Row_number (transact-sql)row_number (transact-sql)
Содержание:
- Notas generalesGeneral Remarks
- C. Four ranking functions used in the same query
- Introduction
- Oracle ROW_NUMBER() examples
- ArgomentiArguments
- Повторное использование определений окон
- АргументыArguments
- MySQL ROW_NUMBER() function examples
- ROW_NUMBER Analytic Function
- Логическая обработка запросов
- ArgumentosArguments
- Возможность создания дополнительных фильтров
- Remarques d’ordre généralGeneral Remarks
- Предложение OVER (Transact-SQL)
- Виды функций
- SQL ROW_NUMBER() Function Overview
- Функция NTILE
Notas generalesGeneral Remarks
No hay ninguna garantía de que las filas devueltas por una consulta con al usar se ordenen exactamente igual con cada ejecución a menos que se cumplan estas condiciones:There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
Los valores de la columna de la partición sean únicos.Values of the partitioned column are unique.
-
Los valores de las columnas sean únicos.Values of the columns are unique.
-
Las combinaciones de los valores de la columna de la partición y las columnas sean únicas.Combinations of values of the partition column and columns are unique.
sea no determinista. is nondeterministic. Para obtener más información, consulte Deterministic and Nondeterministic Functions.For more information, see Deterministic and Nondeterministic Functions.
C. Four ranking functions used in the same query
This example shows the four ranking functions
- DENSE_RANK()
- NTILE()
- RANK()
- ROW_NUMBER()
used in the same query. See each ranking function for function-specific examples.
Here is the result set.
| FirstName | LastName | Row Number | Rank | Dense Rank | Quartile | SalesYTD | PostalCode |
|---|---|---|---|---|---|---|---|
| Michael | Blythe | 1 | 1 | 1 | 1 | 4557045.0459 | 98027 |
| Linda | Mitchell | 2 | 1 | 1 | 1 | 5200475.2313 | 98027 |
| Jillian | Carson | 3 | 1 | 1 | 1 | 3857163.6332 | 98027 |
| Garrett | Vargas | 4 | 1 | 1 | 1 | 1764938.9859 | 98027 |
| Tsvi | Reiter | 5 | 1 | 1 | 2 | 2811012.7151 | 98027 |
| Shu | Ito | 6 | 6 | 2 | 2 | 3018725.4858 | 98055 |
| José | Saraiva | 7 | 6 | 2 | 2 | 3189356.2465 | 98055 |
| David | Campbell | 8 | 6 | 2 | 3 | 3587378.4257 | 98055 |
| Tete | Mensa-Annan | 9 | 6 | 2 | 3 | 1931620.1835 | 98055 |
| Lynn | Tsoflias | 10 | 6 | 2 | 3 | 1758385.926 | 98055 |
| Rachel | Valdez | 11 | 6 | 2 | 4 | 2241204.0424 | 98055 |
| Jae | Pak | 12 | 6 | 2 | 4 | 5015682.3752 | 98055 |
| Ranjit | Varkey Chudukatil | 13 | 6 | 2 | 4 | 3827950.238 | 98055 |
Introduction
The most commonly used function in SQL Server is the SQL ROW_NUMBER function. The SQL ROW_NUMBER function is available from SQL Server 2005 and later versions.
ROW_NUMBER adds a unique incrementing number to the results grid. The order, in which the row numbers are applied, is determined by the ORDER BY expression. Most of the time, one or more columns are specified in the ORDER BY expression, but it’s possible to use more complex expressions or even a sub-query. So, it creates an ever-increasing integral value and it always starts off at 1 and subsequent rows get the next higher value.
You can also use it with a PARTITION BY clause. But when it crosses a partition limit or boundary, it resets the counter and starts from 1. So, the partition may have values 1, 2, 3, and so on and the second partitions again start the counter from 1, 2, 3… and so on, and so forth.
Oracle ROW_NUMBER() examples
We’ll use the table from the sample database to demonstrate the function.
