Sql: union all operator
Содержание:
- Пример — одиночное поле с тем же именем
- Примеры
- JOIN-соединения – операции горизонтального соединения данных
- Set Operator
- Пример с одним полем
- Другие случаи объединения запросов к одной таблице с помощью оператора SQL UNION
- UNION
- Логические операторы SQLite
- Примеры
- Demo Database
- SQL References
- Правила использования
- Итоги и индивидуальные значения в одной таблице с помощью оператора SQL UNION
Пример — одиночное поле с тем же именем
Давайте посмотрим, как использовать SQL оператор UNION, который возвращает одно поле. В этом простом примере поле в обоих операторах SELECT будет иметь одинаковое имя и тип данных. Например.
PgSQL
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNION SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
В этом SQL примере оператора UNION, если supplier_id появилось в таблицах suppliers и orders, оно будет один раз в вашем наборе результатов. Оператор UNION удаляет дубликаты. Если вы не хотите удалить дубликаты, попробуйте использовать оператор UNION ALL. Теперь давайте рассмотрим этот пример, далее приведем некоторые данные. Если у вас была таблица suppliers, заполненная следующими записями.
| supplier_id | supplier_name |
|---|---|
| 1000 | Yandex |
| 2000 | |
| 3000 | Oracle |
| 4000 | Bing |
И таблица orders заполнена следующими записями.
| order_id | order_date | supplier_id |
|---|---|---|
| 2019-07-01 | 2000 | |
| 2019-07-01 | 6000 | |
| 2019-07-02 | 7000 | |
| 2019-07-03 | 8000 |
И вы выполнили следующий запрос UNION.
PgSQL
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM orders
ORDER BY supplier_id;
|
1 2 3 4 5 6 |
SELECTsupplier_id FROMsuppliers UNION SELECTsupplier_id FROMorders ORDERBYsupplier_id; |
Вы получите следующие результаты.
| supplier_id |
|---|
| 1000 |
| 2000 |
| 3000 |
| 4000 |
| 6000 |
| 7000 |
| 8000 |
Как видно из этого примера, UNION взял все значения supplier_id из таблицы suppliers, а также из таблицы orders и возвратил комбинированный набор результатов. Поскольку оператор UNION удалил дубликаты между результирующими наборами, поле supplier_id 2000 отображается только один раз, даже если оно находится в таблицах suppliers и orders. Если вы не хотите удалять дубликаты, попробуйте вместо этого использовать оператор UNION ALL.
Примеры
Использование UNION при выборке из двух таблиц
Даны две таблицы:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Сергей | 5000 |
| person | amount |
|---|---|
| Иван | 2000 |
| Алексей | 2000 |
| Петр | 35000 |
При выполнении следующего запроса:
(SELECT * FROM sales2005) UNION (SELECT * FROM sales2006);
получается результирующий набор, однако порядок строк может произвольно меняться, поскольку ключевое выражение не было использовано:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Иван | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
В результате отобразятся две строки с Иваном, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Использование UNION ALL при выборке из двух таблиц
Применение дает другой результат, так как дубликаты не скрываются. Выполнение запроса:
(SELECT * FROM sales2005) UNION ALL (SELECT * FROM sales2006);
даст следующий результат, выводимый без упорядочивания ввиду отсутствия выражения :
| person | amount |
|---|---|
| Иван | 1000 |
| Иван | 2000 |
| Алексей | 2000 |
| Алексей | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
Использование UNION при выборке из одной таблицы
Аналогичным образом можно объединять два разных запроса из одной и той же таблицы (хотя вместо этого, как правило, необходимые параметры комбинируют в одном запросе при помощи ключевых слов AND и OR в условии WHERE):
(SELECT person, amount FROM sales2005 WHERE amount=1000) UNION (SELECT person, amount FROM sales2005 WHERE person like 'Сергей');
В результате получится:
| person | amount |
|---|---|
| Иван | 1000 |
| Сергей | 5000 |
Использование UNION как внешнее объединение
При помощи можно создавать также (иногда используется в случае отсутствия встроенной прямой поддержки внешних объединений):
(SELECT *
FROM employee
LEFT JOIN department
ON employee.DepartmentID = department.DepartmentID)
UNION
(SELECT *
FROM employee
RIGHT JOIN department
ON employee.DepartmentID = department.DepartmentID);
Но при этом необходимо помнить, что это все же не одно и то же, что и оператор .
