Дубли страниц
Содержание:
- Как найти дубли страниц на сайте
- О неуникальном контенте
- Как проверить сайт на дубли страниц?
- Поиск дублей страниц на сайте и удаление
- Как убрать дубли страниц на сайте
- Виды дублей страниц на сайте
- В чем опасность дублей
- Как избавиться от дубликатов страниц: основные виды и методы
- Почему нужно избавляться от дублей страниц на сайте
- Последствия дублированного контента
- Как найти дубли страниц?
- Как удалить дубли страниц
Как найти дубли страниц на сайте

Поняв, что такое дубли и чем грозит их появление на сайте, надо научиться их находить, чтобы потом удалить. Рассмотрим несколько способов поиска дубликатов.
-
Как выявить дубли страниц сайта, подскажут сами поисковики. Для Google достаточно указать в расширенном поиске адрес главной страницы, чтобы он выдал проиндексированный объем. Если же в поисковой строке задать адрес документа, который хотелось бы проверить, то система выложит перечень дублей, попавших в индексацию. В этом отношении работать с «Яндексом» проще: поисковик сразу показывает все копии проиндексированных страниц.
Если на вашем ресурсе много документов, для ускорения процесса анализа разбейте их на категории — товарные карточки, статьи в блоге, новости и так далее.
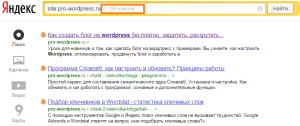
Если вы считаете, что дубли имеет конкретная страница, то на помощь придет поисковый запрос, сформированный из определенного фрагмента текста. Он складывается следующим образом: часть текста берется в кавычки, затем ставится пробел и оператор «site:». Здесь надо указать ваш сайт, на котором будет работать поисковый алгоритм. Например:
«Фрагмент текста со страницы сайта, которая может иметь дубли» site:examplesite.net
Если ваши сомнения не оправдались, то результатом станет та самая страница, которую вы подозревали в наличии дубликатов. Несколько документов, выданные в результате поиска, заставят задуматься о причинах размещения на них одинакового контента. Либо это и есть ожидаемые дубли, которые надо удалить.
Точно так же можно проанализировать сайт с помощью оператора «intitle:», который сравнит содержимое «Title» на представленных в выдаче страницах. Одинаковые метатеги могут быть признаком дубликата — проверить это можно с помощью поискового оператора «site:»:
site:examplesite.net intitle:полный или частичный текст тега Title.
Также с помощью операторов «site» и «inurl» вылавливаются продублированные документы, возникшие на страницах сортировок (sort) или при работе фильтров и поиска (filter, search). Чтобы найти, например, все страницы сортировок, надо задать в поисковой строке: site:examplesite.net inurl:sort. А для поиска страниц фильтров и поиска — site:examplesite.net inurl:filter, search.
Этот метод поиска ориентирован только на дубли, которые были проиндексированы системой. Поэтому полной гарантии того, что обнаружены все копии, он не дает.
- Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли, но только с полным совпадением. Для этого в специальную строку надо ввести URL сайта. Частичные повторы программа отследить не сможет.
- Полные дубли можно обнаружить при помощи инструментов web-мастерской Google. Для этого надо в ней зарегистрироваться, и тогда в разделе «Оптимизация Html» появится перечень страниц с повторяющимся контентом и метатегами <Title>. Полностью дублированные документы в нём хорошо видны, но разделы с частичным совпадением определить невозможно.
-
Онлайн-seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. В неё входит и блок для распознавания и анализа дублируемого контента. Сервис способен найти полные дубликаты Title, Description, H1 на нескольких страницах. Он успешно распознает совпадение H1 и Title, замечает, когда на одной странице ошибочно прописали два метатега Title и не один заголовок формата H1.
Для работы с сервисом Serpstat надо в нём зарегистрироваться и открыть проект для технического аудита сайта.
- Использование поисковых операторов. Для поиска дублей среди открытых для индексации страниц удобно использовать оператор «site:». Если ввести в строку поисковика (Google или «Яндекс») запрос «site:examplesite.net», то в общем индексе выйдут все страницы сайта. Их количество может сильно отличаться от найденных спайдером или от числа страниц в XML-карте. Проанализировав список выдачи, можно обнаружить и дублируемые, и мусорные разделы, которые необходимо закрыть от индексации.
О неуникальном контенте
Поскольку контент является ключевым элементом хорошего SEO, многие пытались манипулировать результатом поисковой выдачи с помощью старого доброго метода “копировать и вставить”, т.е. забирали контент на свой сайт с других сайтов
Поисковые системы, как правило, наказывают за такой метод, поэтому он должен использоваться с осторожностью, а лучше не использоваться вовсе
Но, если вы создали не уникальный контент на сайте, не сходите с ума! Ниже мы рассмотрим, как поисковые системы относятся к дубликату контента, и я поделюсь несколькими советами, которые вы можете применить, чтобы убедиться, что содержание вашего сайта свежее и уникальное.