Oracle simple example
The following statement returns the row number, product name and list price from the table. The row number values are assigned based on the order of list prices.
The following picture shows the output:
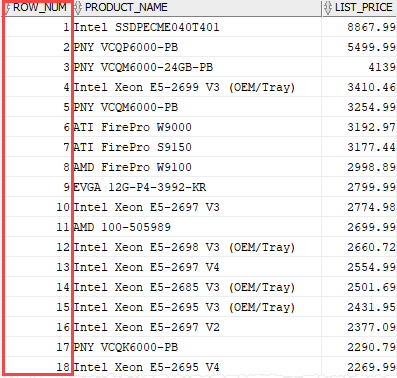
This is a trivial example to just show how the function works.
To effectively use the function, you should use a subquery or a common table expression to retrieve row numbers for a specified range to get the top-N, bottom-N, and inner-N results.
Using Oracle function for pagination
The function is useful for pagination in applications.
Suppose you want to display products by pages with the list price from high to low, each page has 10 products. To display the third page, you use the function as follows:
The output is:

In this example, the CTE used the function to assign each row a sequential integer in descending order. The outer query retrieved the row whose row numbers are between 31 and 40.
Using Oracle function for the top-N query example
To get a single most expensive product by category, you can use the function as shown in the following query:
Here is the output:
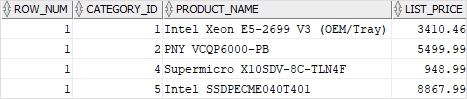
In this example:
- First, the clause divided the rows into partitions by category id.
- Then, the clause sorted the products in each category by list prices in descending order.
- Next, the function is applied to each row in a specific category id. It re-initialized the row number for each category.
- After that, the outer query selected the rows with row number 1 which is the most expensive product in each category.
For the consistent result, the query must return a result set with the deterministic order. For example, if two products had the same highest prices, then the result would not be consistent. It could return the first or second product.
To get more than one product with the same N-highest prices, you can use the or function.
In this tutorial, you have learned how to use the Oracle function to make useful queries such as inner-N, top-N, and bottom-N.
- Was this tutorial helpful?
ArgomentiArguments
PARTITION BY value_expressionPARTITION BY value_expressionSuddivide il set di risultati generato dalla clausola FROM in partizioni alle quali viene applicata la funzione ROW_NUMBER.Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression specifica la colonna in base alla quale viene partizionato il set di risultati.value_expression specifies the column by which the result set is partitioned. Se non viene specificato, la funzione considera tutte le righe del set di risultati della query come un unico gruppo.If is not specified, the function treats all rows of the query result set as a single group. Per altre informazioni, vedere Clausola OVER — (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
order_by_clauseorder_by_clauseLa clausola determina la sequenza in base alla quale alle righe viene assegnato un valore univoco all’interno di una partizione specificata.The clause determines the sequence in which the rows are assigned their unique within a specified partition. Questo argomento è obbligatorio.It is required. Per altre informazioni, vedere Clausola OVER — (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
Повторное использование определений окон
Представьте, что вам нужно вызвать несколько оконных функций в одном запросе, при этом часть определения окна (или все определение) у нескольких функций совпадает. Если указать определение окна во всех функциях, код может сильно увеличиться в объеме, как в этом примере:
В стандартном SQL есть решение этой проблемы в виде предложения, которое называется WINDOW и позволяет присваивать имя определению окна или его части. После этого это имя можно использовать в других определениях окон, используемых в оконных функциях или даже определениях имен других окон. С точки зрения концепции это предложение вычисляется после предложения HAVING и до предложения SELECT.
SQL Server пока не поддерживает предложение WINDOW. В стандартном SQL можно сократить предыдущий запрос с использованием предложения WINDOW так:
Как видите, разница ощутима. В данном случае предложение WINDOW присваивает имя W1 полному определению окна с параметрами секционирования, упорядочения и кадрирования. После этого W1 используется в качестве определения окна во всех четырех функциях. Предложение WINDOW довольно сложное. Как уже говорилось, не обязательно присваивать имя полному определению окна — можно назначать имя только части определения. В таком случае определение окна содержит смесь именованных частей и явно заданных параметров. Кстати сказать, описание предложения WINDOW в стандарте SQL занимает целых десять страниц! И разобраться в них не так-то просто.
