Парсеры вордстата
Содержание:
- Оффлайн парсеры
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Парсинг вопросов-ответов в результатах поиска
- Что такое поисковые подсказки и зачем они нужны
- Сервисы для парсинга
- Парсеры сайтов в зависимости от используемой технологии
- Где найти поисковые подсказки в виде вопросов и как собрать
- Программы парсеры
- Определение перспективных ключевых фраз
- Советы и рекомендации по использованию программ для парсинга
- Легальные, «белые» методы формирования подсказок
- Парсим запросы из поисковой выдачи или сайтов конкурентов
Оффлайн парсеры
Возможность парсинга Яндекс Вордстат без доступа к интернету или при его низкой скорости – одно из требований к современным инструментам СЕО анализа. Технически это реализовано просто – на компьютер или аналогичное устройство, скачивается базы Wordstat и затем с помощью программы происходит выборка ключевых слов.
Букварикс десктопная версия
Впервые полноценный десктопный вариант представили разработчики «Букварикс». Однако уже в октябре 2017 года этот проект был «заморожен», ПО и базы данных не обновляются. Компания предлагает все инструменты в онлайн-режиме. Скачать приложение можно на старой версии официального сайта, использование бесплатное.
Что нужно учитывать при использовании десктопной версии:
- скачиваемый объем – около 30 Гбайт;
- скачать можно только с Яндекс.Диска, состоит из 20 частей;
- последняя дата обновления БД – 1 октября 2017 г.
Информация в этой версии устарела, возможно использование как вспомогательного инструмента.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» — в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист — это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом — все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Парсинг вопросов-ответов в результатах поиска
Вопросы/ответы можно извлекать и вручную из результатов поиска. Но зачем, если есть шаблон от Hannah Rampton?
Это один из шаблонов, который мы используем при поиске идей для контента и постановке ТЗ копирайтерам. Анализ вопросов, связанных с основным запросом, позволяет углубиться в тему и создать интент-ориентированный контент (подробнее — в нашей статье об алгоритме Neural Matching).
Для выгрузки вопросов/ответов:
- создайте копию шаблона Google Q&A Extraction_v2;
- установите бесплатное расширение Scraper для Chrome (оно парсит данные с веб-страниц с помощью XPath);
- измените в настройках поисковика язык с русского на английский (это нужно для корректной работы формул в шаблоне).
Приступаем к парсингу вопросов/ответов:
в открывшемся окне в блоке «Selector» выбираем «XPath», вводим в поле запрос для парсинга раскрывающихся списков с вопросами/ответами: //g-accordion-expander (обратите внимание, чтобы блок Columns был заполнен так же, как на скриншоте);
нажимаем «Scrape»;
- после парсинга нажимаем «Copy to clipboard»;
- открываем шаблон, переходим на лист «Google Questions and Answers», наводим курсор на ячейку А10 и нажимаем Ctrl+Shift+V.
Если все сделано верно, то поля с вопросами, ответами и URL заполнятся автоматически.
На листе «Clean Data» та же информация представлена в юзабельном текстовом формате (кроме того, здесь исключены дубли).
На листе «Search by Keyword» вы можете найти вопросы по заданному ключевому слову (или его части).
Также вы можете выбрать вопросы по домену — для этого на листе «Search by Domain» введите полный URL или его часть.
Таким образом, вы быстро и бесплатно найдете релевантные вопросы по вашей тематике.
Что такое поисковые подсказки и зачем они нужны
Поисковые подсказки — это фразы, которые появляются в виде списка автозаполнения, как только пользователь начинает вводить искомую фразу в поисковой строке.
Поисковые подсказки в Google:

Поисковые подсказки в Яндексе:

Поисковые подсказки в YouTube:

По одной и той же фразе поисковики выдают разные подсказки. Дело в том, что каждый поисковик формирует подсказки по собственным алгоритмам. Но есть ряд общих факторов, которые объединяют все поисковые системы.
Что учитывают поисковые системы при подборе поисковых подсказок:
- Популярность поискового запроса в данный момент времени (актуальные и трендовые запросы вроде «что такое инаугурация» или «что такое криптовалюта» выводятся в первую очередь).
- История пользовательского поиска (каждый пользователь склонен просматривать страницы определенных тематик чаще других, и поисковики формируют подсказки в зависимости от интересов).
- Местоположение пользователя (учитывается актуальность запросов для конкретного региона).
- Фактор разнообразия (поисковые системы «подмешивают» варианты подсказок из разных тематик, чтобы повысить вероятность того, что пользователь воспользуется автоподстановкой).
