Faq: кластеризация и группировка запросов
Содержание:
- Не забываем пользоваться руками
- Этап 2. Сбор и чистка семантического ядра в Key Collector
- Сравнение сервисов
- Группировка с агрегатными функциями
- Зачем группировать ключевые слова
- Как пользоваться группировкой?
- Кластеризация семантического ядра
- Зачем нужны сервисы кластеризации?
- Этап 3. Формирование структуры интернет-магазина
- Что такое группы объявлений в Яндекс.Директ и для чего они нужны
- Как это работает?
- Особенности сбора семантики по видам проектов
- Пошаговая кластеризация на реальном примере
- Методы кластеризации
- Что такое семантическое ядро
- Заключение
Не забываем пользоваться руками
Для этапов группировки и определения посадочных страниц я постарался обрисовать алгоритм, который максимально ускорит и автоматизирует этот процесс. Однако финальный этап всё равно должен оставаться за вами, так как машина в обозримом будущем будет оставаться глупее человека и косячить.
В случае с группировкой поисковых подразумевается уже упомянутая ранее вероятность включения в одну группу таких запросов, одновременное продвижение которых в рамках одной посадочной страницы будет неэффективно.
В случае же с определением посадочных страниц — поисковая система могла признать самой релевантной страницей сайта не ту, которую нужно в дальнейшем продвигать, а ту, которая может быть даже не посвящена теме запроса и просто имеет случайное вхождение словосочетания, определившее релевантность всей страницы. Автоматизируйте, но потом хотя бы поверхностно пробегайтесь по всему от А до Я, проверяя верность тех или иных полученных данных.
Вот, вроде, и всё
Спасибо за внимание и жду ваших вопросов
Материал обновлен: 30 мая 2016.
Этап 2. Сбор и чистка семантического ядра в Key Collector
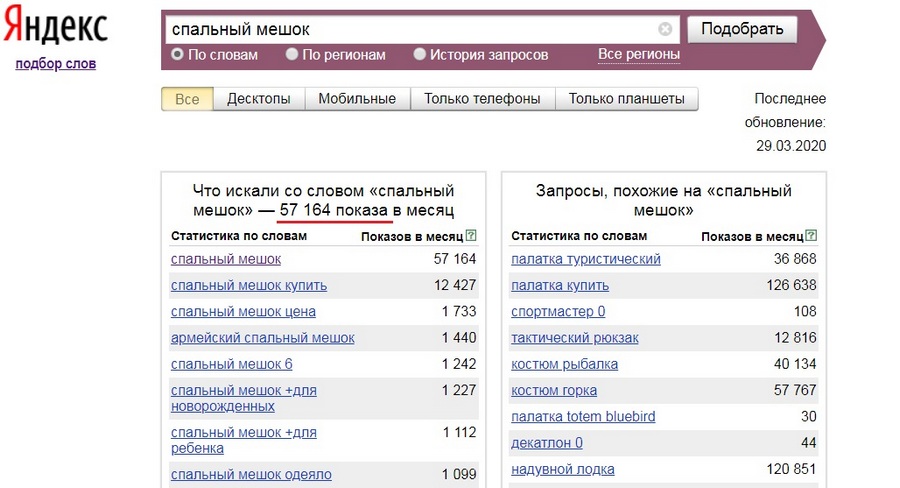
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:
После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:
В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:
После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:
Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:
Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:
Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.
Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:
После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Сравнение сервисов
В поиске самых популярных сервисов очень помог доклад Александра Ожгибесова на BDD-2017, к тем, что у него было добавлено еще несколько сервисов, получился такой список:
- Топвизор
- Pixelplus
- Serpstat
- Rush Analytics
- Just Magic
- Key Collector
- MindSerp
- Semparser
- KeyAssort
- coolakov.ru
Первое на что проверялись полученные в результате кластеризации эталонного ядра по этим сервисам группы – это не делает ли сервис слишком широкие группы. А именно не попали ли запросы из разных групп эталонного ядра в один кластер по версии сервиса.
