Онлайн сервис восстановления сайтов из веб архива
Содержание:
- Как проверять полученные статьи на уникальность
- Как использовать веб-архив?
- Аспекты архивирования
- В наши дни создатель первого сайта выступает за свободный интернет
- r-tools.org
- Очистка записей
- Индексация веб-страниц в интернете
- Возможности использования веб-архивов
- Проблемы архивирования
- [править] Ссылки
- Как пользоваться веб-архивом?
- Проекты, предоставляющие историю сайта
- Кэш браузера
- Описание
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Аспекты архивирования
Веб-архивирование, как и любой другой вид деятельности, имеет юридические аспекты, которые необходимо учитывать в работе:
- Сертификация в надёжности и целостности содержания веб-архива.
- Сбор проверяемых веб-активов.
- Предоставление поиска и извлечения из массива данных.
- Сопоставимость содержания коллекции
Ниже представлен набор инструментов, который использует Консорциум по архивированию интернета
- Heretrix — архивация.
- NutchWAX — поиск коллекции.
- Открытый исходный код «Wayback Machine» — поиск и навигация.
- Web Curator Tool — выбор и управление.
Другие инструменты с открытым исходным кодом для манипуляций над веб-архивами:
WARC-инструменты — для программного создания, чтения, анализа и управления веб-архивами.
Просто бесплатное ПО:
- Инструменты поиска Google — для полнотекстового поиска.
- WSDK — набор утилит, Erlang-модулей для создания WARC-архива.
В наши дни создатель первого сайта выступает за свободный интернет
Бернерс Ли выступает за реорганизацию интернета.
Сегодня Бернерс Ли активно выступает за открытость интернета. К локализации персональных данных пользователей своей страны и идеям суверенного интернета он относится скептически.
Тим говорит, что любое разделение сети на сегменты — очень плохая идея. Причина бурного развития Веба заключалась в том, что интернет был негосударственным, открытым и общедоступным.
Бернерс Ли призывает все страны быть очень осторожными в попытках подчинить себе мировую паутину.
Интернет должен остаться свободным.
Это отдельный мир, со своими законами и правилами, который каждый день помогает и развлекает нас уже более 25 лет, но все еще далек от совершенства. Развивайся, интернет.
iPhones.ru
Недавно этому сайту исполнилось 28 лет, и его создатель все еще жив.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Очистка записей
Если вы решили удалить историю входов на различные сайты полностью либо убрать из списка некоторые из наименований, то это выполнять можно несколькими способами. Ниже мы перечислим пути, как очистить историю в Microsoft Edge.
- Открыв список сайтов, на которые вы заходили, чтобы посмотреть сохранённые в нём данные, вы увидите ссылку «Очистка всех журналов». Нажав на неё, вы удалите все записи. Учитывайте, что по умолчанию удаляется информация только из браузерного журнала, cookie, локально сохранённые файлы веб-страниц, кэш.
- Очистить записи удобно сочетанием Ctrl+Shift+Del. Вам предложат список удаляемых сведений. Передавая компьютер другому пользователю во владение, выбирайте все пункты очистки. Здесь можно ещё выбрать глубокую очистку, скрытую кнопкой «Больше». Такую очистку рекомендуем выполнять, если появились проблемы с запуском браузера.
- Удалить сведения возможно через Меню. В правом углу сверху есть кнопка «Дополнительно» (многоточие). Нажав на неё, выберите «Параметры». В списке найдёте «Очистить данные браузера», здесь присутствует кнопка для выбора пунктов, в которых нужно удалить информацию.
- Можно удалить информацию по разделам. Откройте Журнал, чтобы выполнить просмотр сохранённой истории входов на сайты. Рядом с каждым разделом есть крестик, нажатие на который поможет очистить раздел. Таким же способом можно очистить по отдельности посещённые сайты. Эта функция удаления, наверняка, удобна тем, на чьих компьютерах работают несколько пользователей, если вы не хотите, чтобы другие знали, что вы посещали некоторые веб-страницы. Для удаления сведений о посещении одной веб-страницы, наведите в списке на неё мышкой, и вместо времени входа справа появится крестик для удаления.
Если не хотите сохранять историю ваших посещений в Microsoft Edge, вы можете пользоваться режимом приватности, тогда сторонние сайты не отслеживают ваши данные, информация о страницах, на которых вы побывали, не сохраняется. Если же эти сведения сохранились на вашем компьютере и хотите их удалить, очистить Microsoft Edge, используя выше приведённые рекомендации. Это выполнить несложно, притом вы можете выбирать удобный для вас путь из нескольких предложенных.
Читайте, как и где посмотреть историю вашего браузера и каким способом её можно удалить
.
По умолчанию, любой браузер сохраняет историю посещённых с его помощью интернет страниц или сайтов. История сохраняется в хронологическом прядке, и хранится в браузере пока её не удалить. Если вы помните приблизительное время посещения нужного сайта, то его без труда можно найти в Истории браузера. Также в истории можно просмотреть перечень сайтов, посещённых пользователем в определённый промежуток времени.