Чтобы лучше понимать как, например, Google обрабатывает дублированный контент, вам нужно ознакомится с их мануалом https://support.google.com/webmasters/answer/66359?hl=ru Если вы боитесь получить фильтр за дублированный контент, позвольте я вас успокою и приведу цитату из данной справки
Вот и все, Google сообщает, что сайт не попадет под фильтр за дублированный контент, если вы не вводите пользователей в заблуждение. Но, если на сайте присутствуют дубли, то нужно разобраться, что это за дубли и решить эту проблему. Существует несколько типов дублированного контента:
- Полный дубль – два разных URL’а имеют одинаковый контент
- Частичный дубль – контент на разных страницах имеет мало отличий друг от друга
- Дубли с других доменов – полный или частичный дубль с другими сайтами (доменами).
Дублированный контент может получится в связи с разными ситуациями. Неправильная структура сайта, которая порождает полные или частичные дубли на разных страницах, лицензионное соглашение выбранной CMS, которое может находиться на разных сайта, шаблонные страницы, такие как публичная оферта, тексты законов и так далее.
Каждая из этих проблем имеет свои пути решения. Прежде чем приступить к решению этой проблемы, рассмотрим последствия наличие дублей страниц для сайта.
Как проверить сайт на дубли страниц?
Практика показывает, что отечественный поисковик Яндекс относится к дублям не так строго, как зарубежный Гугл. Однако и он не оставляет такие ошибки вебмастеров без внимания, поэтому для начала нужно разобраться с тем, как найти дубликаты страниц.
Как видим, Яндекс нашел 196 проиндексированных страниц. Теперь проделаем то же самое с Google.
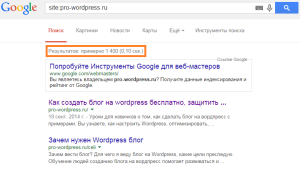
Мы получили 1400 страниц в общем индексе Гугл. Кроме основных страниц, участвующих в ранжировании, сюда попадают так называемые «сопли». Это дубли, либо малозначимые страницы. Чтобы проверить основной индекс в Google, нужно ввести другой оператор: site:pro-wordpress.ru/&
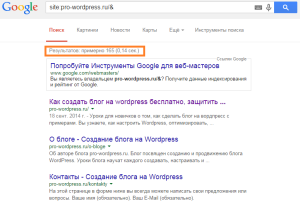
Итого в основном индексе 165 страниц. Как видим, у моего блога есть проблема с количеством дублей. Чтобы их увидеть, нужно перейти на последнюю страницу общей выдачи и нажать «показать скрытые результаты».

Снова перейдя в конец выдачи, вы увидите примерно такое:
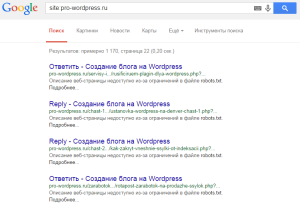
Это и есть те самые дубли, в данном случае replycom. Такой тип дублей в WordPress создается при появлении комментариев на странице. Есть множество разных видов дублей, их названия и способы борьбы с ними, будут описаны в следующей статье.
Наверняка у вас возник вопрос, почему в Яндексе мы не увидели такого количества дублей, как в Google. Все дело в том, что в файле robots.txt (кто не знает что это, читайте «Правильный robots.txt для WordPress») на блоге стоит запрет на индексацию подобных дублей с помощью директивы Disallow (подробнее об этом в следующем посте). Для Яндекса этого достаточно, но Гугл работает по своим алгоритмам и все равно учитывает эти страницы. Но их контент он не показывает, говорит, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Поиск дублей страниц на сайте и удаление
Дубли плохо влияют на индексацию блога. Польза от перелинковки и внешних ссылок значительно теряет вес. Чаще всего дубли страниц формируются у CMS WordPress, Joomla и др.
Возможно, небольшое количество дублей и не повредит сайту, но если их очень много, тогда с сайтом могут начаться реальные проблемы. Для поиска дублей существует несколько способов.
Один из способов поиска дублей страниц на сайте
Введите вначале в поисковике Яндекс команду: host:вашсайт.ru, а потом в Гугл, и посмотрите на результат выдачи, какое количество в Яндекс, и какое в Гугл.
В Google у меня показало 3470 ответа, а в Яндексе всего 130. Так вот, если число страниц в Яндекс и Гугл будет значительно отличаться, то это уже подозрительно.
Еще один способ
С каждой страницы скопируйте отрывок текста, примерно 15 слов и вставьте в поисковую строку браузера. Если будет появляться в выдаче более одной страницы, значит, существуют дубли.
