Encoding.utf8 свойство
Содержание:
- Два типа кодирования
- Кодировки на основе Unicode
- [править] BOM (сигнатура)
- История создания
- Недостатки и достоинства
- Как задать кодировку UTF-8
- Htaccess
- Переход к Unicode
- О программе
- ASCII
- [править] Максимальный потенциал
- Кодировка windows-1251
- Как это работает?
- Как перевести файлы в кодировку UTF-8
- UTF-8
- Декодирование потока байтов
- Комментарии
- Символы стрелок в UTF8
Два типа кодирования
Есть ещё одно важно различие в кодировании. Некоторые пакеты для кодирования оперируют с примитивами — строки, целые числа и т.д
Строки закодированы кодировками вроде ASCII или Unicode или любыми другими кодировками. Целые числа могут закодированы по разному, в зависимости от endianness или используя целочисленное кодирование с произвольной длиной. Даже сами байты часто могут закодированы используя схемы вроде Base64, чтобы превратить их в печатаемые символы.
Но всё же чаще, когда мы говорим про кодирование, мы думаем именно о кодировании объектов. Это означает превращение сложных структур в памяти таких как структуры, карты и слайсы в набор байт. В этом превращении приходится иметь дело с массой компромиссов и за много лет люди придумали множество различных способов кодирования.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
[править] BOM (сигнатура)
Многие программы Windows (включая Блокнот) добавляют байты 0xEF, 0xBB, 0xBF в начале любого документа, сохраняемого как UTF-8.
Это метка порядка байтов (англ. Byte Order Mark, BOM), также её часто называют сигнатурой (соответственно, UTF-8 и UTF-8 with Signature). По наличию сигнатуры программы могут автоматически определить, является ли файл закодированным в UTF-8, однако файлы с такой сигнатурой могут некорректно обрабатываться старыми программами, в частности xml-анализаторами. Такие редакторы, как Notepad++, Notepad2 и Kate, позволяют явно указывать, следует ли добавлять сигнатуру при сохранении UTF-файлов.
Например: В файле записана одна латинская буква «a».
- Если кодировка этого файла UTF-8 with Signature, то он будет содержать: 0xEF 0xBB 0xBF 0x61
- Если кодировка этого файла UTF-8 (без сигнатуры), то он будет содержать: 0x61
Если считывающая программа не поддерживает BOM, то эти три байта успешно раскодируются в один Unicode-символ 0xFEFF. Это не разрывающий слова пробел нулевой ширины и поэтому он может не отобразиться. Этот же символ используется в BOM для кодировок UTF-16 и UTF-32.
История создания
До появления Unicode UTF-8 широко использовались другие кодировки (ASCII, ISO/IEC 646, ISO/IEC 8859, KOI8, Windows-125x).
Впервые кодировка UTF-8 была официально представлена на конференции USENIX в Сан Диего в январе 1993. От других мультибайтных кодировок ее отличала полная совместимость с ASCII: все символы ASCII в UTF-8 кодируются 7 битами. Каждый символ кодировки, отличный от ASCII, состоит из ведущего байта, указывающего длину последовательности, и одного или нескольких продолжающих байт. Такой принцип позволяет определить длину последовательности только по первому байту. Коды символов ASCII, ведущих и продолжающих байт не пересекаются, что позволяет легко найти начало последовательности простым откатом назад максимум на пять байт.
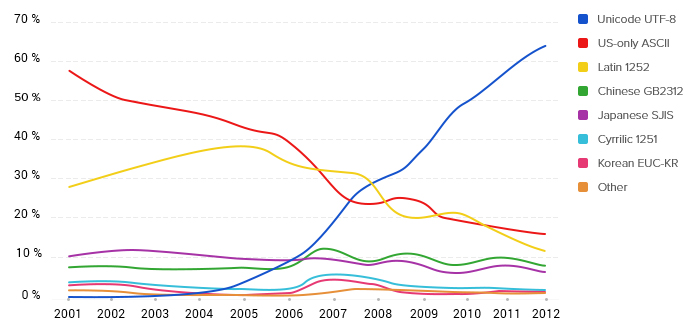 График изменения популярности кодировок в интернете
График изменения популярности кодировок в интернете
В ноябре 2003 года стандартом RFC-3629 максимальная длина последовательности UTF-8 была ограничена четырьмя байтами, однако потенциально UTF-8 позволяет использовать последовательности вплоть до шести байт.