Было бы замечательно, если бы в SQL Server добавили поддержку это-го предложения, особенно теперь, когда расширилась поддержка оконных функций и пользователям придется писать длинные определения окон.
АргументыArguments
PARTITION BY value_expressionPARTITION BY value_expressionДелит результирующий набор, полученный от предложения FROM, на секции, к которым применяется функция ROW_NUMBER.Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression определяет столбец, по которому секционируется результирующий набор.value_expression specifies the column by which the result set is partitioned. Если параметр не указан, функция обрабатывает все строки результирующего набора запроса как одну группу.If is not specified, the function treats all rows of the query result set as a single group. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
order_by_clauseorder_by_clauseПредложение определяет последовательность, в которой строкам назначаются уникальные номера с помощью функции в пределах указанной секции.The clause determines the sequence in which the rows are assigned their unique within a specified partition. Оно должно указываться обязательно.It is required. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
MySQL ROW_NUMBER() function examples
Let’s use the table from the sample database for the demonstration:
1) Assigning sequential numbers to rows
The following statement uses the function to assign a sequential number to each row from the table:
Here is the output:
2) Finding top N rows of every group
You can use the function for the queries that find the top N rows for every group, for example, top three sales employees of every sales channel, top five high-performance products of every category.
The following statement finds the top three products that have the highest inventory of every product line:
In this example,
- First, we used the function to rank the inventory of all products in each product line by partitioning all products by product line and ordering them by quantity in stock in descending order. As the result, each product is assigned a rank based on its quantity in stock. and the rank is reset for each product line.
- Then, we selected only products whose rank is less than or equal to three.
The following shows the output:
3) Removing duplicate rows
You can use the to turn non-unique rows into unique rows and then delete the duplicate rows. Consider the following example.
First, create a table with some duplicate values:
Second, use the function to divide the rows into partitions by all columns. The row number will restart for each unique set of rows.
As you can see from the output, the unique rows are the ones whose the row number equals one.
Third, you can use the common table expression (CTE) to return the duplicate rows and delete statement to remove:
Notice that the MySQL does not support CTE based delete, therefore, we had to join the original table with the CTE as a workaround.
4) Pagination using function
Because the assigns each row in the result set a unique number, you can use it for pagination.
Suppose, you need to display a list of products with 10 products per page. To get the products for the second page, you use the following query:
Here is the output:
In this tutorial, you have learned how to use the MySQL function to generate a sequential number for each row in a result set.
- Was this tutorial helpful?
ROW_NUMBER Analytic Function
If you have ever used the pseudocolumn, you will have an idea what the analytic function does. It is used to assign a unique number from 1-N to the rows within a partition. At first glance this may seem similar to the RANK and DENSE_RANK analytic functions, but the function ignores ties and always gives a unique number to each row.
The basic description for the analytic function is shown below. The analytic clause is described in more detail .
ROW_NUMBER() OVER ( order_by_clause)
The analytic function is order-sensitive and produces an error if you attempt to use it without an in the analytic clause. Unlike some other analytic functions, it doesn’t support the windowing clause. Omitting a partitioning clause from the clause means the whole result set is treated as a single partition. In the following example we assign a unique row number to each employee based on their salary (lowest to highest). The example also includes and to show the difference in how ties are handled.