Подсказки обновляются не реже одного раза в день, в отличие от баз Вордстата и Keyword Planner. Поэтому они более актуальны на данный момент времени, отражают текущие тренды и потребности аудитории.
Фразы из подсказок значительно расширяют и дополняют базовую семантику (в том числе LSI-фразами), позволяют поймать «горячий» и сезонный трафик. Среди них вы наверняка найдете ключи, которых не выдаст ни Вордстат, ни Keyword Planner.

В итоге у вас целый перечень дополнительных LSI-фраз (названия популярных моделей газонокосилок Bosch и комплектующих), которые стоит упомянуть в тексте.
Сервисы для парсинга
Если у вас не хватает времени на ручной парсинг, есть смысл воспользоваться сторонними сервисами.
Rush-analytics.ru
Парсер работает с Водстат, Google Keywords и Youtube. Чтобы начать поиск, зарегистрируйтесь и нажмите на «Сбор подсказок» в левом меню.
После надо пройти три шага. Если вы следовали инструкции, у вас все готово к запуску. Ниже мы расписали порядок действий для каждого шага.
Шаг первый
Нас интересует парсинг подсказок Youtube. Поэтому убираем галочки с других платформ, ставим галочку на «Подсказки Youtube» и идем дальше.
Шаг второй
Здесь надо настроить параметры ключевых слов и глубину поиска. Сначала разберемся с настройками ключей по всем пунктам и вкратце поясним: что сделает система, если поставить галочку.
- Соберет подсказки по ключевому слову. Базовая настройка.
- Соберет подсказки и поставит перед ним пробел.
- Поставит каждую букву выбранного алфавита на латинице после пробела.
- Поставит каждую букву русского алфавита после пробела.
- Поставит цифру возле пробела.
Теперь о глубине парсинга, у нее есть три параметра.
- По умолчанию система просто соберет подсказки по заданным параметрам.
- Если выбрать второй пункт, она сделает поиск по второму кругу.
- И, если выбрать третий пункт, система сработает в три подхода.
Шаг третий
Вставляем ключевые слова. Сделать это можно двумя способами:
- скопировать и вставить список;
- или ввести ключи в таблицу Excel и загрузить её файлом.
После вводим стоп-слова. Готово.
Сервис дает 200 лимитов на баланс, чтобы вы могли затестить работу. А по тарифам — четыре варианта. Смотрите на скриншоте.
Pixelplus.ru
У сервиса много функций. Чтобы не потеряться, вот ссылка на инструмент подсказки ключевых слов Youtube.
В предыдущем примере мы специально подробно расписали шаги. Здесь порядок действий такой же: вводите ключи, глубину парсинга, переборы и пишете стоп-слова.
У сервиса несколько тарифов. Чем выше тариф, тем больше лимитов. Классика.
Keyword Tool
Западный сервис по парсингу. Среди платформ: Google, Youtube, Ebay, Amazon и другие. Есть что-то похожее на пробную версию — вы можете искать ключевые запросы без регистрации, но в ограниченном количестве. Взгляните на скриншот.
Функций не так много. Но сервис удобный.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Где найти поисковые подсказки в виде вопросов и как собрать
Эти сервисы по-своему удобны. Но есть сервис, наиболее подходящий для работы SEO-оптимизатора по созданию семантического ядра для конкретного сайта. Этот сервис называется Prodvigator.
Его особенность в том, что он дает возможность получить рекомендации в виде вопросов. Эти вопросы — реальные запросы пользователей. Отвечая на эти вопросы, можно привлечь большое количество посетителей на ресурс. Пользоваться сервисом достаточно просто:
- Нужно ввести в строку поиска заданный запрос, выбрать поисковую систему и перейти во вкладку «Поисковые подсказки», выйдет большое количество ключевых фраз.
- Более точные данные позволит получить настройка парсинга. Для этого в фильтрах нужно выбрать «Только ключевые слова без топонимов» и прописать вручную слова, которые требуется очистить из выдачи. Перед каждым таким словом необходимо поставить знак минуса. После нажатия кнопки «Применить» выходит уже гораздо меньшее количество ключевых фраз.
- Переход во вкладку «Только вопросы» поможет увидеть список фраз, которые состоят только из вопросов. Их можно использовать для написания статьи, релевантной запросам пользователей.
- Функция «пакетный экспорт» позволит просмотреть поисковые подсказки по нескольким ключевым фразам. Сервис дает возможность ввести до 200 таких фраз и получить поисковые подсказки в Яндексе по каждой в виде отчета. Для этого ключевые фразы вводятся в нужное поле, результаты фильтруются по топонимам и выбираются лишь вопросительные варианты.