На сегодняшний день самой распространенной кодировкой является UTF-8. Она включает в себя более двух миллионов символов: все возможные современные алфавиты, цифры, знаки препинания, математические и специальные символы, музыкальные знаки и символы вымерших форм письменности. А резерва UTF-8 хватит для размещения более двух миллиардов символов. Так что о смене кодировки в ближайшее время задумываться не придётся.
Однако торжество современных технологий — явление относительно новое. Согласно Google, самой распространенной в интернете кодировкой UTF-8 стала только в 2008 году — тогда ее использовали чуть более чем 25% проиндексированных веб-страниц. А еще в 2006 UTF-8 использовали менее чем 10% веб-страниц.
Стремительный рост популярности кодировки UTF-8 связан с целым рядом ее преимуществ перед предшественницами.
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
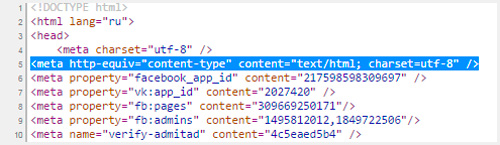
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> |
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова. Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Как задать кодировку UTF-8
В HTML кодировка UTF-8 устанавливается с помощью следующего кода:
˂head˃
˂meta http-equiv=»Content-Type» content=»text/html; charset=utf-8″˃
В PHP кодировка UTF-8 задаётся с помощью функции header() в самом начале файла после задания значения уровня вывода ошибок:
˂?php
error_reporting(-1);
header(‘Content-Type: text/html; charset=utf-8’);
Для подключения к базам данных MySQL кодировка UTF-8 устанавливается так:
˂?php
mysql_set_charset(‘utf8’);
В CSS-файлах кодировка символов UTF-8 указывается так:
@charset «utf-8»;
При сохранении файлов всех типов выбирается кодировка UTF-8 без BOM, иначе сайт работать не будет. Для этого в программе DreamWeave нужно выбрать пункт меню «Модификации – Свойства страницы – Заголовок/Кодировка», изменить кодировку на UTF-8. Затем следует перезагрузить страницу, убрать галочку из пункта «Подключить Юникод сигнатуры (BOM)» и применить изменения. Если какой-либо текст на странице или в базе данных был введён другой формой кодирования, то его нужно ввести заново или перекодировать. При работе с регулярными выражениями обязательно использовать модификатор u.
Также можно сохранить файл в кодировке UTF-8 в «Блокноте» ОС Windows. После выбора пункта меню «Файл – Сохранить как…» установить необходимую форму кодирования и сохранить файл в кодировке UTF-8.
В текстовом редакторе Notepad++, если кодировка отлична от UTF-8, через пункт меню «Преобразовать в UTF-8 без BOM» изменить кодировку и сохранить в кодировке UTF-8.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset "cp1251" |
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат
Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще
Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
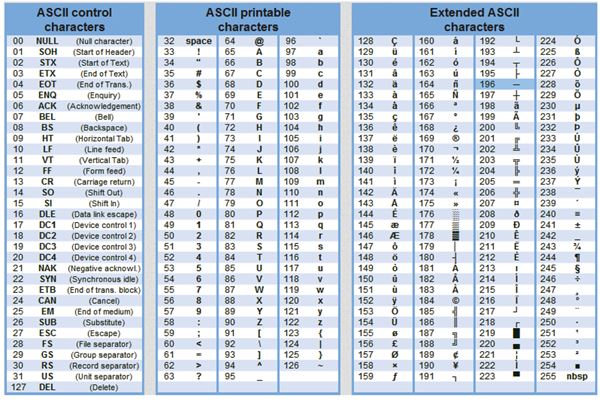
ASCII
UTF-8-кодировка полностью поддерживает коды ASCII (0x00-0x7F). Это значит, что символы Юникода U+0000-U+007F конвертируются в единственный байт 0x00-0x7F UTF-8 и таким образом становятся неотличимыми от ASCII. Более того, чтобы избежать многозначности, значения 0x00-0x7F не используются больше ни в одном байте представления символов Юникода. Для кодирования неидеографических символов, отличных от ASCII, используется последовательность из двух байтов. Символы диапазона U+0800-U+FFFF представлены тремя байтами, а дополнительные с кодами больше U+FFFF требуют четырёх байтов.