SELECT empno,
ename,
deptno,
sal,
ROW_NUMBER() OVER (ORDER BY sal) AS row_num,
RANK() OVER (ORDER BY sal) AS row_rank,
DENSE_RANK() OVER (ORDER BY sal) AS row_dense_rank
FROM emp;
EMPNO ENAME DEPTNO SAL ROW_NUM ROW_RANK ROW_DENSE_RANK
---------- ---------- ---------- ---------- ---------- ---------- --------------
7369 SMITH 20 800 1 1 1
7900 JAMES 30 950 2 2 2
7876 ADAMS 20 1100 3 3 3
7521 WARD 30 1250 4 4 4
7654 MARTIN 30 1250 5 4 4
7934 MILLER 10 1300 6 6 5
7844 TURNER 30 1500 7 7 6
7499 ALLEN 30 1600 8 8 7
7782 CLARK 10 2450 9 9 8
7698 BLAKE 30 2850 10 10 9
7566 JONES 20 2975 11 11 10
7788 SCOTT 20 3000 12 12 11
7902 FORD 20 3000 13 12 11
7839 KING 10 5000 14 14 12
SQL>
Adding the partitioning clause allows us to assign the row number within a partition. In the following example we assign the row number within the department, based on highest to lowest salary.
SELECT empno,
ename,
deptno,
sal,
ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS row_num
FROM emp;
EMPNO ENAME DEPTNO SAL ROW_NUM
---------- ---------- ---------- ---------- ----------
7839 KING 10 5000 1
7782 CLARK 10 2450 2
7934 MILLER 10 1300 3
7788 SCOTT 20 3000 1
7902 FORD 20 3000 2
7566 JONES 20 2975 3
7876 ADAMS 20 1100 4
7369 SMITH 20 800 5
7698 BLAKE 30 2850 1
7499 ALLEN 30 1600 2
7844 TURNER 30 1500 3
7654 MARTIN 30 1250 4
7521 WARD 30 1250 5
7900 JAMES 30 950 6
SQL>
This allows us to write Top-N queries at the partition level. The following example brings back the best paid person in each department, ignoring ties.
SELECT *
FROM (SELECT empno,
ename,
deptno,
sal,
ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS row_num
FROM emp)
WHERE row_num = 1;
EMPNO ENAME DEPTNO SAL ROW_NUM
---------- ---------- ---------- ---------- ----------
7839 KING 10 5000 1
7788 SCOTT 20 3000 1
7698 BLAKE 30 2850 1
SQL>
Логическая обработка запросов
Логическая обработка запросов описывает принципы оценки запроса SELECT в соответствии с логической системой языка. Она описывает процесс, состоящий из нескольких этапов, или фаз, которые начинаются входными таблицами запроса и заканчиваются результирующим набором запроса.
Заметьте, что под логической обработкой запросов я подразумеваю концепцию оценки запроса, которая не обязательно совпадает с физическим процессом обработки запроса сервером SQL Server. В рамках оптимизации SQL Server может сокращать путь, менять порядок некоторых этапов и делать все, что ему заблагорассудится. Но все это только при условии, что он возвращает тот же результат, который должен получиться при логической обработке запроса при декларативном его определении.
Каждый этап логической обработки запроса работает с одной или несколькими таблицами (наборами строк), которые являются входными данными, и возвращает в качестве результата таблицу. Результирующая таблица одного этапа становится входной для следующего этапа.
На следующем рисунке представлена схема логической обработки запроса в SQL Server 2012:

Заметьте, что при написании запроса предложение SELECT всегда пишется первым, но в процессе логической обработки оно находится практически в самом конце — непосредственно перед обработкой предложения ORDER BY.
Логической обработке запросов можно посвятить целую книгу, но для нашей цели достаточно более лаконичного изложения
Для целей нашей дискуссии важно заметить порядок, в которой обрабатываются разные предложения. Следующий список представляет этот порядок (фазы, в которых разрешены оконные функции, выделены цветом):
-
FROM
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
Вычисление выражений
-
Удаление дубликатов
-
-
ORDER BY
-
OFFSET-FETCH/TOP
Понимание процедуры и порядка логической обработки запросов позволяет понять, почему использование оконных функций разрешили только в определенных предложениях.