Но только такого сравнения не достаточно. Сервисы делятся на два подхода к некластеризованному остатку фраз:
- сделать для них общую группу «Некластеризованные»;
- сделать для каждой некластеризованной фразы группу из нее одной.
В сравнении я использовал оба этих параметра в виде соотношения – какой процент фраз от общего количества попал не в свою группу.
Результаты сравнения:
- Топвизор
- разные группы эталона в одной по сервису – 4%
- одна группа эталона в разных по сервису – 7%
- Pixelplus
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 7%
- Serpstat
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 3%
- Rush Analytics (132 фразы, demo)
- разные группы эталона в одной по сервису – 11%
- одна группа эталона в разных по сервису – 8%
- Just Magic
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 9%
- Key Collector
- разные группы эталона в одной по сервису – 12%
- одна группа эталона в разных по сервису – 16%
- MindSerp – не удалось получить демо, не выходят на связь
- Semparser
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 3%
- KeyAssort
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 1%
- coolakov.ru
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 18%
Группировка с агрегатными функциями
Агрегатные функции COUNT, SUM, AVG, MAX, MIN служат для вычисления соответствующего агрегатного значения ко всему
набору строк, для которых некоторый столбец — общий.
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
SELECT Author, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Author
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
SELECT Customer_ID, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Customer_ID
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору IN,
предикату EXISTS и функциям
CONCAT, COALESCE.
На сайте есть более подробный материал об агрегатных функциях и их совместном
использовании с оператором GROUP BY.
Поделиться с друзьями
Реляционные базы данных и язык SQL
Зачем группировать ключевые слова
На этапе сбора семантики мы собираем базисы и «вытаскиваем» из них максимум целевых запросов. У кого-то получаются сотни, а у кого-то тысячи в зависимости от продукта. Составлять объявления под каждый ключевик бессмысленно. Можно, конечно, автоматически подставлять запрос пользователя в заголовок в надежде повысить CTR и снизить цену клика.
Однако такой рецепт кликабельности давно стал мифом, так как:
- Большинство фраз — низкочастотники и ультранизкочастотники. Яндекс против тотального использования схемы «1 запрос = 1 объявление», так как она ведет к перегрузке серверов. Ультиматум — статус «Мало показов»;
- Всё идет к тому, что рекламодатели в Яндексе будут «бороться» не за ключевики, а за аудиторию, за конкретную потребность какого-либо сегмента ЦА. Она может выражаться разными словами. Это мы увидим далее на примере.
Выход — смысловая группировка семантики.
Допустим, у вас 10 базисов ключевых слов. Из них вы сгенерировали 300 фраз. Часть — ВЧ-ключевики — можно настроить один к одному (1 запрос = 1 объявление), а всё остальное — сгруппировать по смысловой релевантности. Это означает, что в одну группу вы собираете запросы, которые характеризуют одну конкретную потребность.
Если вы опасаетесь, что группировка повысит ставки, то напрасно, так как:
- Яндекс распознает синонимы;
- Пользователи стали умнее и уже не ведутся на подсветку запроса жирным в заголовке объявления.
Как пользоваться группировкой?
Для определения релевантных страниц нужно ввести доменное имя сайта? список поисковых запросов, который требуется кластеризовать, и поисковую систему.
Далее — выбрать метод обработки, регион, степень группировки, в чек-боксах проставляются необходимые галочки и нажимается кнопка «Проверить».

Список поисковых запросов, которые можно кластеризовать по ТОПу за один раз, достаточно велик — до 5000 фраз.
При работе доступно четыре метода кластеризации. Первые три — вполне традиционные и привычные для SEO-специалистов, четвертый — авторская разработка:
-
Сильная связь в группах (так называемый Hard-метод).
-
Средняя связь в группах (Middle).
-
Слабая связь в группах (Soft).