JOIN-соединения – операции горизонтального соединения данных
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
- JOIN – левая_таблица JOIN правая_таблица ON условия_соединения
- LEFT JOIN – левая_таблица LEFT JOIN правая_таблица ON условия_соединения
- RIGHT JOIN – левая_таблица RIGHT JOIN правая_таблица ON условия_соединения
- FULL JOIN – левая_таблица FULL JOIN правая_таблица ON условия_соединения
- CROSS JOIN – левая_таблица CROSS JOIN правая_таблица
| Краткий синтаксис | Полный синтаксис | Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) |
|---|---|---|
| JOIN | INNER JOIN | Из строк левой_таблицы и правой_таблицы объединяются и возвращаются только те строки, по которым выполняются условия_соединения. |
| LEFT JOIN | LEFT OUTER JOIN | Возвращаются все строки левой_таблицы (ключевое слово LEFT). Данными правой_таблицы дополняются только те строки левой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк правой_таблицы вставляются NULL-значения. |
| RIGHT JOIN | RIGHT OUTER JOIN | Возвращаются все строки правой_таблицы (ключевое слово RIGHT). Данными левой_таблицы дополняются только те строки правой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк левой_таблицы вставляются NULL-значения. |
| FULL JOIN | FULL OUTER JOIN | Возвращаются все строки левой_таблицы и правой_таблицы. Если для строк левой_таблицы и правой_таблицы выполняются условия_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия_соединения, NULL-значения вставляются на место левой_таблицы, либо на место правой_таблицы, в зависимости от того данных какой таблицы в строке не имеется. |
| CROSS JOIN | — | Объединение каждой строки левой_таблицы со всеми строками правой_таблицы. Этот вид соединения иногда называют декартовым произведением. |
- Это короче и не засоряет запрос лишними словами;
- По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN;
- Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих.
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Set Operator
Let’s get into the details of Set Operators in SQL Server, and how to use them
There are four basic Set Operators in SQL Server:
- Union
- Union All
- EXCEPT
- INTERSECT
Union
The Union operator combines the results of two or more queries into a distinct single result set that includes all the rows that belong to all queries in the Union. In this operation, it combines two more queries and removes the duplicates.
For example, the table ‘A’ has 1,2, and 3 and the table ‘B’ has 3,4,5.
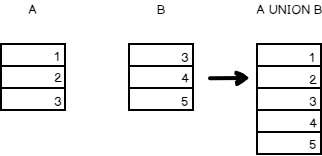
The SQL equivalent of the above data is given below
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) SELECT3 UNION SELECT4 UNION SELECT5 ); |
In the output, you can see a distinct list of the records from the two result sets
Union All
When looking at Union vs Union All we find they are quite similar, but they have some important differences from a performance results perspective.
The Union operator combines the results of two or more queries into a single result set that includes all the rows that belong to all queries in the Union. In simple terms, it combines the two or more row sets and keeps duplicates.
For example, the table ‘A’ has 1,2, and 3 and the table ‘B’ has 3,4,5.
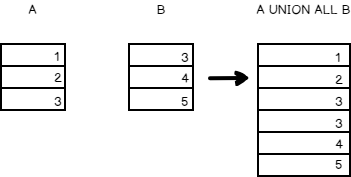
The SQL equivalent of the above data is given below
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) UNIONALL ( SELECT3 UNION SELECT4 UNION SELECT5 ); |
In the output, you can see all the rows that include repeating records as well.
