Кодировка utf
Содержание:
- Введение
- Стандарты TEI и его преобразования
- Способ третий: сохранение
- Текстовое значение
- 1251 – кодовая страница Windows
- 866 – кодовая страница DOS
- Кодировка UNICODE
- Собственный велосипед
- Электронная таблица в 1С средствами табличного документа
- Основные способы кодирования текстовой информации
- Наборы символов, карты символов и кодовые страницы
- Сравнение найденных решений на автоопределение кодировки
- Какая бывает информация?
- Перевод кодировки символов
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождения, название исследований, записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того, что в одном файле часть в кодировке CP1251, а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять, что такое “кракозябры” или “кости”, то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Стандарты TEI и его преобразования
Первоначальная разметка TEI включала все уровни лингвистического анализа, контекстные метаданные всех видов, базовые структурные и функциональные компоненты, дипломатическую транскрипцию, изображения, аннотации, ссылки, соответствия, выравнивание, объекты, содержащие особые данные: дата, время, место, лицо, событие и т.д. (распознавание элементов предметной области), метатекстовую аннотацию (исправления, удаления и т.п.). Но в 2007 году был выпущен новый TEI P5, в котором появились новые характеристики. С одной стороны, в новом формате кодирования появились трудности для разработки программных обработок, анализа и публикации, а с другой стороны, это обеспечило большую гибкость. К примеру, новшество в виде лингвистической разметки, учитывающая разночтения и варианты интерпретации фрагментов текста на разных уровнях языковых структур было трудно совместить с базовыми инструментами лингвистической разметки.
Множество проектов используют TEI для литературоведческих и лингвистических целей. TEI лежит в основе корпуса средневекового французского языка Base de Français Médiéval, на котором тексты размечены в формате XML, на основе TEI в соответствии со спецификацией проекта и с учетом последующего лингвистического анализа.
Стандарт TEI предоставляет богатые возможности для представления разной текстологической информации в электронном виде. Он применяется в различных областях гуманитарного знания и помогает исследователям, которые, с одной стороны, опираются на проработанную систему разметки, а с другой стороны, сами дополняют практику применения TEI собственным опытом.
Видео на русском языке о базовых возможностях TEI:
Видео на русском языке о кодировании именованных сущностей и физических свойств документа:
Способ третий: сохранение
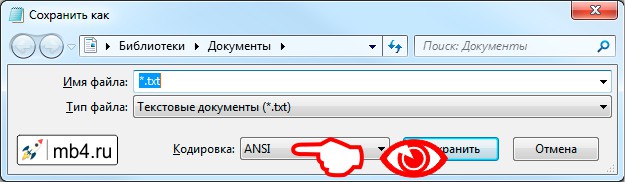
Как изменить кодировку в Excel? Для реализации третьего способа необходимо произвести ряд следующих действий:
- Откройте файл в программе.
- Нажмите «Файл».
- Выберите «Сохранить как».
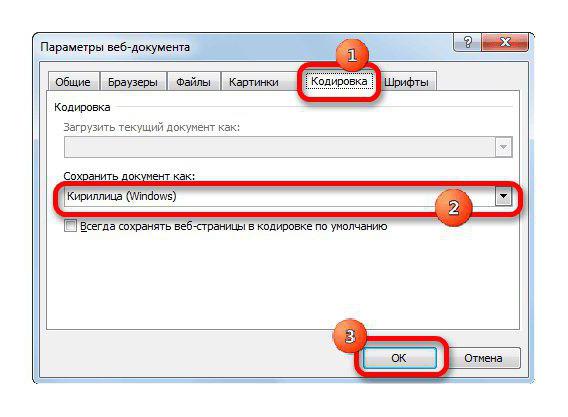
- В появившемся меню выберите расширение и нажмите «Сервис», из выпадающего меню — «Параметры веб-документа».
- В появившемся окне перейдите во вкладку «Кодировка» и выберете ее из списка «Сохранить документ как».
- Нажмите «ОК».
Теперь остается лишь указать папку, куда файл будет сохранен. При последующем его открытии текст должен отображаться корректно.
Почему появляются Каракули и иероглифы в Excel? У этой проблемы может быть несколько вариантов, соберу большинство решений в этой статье. Ну и заодно напишу, как добавлять и использовать символы-иероглифы в тексте.