Ну а если Ваш сайт имеет достаточно много страниц, тогда можно воспользоваться программой Xenu`s Link Sleuth. Скачать программу можно по этой ссылке http://home.snafu.de/tilman/XENU.ZIP
Программа Xenu’s Link Sleuth — инструкция
Скачайте и установите программу на ПК. Запустите ее, а затем перейдите «file» -> “Check URL…»,
введите адрес своего сайта и нажмите ОК.
Начнется долгий процесс проверки. Это программа будет находить страницы, битые ссылки, ссылки на картинки и прочее. Любые ошибки будут выделяться красным цветом, поэтому их будет сложно не заметить.
По результатам проверки моего ресурса, похвастаться нечем. Весь сайт набит каким-то HTML-мусором. Один плагин мне вообще весть сайт чуть не загубил. Пропало несколько статей, а также куча картинок.
После того, как проверка закончится, нужно все содержимое на экране скопировать и вставить в любой текстовый редактор. Там уже можно спокойно искать дубли страниц.
Но проверить дубли на сайте можно не только с помощью этой программы, но и воспользоваться инструментами Яндекc и Google
Удаление дублей страниц
Все ненужные ссылки, которые индексирует Яндекс, можно удалять здесь https://goo.gl/JUdQFd
Также надо удалить ссылки, которые индексирует Гугл. Переходите в Google Webmaster по этой ссылке https://www.google.com/webmasters/tools/, а затем выберите сайт, который который хотите проверить.
Далее, с левой стороны, надо выбрать «Индекс Google», а потом «Удалить URL-адреса». После этого надо кликнуть по серому прямоугольнику, который называется «Создать новый запрос на удаление».
Теперь откройте новую вкладку в браузере и введите в адресной строке google.com. Нам нужен поисковик от Гугл.
Наберите в поисковой строке site:vashsait.ru. Появиться список всех страниц, которые есть на сайте, и если есть дубли, то они тоже появятся.
Теперь находите дубли страниц, и если они есть, то копируйте адреса этих страниц и вставляйте в другой вкладке браузера в окошко «Создать новый запрос на удаление». Я выделил рамочкой, чтобы Вы понимали где адреса страниц копировать.
Вот таким образом Вы избавитесь от всех ненужных копий.
Таким способом можно избавиться от дублей, если у Вас маленький сайт. Но если на сайте достаточно много страниц, то дубли можно удалять с помощью редиректа 301 или закрытия этих страниц от индексации в файле robots.txt.
Файл robots.txt нужно правильно составить, еще в самом начале создания сайта. О файле robots.txt я писал в статье как правильно составить файл robots.txt
Посмотрите видео, как можно удалить дублирующие страницы с сайта, с помощью программы «Xenu Link Sleuth».
https://youtube.com/watch?v=O_gH49szzp4
Как убрать дубли страниц на сайте
Существует несколько различных способов борьбы с дублями. Одни варианты позволяют запретить появление новых дубликатов, другие могут избавиться от старых. Конечно, самый лучший вариант — это ручной. Но для его реализации нужно отлично разбираться в CMS своего сайта и знать работу алгоритмов поисковой системы. Но и другие методы тоже хороши и не требуют специализированных знаний. О них мы сейчас и поговорим.
