Как пользоваться curl
Содержание:
Часто используемые функции CURL и константы
- curl_init — Инициализирует сеанс;
- curl_close — Завершает сеанс;
- curl_exec — Выполняет запрос;
- curl_errno — Возвращает код ошибки;
- curl_setopt — Устанавливает параметр для сеанса, например:
- CURLOPT_HEADER – значение 1 означает, что необходимо вернуть заголовки;
- CURLOPT_INFILESIZE — параметр для указания ожидаемого размера файла;
- CURLOPT_VERBOSE — значение 1 означает что CURL будет выводить подробные сообщения о всех производимых операциях;
- CURLOPT_NOPROGRESS – отключение индикатора прогресса операции, значение 1;
- CURLOPT_NOBODY – если Вам не нужен документ, а нужны только заголовки, то поставьте значение 1;
- CURLOPT_UPLOAD — для закачки файла на сервер;
- CURLOPT_POST – выполнить запрос методом POST;
- CURLOPT_FTPLISTONLY — получение списка файлов в директории FTP сервера, значение 1;
- CURLOPT_PUT — выполнить запрос методом PUT, значение 1;
- CURLOPT_RETURNTRANSFER — возвратить результат, не выводя в браузер, значение 1;
- CURLOPT_TIMEOUT – максимальное время выполнения в секундах;
- CURLOPT_URL – указание адреса для обращения;
- CURLOPT_USERPWD — строка с именем пользователя и паролем в виде :;
- CURLOPT_POSTFIELDS – данные для POST запроса;
- CURLOPT_REFERER — задает значение HTTP заголовка «Referer: »;
- CURLOPT_USERAGENT — задает значение HTTP заголовка «User-Agent: »;
- CURLOPT_COOKIE — содержимое заголовка «Cookie: », который будет отправлен с HTTP запросом;
- CURLOPT_SSLCERT- имя файла с сертификатом в формате PEM;
- CURLOPT_SSL_VERIFYPEER – значение 0, для того чтобы запретить проверку сертификата удаленного сервера (по умолчанию 1);
- CURLOPT_SSLCERTPASSWD — пароль к файлу сертификата.
- curl_getinfo — Возвращает информацию об операции, вторым параметром может выступать константа для указания, что именно нужно показать, например:
- CURLINFO_EFFECTIVE_URL — последний использованный URL;
- CURLINFO_HTTP_CODE — последний полученный код HTTP;
- CURLINFO_FILETIME — дата модификации загруженного документа;
- CURLINFO_TOTAL_TIME — время выполнения операции в секундах;
- CURLINFO_NAMELOOKUP_TIME — время разрешения имени сервера в секундах;
- CURLINFO_CONNECT_TIME — время, затраченное на установку соединения, в секундах;
- CURLINFO_PRETRANSFER_TIME — время, прошедшее от начала операции до готовности к фактической передаче данных, в секундах;
- CURLINFO_STARTTRANSFER_TIME — время, прошедшее от начала операции до момента передачи первого байта данных, в секундах;
- CURLINFO_REDIRECT_TIME — время, затраченное на перенаправление, в секундах;
- CURLINFO_SIZE_UPLOAD — количество байт при закачке;
- CURLINFO_SIZE_DOWNLOAD — количество байт при загрузке;
- CURLINFO_SPEED_DOWNLOAD — средняя скорость закачки;
- CURLINFO_SPEED_UPLOAD — средняя скорость загрузки;
- CURLINFO_HEADER_SIZE — суммарный размер всех полученных заголовков;
- CURLINFO_REQUEST_SIZE — суммарный размер всех отправленных запросов;
- CURLINFO_SSL_VERIFYRESULT — результат проверки SSL сертификата, запрошенной с помощью установки параметра CURLOPT_SSL_VERIFYPEER;
- CURLINFO_CONTENT_LENGTH_DOWNLOAD — размер загруженного документа, прочитанный из заголовка Content-Length;
- CURLINFO_CONTENT_LENGTH_UPLOAD — размер закачиваемых данных;
- CURLINFO_CONTENT_TYPE — содержимое полученного заголовка Content-type, или NULL в случае, когда этот заголовок не был получен.
Подробнее о функциях CURL и константах к ним можете посмотреть на официальном сайте PHP — php.net
На этом все, для начинающих я думаю достаточно Удачи!