Проблема с кодировкой часто возникает в разных программах. Кто уверен сталкивался с проблемой смены кодировки. Разберем и другие случаи
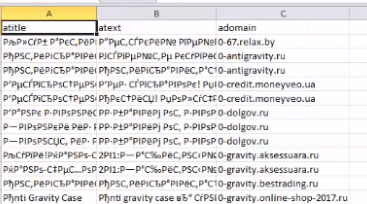
Если при открытии файла вы видите каракули/иероглифы в Excel, вам может помочь смена кодировки. Пересохраните файл следующим способом:
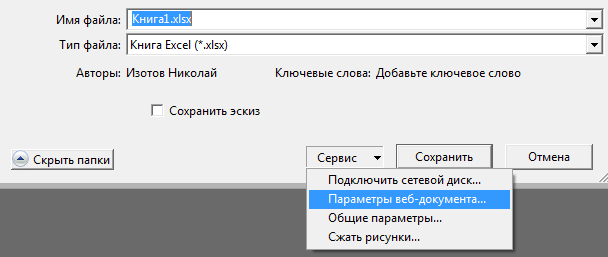
На вкладке Кодировка выберите Юникод (UTF-8) или Кириллица (Windows)
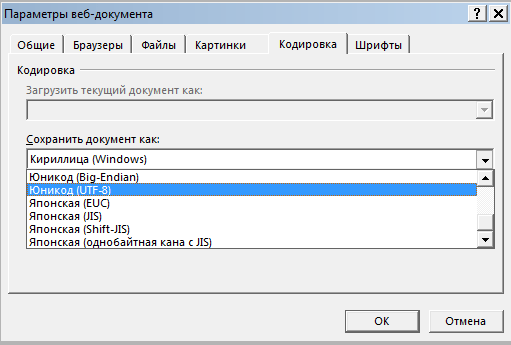
Пересохраняем файл.
Неверная кодировка при получении данных из внешних источников. Открытие CSV файлов
Если при вставке данных из других файлов или внешних источников получаются каракули/неизвестные символы, тоже рекомендуется уточнить кодировку. Сделать это можно следующим образом:
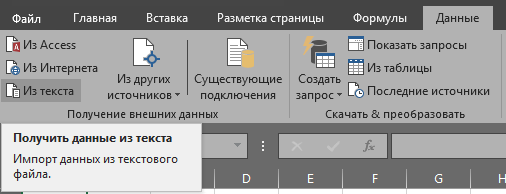
На ленте управления выберите вкладку Данные, а в разделе Получение внешних данных выберите нужный пункт.
Если вы вставляете обычные данные из файла, т.е. текст или таблицу, выберите Из текста
Укажите файл из которого забираем данные, после выберите формат данных, а главное в разделе Формат файла выберите Юникод (UTF-8).
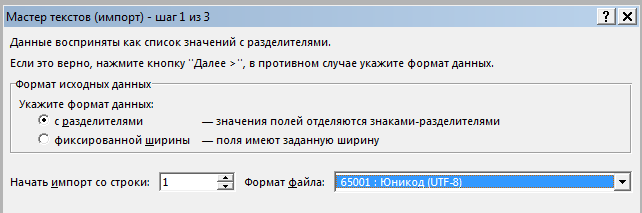
Что выбрать с разделителем или фиксированной ширины (шаг 1), а так же следующий шаг (шаг 2) подробно описан в этой .
В шаге 3 выбираем «Общий» формат данных.
Открываем не той программой
Так же я рекомендую проверить, какой именно программой вы открываете Excel-файл. Бывает, что книги 2010 формата Excel открываются в Excel 2003 (или более ранние версии) с измененным на иероглифы текстом. Подробнее про форматы Excel .
Точно такая же проблема периодически возникает если открывать сложные Excel-книги с большим набором данных через альтернативные табличные редакторы, такие как LibreOffice.Calc, Apache OpenOffice и другие.
Как добавить символы-иероглифы в тексте?
