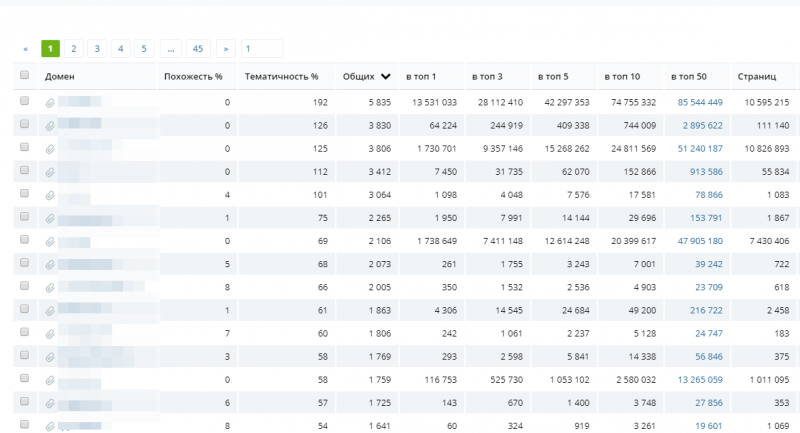
Seo-анализ текста
Содержание:
- Разберем основные параметры оптимизации
- Основы анализа семантического ядра
- Синтаксический анализ
- Где взять уникальный контент?
- Программы для проверки текста на уникальность
- Частота термов
- Что такое семантическое ядро и почему оно так важно?
- Проведение SEO-анализа текста
- SEO-инструменты анализа структуры сайта
- Что нужно знать SEO-специалисту
- Результаты семантического анализа текстов
- Проверка разметки от «Яндекса»
- Валидатор разметки от Яндекса
- Screaming Frog SEO Spider
- Программа Screaming Frog SEO Spider
- Majento SiteAnalyzer
- Что такое семантическое ядро сайта?
- Стоит ли составлять семантику?
Разберем основные параметры оптимизации
В результате разберем следующие основные параметры оптимизации, на которые нужно обратить внимание:
- Знаки без пробелов, с ними, различные ошибки. Здесь, я думаю, сложности возникнуть не должно.
- Наличие уникальных слов. Эти слова могут встречаться в статье всего раз. Если число будет повторяться более двух раз, то уже считается неуникальным.
- Значимые слова. Они определяют полезность содержимого. Учитываются имена существительные.
- Стоп-слова. Как правило, они не подразумевают смысла. К ним относятся: так, вот, или, на, как и другие. Они просто служат для связки словосочетаний в предложении.
- «Вода». Это соотношение значимых слов к общему объему, то есть они не значат информационную ценность. Средний показатель в этом случае считается около 60-75%. Для некоторых распространенных тем этот показатель может быть и несколько больше, это тоже нужно учитывать.
Основы анализа семантического ядра
Чтобы выполнить качественный анализ семантического ядра, необходимо запомнить главные термины — частотность и конкурентность, а также усвоить принцип выстраивания иерархии. К SEO-продвижению нужно относиться серьезно, поскольку это один из главных элементов высокой выдачи сайта в поисковиках, влияющий на доход веб-мастера в Интернете.
Сначала выявим основы SEO-оптимизации по частотности запросов. Необходимо ответить, что такое ВЧ, СЧ, НЧ?
- ВЧ – высокочастотный запрос.
- СЧ – среднечастотный.
- НЧ – низкочастотный.
Отношение того или иного запроса к конкретному типу определяется популярностью слов и фраз, задаваемых пользователями при поиске, а также тематикой блога. При этом строгих правил разделения запросов нет. Чтобы лучше это понять, возьмем приблизительные значения обращений: ВЧ — свыше 2000 в месяц, СЧ — от 1000 до 2000, НЧ — менее 1000. Для определения частотности можно пользоваться сервисом Яндекс.Вордстат.
Рекомендуемые статьи по данной теме:
- Практические советы по раскрутке сайта
- Анализ контента сайта: 9 этапов + сервисы помощники
- Все, что вы хотели знать про услуги продвижения сайта
И всё равно, проводя анализ семантического ядра блога, вам недостаточно будет просто составить список ключей только на основании частотности. Необходимо понять, что такое конкурентность, проанализировать параметры сайтов-соперников, то есть оценить потенциальный успех SEO-продвижения. Для этого, помимо частоты запросов, следует опираться еще на три категории:
- ВК – высококонкурентные.
- СК – среднеконкурентные.
- НК – низкоконкурентные.