INTERSECT
The interest operator keeps the rows that are common to all the queries
For the same dataset from the aforementioned example, the intersect operator output is given below
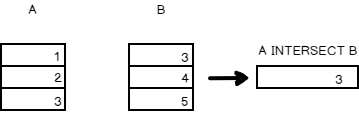
The SQL Representation of the above tables
|
1 |
( SELECT1ID UNION SELECT2 UNION SELECT3 ) SELECT3 UNION SELECT4 UNION SELECT5 ); |
The row ‘3’ is common between the two result sets.
EXCEPT
The EXCEPT operator lists the rows in the first that are not in the second.
For the same dataset from the aforementioned example, the Except operator output is given below
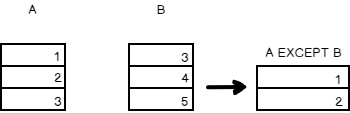
The SQL representation of the above tables with EXCEPT operator is given below
|
1 |
( SELECT1Non-CommonfromonlyA UNION SELECT2 UNION SELECT3 ) SELECT3B UNION SELECT4 UNION SELECT5 ); |
List the non-common rows from the first set.
Note: It is very easy to visualize a set operator using a Venn diagram, where each of the tables is represented by intersecting shapes. The intersections of the shapes, where the tables overlap, are the rows where a condition is met.
Пример с одним полем
Следующий пример Oracle оператора UNION, возвращает одно поле из двух запросов SELECT (и оба поля имеют один и тот же тип данных):
SELECT supplier_id
FROM suppliers
UNION
SELECT supplier_id
FROM order_details;
|
1 2 3 4 5 |
SELECTsupplier_id FROMsuppliers SELECTsupplier_id FROMorder_details; |
В этом примере оператора UNION, если supplier_id присутствует в обоих таблицах suppliers и order_details, то supplier_id появляется один в наборе результатов. Оператор Oracle UNION удаляет дубликаты. Если вы не хотите, чтобы дубликаты были удалены, попробуйте использовать Oracle оператора UNION ALL.
Другие случаи объединения запросов к одной таблице с помощью оператора SQL UNION
Пример 4. В базе данных фирмы есть таблица Staff, содержащая
данные о сотрудниках фирмы. В ней есть столбцы
Salary (размер заработной платы), Job (должность) и Years (длительность трудового стажа).
Первый запрос нужен для получения данных о сотрудниках, заработная плата которых более 21000:
SELECT ID, Name
FROM STAFF WHERE SALARY > 21000
Результатом выполнения запроса будет следующая таблица:
| ID | Name |
| 140 | Fraye |
| 160 | Molinare |
| 260 | Jones |
Второй запрос возвращает имена сотрудников, должность которых «менеждер», а число
лет трудового стажа — менее 8:
SELECT ID, Name
FROM STAFF WHERE Job = ‘Mgr’ AND Years ORDER BY ID
Результатом выполнения запроса будет следующая таблица:
| ID | Name |
| 10 | Sanders |
| 30 | Marenghi |
| 100 | Plotz |
| 140 | Fraye |
| 160 | Molinare |
| 240 | Daniels |
Теперь требуются данные, в которых объединены критерии отбора, применённые в двух
запросах. Объединяем запросы при помощи оператора UNION:
SELECT ID, Name
FROM STAFF WHERE SALARY > 21000
UNION
SELECT ID, Name
FROM STAFF WHERE Job = ‘Mgr’ AND Years ORDER BY ID
Результатом выполнения запроса с оператором UNION будет следующая таблица:
| ID | Name |
| 10 | Sanders |
| 30 | Marenghi |
| 100 | Plotz |
| 140 | Fraye |
| 160 | Molinare |
| 240 | Daniels |
| 260 | Jones |
Запрос с оператором UNION может возвращать и большее количество столбцов, важно, повторимся, чтобы в объединяемых
запросах число столбцов,
порядок их следования и типы данных совпадали.
Теперь работаем с базой данных «Портал объявлений — 1». Скрипт для создания этой базы данных, её таблицы и заполения таблицы данных —
в файле по этой ссылке
Пример 5. Есть база данных портала объявлений.