[править] Максимальный потенциал
До этого рассматривалось кодирование в UTF-8 лишь 32-битных целых без отрицательных значений. Следует отметить, что в стандарте Unicode используются символы лишь до кода 0x001FFFFF включительно. Поэтому даже 32-битных значений может вполне хватить, но этот раздел был включён для полноты изложения в случае использования UTF-8 для кодирования несимвольных данных.
В первом байте количество установленных старших бит определяет количество байт на символ. Оставшиеся младшие биты хранят старшие биты значения кода символа. Мы можем сделать допущение о том, что первый байт не обязан содержать данные. При этом допускаем, что все биты за пределами байта равны нулю. Тогда данные будут содержать только 6 бит в последующих байтах. Получается 36 бит для семибайтового символа и 42 бита — для восьмибайтового.
Кодировка windows-1251
Графические системы развивались, у них необходимость в псевдографике пропадала. Поэтому ее убрали. И возникла целая группа расширенных кодировок ascii без псевдографики. У них принцип такой же: 1 символ = 1 байт. А вместо псевдографики появились символы, которые описывают целую группу кириллических языков (украинский, болгарский, сербский, белорусский). Т.е. здесь мы видим целую группу кириллических языков. Поэтому эта кодировка часто называется кириллицей.
Все вышеописанные кодировки — из разряда ASCII. А как быть с азиатскими языками, где не 256 символов, а тысячи? Поэтому изначально там были свои кодировки. Но вскоре компания Microsoft инициировала создание консорциума для решения проблемы кодировок. Консорциум называется unicode (www.unicode.org). Он объединяет в себе сегодня сотни компаний.
И в результате работы консорциума возникали такие кодировки:
- Кодировка UTF-32. 32 — это количество бит, которое используется для кодирования. И здесь можно описать миллиарды символов. Но есть проблема — в 4 раза увеличивается размер документа, использующего группы европейские языки. Такое не могли себе позволить.
- Кодировка UTF-16. Эта кодировка была принята в качестве базового пространства для всех символов, которые у нас используются. Здесь используется 2 байта на 1 символ. Всего можно закодировать до 1 миллиона символов. Но был небольшой недостаток для англоязычных программистов, все документы увеличивались в 2 раза по размеру. И придумали кодировку переменной длины — utf-8.
- Кодировка UTF-8. Это кодировка переменной длины, т.е. каждый символ может быть закодирован от 1 до 6 байт. На практике используется диапазон 1-4 байт, т.к. за 4 байтами ничего не лежит. Все латинские символы из кодировки ascii кодируются в 1 байт, кириллические символы кодируются в 2 байта, грузинские символы — в 3 байта. Иероглифы — в 4 байта. Всего можно закодировать до 1 миллиона символов.
Как это работает?
Смысл использования символов из таблицы UTF8 заключается в том, что у вас в компьютере уже есть все необходимые знаки и ваш браузер может с лёгкостью их отобразить, нужно только знать их специальный код.
Например, символ стрелочка вверх в UTF8 записывается так ↑
Вы можете скопировать эту последовательность знаков и вставить себе в HTML страницу как обычный текст.
После этого у вас на сайте вместо этого набора знаков появится графическое изображение стрелочки. Удобно, не правда ли!?
И не нужно подключать никаких дополнительных шрифтов на ваш сайт ради вставки нескольких символов, а так же готовить и вставлять графические изображения.
Если вы создаёте свою HTML страницу в кодировке Windows-1251 или ещё какой-то другой то коды дынных символов не буду срабатывать, они отображаются только в кодировке UTF8.
Таблица символов UTF8 (Unicode) включает в себя тысячи, а то миллионы различных знаков.
Чтобы вам не приходилось пересматривать огромные таблицы в поисках нужного значка я выбрала наиболее интересные и полезные из них и разбила их по группам.
Как перевести файлы в кодировку UTF-8
Те, у кого старые сайты, могут столкнуться с такой проблемой, что необходимо перевести файлы в кодировку UTF-8. К их числу я смело могу назвать и себя. Начала делать сайты более 10 лет назад, когда об этой кодировке было мало что известно. На всех страницах у меня стояла кодировка:
<META http-equiv=content-type content=»text/html; charset=utf-8″>
За эти годы некоторые мои сайты распухли до тысячи и более страниц и переделывать все эти тысячные страницы не хватит никаких сил и времени.