Рассчитать частотность ключей нетрудно. А вот с оценкой конкурентности всё сложнее. Чтобы было проще, уравнивают показатели: ВЧ = ВК, СЧ = СК, НЧ = НК. Иногда так делать категорически нельзя. Так, в определенных тематиках СЧ-запросы очень перспективны для продвижения в топ поисковой выдачи. Как правило, это специфические выражения или фразы, в написании которых допущена ошибка. Есть также перечень НЧ-запросов, которые настолько часто используются на сайтах конкурентов, что их даже не нужно индексировать.
Веб-специалисту полезно рассмотреть и проанализировать еще три понятия SEO-оптимизации:
- Первичные запросы. Общие ключевые слова, соответствующие теме блога. Так, для блога «Заработок в Интернете» подходят слова: «баннеры», «реклама», «бизнес», «игры», «форекс» и другие.
- Основные запросы. Это список ключей из СЧ и НЧ, по которым реально повысить позиции сайта с минимальными усилиями и в сжатые сроки. Так, для вышеприведенного примера подойдут: «как заработать на сайте», «размещение баннеров», «контекстная реклама google», «бизнес в Интернете», «лучший форекс брокер», «онлайн-игры на реальные деньги» и т. д.
- Дополнительные запросы (ассоциативные). Значение ключей для поиска бывает схожим. Например, при анализе словосочетания «семантическое ядро» основой подобных фраз будет: «поисковая оптимизация», «SEO», «продвижение сайта в поисковиках».
Основа анализа при разработке сайта требуется для того, чтобы предоставить пользователю нужную ему информацию.
Если правильно применять понятия «конкурентность» и «частотность» запросов, то случайного посетителя блога можно превратить в постоянного и лояльного гостя.
Синтаксический анализ
| Название | Метод | Языки | Лицензия | Платформа |
|---|---|---|---|---|
| грамматика HPSG | русский, английский, немецкий | LGPL | Linux, Windows | |
| машинное обучение | русский, английский | Бесплатная для исследовательских целей + коммерческая | Веб-сервис, Java, Python | |
| MaltParser | машинное обучение | русский, английский | Java | |
| максимизация остовного дерева | английский, португальский | Apache License | Java | |
| Link Grammar Parser | грамматика связей | русский, английский | BSD | Linux, Windows |
| грамматика аффиксов над конечной решёткой | русский, английский, французский, испанский, арабский | GPL | Linux, Windows | |
| машинное обучение | английский | Apache License | Python | |
| машинное обучение | английский | GPL | Python | |
| правила, регулярные выражения | английский, испанский, немецкий, французский, итальянский, нидерландский | BSD | Python | |
| правила | русский, английский | Коммерческая | Linux, Windows | |
| правила | русский | Коммерческая | Windows | |
| правила | русский, английский | Коммерческая | Windows | |
| правила | русский | Коммерческая | FreeBSD, Windows | |
| правила | русский, английский | н/д | Windows | |
| функциональная модель языка | русский | Коммерческая | Веб-сервис | |
| машинное обучение | английский, немецкий, арабский, китайский, болгарский, итальянский, португальский | GPL | Java | |
| машинное обучение | английский, китайский, румынский | GPL v3 | C++ | |
| машинное обучение | английский, немецкий, китайский, испанский | GPL v2 | Java | |
| машинное обучение | русский | некоммерческая | .NET on Linux, Windows |
Где взять уникальный контент?
Проверить статью достаточно просто: поможет Адвего проверка текста на уникальности и другие аналогичные ресурсы. Однако закономерно возникает и вопрос того, где взять подходящий контент для своего сайта. Есть несколько вариантов.
РерайтРерайтом называется переписывание существующего текста своими словами, с использованием синонимизации, сменой порядка расположения слов. Это простейший и дешевый вариант, который не требует значительных усилий и трат. Биржа Адвего предоставляет заработок авторам таким образом.Основной недостаток подобного выбора кроется в стремительном развитии поисковых систем. Все чаще они могут распознавать рерайт и не признавать его уникальность, со всеми вытекающими отрицательными последствиями для сайта.
Частично проблему решает Адвего Антиплагиат проверка, ведь последние версии программы работают с разными показателями и позволяют ориентироваться в качестве готового материала
Но при заказе или создании рерайта следует сохранять осторожность и бдительность.
КопирайтКопирайт предполагает создание авторских текстов с нуля. Такой вариант будет уникальным и чаще всего гораздо более содержательным
При создании таких текстов можно учесть все особенности и пожелания, адаптируя информацию под потребности конкретного сайта.