Пусть сначала требуется получить данные о категориях и частях категорий объявлений,
в которых подано более 100 объявлений в неделю. Пишем следующий запрос:
SELECT Category, Part, Units, Money
FROM ADS WHERE Units > 100
Результатом выполнения запроса будет следующая таблица:
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Музыка | 117 | 7605 |
Теперь требуется извлечь данные о категориях и частях категорий объявлений, за
которые выручено более 10000 денежных единиц в неделю. Пишем следующий запрос:
SELECT Category, Part, Units, Money
FROM ADS WHERE Money > 10000
Результатом выполнения запроса будет следующая таблица:
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Регипс | 112 | 11760 |
Теперь требуется извлечь данные, которые соответствуют критериям и первого, и второго запросов.
Объединяем запросы при помощи оператора UNION:
SELECT Category, Part, Units, Money
FROM ADS WHERE Units > 100
UNION
SELECT Category, Part, Units, Money
FROM ADS WHERE Money > 10000
Результатом выполнения запроса будет следующая таблица:
| Транспорт | Автомашины | 110 | 17600 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Музыка | 117 | 7605 |
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, DELETE, HAVING.
UNION
Последнее обновление: 20.07.2017
Оператор UNION подобно inner join или outer join позволяет соединить две таблицы. Но в отличие от inner/outer join
объединения соединяют не столбцы разных таблиц, а два однотипных набора в один. Формальный синтаксис объединения:
SELECT_выражение1 UNION SELECT_выражение2 SELECT_выражениеN]
Например, пусть в базе данных будут две отдельные таблицы для клиентов банка (таблица Customers) и для сотрудников банка (таблица Employees):
USE usersdb;
CREATE TABLE Customers
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(20) NOT NULL,
LastName NVARCHAR(20) NOT NULL,
AccountSum MONEY
);
CREATE TABLE Employees
(
Id INT IDENTITY PRIMARY KEY,
FirstName NVARCHAR(20) NOT NULL,
LastName NVARCHAR(20) NOT NULL,
);
INSERT INTO Customers VALUES
('Tom', 'Smith', 2000),
('Sam', 'Brown', 3000),
('Mark', 'Adams', 2500),
('Paul', 'Ins', 4200),
('John', 'Smith', 2800),
('Tim', 'Cook', 2800)
INSERT INTO Employees VALUES
('Homer', 'Simpson'),
('Tom', 'Smith'),
('Mark', 'Adams'),
('Nick', 'Svensson')
Здесь мы можем заметить, что обе таблицы, несмотря на наличие различных данных, могут характеризоваться двумя общими атрибутами —
именем (FirstName) и фамилией (LastName). Выберем сразу всех клиентов банка и его сотрудников из обеих таблиц:
SELECT FirstName, LastName FROM Customers UNION SELECT FirstName, LastName FROM Employees
В данном случае из первой таблицы выбираются два значения — имя и фамилия клиента. Из второй таблицы Employees также
выбираются два значения — имя и фамилия сотрудников. То есть при объединении количество выбираемых столбцов и их тип
совпадают для обеих выборок.
При этом названия столбцов объединенной выборки будут совпадать с названия столбцов первой выборки. И если мы захотим при этом еще произвести сортировку,
то в выражениях ORDER BY необходимо ориентироваться именно на названия столбцов первой выборки:
SELECT FirstName + ' ' +LastName AS FullName FROM Customers UNION SELECT FirstName + ' ' + LastName AS EmployeeName FROM Employees ORDER BY FullName DESC
В данном случае каждая выборка имеет по одному столбцу, который представляет объединение имени и фамилии клиента или сотрудника.