Следовать за редиректами
Сервер Google сообщил нам, что страница перемещена (301 Moved Permanently), и теперь надо запрашивать страницу . С помощью опции укажем CURL следовать редиректам:
> curl -L google.com <!doctype html> <html itemscope="" itemtype="http://schema.org/WebPage" lang="ru"> <head> <meta content="Поиск информации в интернете: веб страницы, картинки, видео и многое другое." name="description"> <meta content="noodp" name="robots"> <meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"> <meta content="origin" name="referrer"> <title>Google</title> ..........
Формы
Формы — основной способ представления web-сайта как HTML-страницы
с полями, в которые пользователь вводит данные, и затем нажимает на
кнопку ‘OK’ или ‘Отправить’, после чего данные отсылаются на сервер.
Затем сервер использует принятые данные и решает, как действовать
дальше: искать информацию в базе данных, показать введенный адрес на
карте, добавить сообщение об ошибке или использовать информацию для
аутентификации пользователя. Разумеется, на стороне сервера имеется
какая-то программа, которая принимает ваши данные.
4.1 GET
GET-форма использует метод GET, например следующим образом:
<form method="GET" action="junk.cgi">
<input type=text name="birthyear">
<input type=submit name=press value="OK">
</form>
Если вы откроете этот код в вашем браузере, вы увидите форму с
текстовым полем и кнопку с надписью «OK». Если вы введете
‘1905’ и нажмете OK, браузер создаст новый URL, по которому и
проследует. URL будет представляться строкой, состоящей из пути
предыдущего URL и строки, подобной
«junk.cgi?birthyear=1905&press=OK».
Например, если форма располагалась по адресу
«www.hotmail.com/when/birth.html», то при нажатии на кнопку
OK вы попадете на URL
«www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK».
Большинство поисковых систем работают таким образом.
Чтобы curl сформировал GET-запрос, просто введите то, что
ожидалось от формы:
# curl "www.hotmail.com/when/junk.cgi?birthyear=1905&press=OK"
4.2 POST
Метод GET приводит к тому, что вся введенная информация
отображается в адресной строке вашего браузера. Может быть это
хорошо, когда вам нужно добавить страницу в закладки, но это
очевидный недостаток, когда вы вводите в поля формы секретную
информацию, либо когда объем информации, вводимый в поля, слишком
велик (что приводит к нечитаемому URL).
Протокол HTTP предоставляет метод POST. С помощью него клиент
отправляет данные отдельно от URL и поэтому вы не увидете их в
адресной строке.
Форма, генерирующая POST-запрос, похожа на предыдущую:
<form method="POST" action="junk.cgi">
<input type=text name="birthyear">
<input type=submit name=press value=" OK ">
</form>
Curl может сформировать POST-запрос с теми же данными следующим
образом:
# curl -d "birthyear=1905&press=%20OK%20" www.hotmail.com/when/junk.cgi
Этот POST-запрос использует ‘Content-Type
application/x-www-form-urlencoded’, это самый широко используемый
способ.
Данные, которые вы отправляете к серверу, должны быть правильно
закодированы, curl не будет делать это за вас. К примеру, если вы
хотите, чтобы данные содержали пробел, вам нужно заменить этот пробел
на %20 и т.п. Недостаток внимания к этому вопросу — частая ошибка,
из-за чего данные передаются не так, как надо.
4.3 Загрузка файлов с помощью POST (File Upload POST)
В далеком 1995 был определен дополнительный способ передавать
данные по HTTP. Он задокументирован в RFC 1867, поэтому этот способ
иногда называют RFC1867-posting.
Этот метод в основном разработан для лучшей поддержки загрузки
файлов. Форма, которая позволяет пользователю загрузить файл,
выглядит на HTML примерно следующим образом:
<form method="POST" enctype='multipart/form-data' action="upload.cgi">
<input type=file name=upload>
<input type=submit name=press value="OK">
</form>
Заметьте, что тип содержимого Content-Type установлен в
multipart/form-data.
Чтобы отослать данные в такую форму с помощью curl, введите
команду:
# curl -F upload=@localfilename -F press=OK
4.4 Скрытые поля
Обычный способ для передачи информации о состоянии в
HTML-приложениях — использование скрытых полей в формах. Скрытые поля
не заполняются, они невидимы для пользователя и передаются так же,
как и обычные поля.