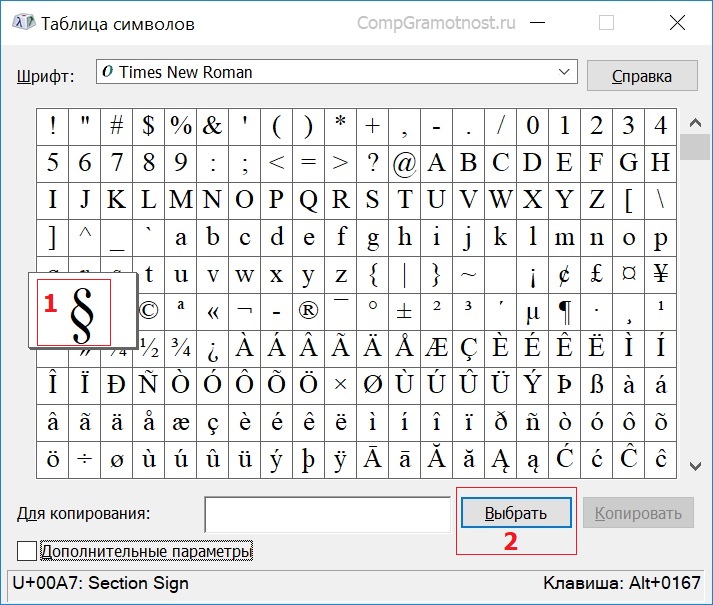
«С текстом у меня все в порядке, мне нужно вставить иероглиф/символ в Excel» — скажите вы. Чтобы вставить символ перейдите на вкладку Вставка и в разделе Символы выберите Символ.
В таблице символов можно найти почти любой символ
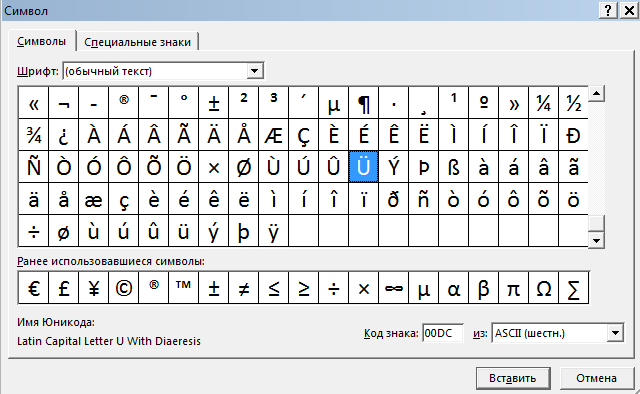
Чтобы добавить его в текст — кликните по нему.
Поделитесь нашей статьей в ваших соцсетях:
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
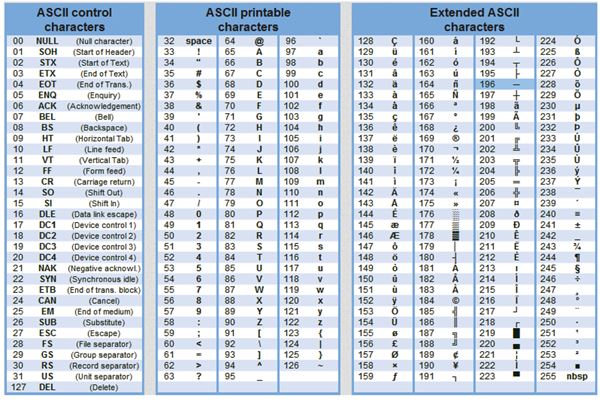
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 | 169 | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
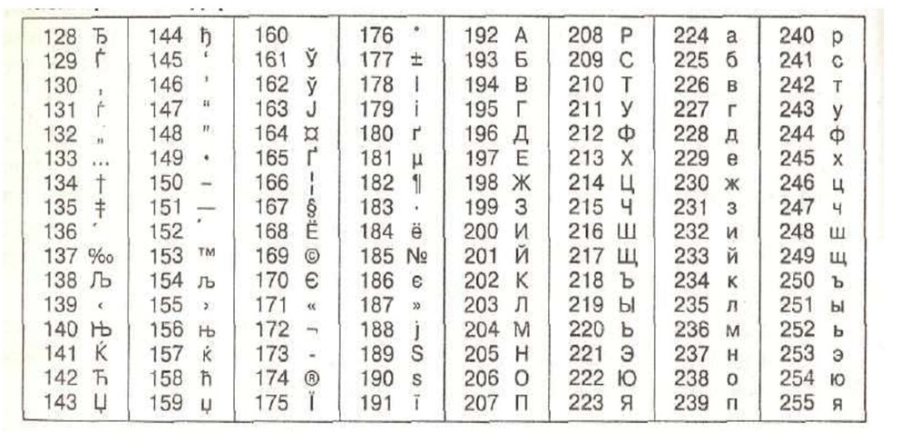
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| левая открывающая квадратная скобка | |
| правая закрывающая квадратная скобка | |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| двоеточие | |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| слэш, косая черта, знак дроби | |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE typedef wchar_t TCHAR;#else typedef char TCHAR;#endif
_T(«строка»)tchar.hПредставление данных и архитектура ЭВМ
Собственный велосипед
Автоопределение кодировки возможно только эвристическими методами, не точно. Если мы не знаем на каком языке и в какой кодировке записан текстовый файл, то определить кодировку с высокой точночностью наверняка можно, но будет сложновато… и нужно будет достаточно много текста.