301 редирект
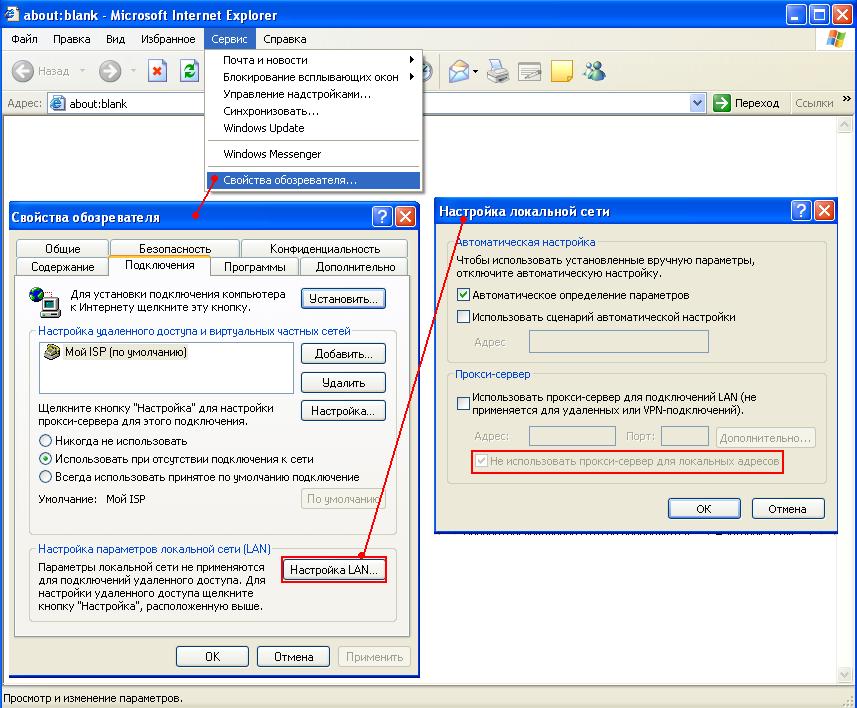
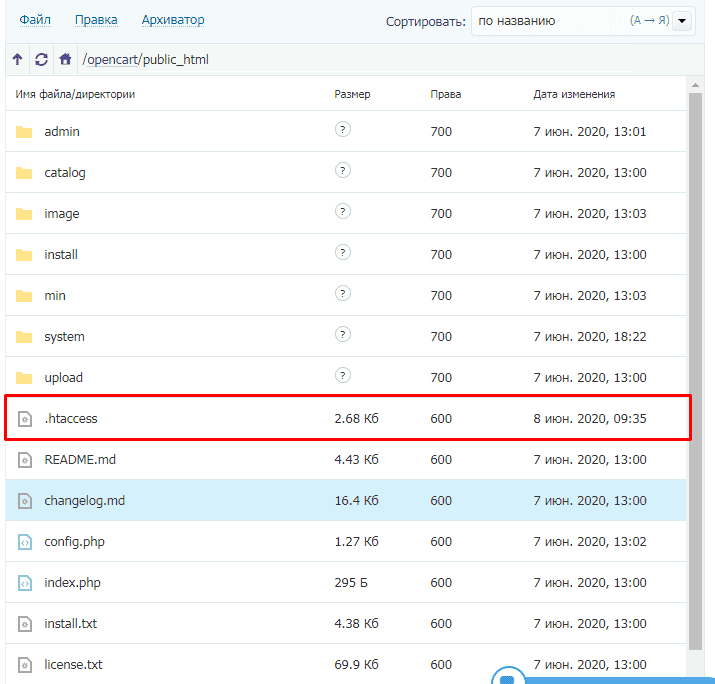
Данный способ считается самым эффективным, но и самым требовательным к знанию программирования. Дело в том, что здесь прописываются нужные правила в файле .htaccess (находиться в корне директории сайта). И если они прописываются с ошибкой, то можно не только не решить поставленную задачу удаления дублей, но и вообще убрать весь сайт из Интернета.
Как же решается задачка удаления дублей с помощью 301-го редиректа? В основу его лежит понятие переадресации поисковых роботов с одной страницы (с дубля) на другую (оригинальную). То есть робот приходит на дубликат какой-то страницы и и с помощью редиректа появляется на нужном нам оригинальном документе сайта. Его то он и начинает изучать, пропуская дубль вне поля своего зрения.

Со временем после прописки всех вариантов этого редиректа, склеиваются одинаковые страницы и дубли со временем выпадает с индекса. Поэтому этот вариант отлично чистит уже проиндексированные ранее дубли страниц. Если Вы решите воспользоваться этим методом, то обязательно перед пропиской правил в файле .htaccess, изучите синтаксис создания редиректов. Например, рекомендую для изучения руководство по 301-му редиректу от Саши Алаева.
Создание канонической страницы
Данный способ используется для указания поисковой системе того документа из всего множества его дублей, который должен быть в основном индексе. То есть такая страница считается оригинальной и участвует в поисковой выдаче.
Для ее создания необходимо на всех страницах дублей прописать код с урлом оригинального документа:
<link rel= «canonical» href= «http://www.site.ru/original-page.html»>
Конечно, прописывать все это вручную тяжковато. Для этого существуют различные плагины. Например, для своего блога, который работает на движке ВордПресс, я указал этот код с помощью плагина «All in One SEO Pack». Делается это очень просто — ставиться соответствующая галочка в настройках плагина:
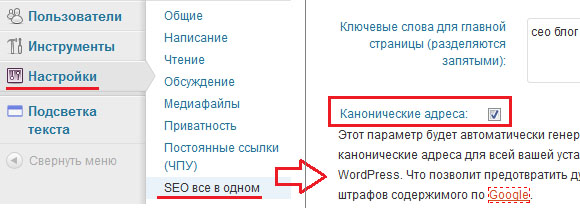
К сожалению, вариант с канонической страницей не удаляет дубли страниц, а только предотвращает их дальнейшее появление. Для того, чтобы избавиться от уже проиндексированных дубликатов, можно использовать следующий способ.
Директива Disallow в robots.txt
Вот поэтому то и создан такой файл, в котором прописываются различные директивы запрета и допуска индексации поисковым системам. Запретить сканирование дублей страниц можно с помощью директивы Disallow:

При создании директивы тоже нужно правильно составлять запрет. Ведь если ошибиться при заполнении правил, то на выходе может получиться совсем не та блокировка страниц. Тем самым мы можем ограничить доступ к нужным страницам и дать просочиться другим дублям. Но все же здесь ошибки не так страшны, как при составлении правил редиректа в .htaccess.