Чтобы посмотреть историю наиболее популярного браузера Google Chrome:
Чтобы очистить историю Chrome:
Чтобы посмотреть историю посещённых страниц Яндекс.Браузер:
Чтобы очистить историю Яндекс.Браузер:
Opera
Opera – это ещё один популярный браузер, который кроме прочего, известен функцией встроенного VPN. Чтобы посмотреть историю браузера Opera:
Чтобы очистить историю браузера Opera:
Mozilla Firefox
Чтобы посмотреть историю браузера Mozilla Firefox, есть несколько способов.
Чтобы очистить историю Mozilla Firefox:
Microsoft Edge
Microsoft Edge – это встроенный в Windows 8 и 10 браузер, который заменил Internet Explorer. Историю Microsoft Edge можно посмотреть в меню с названием Журнал
.
Чтобы открыть его:
Чтобы очистить историю Microsoft Edge:
Internet Explorer
Для пользователей Windows 7, часто привычным браузером остаётся Internet Explorer. Он также сохраняет историю посещений пользователем веб-ресурсов. Чтобы посмотреть её:
Чтобы очистить историю Internet Explorer:
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
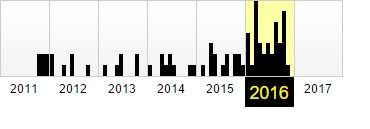 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Проблемы архивирования
Сканеры
Для веб-архивов, которые полагаются на веб-сканеры, имеются следующие проблемы:
- Сайт может запретить для просмотра часть сайта как для веб-сканера, так и для пользователей.
- Часть сайта может быть скрыта в deep Web.
- Ловушки для сборщиков (Crawler traps), например, генерируемые календари и телефонные списки, могут привести к чрезвычайно большому или бесконечному количеству страниц.
- За время обхода сайта уже обойдённые страницы могут измениться.
Однако, технологии сбора способны выдавать в результате страницы с полностью работоспособными ссылками.
Общие ограничения
Иногда администратор сайта настраивает сервер так, что тот выдает нормальные документы лишь пользователям обычных браузеров, но генерирует иные данные для ботов, архиваторов, пауков и т. п. автоматических программ. Это делается с целью обмана поисковых систем или же для увеличения пропускной способности канала, чтобы веб-сервер выдавал пригодный для просмотра материал для устройства и не скачивал ничего лишнего.
Веб-архив сталкивается и с юридическими проблемами. Сохранённый в нём документ может оказаться объектом интеллектуальной собственности, и правообладатель может потребовать удалить его. В других случаях веб-архив может подвергнуться преследованию со стороны какого-либо государства. Правовой основой (поводом) такого преследования обычно выступает законодательство об охране приватности либо о запрете распространения информации. Если архив находится в другой стране, юридическая процедура, ведущая к блокировке сайта, может пройти без ведома и участия владельца ресурса, и он теряет возможность защищаться и опротестовывать решение (если такая возможность предусмотрена).
[править] Ссылки
| Веб-архив относится к теме «Интернет» | |||||||||||||||||||||
|
Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.

Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена
Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.
Проекты, предоставляющие историю сайта
 Peeep.us в действии
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
Описание
Большинство публикаций архива доступно в исходном виде в формате ΤΕΧ (и его вариантах), но можно также скачать автоматически генерирующиеся документы в форматах PostScript и PDF.
Раз в несколько лет архив обновляет используемый дистрибутив ΤΕΧа;
в настоящее время это TeX Live 2016 года, а до начала 2017-го года использовался TeX Live 2011 года;
проблемы связанные с несоответствием версий обычно решаются через даунгрейд локальной версии ΤΕΧа.
Часть статей выкладывается авторами в форматах, отличных от ΤΕΧ в частности, PDF, PostScript и HTML; при этом публикация статьи сгенерированной в ΤΕΧе без исходных файлов не допускается.
Существует возможность оформить е-mail-подписку на список новых статей с их аннотациями. Можно подписаться либо на все статьи, либо на статьи только по интересующей тематике, например: вычислительная геометрия, дискретная математика и другим дисциплинам.
Статьи, выкладываемые авторами в архив, не проходят процедуру научного рецензирования (и в связи с этим, строго говоря, не считаются научными публикациями). Модераторы архива могут уточнить и переклассифицировать направление (раздел архива), в котором появится статья. В январе 2004 года в архиве была введена система предварительного подтверждения (англ. endorsement), в соответствии с которой автор, направляющий статью, должен обладать статусом «поручителя» (endorser) или статья должна быть рекомендована другим поручителем; статус поручителя получают автоматически авторы из признанных академических учреждений. Эта система позволяет уменьшить количество псевдонаучных публикаций.
Статьи архива могут быть изменены их авторами; при этом, как правило, остаются доступными и ранние варианты;
однажды опубликовав статью в архиве, её уже нельзя из него полностью убрать.