Простой пример формы с одним видимым полем, одним скрытым и
кнопкой ОК:
<form method="POST" action="foobar.cgi">
<input type=text name="birthyear">
<input type=hidden name="person" value="daniel">
<input type=submit name="press" value="OK">
</form>
Чтобы отправить POST-запрос с помощью curl, вам не нужно думать о
том, скрытое поле или нет. Для curl они все одинаковы:
# curl -d "birthyear=1905&press=OK&person=daniel"
4.5 Узнать, как выглядит POST-запрос
Когда вы хотите заполнить форму и отослать данные на сервер с
помощью curl, вы наверняка хотите, чтобы POST-запрос выглядел точно
также, как и выполненный с помощью браузера.
Простой способ увидеть свой POST-запрос, это сохранить
HTML-страницу с формой на диск, изменить метод на GET, и нажать
кнопку ‘Отправить’ (вы можете также изменить URL, которому будет
передаваться данные).
Вы увидите, что данные присоединились к URL, отделенные символами
‘?’, как и предполагается при использовании GET-форм.
Множественный cURL
Одной из самых сильных сторон cURL является возможность создания «множественных» cURL обработчиков. Это позволяет вам открывать соединение к множеству URL одновременно и асинхронно.
В классическом варианте cURL запроса выполнение скрипта приостанавливается, и происходит ожидание завершения операции URL запроса, после чего работа скрипта может продолжиться. Если вы намереваетесь взаимодействовать с целым множеством URL, это приведёт к довольно-таки значительным затратам времени, поскольку в классическом варианте вы можете работать только с одним URL за один раз. Однако, мы можем исправить данную ситуацию, воспользовавшись специальными обработчиками.
Давайте рассмотрим пример кода, который я взял с php.net:
// создаём несколько cURL ресурсов
$ch1 = curl_init();
$ch2 = curl_init();
// указываем URL и другие параметры
curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/");
curl_setopt($ch1, CURLOPT_HEADER, 0);
curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/");
curl_setopt($ch2, CURLOPT_HEADER, 0);
//создаём множественный cURL обработчик
$mh = curl_multi_init();
//добавляем несколько обработчиков
curl_multi_add_handle($mh,$ch1);
curl_multi_add_handle($mh,$ch2);
$active = null;
//выполнение
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
}
//закрытие
curl_multi_remove_handle($mh, $ch1);
curl_multi_remove_handle($mh, $ch2);
curl_multi_close($mh);
Идея состоит в том, что вы можете использовать множественные cURL обработчики. Используя простой цикл, вы можете отследить, какие запросы ещё не выполнились.
В этом примере есть два основных цикла. Первый цикл do-while вызывает функцию curl_multi_exec(). Эта функция не блокируемая. Она выполняется с той скоростью, с которой может, и возвращает состояние запроса. Пока возвращенное значение является константой ‘CURLM_CALL_MULTI_PERFORM’, это означает, что работа ещё не завершена (например, в данный момент происходит отправка http заголовков в URL); Именно поэтому мы продолжаем проверять это возвращаемое значение, пока не получим другой результат.
В следующем цикле мы проверяем условие, пока переменная $active = ‘true’. Она является вторым параметром для функции curl_multi_exec(). Значение данной переменной будет равно ‘true’, до тех пор, пока какое-то из существующих изменений является активным. Далее мы вызываем функцию curl_multi_select(). Её выполнение ‘блокируется’, пока существует хоть одно активное соединение, до тех пор, пока не будет получен ответ. Когда это произойдёт, мы возвращаемся в основной цикл, чтобы продолжить выполнение запросов.
А теперь давайте применим полученные знания на примере, который будет реально полезным для большого количества людей.