Копирайт хорошо воспринимается поисковыми системами, а Адвего Антиплагиат обычно не вызывает проблем
Важно, чтобы текст был грамотным, читабельным и написанным в подходящем стиле, с учетом специфики целевой аудитории.
Копирайтом можно заняться самостоятельно или привлечь специалистов. Кроме того, существуют биржи готового контента, где можно подобрать подходящий материал на свой вкус
В качестве такой биржи контента может использоваться сайт Адвего.
Переводы
В международном интернет пространстве существует огромное количество материалов на разных языках. Среди них наверняка найдется информация на любую тему, включая узкоспециализированные направления.
Грамотный переводчик с легкостью справится с поставленной задачей. Главное соблюдать осторожность, выдерживая стиль и терминологию.
Перевод должен быть выполнен исключительно профессионально, и это поможет получит уникальный, интересный и полезный текст, широкую аудиторию и высокое ранжирование страницы.
Запись
Достаточно оригинальный и малораспространенный метод, предполагающий конвертацию аудио- и видеоматериалов в текстовый формат. Для преобразования речи существуют специальные программы. Также это можно сделать вручную.
После записи главное тщательно проверить Адвего уникальность, чтобы не выяснилось, что такая статья уже существует.
Также публикация должна быть тщательно отредактирована на предмет ошибок, опечаток и других проблем, которые возникают при работе с конвертерами.
Веб-архив
Достаточно сомнительный метод, но в некоторых случаях он может прийтись весьма кстати. Для этого требуется изучить «мертвые» сайты, на страницах которых находились уникальные материалы. Для поиска таких сайтов существуют специальные сервисы и программы.
Важно помнить, что огромное количество конкурентоспособного контента уже было разобранное предприимчивыми мастерами. Необходимо также контролировать уникальность, и тогда такой вариант может помочь в наполнении сайта.
Размножение статейРазмножение статей предполагает получение нескольких копий одного материала, которые будут уникальны для поисковых систем.
Чаще всего этот метод подходит для размножения объявлений или описаний, которые не предполагают значительной свободы действий и формулировок.
Размножить статьи можно вручную или при помощи специального программного обеспечения. Это достаточно продолжительная и кропотливая работа, которая требует внимательности и тщательного подхода.
После размножения текст редактируется, запускается Адвего проверка, и лишь тогда материал готов к публикации.
Программы для проверки текста на уникальность
Самые надежные и бесплатные методы проверки своего текста на уникальность – это установить программы на компьютер. Работаю быстро, предоставляют полный отчет и нет ограничения по числу совершаемых проверок.
eTXT Проверка уникальности
На мой взгляд лучшая программа для проверки текста на уникальность. Удобный интерфейс, достаточно быстрая работа, расширенные настройки, а главное эта программа бесплатная.
Скачиваем файл с официального сайта, а затем устанавливаем, после установки программа будет называться AntiPlagiarism.NET.
Если планируется много проверять или большие объемы, то рекомендую сразу настроить автоматический ввод защитной капчи.
Меню Операции, далее Настройки, вкладка Другие, выбираем пункт использовать сервис антикапчи. На выбор три ресурса:
- rucaptcha.com – сервис ручного распознавания капчи.
- anti-captcha.com – популярный, надежный, сервис, с невысокой стоимостью, использую именно его.
- captcha24.com – уже не работает.
Выбрав нужный, регистрируемся, пополняем баланс, находим специальный ключ, копируем его и вставляем в настройки программы AntiPlagiarism.NET.
Для начала указываем статью и запустить проверку.
После анализа, будет небольшой отчет, в котором показан не уникальный текст, каждое такое предложение будет выделено своим цветом, а ниже в разделе “Журнал” будет указано откуда он заимствован.
В приложении доступно четыре варианта:
- стандартная;
- экспресс;
- глубокая;
- на рерайт.
Они отличаются своим методом, скоростью и конечно итоговым результатом. Поэтому рекомендую проверять двумя разными вариантами.
Помимо основных вариантов, если дополнительные такие как:
Пакетная проверка – можно проверить сразу несколько текстов, для это открываем меню Операции, пункт Пакетная обработка, указываем директорию, в которой находятся файлы, выбираем метод, причем есть возможность проверить нужный текст или файл, с файлами, которые хранятся на компьютере, для этого нужно выбрать кнопку Локальная проверка. Открыв пункт Дополнительные опции, появляется возможность отсортировать файлы по папкам, указав критерий уникальности.
Проверка сайта – удобная опция, которая позволяет достаточно быстро проверить страницы сайта на уникальность. Для этого открывает меню Операции, пункт Проверка сайта, далее указывает адрес сайта, нажимаем закачать, далее выбираем вариант проверки.