ArgumentosArguments
PARTITION BY value_expressionPARTITION BY value_expressionDivide el conjunto de resultados generado por la cláusula FROM en particiones a las que se aplica la función ROW_NUMBER.Divides the result set produced by the FROM clause into partitions to which the ROW_NUMBER function is applied. value_expression especifica la columna a partir de la cual se particiona el conjunto de resultados.value_expression specifies the column by which the result set is partitioned. Si no se especifica , la función trata todas las filas del conjunto de resultados de la consulta como un único grupo.If is not specified, the function treats all rows of the query result set as a single group. Para más información, vea Cláusula OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
order_by_clauseorder_by_clauseLa cláusula determina la secuencia en la que se asigna a las filas el único correspondiente en una partición especificada.The clause determines the sequence in which the rows are assigned their unique within a specified partition. Es obligatorio.It is required. Para más información, vea Cláusula OVER (Transact-SQL).For more information, see OVER Clause (Transact-SQL).
Возможность создания дополнительных фильтров
Я показал, как в T-SQL можно прибегнуть к обходному решению и косвенным образом использовать оконные функции в элементах, которые не поддерживают их напрямую. Это обходное решение основано на применении табличного выражения в форме CTE или производной таблицы. Приятно иметь дополнительный вариант, но в табличном выражении используется дополнительный уровень запроса и все немного усложняется. Приведенные мной примеры просты, но как насчет длинных и сложных запросов. Возможно ли более простое решение без этого дополнительного уровня?
Если говорить об оконных функциях, то в SQL Server на текущий момент нет другого решения. Вместе с тем, интересно посмотреть, как другие справляются с этой проблемой. Например, в Teradata создали фильтрующее предложение, которое называется QUALIFY и принципиально вычисляется после предложения SELECT. Это означает, что в нем можно напрямую обращаться к оконным функциям, как в следующем примере:
Более того, можно ссылаться на псевдонимы столбцов, определенных в списке SELECT, так:
Предложения QUALIFY нет в стандартном SQL — оно поддерживается только в продуктах Teradata. Но оно кажется очень интересным решением, и было бы неплохо, если бы и стандарт, и в SQL Server удовлетворили такую потребность.
Remarques d’ordre généralGeneral Remarks
Rien ne garantit que les lignes renvoyées par une requête utilisant seront ordonnées exactement de la même manière à chaque exécution, sauf si les conditions suivantes sont vérifiées.There is no guarantee that the rows returned by a query using will be ordered exactly the same with each execution unless the following conditions are true.
-
Les valeurs de la colonne partitionnée sont uniques.Values of the partitioned column are unique.
-
Les valeurs des colonnes sont uniques.Values of the columns are unique.
-
Les combinaisons de valeurs de la colonne de partition et des colonnes sont uniques.Combinations of values of the partition column and columns are unique.
n’est pas déterministe. is nondeterministic. Pour plus d’informations, consultez Fonctions déterministes et non déterministes.For more information, see Deterministic and Nondeterministic Functions.
Предложение OVER (Transact-SQL)
Но есть особенности, которые не сразу ясны из официальной документации, либо, вообще, в ней не раскрываются.
Сразу скажу, что если есть возможность не делать партиционирование, то лучше его не делать. Зачастую дешевле увеличить размер памяти у вашего сервера БД, чтобы он начал запросто переваривать большие таблицы. И только когда вы упретесь в то, что такого количества памяти нет в продаже, стоит приступать к активным действиям.
Официальной документации вполне достаточно для того, чтобы партиционирование заработало. Более того, все дальнейшие рассуждения буду мало полезными для тех, кто официальную документацию не читал.
Во-первых, в должны быть IMMUTABLE функции. День у меня ушел на то, чтобы понять, что TIMESTAMP WITH TIME ZONE не является IMMUTABLE.
Пример того, как выглядит генерация триггера на вставку в партиционированную таблицу. Для этой статьи я добавил комментарии для больше понятности, но все равно выглядит громоздко.
После выполнения мы получим 36 новых таблиц в БД и триггер, похожий на этот.
При партиционировании перестает работать , а это значит, что при вставке новой записи нельзя узнать ее id. Для этого существует костыль, который на каждую вставку делает дополнительную вставку и удаление, чтобы получить id записи. Я не рискнул использовать его в бою, поскольку у нас и так очень интенсивная нагрузка на БД.