Запрет на индексацию с помощью Disallow действует для всех роботов. Но не для всех эти запреты позволяют поисковой системе убирать из индекса запрещенные страницы. Например, Яндекс со временем удаляет блокированные в robots.txt дубли страниц.
А вот Google не будет очищать свой индекс от ненужного хлама, который указал веб-мастер. К тому же директива Disallow не является гарантом этой блокировки. Если на запрещенные в инструкции страницы идут внешние ссылки, то они со временем появятся в базе данных Гугла.
Виды дублей страниц на сайте

Дубликаты бывают трех видов:
- Полные — с полностью одинаковым контентом.
- Частичные — с частично повторяющимся контентом.
- Смысловые — когда несколько разделов несут один смысл, переданный разными словами.
Анализируя структуру сайта, эксперты чаще реагируют на полные совпадения, хотя поисковые системы замечают и частичные, и смысловые.
1. Полные
Полный аналог ухудшает факторы внутренней оптимизации всего сайта и затрудняет его продвижение в ТОП, что крайне нежелательно. Поэтому их надо ликвидировать сразу после обнаружения.
К ним относятся:
- Версия с/без www. Возникает, если пользователь не указал зеркало в панели «Яндекса» и Google.
- Различные варианты главной страницы:
- site.net/index.html;
- site.net/index/;
- site.net/index;
- site.net.
- Страницы, которые появляются при ошибочной иерархии разделов:
- site.net/category/gift/;
- site.net/products/gift/;
- site.net/products/category/gift/.
- UTM-метки. Они используются, чтобы передавать данные для анализа рекламы и источника переходов. Поисковики их обычно не индексируют, но иногда бывают исключения.
- GET-параметры в URL. Иногда при передаче данных GET-параметры попадают в адрес:
- Разделы, сгенерированные реферальной ссылкой. Обычно их выделяют специальным параметром, добавляемым к URL. На такой ссылке должен стоять редирект на обычный URL, но этим часто пренебрегают.
- Если неправильно настроить раздел с ошибкой 404, то он спровоцирует появление бесконечного количества дублей. Любые символы в адресе сайта автоматически превратятся в ссылку и без редиректа выдадут ошибку 404.
Прекратить появление дубликатов с полным совпадением можно, если поставить редирект, убрать ошибку программным путем или закрыть ресурс от индексации.
2. Частичные
 Дубликаты с частичным совпадением меньше влияют на сайт. Трудно сказать, сколько дублей страниц сайта допустимо. Но если их слишком много, то это снижает позиции ресурса в поисковой выдаче, а также мешает его продвижению по конкретным ключевым запросам. Осталось выяснить, как частичные дубли появляются на сайте.
Дубликаты с частичным совпадением меньше влияют на сайт. Трудно сказать, сколько дублей страниц сайта допустимо. Но если их слишком много, то это снижает позиции ресурса в поисковой выдаче, а также мешает его продвижению по конкретным ключевым запросам. Осталось выяснить, как частичные дубли появляются на сайте.
Характеристики в карточке товара
Описание товара на странице может иметь дополнительные вкладки, например отзывы или характеристики. Переключившись на одну из них, можно отследить изменение URL, хотя большая часть информации не меняется. Это и создает дубль.
Пагинация
Если система управления контентом настроена неверно, то при переходе на следующую страницу в одной категории URL меняется, а Title и Description остаются теми же. В результате получаем несколько различных ссылок с одинаковыми метатегами:
- site.net/category/notebooks/?page=2;
- site.net/category/notebooks/.
Поисковый алгоритм проиндексирует эти URL-адреса как разные документы. Этого можно избежать — надо лишь проверить реализацию вывода товаров и автогенерации с технической стороны.
Кроме этого, на каждом документе пагинации надо будет указать каноническую страницу как главную на сайте.
Подстановка контента
Когда владельцы ресурса хотят увеличить количество посещений по запросам с указанием города, они добавляют на сайт кнопку выбора региона. При переходе в другой город на странице с контактами меняется номер телефона. Но бывают случаи, когда в адресной строке появляется такой аргумент, как, например, «wt_city_by_default=..». В результате документ получает несколько дублей с разными ссылками. Подобная генерация недопустима, старайтесь использовать 301 редирект.
Версия для печати
Подразумевает точную копию содержимого раздела, но в другом, преобразованном формате, например:
- site.net/blog/content;
- site.net/blog/content/print — версия для печати.
Чтобы не создавать множество дубликатов, их надо закрывать от индексации в robots.txt.
Смысловые
Чтобы обнаружить смысловые дубли, а точнее статьи, написанные под запросы из одного кластера, необходимо провести парсинг сайта, например, с помощью программы Screaming Frog. Затем добавить в любой Hard-кластеризатор скопированные заголовки всех статей с порогом группировки 3,4. Смысловые дубли обязательно окажутся в одном кластере. Надо оставить лучшую статью, а с остальных поставить 301 редирект.