Сейчас уже так не пишут. На смену старому пришло новое — HTML5, где нужно прописать:
<meta charset=»utf-8″>
Скажу честно, все же решила я все перелопатить вручную и вот как это у меня происходило:
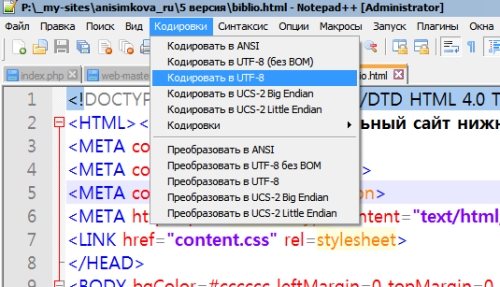
- Открывала файл в Notepad++
- Выделяла весть текст
- Копировала весь текст
- Переводила кодировку в UTF-8
- Вставляла текст
- Проверяла опять — в той ли кодировке стоит?
- Сохраняла файл
И вот два дня я так долбила один свой сайт.
Можно, конечно же и не менять ничего. Но ведь старые сайты мои давно устарели, нужно переводить их и на современную верстку HTML5 и CSS3, плюс мобильную и адаптивную верстку. И лучше это делать в более продвинутых программах, а не в Notepad++.
Короче, приуныла я. Однако приехал сын-программист и все решил!
Оказывается все уже давно придумано. И если у Вас возникла такая же проблема — не отчаивайтесь! Есть прекрасная программа UTFCast Express
Эту программу можно скачать тут — http://www.rotatingscrew.com/utfcast-express.aspx — Это условно бесплатная программа, которая умеет конвертировать текст из разных кодировок в utf8. Доступна для ОС семейства Windows.
Запускаем UTFCast Express и указываем правильные пути: сверху — что конвертировать, снизу — куда складывать конвертированные файлы. Вам нужно просто выбрать нужные директории, программа сама перекодирует все нужные файлы из папки. Нажимаем «Start».
Единственно, заранее создайте новую папку, куда программа закачает все Ваши файлы из нужной папки.
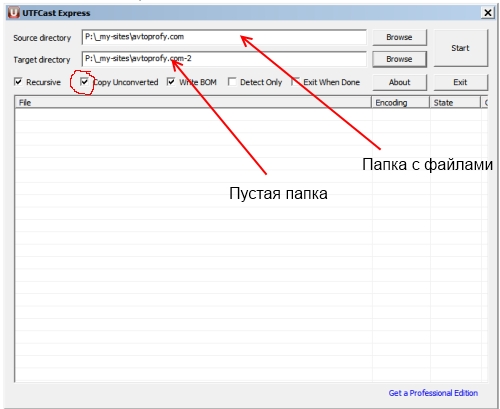
Не забудьте также поставить галочку «Copy Unconverted». Нажимаете кнопочку «Start» и программа заработала!
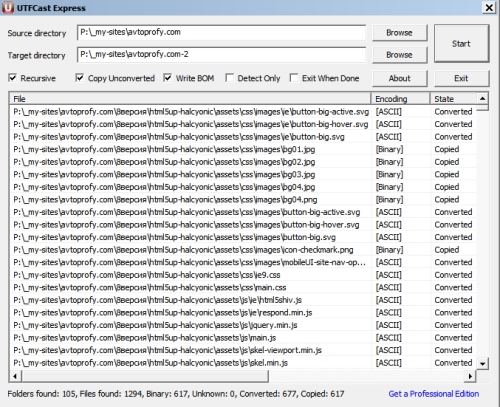
Всего пара минут и все файлы волшебным образом перекодировались в нужную кодировочку!
Папку с прежними файлами можете просто удалить, чтобы не занимала место и работать дальше! Вперед, к новым высотам!
Ура, товарищи!!!
UTF-8
UTF-8-это код переменной длины. Некоторые символы требуют 1 байт, некоторые требуют 2, Некоторые 3 и некоторые 4. Байты для каждого символа просто записываются один за другим как непрерывный поток байтов.
в то время как некоторые символы UTF-8 могут быть длиной 4 байта, UTF-8 невозможно закодировать 2^32 символа. Это даже не близко. Я попытаюсь объяснить причины этого.