Получение и отправка заголовков
По умолчанию, заголовки ответа сервера не показываются. Но это можно исправить:
> curl -i google.com HTTP/1.1 301 Moved Permanently Location: http://www.google.com/ Content-Type: text/html; charset=utf-8 Date: Sun, 16 Sep 2018 08:28:18 GMT Expires: Tue, 16 Oct 2018 08:28:18 GMT Cache-Control: public, max-age=2592000 Server: gws Content-Length: 219 X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
Если содержимое страницы не нужно, а интересны только заголовки (будет отправлен запрос):
> curl -I http://www.example.com/ HTTP/1.1 200 OK Date: Sun, 16 Sep 2018 08:20:52 GMT Server: Apache/2.4.34 (Win64) mod_fcgid/2.3.9 X-Powered-By: PHP/7.1.10 Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate Pragma: no-cache Set-Cookie: PHPSESSID=svn7eb593i8d2gv471rs94og58; path=/ Set-Cookie: visitor=fa867bd917ad0d715830a6a88c816033; expires=Mon, 16-Sep-2019 08:20:53 GMT; Max-Age=31536000; path=/ Set-Cookie: lastvisit=1537086053; path=/ Content-Length: 132217 Content-Type: text/html; charset=utf-8
Посмотреть, какие заголовки отправляет CURL при запросе, можно с помощью опции , которая выводит более подробную информацию:
> curl -v google.com
- Строка, начинающаяся с означает заголовок, отправленный серверу
- Строка, начинающаяся с означает заголовок, полученный от сервера
- Строка, начинающаяся с означает дополнительные данные от CURL
* Rebuilt URL to: http://google.com/ * Trying 173.194.32.206... * TCP_NODELAY set * Connected to google.com (173.194.32.206) port 80 (#0)
> GET / HTTP/1.1 > Host: google.com > User-Agent: curl/7.61.1 > Accept: */* > < HTTP/1.1 301 Moved Permanently < Location: http://www.google.com/ < Content-Type: text/html; charset=utf-8 < Date: Mon, 17 Sep 2018 15:11:49 GMT < Expires: Wed, 17 Oct 2018 15:11:49 GMT < Cache-Control: public, max-age=2592000 < Server: gws < Content-Length: 219 < X-XSS-Protection: 1; mode=block < X-Frame-Options: SAMEORIGIN < <HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8"> <TITLE>301 Moved</TITLE></HEAD><BODY> <H1>301 Moved</H1> The document has moved <A HREF="http://www.google.com/">here</A>. </BODY></HTML>
* Connection #0 to host google.com left intact
Если этой информации недостаточно, можно использовать опции или .
А вот так можно отправить свой заголовок:
> curl -H "User-Agent: Mozilla/5.0" http://www.example.com/
PHP cURL POST
Разница между и запросами — это синтаксиc для отправки. Для можно указать больше параметров, например, поля, которые будут отправляться. Допустим, вы хотите отправить форму на сайте куда делаете запрос, тогда в данном случае вам точно понадобиться .
// Для начала скажем, что мы хотим использовать cURL
$curl = curl_init();
// Определение прааметров. Ссылку (куда будет делаться запрос), какие заголовки будут у этого запроса, задаем, что запрос должен быть в формате POST и передаем параметры этого запроса в виде массива 'ключ' => 'значение'.
curl_setopt_array($curl, [
CURLOPT_RETURNTRANSFER => 1,
CURLOPT_URL => 'http://testcURL.com',
CURLOPT_USERAGENT => 'Codular Sample cURL Request',
CURLOPT_POST => 1,
CURLOPT_POSTFIELDS =>
]);
// Отправляем запроса и сохраняем его в $res
$res = curl_exec($curl);
// Закрываем запрос и удаляем инициализацию $curl
curl_close($curl);
Процедура отправки этого запроса почти идентична тому, что было в за исключением двух дополнительных строчек. С помощью мы говорим cURL о том, что хотим отправить запрос и затем прописываем параметры для отправки с в виде массива (сначала имя параметра и затем его значение).
CURLOPT_POSTFIELDS =>
Обратите внимание на то, что если на форме будет стоять капча (проверка на ботов), тогда зарегистрироваться автоматически не получится
Получение информации
Ещё одним дополнительным шагом является получение данных о cURL запросе, после того, как он был выполнен.
// ... curl_exec($ch); $info = curl_getinfo($ch); echo 'Took ' . $info . ' seconds for url ' . $info; // …
Возвращаемый массив содержит следующую информацию:
- “url”
- “content_type”
- “http_code”
- “header_size”
- “request_size”
- “filetime”
- “ssl_verify_result”
- “redirect_count”
- “total_time”
- “namelookup_time”
- “connect_time”
- “pretransfer_time”
- “size_upload”
- “size_download”
- “speed_download”
- “speed_upload”
- “download_content_length”
- “upload_content_length”
- “starttransfer_time”
- “redirect_time”
Базовая структура
Прежде чем мы двинемся дальше к более сложным примерам, давайте рассмотрим базовую структуру cURL запроса в PHP. Существует четыре основных шага, которые нужно учитывать в каждом скрипте:
- Инициализация
- Назначение параметров
- Выполнение и выборка результата
- Освобождение памяти
// 1. инициализация $ch = curl_init(); // 2. указываем параметры, включая url curl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. получаем HTML в качестве результата $output = curl_exec($ch); // 4. закрываем соединение curl_close($ch);
Шаг #2 (то есть, вызов curl_setopt()) будем обсуждать в этой статье намного больше, чем все другие этапы, т.к. на этой стадии происходит всё самое интересное и полезное, что вам необходимо знать. В cURL существует огромное количество различных опций, которые должны быть указаны, для того чтобы иметь возможность сконфигурировать URL-запрос самым тщательным образом. Мы не будем рассматривать весь список целиком, а остановимся только на том, что я посчитаю нужным и полезным для этого урока. Всё остальное вы сможете изучить сами, если эта тема вас заинтересует.
