Wayback machine что это за сервис?
Содержание:
- Проекты
- Инструкция по получению уникальных статей с вебархива
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- Что такое веб-архив и зачем он нужен?
- Блокировка Архива Интернета[ | код]
- Как вытянуть из Webarchive уникальный контент для сайта
- Поиск сайтов в Wayback Machine
- Юридические проблемы с архивным контентом
- Raw Numbers
- Примечания
- Компании, архивирующие интернет
- Backing up the Internet Archive
- Downloading from archive.org
- archive.md
- Проекты
- Как пользоваться веб архивом
- Проекты[ | код]
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. Поэтому сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к Интернет-сайтам: как и сервис кэшированных копий страниц от поисковых систем, архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.

Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Блокировка Архива Интернета[ | код]
В России | код
| Внешние изображения |
|---|
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
По состоянию на 22 августа 2019 года в Мосгорсуде находятся на рассмотрении иски Ассоциации по защите авторских прав в интернете (АЗАПИ), в которых заявлено требование о блокировке интернет-портала archive.org на территории России в связи с нарушениями авторских прав.
В других странах СНГ | код
Архив блокировался на территории Казахстана в 2015 году.
Также в 2017 году сообщалось о блокировках архива в Киргизии.
В Индии | код
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Как вытянуть из Webarchive уникальный контент для сайта
Описанный ниже способ лично я не использовал, но чисто теоретически все должно работать. Саму идею я почерпнул на этом молодом ресурсе, где и были описаны все шаги. Принцип метода состоит в том, что каждый день умирают и никогда не возрождаются десятки сайтов.
Причин этому может быть много и большинство из почивших в бозе ресурсов никакой особой ценности в плане контента никогда и не представляли. Но из всякого правила бывают исключения и нужно будет всего-навсего отделить зерна от плевел. Главное чтобы исчезнувшие сайты с более-менее удобоваримым контентом были бы представлены в Web Archive, хотя бы одной копией.
Т.к. после смерти контент этих сайтов постепенно выпадет из индекса поисковых систем, то взяв его из интернет-архива вы, по идее, станете его законным владельцем и первоисточником для поисковых систем. Замечательно, если будет именно так (есть вариант, что еще при жизни ресурса его нещадно могли откопипастить). Но кроме проблемы уникальности текстов, существует проблема их отыскания.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов).
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Использую для заработка
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
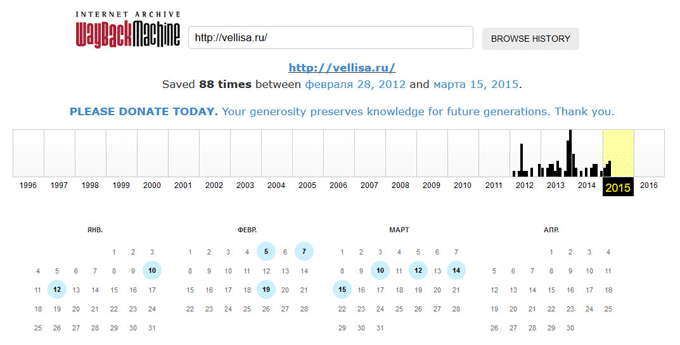
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
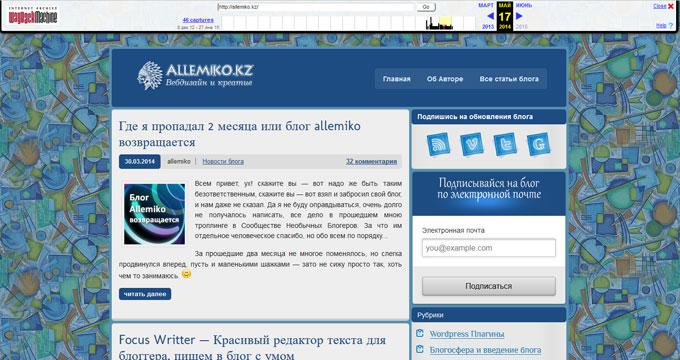
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления и что владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарных знаках с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать, что требования истца были недействительными, основываясь на содержании их веб-сайтов за несколько лет до этого. Затем истец, Healthcare Advocates, изменил свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Интернет-архив не нарушает авторские права Shell . Shell отреагировала и подала встречный иск против Internet Archive за архивирование ее сайта, которое, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отклонять иски Shell о нарушении авторских прав, связанные с ее копировальной деятельностью, которые также будут проданы.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив сообщил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не намеревался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 году порнографический актера по имени Daniel Davydiuk пытался удалить заархивированные образа себя из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем, обратившись к Федеральному суду Канады .