Для меня такая цель не стояла. Мне достаточно определять кодировки в предположении что там есть русский язык. И второе, определять нужно по небольшому количеству символов – на 10 символах должно быть достаточно уверенное определение, а желательно вообще на 5–6 символах.
Алгоритм
Когда я обнаружил совпадение кодировок KOI8-r и CP1251 по местоположению алфавита, то на пару дней загрустил… стало понятно, что чуть-чуть придётся подумать. Получилось так.
Основные решения:
- Работу будем вести со слайсом байтов, для совместимости с charset.DetermineEncoding()
- Кодировку UTF-8 и случаи с BOM проверяем отдельно
- Входные данные передаём по очереди каждой кодировке. Каждая сама вычисляет два целочисленных критерия. У кого сумма двух критериев больше, тот и выиграл.
Первый критерий
Первым критерием является количество самых популярных букв русского алфавита.
Наиболее часто встречаются буквы: о, е, а, и, н, т, с, р, в, л, к, м, д, п, у. Данные буквы дают 82% покрытия. Для всех кодировок кроме KOI8-r и CP1251 я использовал только первые 9 букв: о, е, а, и, н, т, с, р, в. Этого вполне хватает для уверенного определения.
А вот для KOI8-r и CP1251 пришлось доработать напильником. Коды некоторых из этих букв совпадают, например буква о имеет в CP1251 код 0xEE при этом в KOI8-r этот код у буквы н. Для этих кодировок были взяты следующие популярные буквы.
Второй критерий
К сожалению для очень коротких случаев (общая длина русского текста 5-6 символов) встречаемость популярных букв на уровне 1-3 шт и происходит нахлёст кодировок KOI8-r и CP1251. Пришлось вводить второй критерий. Подсчёт количества пар согласная+гласная.
Такие комбинации ожидаемо наиболее часто встречаются в русском языке и соответственно в той кодировке в которой число таких пар больше, та кодировка имеет больший критерий.
Вычисляются оба критерия, складываются и полученная сумма является итоговым критерием.
Результат отражен в таблице выше.
Электронная таблица в 1С средствами табличного документа
Функционал электронной таблицы для программ на платформе 1С реализован на основе табличного документа. Функционал реализован в виде обработки (тонкий клиент). В формулах электронной таблицы можно использовать любые языковые конструкции, процедуры и функции 1С, ссылки на другие ячейки электронной таблицы. Допустимо обращаться к ячейкам электронной таблицы по имени именованной области. В случае использования в формулах электронной таблицы данных из самой таблицы пересчет зависимых ячеек с формулами производится автоматически. Электронную таблицу можно сохранить в файл формата xml.
1 стартмани
Основные способы кодирования текстовой информации
Существует несколько основных способов кодирования текстовой информации:
- графический, в котором текстовая информация кодируется путем использования специальных рисунков или знаков;
- символьный, в котором тексты кодируются с использованием символов того же алфавита, на котором написан исходник;
- числовой, в котором текстовая информация кодируется с помощью чисел.
Процесс чтения текста представляет собой процесс, обратный его написанию, в результате которого письменный текст преобразуется в устную речь. Чтение – это ничто иное, как декодирование письменного текста.