Использование этой возможности в создании или расширении существующего семантического ядра позволяет получить список релевантных и актуальных фраз, которые обязательно приведут на сайт трафик. Ведь это именно те запросы, что используют для нахождения товаров и/или услуг реальные пользователи.
По работе с поисковыми подсказками вышла не так давно книга, нашего соотечественника Скорых Михаила. Для того, чтобы вникнуть в суть работы подсказок, как работать с негативными подсказками, формирование их для длинных запросов, какие бонусы это может принести, рекомендуем начать с нее.
Программы парсеры
Для точной обработки ключевых слов рекомендуется использовать программные комплексы. Преимущество – они работают напрямую с базами данных Ворстат. Полная версия платная, некоторые разработчики предоставляют демо-режим с ограниченным функционалом.
Кей Коллектор
Программа «Кей Коллектор» популярна среди разработчиков и СЕО-оптимизаторов. Причины – работа с популярными поисковыми системами, сегментация выборок по параметрам пользователя. Предоставляется только на платной основе, стоимость зависит от количества приобретаемых лицензий.
Особенности «Кей Коллектор»:
- Анализируется только актуальная статистика, сбор информации ведется напрямую из баз данных (БД) Яндекса.
- Ключевые слова подбираются по региону, частоте, сезонности.
- Учитываются стоп-слова.
Возможен многопоточный режим работы. Но есть вероятность получения бана или многократного ввода капчи при формировании нескольких потоков запроса информации с одного IP. Возможен сбор информации через Яндекс.Директ, что уменьшает скорость обработки.
Словоёб
Бесплатная альтернатива Кей Коллектор, но с меньшими функциональными возможностями. Отличие – «Словоёб» работает только с Вордстат. При анализе некоторых ключевых фраз могут не учитываться низкочастотные запросы, которые есть в статистике Яндекс.Директ. Глубина эффективного парсинга ограничена 40 страницами.
Особенности программы «Словоёб»:
- меньшие возможности работы с таблицами;
- нет «поисковых подсказок»;
- отсутствует сбор главных страниц выдачи;
- нет позиций по запросам.
Программа подходит для формирования СЯ небольшого проекта. Причина – скорость обработки полученных данных, нет углубленного анализа запросов.
Магадан
Технические ограничения в бесплатном варианте программы:
- нельзя выбрать региональность для запросов;
- отключены фильтры по количеству символов, слов;
- нет импорта файлов со стоп-словами;
- нельзя задавать правила к генерируемым ключевым фразам;
- отключен экспорт КС.
Несмотря на такие ограничения «Магадан» можно использовать для формирования СЯ 1-3 проектов. Но по отзывам пользователей по сравнению с ручной обработкой Вордстата теряются низкочастотные запросы.
Определение перспективных ключевых фраз
Когда денег на SEO мало (в случае с МСБ это почти всегда так), продвигаться по ядру из тысяч запросов не получится. Придется выбирать самые «жирные» из них, а остальные откладывать до лучших времен.
Один из способов — выбрать фразы, по которым страницы сайта находятся с 5 по 20 позицию в Google. По ним можно быстрее и с меньшими затратами выйти в ТОП-5. Ну и скачок позиций, скажем, с двенадцатой на третью даст намного больше трафика, чем с 100-й на 12-ю (узнать точный прирост трафика вы можете с помощью сценарного прогноза в Data Studio).
Позиции по ключевым фразам в Google доступны в Search Console. Для их выгрузки есть шаблон, описанный в Codingisforlosers.
Для выгрузки ключей из ТОП-20 необходимо:
- создать копию шаблона Quick Wins Keyword Finder (все шаблоны в статье закрыты от редактирования, просьба не запрашивать права доступа — просто создайте копию и используйте ее);
- установить дополнение для Google Sheets Search Analytics for Sheets (для настройки экспорта отчетов из Search Console в Google Sheets);
- иметь доступ к аккаунту в Search Console и накопленную статистику по запросам (хотя бы за пару месяцев).
Открываем шаблон и настраиваем выгрузку данных из Search Console (меню «Дополнения» / «Search Analytics for Sheets» / «Open Sidebar»).
Для автоматической выгрузки на вкладке «Requests»:
- в поле «Verified Site» выбираем сайт (после подтверждения доступа к аккаунту в появится список сайтов);
- в поле «Group By» выбираем «Query» и «Page» (то есть мы будем извлекать данные по запросам и страницам);
- в поле «Results Sheet» обязательно задаем «RAW Data», иначе шаблон работать не будет.
