка, состоящая из латинских букв и цифр, а так же из еще некоторых символов (к сожалению, не помню каких еще). В теле запроса в начало границы добавляется ‘–‘, а заканчивается запрос границей, к которой символы ‘–‘ добавляются еще и в конец. В нашем запросе два раздела, первый описывает поле login, а второй поле password. Content-Disposition (тип данных в разделе) говорит, что это будут данные из формы, а в поле name задается имя поля. На этом заголовок раздела заканчивается и далее следует область данных раздела, в котором помещается значение поля (кодировать значение не требуется!).
Хочу обратить Ваше внимание та то, что в заголовках разделов не надо использовать Content-Length, а вот в заголовке запроса надо и его значение является размером всего Entity-Body, стоящего после второго
, следующего за Content-Length: 209. Т.е
Entity-Body отделяется от заголовка дополнительным переводом строки (что можно заметить и в разделах).
А теперь давайте напишем запрос для передачи файла.
POST http://www.site.ru/postnews.html HTTP/1.0Host: www.site.ruReferer: http://www.site.ru/news.htmlCookie: income=1Content-Type: multipart/form-data; boundary=1BEF0A57BE110FD467AContent-Length: 491
–1BEF0A57BE110FD467A Content-Disposition: form-data; name=»news_header» Пример новости –1BEF0A57BE110FD467A Content-Disposition: form-data; name=»news_file»; filename=»news.txt» Content-Type: application/octet-stream Content-Transfer-Encoding: binary А вот такая новость, которая лежит в файле news.txt –1BEF0A57BE110FD467A–
В данном примере в первом разделе пересылается заголовок новости, а во втором разделе пересылается файл news.txt. Внимательный да увидит поля filename и Content-Type во втором разделе. Поле filename задает имя пересылаемого файла, а поле Content-Type тип данного файла. Application/octet-stream говорит о том, что это стандартный поток данных, а Content-Transfer-Encoding: binary говорит на о том, что это бинарные данные, ничем не закодированные.
Очень важный момент. Большинство CGI скриптов написано умными людьми, поэтому они любят проверять тип пришедшего файла, который стоит в Content-Type. Зачем? Чаще всего закачка файлов на сайтах используется для получения картинок от посетителя. Так вот, браузер сам пытается определить что за файл посетитель хочет отправить и вставляет соответствующий Content-Type в запрос. Скрипт его проверяет при получении, и, например, если это не gif или не jpeg игнорирует данный файл. Поэтому при «ручном» формировании запроса позаботьтесь о значении Content-Type, чтобы оно было наиболее близким к формату передаваемого файла.
| image/gif | для gif |
| image/jpeg | для jpeg |
| image/png | для png |
| image/tiff | для tiff (что используется крайне редко, уж больно емкий формат) |
В нашем примере формируется запрос, в котором передается текстовый файл. Точно так же формируется запрос для передачи бинарного файла.