9 ответов
73
Загрузите cURL для Windows из здесь (и обязательно выберите его из Win32 — общий вниз на странице).
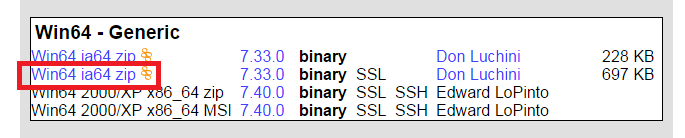
Затем поместите его в каталог внутри вашей переменной среды PATH (например: )) или запустите его с полным путем, предшествующим исполняемому имени.
Если вы поместите его в каталог, находящийся внутри вашего PATH, обязательно закройте и снова запустите командную строку, чтобы сделать эту команду доступной.
80
Если вы устанавливаете Git for Windows , вы автоматически получаете Curl. Существуют следующие преимущества:
- Git автоматически выполняет настройку во время установки.
- Вы получаете GNU bash , действительно мощную оболочку, на мой взгляд, намного лучше, чем родная консоль Windows.
- Вы получаете множество других полезных инструментов Linux, таких как tail, cat, grep, gzip, pdftotext, less, sort, tar, vim и даже Perl.
2
После установки OpenSSL Light перезагрузите Windows, откройте командную строку, затем выполните тестовую команду, например:
Если вы вернете HTML-теги, это сработало.
2
Как настроить cURL:
- Загрузите и распакуйте 64-разрядную cURL с помощью SSL.
- Скопируйте файл в папку Windows . По умолчанию это .
- Загрузите и установите 64-разрядный 64-разрядный ресурс Runtime Visual Studio 2010 C ++ здесь .
- Загрузите последний пакет открытых ключей Certficate Authority из mozilla.org здесь .
- Переименуйте этот файл из в .
- Переместите этот файл в папку Windows .
Как протестировать его:
- Запустите , чтобы открыть командную строку.
- Для обеих команд вы должны увидеть пару страниц исходного кода HTML. Если вы видите это, cURL запущен и работает!
2
Tar и Curl доступны в Windows, начиная с Insider Build 17063, в составе инструментальной цепочки Windows: curl и bsdtar.
Tar : инструмент командной строки, который позволяет пользователю извлекать файлы и создавать архивы. Вне PowerShell или установки стороннего программного обеспечения не удалось извлечь файл из cmd.exe. Реализация использует libarchive.
1
Вы можете установить этот «cURL для Windows»:
cURL для Windows — это установщик MSI для cURL, популярного инструмента переноса веб-страниц в командной строке.
http://www.confusedbycode.com/curl/
1
Для людей, которым буквально не нужен исполняемый файл , а просто нужно, например, см. или сохранить результаты запроса GET, можно напрямую использовать . В обычной командной строке введите:
, который, хотя и немногословный, похож на ввод
в более среде Unix-ish.
Дополнительная информация о доступна здесь: Методы WebClient (System.Net) .
Не нужно перезапускать окна, но необходимо перезапустить CMD.
- Установите cURL из curl.haxx.se .
- Установите переменную окружения Path в соответствии с расположением curl.exe на вашем компьютере, что-то вроде C: \ Users \ You \ cURL
-
Загрузить файл сертификата с сайта mozilla.org, связанный в одном из
ответы выше, и переместите его в папку system32.
Я использовал ответ fuxia для запуска некоторых сценариев bash, которые я написал в Linux на платформе Windows. Это работает очень хорошо.