В чем опасность дублей
1. Неправильная идентификация релевантной страницы поисковым роботом. Допустим, у вас одна и та же страница доступна по двум URL:
https://site.ru/kepki/
https://site.ru/catalog/kepki/
Вы вкладывали деньги в продвижение страницы https://site.ru/kepki/. Теперь на нее ссылаются тематические ресурсы, и она заняла позиции в ТОП10. Но в какой-то момент робот исключает ее из индекса и взамен добавляет https://site.ru/catalog/kepki/. Естественно, эта страница ранжируется хуже и привлекает меньше трафика.
2. Увеличение времени, необходимого на переобход сайта роботами. На сканирование каждого ресурса у поисковых роботов есть краулинговый бюджет – максимальное число страниц, которое робот может посетить за определенный отрезок времени. Если на сайте много дублей, робот может так и не добраться до основного контента, из-за чего его индексация затянется. Эта проблема особенно актуальна для сайтов с тысячами страниц.
3. Наложение санкций поисковых систем. Сами по себе дубли не являются поводом к пессимизации сайта – до тех пор, пока поисковые алгоритмы не посчитают, что вы создаете дубли намеренно с целью манипуляции выдачей.
4. Проблемы для вебмастера. Если работу над устранением дублей откладывать в долгий ящик, их может накопиться такое количество, что вебмастеру чисто физически будет сложно обработать отчеты, систематизировать причины дублей и внести корректировки. Большой объем работы повышает риск ошибок.
Дубли условно делятся на две группы: явные и неявные.
Как избавиться от дубликатов страниц: основные виды и методы
В данном пункте разберем наиболее часто встречающиеся виды дубликатов страниц и варианты их устранения:
- Не склеенные страницы с «/» и без «/», с www и без www, страницы с http и с https.
Варианты устранения:
一 Настроить 301 Moved Permanently на основное зеркало, обязательно выполните необходимые настройки по выбору основного зеркала сайта в Яндекс.Вебмастер.
- Страницы пагинации, когда дублируется текст с первой страницы на все остальные, при этом товар разный.
Выполнить следующие действия:
一 Использовать теги next/prev для связки страниц пагинации между собой;
一 Если первая страница пагинации дублируется с основной, необходимо на первую страницу пагинации поставить тег rel=”canonical” со ссылкой на основную;
一 Добавить на все страницы пагинации тег:
|
< meta name=»robots» content=»noindex, follow» / > |
Данный тег не позволяет роботу поисковой системы индексировать контент, но дает переходить по ссылкам на странице.
- Страницы, которые появляются из-за некорректно работающего фильтра.
Варианты устранения:
一 Корректно настроить страницы фильтрации, чтобы они были статическими. Также их необходимо правильно оптимизировать. Если все корректно настроено, сайт будет дополнительно собирать трафик на страницы фильтрации;
一 Закрыть страницы-дубликаты в файле robots.txt с помощью директивы Disallow.
- Идентичные товары, которые не имеют существенных различий (например: цвет, размер и т.д.).
Варианты устранения:
一 Склеить похожие товары с помощью тега rel=”canonical”;
一 Реализовать новый функционал на странице карточки товара по выбору характеристики. Например, если есть несколько почти одинаковых товаров, которые различаются только, к примеру, цветом изделия, то рекомендуется реализовать выбор цвета на одной карточке товара, далее – с остальных настроить 301 редирект на основную карточку.
- Страницы для печати.
Вариант устранения:
一 Закрыть в файле robots.txt.
- Страницы с неправильной настройкой 404 кода ответа сервера.
Вариант устранения:
一 Настроить корректный 404 код ответа сервера.
- Дубли, которые появились после некорректной смены структуры сайта.
Вариант устранения:
一 Настроить 301 редирект со страниц старой структуры на аналогичные страницы в новой структуре.
- Дубли, которые появляются из-за некорректной работы Яндекс.Вебмастера. Например, такие URL-адреса, которые заканчиваются на index.php, index.html и др.
Варианты устранения:
一 Закрыть в файле robots.txt;
一 Настроить 301 редирект со страниц дубликатов на основные.
- Страницы, к примеру, одного и того же товара, которые дублируются в разных категориях по отдельным URL-адресам.
Варианты устранения:
一 Cклеить страницы с помощью тега rel=”canonical”;
一 Лучшим решением будет вынести все страницы товаров под отдельный параметр в URL-адресе, например “/product/”, без привязки к разделам, тогда все товары можно раскидывать по разделам, и не будут “плодиться” дубликаты карточек товаров.
- Дубли, которые возникают при добавлении get-параметров, различных utm-меток, пометок счетчиков для отслеживания эффективности рекламных кампаний: Google Analytics, Яндекс.Метрика, реферальных ссылок, например, страницы с такими параметрами как: gclid=, yclid=, openstat= и др.