Более того, надо понимать, что в случае с партиционироваными таблицами, вы можете иметь одинаковые id для разных записей, так как уникальность id проверяется (если проверяется) только на уровне конкретной дочерней таблицы. Если вы вставляете данные только в главную таблицу , то id гарантированно будут отличаться, потому что триггер использует sequence от главной таблицы. Но ничего не запрещает вам вставить в дочернюю таблицу данные напрямую.
Какой выигрыш от такого усложнения? Во-первых, вместо одного большого индекса у вас будет теперь много маленьких, которые помещаются в память. Если вам надо сделать выборку по дате, то seq scan будет идти только по нужным партициям. В нашем случае, например, все запросы, в основном, делаются по последнему месяцу, поэтому она оказывается в кэше БД и, самое главное, помещается туда целиком. А как мы знаем, БД для web-проекта либо помещается в память, либо не работает, но об этом я напишу как-нибудь в другой раз.
Виды функций
Оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать сразу несколько оконных функций. Давайте подробно разберем каждую группу и пройдемся по основным функциям.
Агрегатные функции
Агрегатные функции – это функции, которые выполняют на наборе данных арифметические вычисления и возвращают итоговое значение.
- SUM – возвращает сумму значений в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются);
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце.
Пример использования агрегатных функций с оконной инструкцией OVER:
SELECT Date , Medium , Conversions , SUM(Conversions) OVER(PARTITION BY Date) AS 'Sum' , COUNT(Conversions) OVER(PARTITION BY Date) AS 'Count' , AVG(Conversions) OVER(PARTITION BY Date) AS 'Avg' , MAX(Conversions) OVER(PARTITION BY Date) AS 'Max' , MIN(Conversions) OVER(PARTITION BY Date) AS 'Min' FROM Orders

Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках.
SELECT Date , Medium , Conversions , ROW_NUMBER() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Row_number' , RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Rank' , DENSE_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Dense_Rank' , NTILE(3) OVER(PARTITION BY Date ORDER BY Conversions) AS 'Ntile' FROM Orders

Функции смещения
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LAG или LEAD – функция LAG обращается к данным из предыдущей строки окна, а LEAD к данным из следующей строки. Функцию можно использовать для того, чтобы сравнивать текущее значение строки с предыдущим или следующим. Имеет три параметра: столбец, значение которого необходимо вернуть, количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE или LAST_VALUE — с помощью функции можно получить первое и последнее значение в окне. В качестве параметра принимает столбец, значение которого необходимо вернуть.
SELECT Date , Medium , Conversions , LAG(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lag' , LEAD(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Lead' , FIRST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'First_Value' , LAST_VALUE(Conversions) OVER(PARTITION BY Date ORDER BY Date) AS 'Last_Value' FROM Orders

Аналитические функции
Аналитические функции — это функции которые возвращают информацию о распределении данных и используются для статистического анализа.
- CUME_DIST — вычисляет интегральное распределение (относительное положение) значений в окне;
- PERCENT_RANK — вычисляет относительный ранг строки в окне;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
Важно! У функций PERCENTILE_CONT и PERCENTILE_DISC, столбец, по которому будет происходить сортировка, указывается с помощью ключевого слова WITHIN GROUP
SELECT Date , Medium , Conversions , CUME_DIST() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Cume_Dist' , PERCENT_RANK() OVER(PARTITION BY Date ORDER BY Conversions) AS 'Percent_Rank' , PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Cont' , PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY Conversions) OVER(PARTITION BY Date) AS 'Percentile_Disc' FROM Orders

SQL ROW_NUMBER() Function Overview
The is a window function that assigns a sequential integer number to each row in the query’s result set.
The following illustrates the syntax of the function:
In this syntax,
- First, the clause divides the result set returned from the clause into partitions. The clause is optional. If you omit it, the whole result set is treated as a single partition.
- Then, the clause sorts the rows in each partition. Because the is an order sensitive function, the clause is required.