Нажимаем кнопку «Request Data». После экспорт данных на листе «Quick Wins» указаны запросы, страницы, количество кликов, показов, средний CTR и позиция за период. Эти ключи подходят для приоритетного продвижения.
Помимо автоматической выгрузки в шаблоне есть ручной режим. Перейдите на вкладку «MANUAL» и введите данные (ключи, URL и позиции). На вкладке «Quick Wins » будет выборка перспективных запросов.
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).

Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Легальные, «белые» методы формирования подсказок
Грамотная реклама товара или услуги помогает достичь популяризации запроса традиционным, безопасным методом. Цепляя обывателя, она вызывает интерес к бренду, название которого пользователь вводит в строку поиска, движимый эмоциональным порывом. Чем чаще запрос появляется в поиске, тем быстрее появляется подсказка с нужным сочетанием слов.
Способы, повышающие частоту пользовательского запроса:
- тизерная реклама, которая красиво представляет проблему (загадку), за ответом к которой обыватель пойдёт на сайт, создавая запрос;
- активная медийная позиция: участие фирмы в выставках, конференциях, спонсорство. Понятный и заметный логотип непременно привлечёт новых людей, которые захотят узнать больше о компании, обращаясь в поиск;
- использование потенциала известных интернет-блогеров, которые могут активно явно или неявно продвигать товар или услугу.
Теги
Вам также будет интересно
Парсим запросы из поисковой выдачи или сайтов конкурентов
Теперь самое интересное, надо составить семантическое ядро, то есть подготовить список запросов (поисковых фраз), которые вводят люди в поиске, где в будущем должны будут находить вашу площадку.
Собирать запросы сейчас можно огромным количеством способов, но все они сводятся к трем критериям:
- Парсинг бесплатной статистики Wordstat.
- Парсинг собственных баз специальных сервисов.
- Анализ конкурентов.
Wordstat
Больше всего ключевые слова подбирают по данным предоставляемым самим Яндексом, с помощью бесплатного сервиса wordstat.yandex.ru.
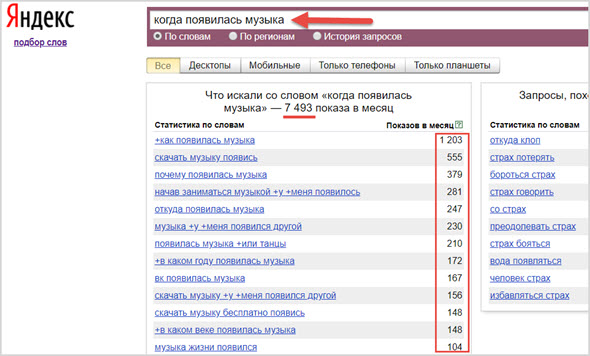
Однако, фильтровать там запросы очень сложно, результаты отображаются только по 50 штук на странице и нет возможности что-либо сортировать или скачивать.
Подробнее о том, какие есть операторы в Вордстате и как их применять на практике смотрите по указанной ссылке.
Базы ключевых слов
Со временем появились сайты, где предлагается купить готовые запросы по различным тематикам и странам.
Думаю все слышали про Мутаген, Букварикс и другие сервисы, где в одном месте собраны миллиарды ключей.
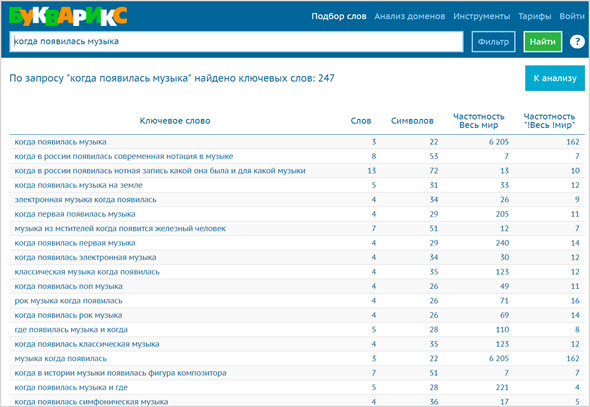
Глупо будет скрывать тот факт, что там присутствуют те же запросы, что вы можете сами спарсить через Вордстат.
Запросы конкурентов
И еще одни популярный метод, которым даже я пользуюсь называется «украсть запросы конкурента». Суть его очень проста, находите трафиковый сайт с такой же тематикой что и ваш и с помощью специальных сервисов скачиваете все ключевые слова по которым он ранжируется в Яндекс и Google.
Лидерами в этом направлении стали:
- SEMrush
- SpyWords
- Mutagen
- Serpstat
- MOAB