А сейчас обратите внимание на то, что существует много способов кодирования одного и того же текста на одном и том же языке. Пример 1
Пример 1
Поскольку мы русские, то и текст привыкли записывать с помощью алфавита своего родного языка. Однако тот же самый текст можно записать, используя латинские буквы. Иногда это приходится делать, когда мы отправляем SMS по мобильному телефону, клавиатура которого не содержит русских букв, или же электронное письмо на русском языке за границу, если у адресата нет русифицированного программного обеспечения. Например, фразу «Здравствуй, дорогой Саша!» можно записать как: «Zdravstvui, dorogoi Sasha!».
Наборы символов, карты символов и кодовые страницы
Исторически термины «кодировка символов», «карта символов», «набор символов» и « кодовая страница » были синонимами в информатике , поскольку один и тот же стандарт определял репертуар символов и то, как они должны были быть закодированы в поток кодовые единицы — обычно с одним символом на кодовую единицу. Но теперь эти термины имеют связанные, но разные значения из-за усилий органов стандартизации по использованию точной терминологии при описании и объединении множества различных систем кодирования. Несмотря на это, эти термины по-прежнему используются как синонимы, а набор символов практически повсеместен.
« Кодовая страница » обычно означает байтово-ориентированное кодирование, но в отношении некоторого набора кодировок (охватывающих разные сценарии), где многие символы используют одни и те же коды в большинстве или всех этих кодовых страницах. Хорошо известными наборами кодовых страниц являются «Windows» (на основе Windows-1252) и «IBM» / «DOS» (на основе кодовой страницы 437 ), подробности см. В кодовой странице Windows . Большинство, но не все, кодировки, называемые кодовыми страницами, являются однобайтовыми (но см. Октет по размеру байта).
Архитектура представления символьных данных IBM (CDRA) обозначает идентификаторы кодированных наборов символов ( CCSID ), каждый из которых по-разному называется «набором символов», «набором символов», «кодовой страницей» или «CHARMAP».
Термин «кодовая страница» не встречается в Unix или Linux, где предпочтительнее «charmap», обычно в более широком контексте локалей.
В отличие от « », «кодировка символов» — это отображение абстрактных символов на кодовые слова . «Набор символов» на языке HTTP (и MIME ) совпадает с кодировкой символов (но не совпадает с CCS).
« Устаревшая кодировка» — это термин, который иногда используется для характеристики старых кодировок символов, но с неоднозначным смыслом. Большая часть его использования находится в контексте Unicodification , где он относится к кодировкам, которые не охватывают все кодовые точки Unicode, или, в более общем плане, с использованием несколько иного репертуара символов: несколько кодовых точек, представляющих один символ Unicode, или наоборот (см., Например, кодовая страница 437 ). Некоторые источники называют кодировку устаревшей только потому, что она предшествовала Unicode. Все кодовые страницы Windows обычно называют устаревшими как потому, что они предшествуют Unicode, так и потому, что они не могут представить все 2 21 возможных кодовых точек Unicode.
Сравнение найденных решений на автоопределение кодировки
Мне кажется, получилось забавно.
| # | Кодировка | html/charset | saintfish/chardet | softlandia/cpd | enca |
|---|---|---|---|---|---|
| 1 | CP1251 | windows-1252 | CP1251 | CP1251 | CP1251 |
| 2 | CP866 | windows-1252 | windows-1252 | CP866 | CP866 |
| 3 | KOI8-R | windows-1252 | KOI8-R | KOI8-R | KOI8-R |
| 4 | ISO-8859-5 | windows-1252 | ISO-8859-5 | ISO-8859-5 | ISO-8859-5 |
| 5 | UTF-8 with BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 6 | UTF-8 without BOM | utf-8 | utf-8 | utf-8 | utf-8 |
| 7 | UTF-16LE with BOM | utf-16le | utf-16le | utf-16le | ISO-10646-UCS-2 |
| 8 | UTF-16LE without BOM | windows-1252 | ISO-8859-1 | utf-16le | unknown |
| 9 | UTF-16BE with BOM | utf-16le | utf-16be | utf-16be | ISO-10646-UCS-2 |
| 10 | UTF-16BE without BOM | windows-1252 | ISO-8859-1 | utf-16be | ISO-10646-UCS-2 |
| 11 | UTF-32LE with BOM | utf-16le | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 12 | UTF-32LE without BOM | windows-1252 | utf-32le | utf-32le | ISO-10646-UCS-4 |
| 13 | UTF-32BE with BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 14 | UTF-32BE without BOM | windows-1252 | utf-32be | utf-32be | ISO-10646-UCS-4 |
| 15 | KOI8-R (UPPER) | windows-1252 | KOI8-R | KOI8-R | CP1251 |
| 16 | CP1251 (UPPER) | windows-1252 | CP1251 | CP1251 | KOI8-R |
| 17 | CP866 & CP1251 | windows-1252 | CP1251 | CP1251 | unknown |
Наблюдение 1
enca не определила кодировку у файла UTF-16LE без BOM — это странно, ну ладно. Я попробовал добавить больше текста, но результата не получил.