- SEO – проверка — это небольшой сервис, который проведет “легкий” аудит сайта, например можно узнать дату регистрации домена, число страниц в поисковой системе Yandex, Google и т. д.
- Уникальность изображений – сейчас очень много магазинов по покупке изображений, поэтому есть возможность проверить уникально ли оно. Меню Операции, пункт Уникальность изображений, далее выбираем изображение и ждем. Процесс не быстрый. Ниже будет указано уникально или нет и будут даны адреса сайтов с похожими или неуникальными изображениями.
Сравнение текстов – удобная опция, для сравнения двух текстов. Одинаковый текст выделяется цветом, а также есть отчет об уникальности текста. Меню Операции, пункт Сравнение текстов, указываем первый и второй, нажимаем сравнить.
Advego Plagiatus
Самая известная, бесплатная программа для проверки уникальности текста. Advego — это прежде всего огромная биржа контента, поэтому в их арсенале есть сильный и отличный инструмент по проверке текста.
Также у Advego есть сервис по распознаванию капчи – advego.com/anticaptcha.
При запуске, сразу открывается дополнительное меню, где можно выбрать вариант ввода:
Для анализа готовой статьи, нажмите пункт “написать текст в программе”, далее набираем текст и выбираем вариант проверки: быстрая или полная.
После того как Advego Plagiatus проверит, будет отчет, а на вкладке Журнал, отображается отчет проверки и адреса сайтов. Вкладка Результат – покажет какой именно текст заимствован и с какого сайта.
Старайтесь всегда проверять свои работы на уникальность, это как минимум спасет Вас от неловких ситуаций, а также узнать кто заимствовал Ваш текст, статью, дипломную работу.
Результаты голосования!
TEXT.RU
3
ETXT.RU
2
CONTENT-WATCH.RU
1
ANTIPLAGIAT.RU
MIRALINKS.RU
-2
А также читайте мою статью “Как сделать скриншот экрана на компьютере“.
До скорой встречи!
Частота термов
Один из основных подходов заключается в подсчете частоты встречаемости каждого слова(в нашем случае слово это “терм”) в каждой статье (статьи будем назвать “документами”). Затем документы можно представить как числовые векторы в которых хранятся значения частот повторения термов. В результате у нас будет большая матрица термов документов в которой каждый элемент tdi, j представлен частотой с которой терм ti встречается в документе dj. Ниже представлен пример такой матрицы. Для ее составления мы использовали наш набор статей.

Значения нуля в нашей матрице показаны как пустые ячейки, что довольно сильно повышает читаемость таблички. Колонка справа показывает значения для статьи, которую мы использовали как запрос для поиска схожести, тут она показана для сравнения.
В нашем примере с матрицей сейчас не учитывается сходство слов и их последовательность. Мы просто считаем частоту с которой они встречаются в документе, независимо от того где они встречаются. Сразу заметно что в таком случае третья статья имеет больше всего совпадений по термам с нашим запросом. Это сходство подтверждается сравнением косинусных сходство векторов из нашего набора с нашим запросом.
Косинусное сходство это математическая мера схожести двух числовых векторов. По сути, оно вычисляется через разницу между углами сравниваемых векторов. Для более полного понимания что такое косинусное сходство стоит почитать статью Кристиана Перона. Схожесть векторов выражается числом от 0 (полностью противоположные векторы) до 1 (абсолютно одинаковые векторы), чем ближе значение к 1 тем больше сходство. Сравнив наш запрос с каждым вектором мы получим результаты, показанные ниже:

По результатам видно, что наиболее близкая к нашему запросу статья как раз та самая .
Несмотря на то, что у нас получился неплохой результат, у нашего подхода есть несколько недостатков. Если внимательно посмотреть на результаты и нашу матрицу, то видно что второй документ имеет только одно совпадение с нашим запросом (the), а значение схожести аж . Так происходит, потому что слово the встречается дважды и в запросе и в документе. Для сравнения, первый документ семантически намного ближе к нашему запросу, но оценка схожести отличается очень незначительно. Мы должны исправить обе эти проблемы и начнем с первой: избавимся от слов, которые портят оценку, но не несут сематической нагрузки, такие как , , и т.д.
Что такое семантическое ядро и почему оно так важно?
Перечень ключевых слов и фраз, которые характеризуют направление и тематику сайта, называют семантическим ядром. Оно позволяет понять, пользуется ли спросом информация, товар, услуга, и выстроить грамотную структуру ресурса.