программное обеспечение, которое читает поток UTF-8, просто получает последовательность байтов — как оно должно решить, следующие 4 байта-это один 4-байтовый символ, или два 2-байтовых символа, или четыре 1-байтовых символа (или какая-то другая комбинация)? В основном это делается путем решения, что определенные 1-байтовые последовательности не являются допустимыми символами, а некоторые 2-байтовые последовательности не являются допустимыми символами и т. д. Когда эти недопустимые последовательности появляются, предполагается, что они являются частью больше последовательности.
вы видели совсем другой пример этого, я уверен: это называется побегом. Во многом языки программирования решено, что символ в исходном коде строки не переводится на любой допустимый символ в «скомпилированной» форме строки. Когда \ находится в источнике, предполагается, что он является частью более длинной последовательности, например или
Обратите внимание, что является недопустимой 2-символьной последовательностью и является недопустимой 3-символьной последовательностью, но является допустимой 4-символьной последовательностью
в основном, есть компромисс между наличием многих характеры и иметь более короткие характеры. Если вы хотите 2^32 символов, они должны быть в среднем длиной 4 байта. Если вы хотите, чтобы все ваши символы были 2 байта или меньше, то вы не можете иметь более 2^16 символов. UTF-8 дает разумный компромисс: все ASCII символы (ASCII от 0 до 127) даны 1-байтовые представления, что отлично подходит для совместимости, но разрешено гораздо больше символов.
как и большинство кодировок переменной длины, включая виды побега последовательности, показанные выше, UTF-8 является мгновенная код. Это означает, что декодер просто читает байт за байтом, и как только он достигает последнего байта символа ,он знает, что такое символ (и он знает, что это не начало более длинного символа).
например, символ » A » представлен с использованием байта 65, и нет двух/трех/четырехбайтовых символов, первый байт которых равен 65. Иначе декодер не смог бы сказать. эти символы, кроме «А», за которыми следует что-то еще.
но UTF-8 ограничен еще больше. Это гарантирует, что кодировка более короткого символа никогда не появится в любом месте в кодировке более длинного символа. Например, ни один из байтов в 4-байтовом символе не может быть 65.
поскольку UTF-8 имеет 128 различных 1-байтовых символов (значения которых равны 0-127), все 2, 3 и 4-байтовые символы должны состоять исключительно из байтов в диапазоне 128-256. Это большое ограничение. Однако он позволяет строковым функциям, ориентированным на байты, работать практически без изменений. Например, C функция всегда работает так, как ожидалось, если ее входы являются допустимыми строками UTF-8.
Декодирование потока байтов
Подобно кодированию строки, мы можем декодировать поток байтов в строковый объект, используя функцию .
Формат:
encoded = input_string.encode() # Using decode() decoded = encoded.decode(decoding, errors)
Поскольку преобразует строку в байты, просто делает обратное.
byte_seq = b'Hello' decoded_string = byte_seq.decode() print(type(decoded_string)) print(decoded_string)
Вывод
<class 'str'> Hello
Это показывает, что преобразует байты в строку Python.
Подобно параметрам , параметр определяет тип кодирования, из которого декодируется последовательность байтов. Параметр обозначает поведение в случае сбоя декодирования, который имеет те же значения, что и у .
Комментарии
Это свойство возвращает UTF8Encoding объект, который кодирует символы в кодировке Юникод (UTF-16) в последовательность от одного до четырех байтов на символ и декодирует массив байтов в кодировке UTF-8 в символы Юникода (UTF-16-Encoded).This property returns a UTF8Encoding object that encodes Unicode (UTF-16-encoded) characters into a sequence of one to four bytes per character, and that decodes a UTF-8-encoded byte array to Unicode (UTF-16-encoded) characters. Сведения о кодировках символов, поддерживаемых .NET, и обсуждении используемой кодировки Юникод см. в разделе Кодировка символов в .NET.For information about the character encodings supported by .NET and a discussion of which Unicode encoding to use, see Character Encoding in .NET.
UTF8EncodingОбъект, возвращаемый этим свойством, может не иметь соответствующего поведения для приложения.The UTF8Encoding object that is returned by this property might not have the appropriate behavior for your app.
-
Он возвращает UTF8Encoding объект, который предоставляет метку порядка байтов Юникода (BOM).It returns a UTF8Encoding object that provides a Unicode byte order mark (BOM). Чтобы создать экземпляр кодировки UTF8, которая не предоставляет СПЕЦИФИКАЦИю, вызовите любую перегрузку UTF8Encoding конструктора.To instantiate a UTF8 encoding that doesn’t provide a BOM, call any overload of the UTF8Encoding constructor.