Но в случае с клиентами столбец будет называться FullName, а в случае с сотрудниками — EmployeeName. Тем не менее для сортировки применяется название столбца из первой выборки и он же будет в результирующей выборке:
Если же в одной выборке больше столбцов, чем в другой, то они не смогут быть объединены. Например, в следующем случае объединение завершится с ошибкой:
SELECT FirstName, LastName, AccountSum FROM Customers UNION SELECT FirstName, LastName FROM Employees
Также соответствующие столбцы должны соответствовать по типу. Так, следующий пример завершится с ошибкой из-за не соответствия по типу данных:
SELECT FirstName, LastName FROM Customers UNION SELECT Id, LastName FROM Employees
В данном случае первый столбец первой выборки имеет тип NVARCHAR, то есть хранит строку. Первый столбец второй выборки — Id имеет тип INT, то есть хранит число.
Если оба объединяемых набора содержат в строках идентичные значения, то при объединении повторяющиеся строки удаляются.
Например, в случае с таблицами Customers и Employees сотрудники банка могут быть одновременно его клиентами и содержаться в обеих таблицах.
При объединении в примерах выше всех дублирующиеся строки удалялись. Если же необходимо при объединении сохранить все, в том числе повторяющиеся строки, то для этого необходимо использовать оператор ALL:
SELECT FirstName, LastName FROM Customers UNION ALL SELECT FirstName, LastName FROM Employees
Объединять выборки можно и из одной и той же таблицы. Например, в зависимости от суммы на счете клиента нам надо начислять ему определенные проценты:
SELECT FirstName, LastName, AccountSum + AccountSum * 0.1 AS TotalSum FROM Customers WHERE AccountSum < 3000 UNION SELECT FirstName, LastName, AccountSum + AccountSum * 0.3 AS TotalSum FROM Customers WHERE AccountSum >= 3000
В данном случае если сумма меньше 3000, то начисляются проценты в размере 10% от суммы на счете. Если на счете больше 3000, то
проценты увеличиваются до 30%.
НазадВперед
Логические операторы SQLite
Вот список всех логических операторов, доступных в SQLite.
| Оператор | Описание |
| AND | Оператор AND допускает существование множества условий в предложении WHERE оператора SQL. |
| BETWEEN | Оператор BETWEEN используется для поиска значений, находящихся в пределах набора значений, с учетом минимального значения и максимального значения. |
| EXISTS | Оператор EXISTS используется для поиска наличия строки в указанной таблице, соответствующей определенным критериям. |
| IN | Оператор IN используется для сравнения значения со списком литеральных значений, которые были указаны. |
| NOT IN | Отрицание оператора IN, которое используется для сравнения значения со списком значений буквального значения, которые были указаны. |
| LIKE | Оператор LIKE используется для сравнения значения с аналогичными значениями с помощью подстановочных операторов. |
| GLOB | Оператор GLOB используется для сравнения значения с аналогичными значениями с помощью подстановочных операторов. Кроме того, GLOB чувствителен к регистру, в отличие от LIKE. |
| NOT | Оператор NOT меняет смысл логического оператора, с которым он используется. Например. НЕ СУЩЕСТВУЕТ, НЕ МЕЖДУ, НЕ ВХОДИТ и т. Д. Это оператор отрицания. |
| OR | Оператор OR используется для объединения нескольких условий в предложение WHERE оператора SQL. |
| IS NULL | Оператор NULL используется для сравнения значения со значением NULL. |
| IS | Оператор IS работает как = |
| IS NOT | Оператор IS работает как! = |
| || | Добавляет две разные строки и создает новую. |
| UNIQUE | Оператор UNIQUE выполняет поиск каждой строки указанной таблицы для уникальности (без дубликатов). |
Примеры
Использование UNION при выборке из двух таблиц
Даны две таблицы:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Сергей | 5000 |
| person | amount |
|---|---|
| Иван | 2000 |
| Алексей | 2000 |
| Петр | 35000 |
При выполнении следующего запроса:
(SELECT * FROM sales2005) UNION (SELECT * FROM sales2006);
получается результирующий набор, однако порядок строк может произвольно меняться, поскольку ключевое выражение не было использовано:
| person | amount |
|---|---|
| Иван | 1000 |
| Алексей | 2000 |
| Иван | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
В результате отобразятся две строки с Иваном, так как эти строки различаются значениями в столбцах. Но при этом в результате присутствует лишь одна строка с Алексеем, поскольку значения в столбцах полностью совпадают.