Термин «семантическое ядро» встречается часто. Что это такое? Поговорим о механизме работы поисковой системы. Мы вводим запрос (ключевое слово) и получаем перечень страниц, максимально релевантных нашему запросу и оптимизированных под него. Семантическим ядром считается список всех ключей, используемых для продвижения сайта.
Вам обязательно нужно знать и понимать, какие сведения и по каким запросам человек может найти на веб-ресурсе. Если вы не знаете этого, востребованным сайт никогда не станет. То есть SEO-продвижение невозможно без формирования семантического ядра.
Веб-сайт должен привлекать всю целевую аудиторию (ЦА). Для этого требуется:
- сбор полного семантического ядра. Помните, что на один запрос не делают одну страницу;
- кластеризация запросов. После сбора всех ключевых слов их нужно объединить в группы. В них может быть как 5, так и 25 ключей. Каждая группа предназначена для решения одной задачи;
- определение посадочной страницы. Одна страница — на одну группу. На сайте не должно быть двух страниц, решающих одну задачу.
Если вы заинтересованы в нормальном SEO-продвижении своего ресурса, соберите все возможные ключи. Возьмем сайт строительной компании. При выборе запросов мы понимаем, что жилье можно разбить по типам: дом, таунхаус, квартира и т. д. Соответственно подбираются следующие ключевые запросы: купить дом, купить квартиру, купить таунхаус, купить дом с ремонтом и пр.
Итак, мы разбили запросы на все способы и типы. Сейчас наша задача — разместить информацию. Необязательно помещать всё в меню веб-сайта. Лучше распределите данные по страницам разделов и подразделов, создайте блок фильтров. Так вы раскидаете все запросы по сайту и получите дополнительный трафик.
Поэтапное формирование семантического ядра выглядит так:
- Сбор ключевых запросов из многочисленных источников.
- Очистка ядра от неподходящих запросов.
- Объединение и группировка запросов.
- Формирование структуры сайта под данное ядро.
Залог качественного SEO-продвижения сайта заключается в грамотном формировании семантического ядра. Оно несет смысловую нагрузку вашего ресурса. Если человек по запросу не может получить полные (релевантные) сведения о вашем сайте, придется с ним (с сайтом) поработать.
Формирование качественного семантического ядра — долгий процесс. Кто-то предпочитает сбор семантики вручную, но большинство веб-студий делают это автоматизировано, используя специальные сервисы. Как подобрать запросы, что брать за основу? Поговорим об основных источниках ключевых слов.
В первую очередь нужно проанализировать информацию, товары или услуги, которые уже размещены или скоро появятся на сайте. Это — самое главное при работе с семантическим ядром. Ваша задача — максимально глубоко проанализировать проект и понять специфику ниши. У многих веб-специалистов нет возможности полностью изучить чужой бизнес, а потому в этом вопросе непременно нужно взаимодействовать с клиентом. Так, например, вы можете согласовать весь перечень поисковых фраз.
Яндекс-статистика запросов в поисковиках — прекрасное решение для оптимизаторов, позволяющее узнать, что пользователи ищут в Интернете. Всё, что вам нужно сделать — зайти на сервис wordstat.yandex.ru. Подобный инструмент есть и у Google: частота запросов www.google.ru/adwords/. Сервисы предназначены для использования контекстной рекламы, однако и для SEO-оптимизации тоже подходят.
Статистика сайта — отличный источник ключевых слов. Её также необходимо тщательно анализировать, особенно если у сайта уже есть хороший трафик. Накопленные данные позволяют оценить запросы и трафик поведения пользователей на странице (число просмотров, проведенное время, количество отказов).
Чтобы легко и быстро создать качественную структуру сайта, нужно проанализировать веб-ресурсы конкурентов. Необходимо лишь найти нескольких лидеров в вашем сегменте, у которых SEO-структура сформирована грамотно.
Далее есть несколько вариантов:
- анализ видимости конкурентов в поисковиках и получение списка их ключевых слов. Формирование семантического ядра на основе данных запросов или дополнение своего отсутствующими;
- сбор лучших решений из структуры нескольких сайтов конкурентов и создание своей идеальной.
Проведение SEO-анализа текста
Введенный на сервисе Aдвего и проверенный текст получает свою статистику.
Заказчик всегда требует от автора определенное количество символов без пробелов. В сервисе Адвего указывается общее количество символов, а также количество знаков без пробелов.

Как начать работу копирайтером?Начните написание статей ️ по ТЗ или продавайте свои готовые тексты
Проведем анализ значения каждого из параметров, которые выдает проверка.
Уникальными считаются слова, употребленные только один раз на протяжении всего текста.