Raw Numbers
December 2010:
- 4 data centers, 1,300 nodes, 11,000 spinning disks
- Wayback Machine: 2.4 PetaBytes
- Books/Music/Video Collections: 1.7 PetaBytes
- Total used storage: 5.8 PetaBytes
August 2014:
- 4 data centers, 550 nodes, 20,000 spinning disks
- Wayback Machine: 9.6 PetaBytes
- Books/Music/Video Collections: 9.8 PetaBytes
- Unique data: 18.5 PetaBytes
- Total used storage: 50 PetaBytes
Items added per year
Search made 21:56, 17 January 2016 (EST) (this is just from the (mutable) «addeddate» metadata, so it might change, although it shouldn’t)
| Year | Items added |
|---|---|
| 2001 | 63 |
| 2002 | 4,212 |
| 2003 | 18,259 |
| 2004 | 61,629 |
| 2005 | 61,004 |
| 2006 | 185,173 |
| 2007 | 334,015 |
| 2008 | 429,681 |
| 2009 | 807,371 |
| 2010 | 813,764 |
| 2011 | 1,113,083 |
| 2012 | 1,651,036 |
| 2013 | 3,164,482 |
| 2014 | 2,424,610 |
| 2015 | 3,113,601 |
Примечания
- (англ.). Alexa Internet. — Глобальный рейтинг сайта archive.org. Дата обращения: 20 июня 2020.
- .
- .
- (англ.). archive.org. Дата обращения: 28 марта 2019.
- . Internet Archive (7 мая 2007). Дата обращения: 31 августа 2016.
- (недоступная ссылка). Wayback Machine (6 июня 2000). Дата обращения: 1 сентября 2016.
- Jeff. (Blog). Wayback Machine Forum. Internet Archive (23 сентября 2002). Дата обращения: 4 января 2007. Author and Date indicate initiation of forum thread
- Miller, Ernest (Blog). LawMeme. Yale Law School (24 сентября). Дата обращения: 4 января 2007. The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. (англ.). preprint cs/0404005 16. arXiv (2004). Дата обращения: 26 ноября 2017.
- .
- .
- (недоступная ссылка). Дата обращения: 17 сентября 2017.
- . Роскомнадзор (24 октября 2014).
- ↑
Компании, архивирующие интернет
Архив Интернета
Основная статья: Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
Основная статья: WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Основная статья: archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Backing up the Internet Archive
In April 2015, ArchiveTeam founder Jason Scott came up with an idea of a distributed backup of the Internet Archive. In the following months, the necessary tools got developed and volunteers with spare disk space appeared, and now tens of terabytes of rare and precious digital content of the Archive have already been cloned in several copies around the world. The project is open to everyone who has got at least a few hundred gigabytes of disk space that they can sacrifice on the medium or long term. For details, see the INTERNETARCHIVE.BAK page.
Let us clarify once again: ArchiveTeam is not the Internet Archive. This «backing up the Internet Archive» project, just like all the other website-rescuing ArchiveTeam projects are not ordered, asked for, organized or supported by the Internet Archive, nor are the ArchiveTeam members the employees of the Internet Archive (except a few ones). Besides accepting – and, in this case, providing – the content, the Internet Archive doesn’t collaborate with the ArchiveTeam.
Most of the directly downloadable items at IA are also available as torrents — at any given time some fraction of these have external seeders, although as of 01:46, 17 February 2016 (EST) there is a problem with IA’s trackers where they refuse to track many of the torrents.
Downloading from archive.org
- Other Wayback Machine APIs used in the website interface, not included in IA’s list, include:
- Manually, from an individual item: click «HTTPS»; or replace with in the URL and reload. This will take you to a page with a link to download a ZIP containing the original files and metadata.
- To download a raw, unmodified page from the Wayback Machine, add «id_» to the end of the timestamp, e.g.
robots.txt and the Wayback Machine
As of April 2017, the Internet Archive is no longer fully respecting robots.txt, although this change may not be visible on all archived sites yet. Alexa’s crawler still respects robots.txt, and Archive-It respects robots.txt by default. Users can still request that their domain be excluded from the Wayback Machine.
Note that if the content is available in the form of web archive (WARC) file through the IA’s normal collections the WARC file may still be downloaded even if the content is not accessible through the Wayback Machine.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. Поэтому сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к Интернет-сайтам: как и сервис кэшированных копий страниц от поисковых систем, архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Проекты[ | код]
Wayback Machine | код
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность | код
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library | код
Основная статья: Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.