- Finally, each row in each partition is assigned a sequential integer number called a row number. The row number is reset whenever the partition boundary is crossed.
Функция NTILE
Эта функция позволяет разбивать строки в секции окна на примерно равные по размеру подгруппы (tiles) в соответствии с заданным числом подгрупп и упорядочением окна. Допустим, что нужно разбить строки представления OrderValues на 10 подгрупп одинакового размера на основе упорядочения по val. В представлении 830 строк, поэтому требуется 10 подгрупп, размер каждой будет составлять 83 (830 деленное на 10). Поэтому первым 83 строкам (одной десятой части), упорядоченным по val, будет назначен номер группы 1, следующим 83 строкам — номер подгруппы 2 и т. д. Вот запрос, вычисляющий номера как строк, так и подгрупп:
Если вы думаете, что разбиение на подгруппы похоже на разбиение на страницы, хочу вас предупредить, что не стоит их путать. При разбиении на страницы, размер страницы является константой, а число страниц меняется динамически — оно определяется делением числа строк в результате запроса на размер страницы. При разбиении на подгруппы число подгрупп является константой, а размер подгруппы меняется и определяется как число строк деленное на заданное число подгрупп. Ясно, для чего нужно разбиение на страницы, а разбиение на подгруппы обычно используется для аналитических задач — когда нужно распределить данные среди заданного числа равных по размеру сегментов с использованием упорядочения по определенному измерению.
Но вернемся к результату запроса, вычисляющего номера как строк, так и подгрупп: как видите они тесно связаны друг с другом. По сути, можно считать, что номер подгруппы вычисляется на основе номера строки. В предыдущем разделе мы говорили, что если упорядочение окна не является уникальным, функция ROW_NUMBER является недетерминистической. Если разбиение на подгруппы принципиально основано на номерах строк, то это означает, что вычисление NTILE также недетерминистично, если упорядочение окна не уникально. Это означает, что у данного запроса может быть несколько правильных результатов. Можно посмотреть на это с другой стороны: двум строкам с одним значением упорядочения могут быть назначены разные номера подгрупп. Если нужен гарантированный детерминизм, можно следовать моим рекомендациям по получению детерминистических номеров строк, а именно добавить в упорядочение окна дополнительный параметр:
Теперь у запроса только один правильный результат. Ранее, при описании функции NTILE я пояснил, что она позволяет разбить строки в секции окна на примерно равные подгруппы. Я использовал слово «примерно», потому что число строк, полученное в базовом запросе, может не делиться нацело на число подгрупп. Допустим, вы хотите разбить строки представления OrderValues на 100 подгрупп. При делении 830 на 100 получаем частное 8 и остаток 30. Это означает, что базовая размерность подгрупп будет 8, но часть подгрупп получать дополнительную строку. Функция NTILE не пытается распределять дополнительные строки среди подгрупп с равным расстоянием между подгруппами — она просто добавляет по одному ряду в первые подгруппы, пока не распределит остаток. При наличии остатка 30 размерность первых 30 подгрупп будет на единицу больше базовой размерности. Поэтому первые 30 будут содержать 9 рядов, а последние 70 — 8, как показано в следующем запросе:
Следуя привычному методу, попытаемся создать альтернативные решения, заменяющие функцию NTILE и не содержащие оконных функций.
Я покажу один способ решения задачи. Для начала, вот код, который вычисляет число подгрупп по заданным размерности, числу подгрупп и числу строк:
Вычисление вполне очевидно. Для входных данных код возвращает 5 в качестве числа подгрупп.
Затем применим эту процедуру к строкам представления OrderValues. Используйте агрегат COUNT, чтобы получить размерность результирующего набора, а не входные данные @cnt, а также примените описанную ранее логику для вычисления номеров строк без использования оконных функций вместо входных данных @rownum:
Как обычно, не пытайтесь повторить это в производственной среде! Это пример предназначен для обучения, а его производительность в SQL Server ужасна по сравнению с функцией NTILE.