Значимыми словами являются имена существительные – семантическое ядро текста, а глаголы и прилагательные считаются водой.
У междометий, предлогов и союзов, не несущих смысловой нагрузки участь быть стоп-словами.
Водой называются слова, которые наполняют словами статью и без них она будет меньше, но более бледной и безликой. Эта категория слов определяется математически (деление всего количества значимых слов на весь объем текста).
Классической тошнотой называют ту же воду, также определяемую математически (корень квадратный из всех часто повторяемых слов).
Академическую тошноту вычисляют пропорцией к количеству повторений слов
Нужно обратить внимание, что этот параметр не должен быть по Адвего выше 9-10%. Потому что в противном случае текст в поисковике будет восприниматься переспамленым.
Частота слов по Адвего не должна превышать 3%
Если слово употреблено только один лишний раз – в поисковике статья будет определена, как спамная.
Как только текст будет написан, ее нужно проверить по Адвего не только на грамматику, орфографию, но и сделать анализ на процент воды и тошноты, как классической, так и академической. Проценты должны быть как можно меньше. Но учтите, что тексты, в которых воды нет, практически отсутствуют в сети.
SEO-инструменты анализа структуры сайта
Большое значение для ранжирования страниц сайта имеет его структура.
SEO-анализ перелинковки сайта
Перелинковка сайта это организованная структура переадресаций внутри сайта. Относится перелинковка к внутренней оптимизации сайта. Рассчитывает ссылочные веса страниц сайта.
Сервис Audit от Megaindex
Этот инструмент позволяет сделать бесплатную проверку перелинковки сайта. Адрес инструмента: audit.megaindex.ru.
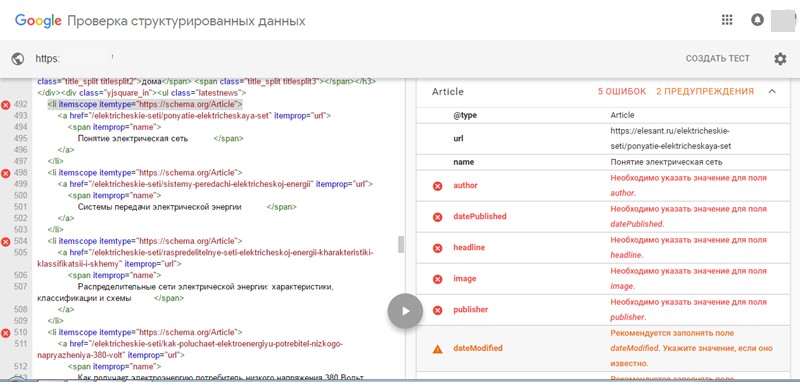
Анализы мета данных и разметки сайта
Для проверки структурированных данных расширенной разметки есть отличный инструмент Google. Адрес инструмента: //www.google.com/webmasters/tools/richsnippets.
Анализ идет по данным разметки:
- @type (тип публикации)
- url (адрес)
- name (название)
- cancelauthor (автор)
- canceldatePublished (дата публикации)
- cancelheadline
- cancelimage
- cancelpublisher
Мастер разметки структурированных данных от Google
С помощью этого инструмента можно посмотреть разметку сайта с найденными ошибками. Адрес: //www.google.com/webmasters/markup-helper/
Валидатор микрозаметки Яндекс
Этот инструмент вы найдете в инструментах веб мастеров Яндекс на своем аккаунте. Он позволяет проверить семантическую разметку на сайте и посмотреть, как роботы ПС могут извлекать структурированные данные. https://webmaster.yandex.ru/tools/microtest/
Что нужно знать SEO-специалисту
- Семантические модели хорошо подходят для охвата синонимов, связанных слов и семантических фреймов. Система связанных фреймов может образовывать семантическую сеть. Семантическая сеть – это набор слов, которые обозначают объекты предметной области и задают отношения между ними. Например, семантическая сеть чая «Золотая чаша» может включать в себя традицию, чай, чашку, чайник, ложку, сахар, напиток и т.д.
- При создании нового контента будет полезно подумать о семантических фреймах. Т.е. учитывать семантическую структуру, по которой вы хотите продвигать вашу страницу в ТОП, а не конкретное ключевое слово.
- Игра с контентом, скорее всего, мало что даст. Синонимичные слова, такие как квартира и апартаменты, будут иметь очень похожие векторы. При замене слов в тексте на слова синонимы мы получим текст, который будет близок к исходному варианту с точки зрения поисковой системы.
- Поисковые системы стали гораздо лучше находить нужную информацию, но не будет лишним давать им подсказки, используя структурированную разметку данных.