Использование UNION ALL при выборке из двух таблиц
Применение дает другой результат, так как дубликаты не скрываются. Выполнение запроса:
(SELECT * FROM sales2005) UNION ALL (SELECT * FROM sales2006);
даст следующий результат, выводимый без упорядочивания ввиду отсутствия выражения :
| person | amount |
|---|---|
| Иван | 1000 |
| Иван | 2000 |
| Алексей | 2000 |
| Алексей | 2000 |
| Сергей | 5000 |
| Петр | 35000 |
Использование UNION при выборке из одной таблицы
Аналогичным образом можно объединять два разных запроса из одной и той же таблицы (хотя вместо этого, как правило, необходимые параметры комбинируют в одном запросе при помощи ключевых слов AND и OR в условии WHERE):
(SELECT person, amount FROM sales2005 WHERE amount=1000) UNION (SELECT person, amount FROM sales2005 WHERE person like 'Сергей');
В результате получится:
| person | amount |
|---|---|
| Иван | 1000 |
| Сергей | 5000 |
Использование UNION как внешнее объединение
При помощи можно создавать также (иногда используется в случае отсутствия встроенной прямой поддержки внешних объединений):
(SELECT *
FROM employee
LEFT JOIN department
ON employee.DepartmentID = department.DepartmentID)
UNION
(SELECT *
FROM employee
RIGHT JOIN department
ON employee.DepartmentID = department.DepartmentID);
Но при этом необходимо помнить, что это все же не одно и то же, что и оператор .
Demo Database
In this tutorial we will use the well-known Northwind sample database.
Below is a selection from the «Customers» table:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Obere Str. 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
And a selection from the «Suppliers» table:
| SupplierID | SupplierName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Exotic Liquid | Charlotte Cooper | 49 Gilbert St. | London | EC1 4SD | UK |
| 2 | New Orleans Cajun Delights | Shelley Burke | P.O. Box 78934 | New Orleans | 70117 | USA |
| 3 | Grandma Kelly’s Homestead | Regina Murphy | 707 Oxford Rd. | Ann Arbor | 48104 | USA |
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
Правила использования
Существуют два основных правила, регламентирующие порядок использования оператора :
- Число и порядок извлекаемых столбцов должны совпадать во всех объединяемых запросах;
- Типы данных в соответствующих столбцах должны быть совместимы.
Определения столбцов, данные из которых извлекаются в объединяемых запросах, не должны совпадать, однако должны быть совместимыми путём неявного преобразования. Если типы данных различаются, то получившийся тип данных определяется на основе правил очередности типов данных (для конкретной СУБД). Если типы совпадают, но различаются в точности, масштабе или длине, результат определяется на основе правил, используемых для объединения выражений (для конкретной СУБД). Типы не определенные ANSI, такие как DATA и BINARY, обычно должны совпадать с другими столбцами такого же нестандартного типа.
В Microsoft SQL Server столбцы с типом данных XML должны быть эквивалентными. Все столбцы должны либо иметь тип, определенный в XML-схеме, либо быть нетипизированными. Типизированные столбцы должны относиться к одной и той же коллекции XML-схем.
Ещё одно ограничение на совместимость — это запрет пустых значений (NULL) в любом столбце объединения, причем эти значения необходимо запретить и для всех соответствующих столбцов в других запросах объединения, поскольку пустые значения (NULL) запрещены с ограничением NOT NULL. Кроме того, нельзя использовать UNION в подзапросах, а также нельзя использовать агрегатные функции в предложении SELECT запроса в объединении (однако большинство СУБД пренебрегают этими ограничениями).
Итоги и индивидуальные значения в одной таблице с помощью оператора SQL UNION
Одним запросом можно вывести из таблицы индивидуальные значения столбцов, например, число лет, проработанных
сотрудниками фирмы, размеры их заработной платы и другие. Другим запросом — с использованием
агрегатных функций — можно получить,
например, сумму заработных плат, получаемых сотрудниками отделов или занимающих те или иные должности, или
среднее число лет трудового стажа
(в таких запросах применяется группировка с помощью оператора GROUP BY).