-
Метод «Пиксель Тулс» — уникальный алгоритм, который умеет классифицировать запросы и обеспечивает более точную группировку, так как результаты выдачи по каждому поисковому запросу подвергаются предварительной фильтрации — удалению крупных справочников («Википедия» и прочие из «чёрного списка»), витальных URL, результатов, полученных с помощью алгоритма СПЕКТР и прочих примесей, которые не являются органической выдачей поисковой системы Яндекс и искажают исходные данные.
При продвижении по трафику можно использовать Soft-метод, так как в этом случае не требуется 100% выводимость запросов в группах, а ставка идёт на их количество.
Если же задача вывести максимум запросов в ТОП — рекомендуется использовать метод группировки «Пиксель Тулс».
В инструменте доступно быстрое определение релевантных URL сайта и возможность получения количества главных страниц в выдаче по запросу, что позволяет в дальнейшем скорректировать распределение.
Степень или сила группировки может варьироваться. Рекомендуемая степень равна трем, она введена по умолчанию.
Обычно её достаточно для получения оптимальных результатов. Если группы получаются довольно малочисленные, а список поисковых запросов достаточно обширный — число можно снизить до двух.
Сила / степень — количество одинаковых URL, которые должны встретиться в выдаче по двум запросам, чтобы алгоритм мог ассоциировать их в группу.
Сервис хранит предыдущие результаты в таблице, которую можно скачать в CSV, переименовать, либо удалить.
Кластеризация семантического ядра
Кластеризация (кластерный анализ) — процесс обработки запрос и распределение их на одинаковые лексические группы, называемые кластерами. В кластер попадают запросы, которые могут продвигаться на 1 странице, совместимы между собой и похожи по смыслу.
Виды кластеризации запросов
HARD кластеризация
При данном методе в группу попадают запросы, которые на 100% совместимы между собой, группа формируется, когда URL из ТОП-10 пересекаются во всех запросах, и их количество достигает или превышает определенного порога.
В результате мы получаем большое количество групп небольшого размера за счет высокой точности группировки, метод походит для дальнейшего текстового анализа, т.к. мы будем точно уверены, что в группе нет лишних запросов.
Подходит для большинства коммерческих сайтов и тематик.
SOFT кластеризация
В группу попадают запросы, которые пересекаются URL в ТОП-10 c главным ключом и если их число совпадений достигло нужного нам порога или превысило его.
На выходе получаем меньшее количество групп большого размера за счет слабой точности пересечения запросов, идеально подходит для информационных порталов или форумов, для контекстной рекламы. В группу могут попадать слабо совместимые ключи, в следствии чего использовать такие группы для текстового анализа не рекомендуется.
Программы для кластеризации
Кроме онлайн инструментов есть еще и десктопные версии программ по кластеризации ядра (все программы работают только в Windows):
- Key Collector — 1800 рублей.
- KeyAssort — 1990 рублей. (невозможно работать на Retina дисплеях)
- Majento — , для работы необходимы XML лимиты.
Пример кластеризации семантического ядра в программе Magento:
Сервисы для кластеризации
Для автоматической кластеризации семантического ядра используют платные онлайн сервисы:
- Rush Analytics — является лучшим сервисом для кластеризации ядер, собирает данные с реальной выдачи, без использования XML. Сервис платный, но при регистрации выдается 200 лимитов, которых хватит на группировку 400 запросов в семантике.
- Just-Magic.org — также платный сервис, используется в кластеризации очень сложных тематик, когда необходимо видеть силу связи между ключевыми запросами в кластерах. При регистрации вы получаете лимит на 100 запросов.
- http://coolakov.ru/tools/razbivka/ — бесплатный сервис кластеризации ядра до 1000 запросов.
Пример кластеризации семантики от Coolakov:
Зачем нужны сервисы кластеризации?