Компьютерная лингвистика – это увлекательная и быстро развивающаяся наука. Концепции, представленные в этой статье, не новы и не революционны. Однако они довольно просты и помогают получить общее представление о проблемном поле.
Результаты семантического анализа текстов
1. Кластеризация вопросов и ответов:
a. выделение ключевых слов и синонимов,
b. выделение одинаковых по смыслу словосочетаний,
c. выделение однотипных вопросов,
d. выделение однотипных ответов.
e. выделение частотных ключевых слов и синонимов,
f. выделение смысловых сочетаний ключевых слов с другими словами,
g. расчет корреляции (морфологической, семантической, векторной) между словами и словосочетаниями.
2. Определение понятий и смысла в вопросах и ответах:
a. выделение понятий с разными уровнями обобщения (центроиды),
b. расчет корреляционной связи между понятиями в вопросе и понятиями в ответе,
c. построение семантического ряда смыслов
d. расчет кратчайшего пути от вопроса к ответу, корреляция вопросов и уточнений в диалоге и последним или последней группой ответов.
3. Классификация вопросов и ответов.
a. Определение сущностей, определение субъекта, объекта и предмета.
4. Статистический анализ текста:
a. Количество синонимов, семантическое ядро, частотность ключевых слов.
5. Автореферирование текста.
6. Определение пропущенных частей речи.
7. Построение карт смыслов.
8. Классификация текстов исходя из данных WikiPedia.
9. Перефразирование текста.
10. Определение тональности текста.
Со слов разработчиков сервиса – сервис абсолютно не привязан к определенной тематике и не имеет ограничений в части объемов и формата данных.
Когда речь идет о статистическом анализе, то здесь все просто – используются комплексные алгоритмы, но, главное, что результат всегда может быть предсказуем. А вот, что касается машинного обучения, то здесь получается «черный ящик». Никогда не известно заранее, что получится на выходе.
Кроме того, для машинного обучения очень важно иметь размеченные тексты. Иными словами, если текст не имеет оценки: верно / неверно или заранее не был классифицирован пользователем, то система сама сделать классификацию не сможет – ей необходимо показать примеры, только после этого нейросеть начинает работать
Вот пример обработки текста чата одного коммерческого банка.
Используем статистический метод обработки текста, получаем:
Самые частотные словосочетания (с весами):
- Открытие счета – 41%;
- Закрытие счета — 34%.
Словосочетания (без весов) ТОП 10:
- счет + открытие
- счет + закрытие
- платеж + не уходит
- платеж + завис
- платеж + ошибка
- платеж + на обработке
- поручение + не исполнено
- поручение + на исполнении
- поручение + на обработке
- поручение + отозвать
Вот так может выглядеть графический интерфейс выдачи результатов анализа.
Проверка разметки от «Яндекса»
Схожий функционал предоставляет и «Яндекс» в своем валидаторе микроразметки. Пользоваться им можно как через «Вебмастер» для зарегистрированного в системе сайта, так и без регистрации, просто по адресу URL или фрагменту кода.
Валидатор разметки от Яндекса
Проверка разметки от Яндекса
Сервис умеет распознавать и находить ошибки в оформлении микроразметки согласно популярным стандартам – OpenGraph, Shema.org, микроданные/микроформаты. Для некорректных элементов выдается соответствующее сообщение.
Screaming Frog SEO Spider
Если онлайн-сервисы не подходят, можно использовать устанавливающиеся на ПК инструменты. Например, утилита для анализа SEO-параметров Screaming Frog SEO Spider даже в бесплатном варианте весьма функциональна, несмотря на ограничение в 500 адресов.
Программа Screaming Frog SEO Spider
Screaming Frog SEO Spider
Пользователь может отыскать на сайте нерабочие ссылки, выявить ошибки и редиректы, проанализировать метаданные, исследовать директивы для поисковых роботов, проверить атрибуты ссылок, найти дубликаты страниц и т. д. Платная версия лишена ограничений и умеет делать множество дополнительных проверок, интегрироваться с системами аналитики, работать с AMP-страницами, плюс сопровождается технической поддержкой.
Majento SiteAnalyzer
Альтернативный инструмент – программа SiteAnalyzer от ресурса Majento.ru. По функциональности она является неплохой заменой Screaming Frog, при этом предоставляется бесплатно.
Что такое семантическое ядро сайта?
Семантическое ядро сайта — это сгруппированные в отдельные категории ключевые запросы (слова) соответствующие тематике вашего сайта и позволяющие пользователям через поисковую систему (Яндекс или Google) найти Ваш сайт в интернете.