Слово осторожности, но с помощью. У меня была проблема, когда я не мог использовать взаимодействие консоли при аутентификации, как описано здесь:
https://stackoverflow.com/questions/50724407/curl-command-in-git-bash. Если ваша команда требует аутентификации, и вы не хотите, чтобы пароль был видимым в командной строке или сохранен в вашем скрипте, вам придется использовать другое решение, например, используя файл паролей:
https://stackoverflow.com/questions/2594880/using-curl-with- а-имя пользователя-и-пароль
Если ваша команда требует аутентификации, и вы не хотите, чтобы пароль был видимым в командной строке или сохранен в вашем скрипте, вам придется использовать другое решение, например, используя файл паролей:
https://stackoverflow.com/questions/2594880/using-curl-with- а-имя пользователя-и-пароль
Описание cURL и первые шаги
Для началом работы с инструментом, его нужно инициализировать. Делается это следующим образом:
$ch = curl_init();
Мы использовали функцию инициализации сессии cURL. При этом, можно задать URL сразу, вот так:
$ch = curl_init('https://myblaze.ru');
А можно сделать это потом, в опциях. Порядок установки опций не имеет значения. Делается это другой функцией:
curl_setopt (resource ch, string option, mixed value)
Приведу пример установки опций как раз на примере URL:
$url = "https://myblaze.ru"; curl_setopt($ch, CURLOPT_URL,$url);
Еще парочка примеров задания опций: давайте получим заголовок ответа сервера, при этом не будем получать саму страницу:
curl_setopt($ch, CURLOPT_HEADER, 1); // читать заголовок curl_setopt($ch, CURLOPT_NOBODY, 1); // читать ТОЛЬКО заголовок без тела
Итак, мы инициализировали сессию, задали нужные нам параметры, теперь выполняем получившийся запрос, закрываем сессию и выводим результат:
$result = curl_exec($ch); curl_close($ch); echo $result;
В итоге получаем наш первый полностью рабочий пример использования библиотеки libcurl:
$ch = curl_init(); $url = "https://myblaze.ru"; curl_setopt($ch, CURLOPT_URL,$url); curl_setopt($ch, CURLOPT_HEADER, 1); // читать заголовок curl_setopt($ch, CURLOPT_NOBODY, 1); // читать ТОЛЬКО заголовок без тела $result = curl_exec($ch); curl_close($ch); echo $result;
Как оно работает, надеюсь, понятно, ведь мы рассмотрели каждый шаг по отдельности 🙂 В результате мы получаем заголовок HTTP ответа от сервера, который чуть ниже обязательно разберем, чтобы лучше понимать все этапы взаимодействия браузера и сервера:
HTTP/1.1 200 OK Server: nginx/1.2.6 Date: Sat, 09 Mar 2013 16:38:39 GMT Content-Type: text/html; charset=utf-8 Connection: keep-alive Keep-Alive: timeout=10 X-Pingback: https://myblaze.ru/xmlrpc.php 1
Великолепно! Мы получили заголовок ответа от сервера и опробовали библиотеку в действии. Чем это нам полезно? Тем, что теперь вы примерно представляете себе последовательность действий при работе с cURL:
- Инициализировать сессию (curl_init)
- Задать нужные нам опции (curl_setopt)
- Выполнить полученный запрос (curl_exec)
- Завершить сессию (curl_close)
Двигаемся дальше, но перед тем как делать с libcurl что-то более серьезное, как я и обещал, разберем подробно из чего состоит заголовок HTTP запроса к серверу и ответ на него.
Twitter: проверяем отношения между двумя пользователями
Если вам нужно узнать, читает ли ваши твиты определенный пользователь, то можно задействовать API Twitter. Данный скрипт выводит , если два пользователя, указанные на строчках 17 и 18, находятся в дружеских отношениях на Twitter. В противном случае возвращается .
function make_request($url) {
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
$result = curl_exec($ch);
curl_close($ch);
return $result;
}
/* Получаем соответствие */
function get_match($regex,$content) {
preg_match($regex,$content,$matches);
return $matches;
}
/* Персоны для проверки */
$person1 = 'phpsnippets';
$person2 = 'catswhocode';
/* Отправляем запрос на twitter */
$url = 'https://api.twitter.com/1/friendships/exist';
$format = 'xml';
/* Проверка */
$persons12 = make_request($url.'.'.$format.'?user_a='.$person1.'&user_b='.$person2);
$result = get_match('/<friends>(.*)<\/friends>/isU',$persons12);
echo $result; // Возвращаем "true" или "false"