Наблюдение 2. Проблемы с кодировками CP1251 и KOI8-R
Строка 15 и 16. У команды enca есть проблемы.
Здесь сделаю объяснение, дело в том, что кодировки CP1251 (она же Windows 1251) и KOI8-R очень близки если рассматривать только алфавитные символы.
Таблица KOI8-r
В обеих кодировках алфавит расположен от 0xC0 до 0xFF, но там, где у одной кодировки заглавные буквы, у другой строчные. Судя по всему enca, работает по строчным буквам. Вот и получается, если подать на вход программе enca строку “СТП” в кодировке CP1251, то она решит, что это строка “яро” в кодировке KOI8-r, о чём и сообщит. В обратную сторону также работает.
Стандартной библиотеке html/charset можно доверить только определение UTF-8, но осторожно! Пользоваться следует именно charset.DetermineEncoding(), поскольку метод utf8.Valid(b []byte) на файлах в кодировке utf-16be возвращает true
Какая бывает информация?

Итак, для восприятия информации компьютеру необходимо запустить процессы обработки. А какая вообще бывает информация? Темой этой статьи является кодирование текстовой информации
Мы уделим особенное внимание этой задаче, но разберемся и с другими микротемами
Информация может быть текстовой, числовой, звуковой, графической. Компьютер должен запустить процессы, обеспечивающие кодирование текстовой информации, чтобы вывести на экран то, что мы, например, печатаем на клавиатуре. Мы будем видеть символы и буквы, это понятно. А что же видит машина? Она воспринимает абсолютно всю информацию – и речь сейчас идет не только о тексте – в качестве определенной последовательности нулей и единиц. Они составляют основу так называемого двоичного кода. Соответственно, процесс, который преобразует поступающую на устройство информацию в понятную ему, имеет название “двоичное кодирование текстовой информации”.
Перевод кодировки символов
В результате использования множества методов кодирования символов (и необходимости обратной совместимости с архивными данными) было разработано множество компьютерных программ для преобразования данных между схемами кодирования как формы перекодирования данных . Некоторые из них цитируются ниже.
Кроссплатформенность :
- Веб-браузеры — большинство современных веб-браузеров поддерживают автоматическое определение кодировки символов. Например, в Firefox 3 см. Подменю «Вид / Кодировка символов».
- iconv — программа и стандартизированный API для преобразования кодировок
- luit — программа, преобразующая кодировку ввода и вывода в программы, работающие в интерактивном режиме
- convert_encoding.py — Утилита на основе Python для преобразования текстовых файлов между произвольными кодировками и окончаниями строк.
- decodeh.py — алгоритм и модуль для эвристического угадывания кодировки строки.
- Международные компоненты для Unicode — набор библиотек C и Java для преобразования кодировки. uconv можно использовать из ICU4C.
- Более новые версии команды Unix file пытаются выполнить базовое определение кодировки символов (также доступно в Cygwin ).
Unix-подобный :
- cmv — простой инструмент для перекодировки имен файлов.
- convmv — преобразовать имя файла из одной кодировки в другую.
- cstocs — конвертировать содержимое файла из одной кодировки в другую для чешского и словацкого языков.
- enca — анализирует кодировки для заданных текстовых файлов.
- recode — конвертировать содержимое файла из одной кодировки в другую
- utrac — конвертировать содержимое файла из одной кодировки в другую.
Windows :
- Encoding.Convert — .NET API
- MultiByteToWideChar / WideCharToMultiByte — преобразование из ANSI в Unicode и Unicode в ANSI
- cscvt — инструмент преобразования набора символов
- enca — анализирует кодировки для заданных текстовых файлов.