Хорошо проработанное семантическое ядро позволит каждой странице вашего ресурса соответствовать определенным запросам пользователей и поможет Вам эффективно продавать свои продукты и услуги, а так же вы сможете привлечь целевую аудитории на сайт.
Основные понятия и термины в семантике
Запросы (ключевые слова) — собираются поисковой системой (Яндекс или Google) для статистики и используются поисковиками при расчете бюджета рекламной кампании Яндекс Директ или Google AdWords.
Для сбора семантического ядра Вам необходимо определить список услуг и товаров которые вы хотите продвигать, и выбрать по каким именно запросам ваши товары или услуги будут искать пользователи и покупатели.
Первым делом для составления семантики необходимо выписать все самые важные слова характеризующие тематику вашего сайта, далее написать предположительно к каждой категории слов, фразы и словосочетания по которым пользователи могут искать Вас в сети (ваши товары или услуги).
Далее каждое словосочетание необходимо проверить на сервисе подбора ключевых слов и добавить слова в семантическое ядро. Но не торопитесь набирать все подряд запросы и пытаться по ним быть в топе.
Для более точного сбора ядра запросов необходимо понимать какие виды запросов бывают, и какие виды запросов подойдут Вашему сайту.
Какие виды запросов бывают
Самое важное значение по которому сортируют запросы Seo оптимизаторы это частотность запросов. Есть 3 основные категории запросов:
Высокочастотные запросы (ВЧ) — самые популярные запросы в основном состоящие из 1- 2 слов и характеризующие тематику в общем. Многие оптимизаторы делят частотность исходя из цифр и начинают ВЧ запросы от 3000 — 5000 тысяч запросов в месяц. Я лично считаю такой подход неподходящим, и характеризую ВЧ запросы как запросы имеющие наибольшую популярность в тематике и характеризующие тематику в целом.
Среднечастотные запросы (СЧ) — запросы менее популярны и имеют обычно от 2-4 слов, а так же носят более точный характер и направленность как по географическому смыслу так и практическому. Продвижение по среднечастотным запросам на мой взгляд наиболее эффективное и целевое, дает отличный результат.
Низкочастотные запросы (НЧ) — самые непопулярные запросы состоящие из 4-7 слов и имеющие точный характер запроса и вполне конкретную миссию. Обычно продвижение по низкочастотным запросам, самое эффективное и быстрое, здесь необходимо действовать по принципу, «чем больше, тем лучше».
Кроме частотности для правильного сбора семантического ядра для нового сайта, так же необходимо понимать насколько конкурентен запрос. Определить конкурентность запроса можно очень просто.
Введите запрос в поисковую строку и вы уведите количество страниц в базе поисковика соответствующих запросу. Чем выше конкуренция тем сложней попасть в ТОП-10 по данному словосочетанию.
По конкурентности запросы бывают:
- Высококонкурентные (ВК)
- Среднеконкурентные (СК)
- Низкоконкурентные (НК)
Стоит ли составлять семантику?
Если вы открыли эту статью, то вас, определенно, интересует и этот вопрос тоже. Сбор семантики кажется поначалу очень муторным и тяжелым делом. Причем пользователи не всегда понимают, зачем это вообще нужно.
Если мы говорим о блоге, причем созданном с целью заработка, то у авторов таких проектов возникает вполне резонный вопрос: где, собственно, брать вдохновение и про что вообще писать. Если у вас будет готовая таблица со всеми темами и ключевыми словами, то вы точно будете знать, о чем написать свой материал. Такой подход позволит не только не сбавлять темпа, но даже и увеличить, потому как вам не придется ломать голову над темой очередной статьи. Останется только выбрать из предложенного списка и решить для себя, как именно написать тот или иной материал.
Вместе с этим все ваши статьи (при условии грамотного написания текстов и соблюдения частотности ключей) будут неплохо вылетать в топ поисковых запросов, что обеспечит вам посещаемость, и это будет еще больше подогревать ваш интерес и мотивировать на новые свершения. Заманчиво же, правда? И все это благодаря одному единственному элементу – семантике, сбор которой у вас не займет много времени.
Для сбора семантики под контекст одного СловоЁБа будет мало. Придется покупать его расширенную версию, именуемую Кей Коллектором. Программа имеет большое количество разных опций, предназначенных как раз для работы с разными контекстными сетями (Директ, Адвордс и т. д.)
Подводя итог, приходим к выводу, что составлять семантику определенно стоит. Это повышает качество продвижения вашего ресурса и позволяет вам на порядок лучше ориентироваться в потребностях пользователей при составлении контент-плана.