-
Он возвращает UTF8Encoding объект, который использует резервную замену, чтобы заменить каждую строку, которая не может быть закодирована, и каждый байт, который не может быть декодирован символом вопросительного знака («?»).It returns a UTF8Encoding object that uses replacement fallback to replace each string that it can’t encode and each byte that it can’t decode with a question mark («?») character. Вместо этого можно вызвать конструктор для создания экземпляра UTF8Encoding объекта, резерв которого является либо EncoderFallbackException или DecoderFallbackException , как показано в следующем примере.Instead, you can call the constructor to instantiate a UTF8Encoding object whose fallback is either an EncoderFallbackException or a DecoderFallbackException, as the following example illustrates.
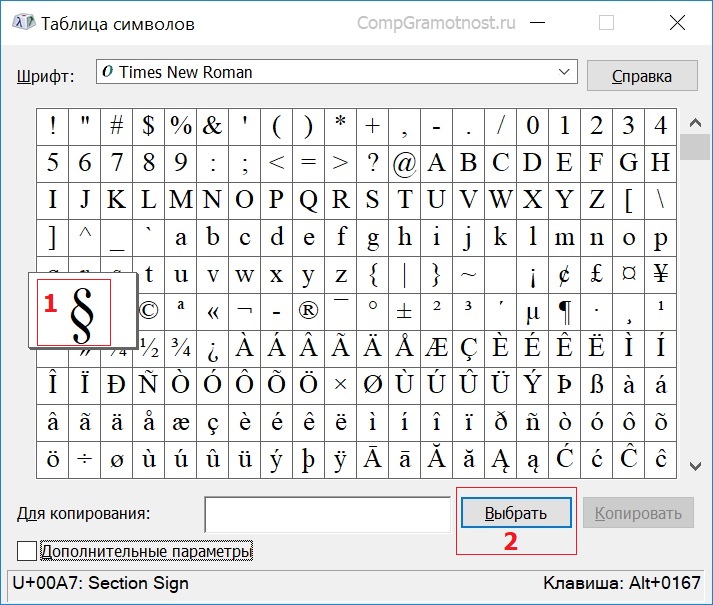
Символы стрелок в UTF8
| Название | Изображение | Код в UTF8 |
|---|---|---|
| Стрелка влево | ← | ← |
| Стрелка вправо | → | → |
| Стрелка вверх | ↑ | ↑ |
| Стрелка вниз | ↓ | ↓ |
| Двойная стрелка в стороны | ↔ | |
| Двойная стрелка вврех-вниз | ↕ | |
| Стрелки влево-вправо | ⇄ | ⇄ |
| Стрелки вверх-вниз | ⇅ | ⇅ |
| Угловая вниз-влево | ↲ | ↲ |
| Угловая вниз-вправо | ↳ | ↳ |
| Угловая вверх-влево | ↰ | ↰ |
| Угловая вверх-вправо | ↱ | ↱ |
| Закруглённая влево | ↶ | ↶ |
| Закруглённая вправо | ↷ | ↷ |
| Круглая вверх-влево | ↺ | ↺ |
| Круглая вверх-вправо | ↻ | ↻ |
| Толстая стрелка вправо | ➔ | ➔ |
| Стрелка зигзаг вниз | ↯ | ↯ |
| Стрелка северо-запад | ↖ | |
| Толстая юго-запад | ➘ | ➘ |
| Толстая вправо | ➙ | ➙ |
| Толстая северо-восток | ➚ | ➚ |
| Пунктирная стрелка вправо | ➟ | ➟ |
| Точечная стрелка влево | ⇠ | ⇠ |
| Угловатая стрелка вправо | ➤ | ➤ |
| Светлая стрелка влево | ⇦ | ⇦ |
| Светлая стрелка вправо | ⇨ | ⇨ |
| Двойная стрелка влево | « | |
| Двойная стрелка вправо | » | |
| Треугольная стрелка вправо | ► | ► |
| Треугольная стрелка влево | ◀ | |
| Треугольная стрелка вверх | ▲ | ▲ |
| Треугоьная стрелка вниз | ▼ | ▼ |
| Светлый треугольник вправо | ▷ | ▷ |
| Светлый треугольник влево | ◁ | ◁ |
| Светлый треугольник вверх | △ | △ |
| Светый треугольник вниз | ▽ | ▽ |
| Стрела лука | ➴ | ➴ |