Варианты устранения:
一 В данном случае необходимо проставить на всех страницах тег rel=”canonical” со ссылкой страницы на саму себя, так как закрытие таких страниц в файле robots.txt может повредить корректному отслеживанию эффективности рекламных кампаний.
Устранение дублей позволит поисковым системам лучше понимать и ранжировать ваш сайт. Используйте советы из этой статьи, и тогда поиск и устранение дублей не будет казаться сложным процессом.
И повторюсь: малое количество дубликатов не так значительно скажется на ранжировании вашего сайта, но большое количество (более 50% от общего числа страниц сайта) явно нанесет вред.
Почему нужно избавляться от дублей страниц на сайте

Рассмотрим подробнее, чем грозит присутствие дублирующих разделов на сайте.
- Ухудшается индексация сайта
Если в проекте из тысячи страниц появится хотя бы по одному дублю, то объем ресурса увеличится вдвое. А если их будет больше? Например, экспертиза одного новостного портала показала, что автоматическое размещение одной новости в каждом разделе приводит к появлению новой страницы сразу с несколькими дублями.
- Неправильно распределяется внутренний ссылочный вес
Дубликат может появиться и в результате неправильно организованной перелинковки. В итоге страница-аналог приобретает больший вес, чем оригинал. Свою роль играют и посетители, попадающие на дублирующую копию, тем самым изменяя её показатели. В этом случае количество посещений на основной версии не изменится.
- Меняется релевантная страница в поисковой выдаче
Поскольку сайт открыт для индексации, то поисковик, наткнувшись на копию, может посчитать её более релевантной запросу, чем оригинал. Происходящая при этом смена страницы в поисковой выдаче может заметно снизить позицию сайта.
- Теряется внешний ссылочный вес
Заинтересовавшись вашим товаром или статьей, пользователь решил поделиться информацией и поставил ссылку на страницу. Если он побывал на дубле, то дал указатель именно на неё, а основная версия недосчитается полезной естественной ссылки.
Последствия дублированного контента
Если вы разместили на сайте кусок дублированного контента по недосмотру или другим случайным причинам, то поисковые алгоритмы могут просто зафильтровать эту часть текста и отобразят в ТОП лучшие, по их мнению материалы.
Иногда они могут отобразить в ТОП и ваш сайт, даже с не уникальном контентом. Пользователи хотят видеть вверху результатов поиска, сайты с лучшим контентом и поисковые алгоритмы оценивая страницы сайтов, так или иначе могут подмешивать в выдачу страницы состоящие из частично неуникального контента. Какие проблемы могут быть при использовании не уникального контента?
Как найти дубли страниц?
Для начала можно посмотреть общую картину с количеством проиндексированных страниц в поисковиках. В этом нам поможет очень полезное расширение для браузера – RDS Bar. Прежде всего нужно подсчитать примерное количество страниц на сайте. У меня на Tipsite.ru на данный момент должно индексироваться примерно 80 страниц. Теперь смотрим, что показывает RDS Bar.
В индексе Яндекса присутствует 83 страницы, что в пределах нормы, а вот Google проиндексировал 144 страницы. Из них 60% (примерно 86 страниц) находится в основном индексе, а вот остальные 40% (58 страниц) – это, так называемые «сопли». Такое прикольное название возникло из-за того, что кроме основного индекса у Google есть еще один – Supplemental Index, который переводится, как «дополнительный». Ну а при попытке прочитать это заграничное слово буквально, получается очень веселое название.
Итак, с общей картиной ознакомились, теперь можно переходит к более точным данным. Начнем с Google. Для этого в адресной строке браузера пишем вот такой запрос: site:tipsite.ru/& (вместо tipsite.ru подставляйте адрес своего сайта). После этого в результатах поиска мы увидим все страницы сайта без «соплей», которые находятся в основном индексе Google.
Теперь пишем немного другой запрос: site:tipsite.ru. В результатах будут показаны все проиндексированные страницы вместе с «соплями».
Переходим на последнюю страницу и нажимаем на неприметную ссылку «Показать скрытые результаты».
Снова двигаемся ближе к концу выдачи и видим, что за «сопли» попали в индекс.
В моем случае это лента RSS. Что самое интересное, эти файлы у меня закрыты от индексации в robots.txt. Сам Google этого тоже не отрицает и вместо сниппета пишет про ограничения в robots.txt, но несмотря на это в индекс, почему то, добавил.
Что касается Яндекса, то с ним все просто и ясно. Он либо индексирует страницу, либо нет и никаких «соплей» в индексе не развешивает. Да и то, что запрещено для индексации в robots.txt Яндекс трогать не будет. Чтобы просмотреть, какие страницы находятся в индексе Яндекса нужно набрать уже знакомый запрос: site:tipsite.ru.