А если нам требуется получить в одной таблице и сводку всех индивидуальных значений, и итоговые значения?
Здесь на помощь приходит оператор SQL UNION, с помощью которого два запроса объединяются. К результату
объединения требуется применить упорядочение, используя оператор ORDER BY. Для чего это необходимо,
будет лучше понятно из примеров.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Пример 1. В базе данных фирмы есть таблица Staff, содержащая
данные о сотрудниках фирмы. В ней есть столбцы
Salary (размер заработной платы), Job (должность) и Years (длительность трудового стажа).
Первый запрос возвращает индивидуальные размеры заработной платы, упорядоченные по должностям:
SELECT Name, Job, Salary
FROM STAFF ORDER BY Job
Результатом выполнения запроса будет следующая таблица:
| Name | Job | Salary |
| Sanders | Mgr | 18357.5 |
| Marenghi | Mgr | 17506.8 |
| Pernal | Sales | 18171.2 |
| Doctor | Sales | 12322.4 |
| Factor | Sales | 16228.7 |
Второй запрос вернёт суммарную заработную плату по должностям. Мы уже готовим этот запрос
для соединения с первым, поэтому будем помнить, что условием соединения является равное число столбцов,
совпадение их названий, порядка следования и типов данных. Поэтому включаем в таблицу с итогами также
столбец Name с произвольным значением ‘Z-TOTAL’:
SELECT ‘Z-TOTAL’ AS Name, Job, SUM(Salary) AS Salary
FROM STAFF GROUP BY Job
Результатом выполнения запроса будет следующая таблица:
| Name | Job | Salary |
| Z-TOTAL | Mgr | 35864.3 |
| Z-TOTAL | Sales | 46722.3 |
Теперь объединим запросы при помощи оператора UNION и применим оператору ORDER BY
к результату объединения. Группировать следует по двум столбцам: должность (Job) и имя (Name), чтобы
строки с итоговыми (суммарными) значениями, в которых значение имени — ‘Z-TOTAL’, находились ниже строк
с индивидуальными значениями. Объединение результатов запросов будет следующим:
(SELECT Name, Job, Salary
FROM STAFF)
UNION
(SELECT ‘Z-TOTAL’ AS Name,
Job, SUM(Salary) AS Salary
FROM STAFF GROUP BY Job)
ORDER BY Job, Name
Результатом выполнения запроса с оператором UNION будет следующая таблица, в которой
каждая первая строка в каждой группе должностей будет содержать суммарную заработную плату
сотрудников, работающих на этой должности:
| Name | Job | Salary |
| Marenghi | Mgr | 17506.8 |
| Sanders | Mgr | 18357.5 |
| Z-TOTAL | Mgr | 35864.3 |
| Doctor | Sales | 12322.4 |
| Factor | Sales | 16228.7 |
| Pernal | Sales | 18171.2 |
| Z-TOTAL | Sales | 46722.3 |
Написать запросы с использованием UNION самостоятельно, а затем посмотреть решение
Пример 2. Данные — те же, что в примере 1, но задача немного
посложнее. Требуется вывести в одной таблице не только индивидуальные размеры заработной платы,
упорядоченные по должностям и суммарную заработную плату по должностям, но суммарную заработную плату
по всем сотрудникам.
Пример 3. В базе данных фирмы есть таблица Staff, содержащая
данные о сотрудниках фирмы. В ней есть столбцы
Name (фамилия), Dept (номер отдела), и Years (длительность трудового стажа).
| Name | Dept | Years |
| Sanders | 20 | 7 |
| Pernal | 20 | 8 |
| Marenghi | 38 | 5 |
| Doctor | 20 | 5 |
| Factor | 38 | 8 |
Вывести в одной таблице
средний трудовой стаж по отделам и индивидуальные значения длительности трудового стажа сотрудников,
сгруппированных по номерам отделов.