Еще один вариант отыскать дубли страниц – это воспользоваться расширенным поиском. В Яндексе расширенный поиск доступен по адресу , ну а в Google вначале нужно нажать «Настройки», а там уже до расширенного поиска рукой подать.
Итак, открываем окно расширенного поиска и вписываем отрывок какой-либо статьи, а также адрес своего сайта. После этого нажимаем кнопку «Найти» и смотрим результаты.
В моем случае дубли не были найдены.
Ну и напоследок хочу рассказать про автоматический способ поиска дублей. В этом деле нам поможет программка Xenu, которая также неплохо ищет битые ссылки, или же Google Webmaster. В пункте «Оптимизация HTML» можно увидеть повторяющиеся метаописания и заголовки, которые могут оказаться дублями страниц.
Как удалить дубли страниц
После обнаружения дублей, первое, что необходимо сделать — найти причину, из-за которой они появляются, и постараться ее устранить.
Выделяют четыре основных метода удаления дублей:
- <meta name=»robots» content=»noindex»>;
- 301 редирект;
- rel=»canonical»;
- robots.txt.
Метатег robots
Позволяет задать роботам правила загрузки и индексирования определенных страниц сайта. Учитывается поисковой системой «Яндекс» и Google.
Метатег <meta name=»robots» content=»noindex» /> следует разместить в HTML-коде дублирующихся страниц в разделе <head>.
Пример:
<!DOCTYPE html><html><head><meta name=»robots» content=»noindex» />(…)</head><body>(…)</body></html>
Заданное для атрибута content значение noindex запрещает поисковым системам показывать страницу в результатах поиска.
Больше информации о специфике и применении метатега robots вы найдете в справочных материалах и «Яндекс».
301 редирект
Несомненно, один из самых действенных и известных методов устранения дублей, который позволяет автоматически перенаправить пользователей с одной страницы на другую. 301 редирект говорит поисковым системам о том, что старый URL-адрес имеет новый путь на постоянной основе. Со временем два или больше документа «склеиваются» в один, на который ведет перенаправление. При этом ссылочный вес сохраняется, поскольку передается со старой страницы на новую.
Настройка осуществляется через редактирование файла .htaccess либо с помощью плагинов.
Вот несколько плагинов для CMS WordPress:
- Redirection
- Simple 301 Redirects
- Safe Redirect Manager
Владельцам сайтов на движке Joomla достаточно воспользоваться встроенным менеджером перенаправлений.
Прежде чем настроить редирект в файле .htaccess, сначала сделайте его бэкап (резервное копирование).
Например, чтобы задать редирект с www на без www, разместите одно из правил:
RewriteEngine OnRewriteCond %{HTTP_HOST} ^www\.(.*)$RewriteRule ^(.*)$ http://%1/$1
или
RewriteEngine OnRewriteCond %{HTTP_HOST} ^www\.(.*)$ RewriteRule ^(.*)$ http://%1/$1
Переадресация с одной статической страницы на другую осуществляется за счет добавления строки:
Redirect 301 /old-page http://yoursite.com/new-page
где:
- old-page — страница, с которой происходит редирект;
- new-page — страница, на которую установлен редирект.
Атрибут rel=»canonical»
Укажите каноническую страницу, чтобы показать поисковым системам, какую страницу нужно индексировать при пагинации, сортировке, попадании в URL GET-параметров и UTM-меток. Этот способ уместен, когда удалять страницу нельзя и её нужно оставить открытой для просмотра. Учитывается поисковой системой «Яндекс» и Google.
Указывая каноническую ссылку, мы указываем адрес страницы, предпочтительной для индексации. Атрибут rel=»canonical» нужно прописать между тегами <head>…</head> на всех страницах, которые являются дублями.
Например, страница доступна по двум адресам: yoursite.com/pages?id=2 и yoursite.com/blog.
Если предпочитаемый URL — /blog, добавьте в HTML-код страницы /pages?id=2 элемент link:
<link rel=»canonical» href=»http://www.example.com/blog»/>
Больше информации о специфике применения атрибута rel=»canonical» вы найдете в справочных материалах и «Яндекс».
Файл robots.txt
Еще одно решение — запретить роботам индексировать дубликаты, дописав в файл robots.txt директиву Disallow. Чаще всего используется в тех случаях, когда нужно запретить индексацию служебных страниц и дублей.
Например, закрыть страницы пагинации от индексации Joomla поможет:
Disallow: /?start*
Учтите, директивы в robots.txt носят рекомендательный характер и могут быть проигнорированы поисковыми роботами, но как правило, они учитывают данное указание.
Итог
Дубли страниц — проблема из разряда «крупногабаритных и тяжеловесных». Если вовремя не отреагировать, все дальнейшие усилия по продвижения могут быть сведены на нет. Надеемся, представленные в этой статье методы помогут оптимизировать ваш ресурс и занять топовые места в поисковой выдачи.