В один кластер должны быть объединены только такие запросы, которые имеют хорошие шансы выйти в топ-10 поисковых систем с общей релевантной страницей. То есть, если по двум запросам в выдаче все страницы сайтов разные и нет пересечений, то следует относить их к разным кластерам. Также и наоборот: если два запроса возможно продвинуть на одной статье, то не следует разносить их на разные кластеры, чтобы не писать лишнего – бюджет на контент не резиновый.
Общая схема составления ТЗ на написание SEO-статьи следующая:
Сбор семантики – статистика поисковых систем, базы семантики, внутренняя статистика проекта;
Кластеризация автоматическая – сервис или программа для кластеризации по подобию топов;
«Посткластеризация» ручная – обработка того что не удалось кластеризовать автоматически;
Приоритезация – определение важности полученных запросов в каждом кластере;
Оформление ТЗ для копирайтера – лемматизация, LSI и различные указания для написания статей, по статье на каждый кластер.
Вот именно для второго пункта нужно было выбрать самый подходящий сервис автоматической кластеризации. Для этой цели я провел сравнительный анализ самых известных, на мой взгляд, сервисов.
Этап 3. Формирование структуры интернет-магазина
Анализируем леммы по каждому признаку и продумываем, под какие из них создать разделы/подразделы или фильтры.
Признак «время» сразу отсеиваем. Сюда попали слова, относящиеся к «поводу». Также удаляем признак «процесс», поскольку слово «вышивать» нерелевантное, а «купить» и так будет фигурировать практически на всех страницах магазина.
Также логично создать пункт меню по признаку «место». Назовем его «Виды декора». Подпункты — «Для гостиной», «Для кухни», «Для сада» и т. п.
Аналогично вынесем в меню признак «повод». Назовем пункт «Праздники». Подразделами будут «Декор на Новый год», «Декор на день рождения» и т. п.
На основе признака «человек» сформируем пункт меню «Подарки» с подразделами «Подарки парню», «Подарки подруге», «Подарки бабушке» и т. п.
И последний пункт меню — «Стиль», сформированный на основе одноименного признака. Подпункты — «Декор прованс», «Декор шебби шик», «Декор лофт».
Остаются признаки «предмет» и «свойство». На основе первого признака нет смысла выделять пункт меню или фильтры, мы их будем использовать в названиях разных рубрик. А вот на основе слов из признака «свойства» делаем фильтры:
- цвет (обязательно — черный, белый, красный, зеленый + другие цвета);
- материал (дерево, железо, бронза, фарфор, стекло, кварц, винил);
- расположение (напольный, настенный, настольный, подвесной декор);
- форма (круглый, овальный, квадратный, неправильной формы);
- размер (высокий, мелкий, большой);
- дополнительные характеристики (светящийся, романтический, резной, ароматизированный).
Выстраиваем структуру магазина:
Остается рассортировать кластеры поисковых запросов по разделам и подразделам.
Естественно, разделов и подразделов не хватит, чтобы разнести все 200 кластеров. Под оставшиеся кластеры создаются страницы с результатами фильтрации (например, будут страницы «Белый декор», «Круглый декор», «Романтический декор» и т. п.). Если и после этого останутся кластеры, под них оптимизируются релевантные карточки товаров.
Что такое группы объявлений в Яндекс.Директ и для чего они нужны
Отразить все преимущества товара / услуги в одном объявлении сложно. Нужно знать, какие точно «выстрелят». Для этого ставим гипотезы. Оптимально проверять по 2 варианта на группу, чтобы избежать лишних заморочек.
Функционал Яндекса берет на себя работу по тестированию и сам определяет лучший вариант из группы исходя из CTR. Система поочередно показывает по одинаковым запросам объявления с указанием разных характеристик продукта. Половина пользователей увидит первый вариант, другая — второй.
Когда наберется достаточно статистики по кликам, более кликабельная версия получит преимущество в показах. В итоге ЦА будет чаще видеть рекламу, которая точно попадает в её потребность.
В пределах группы соблюдайте правила:
- Один заголовок объявления на группу;
- Он соответствует запросу или содержит максимум слов из него.
Нет смысла пробовать разные заголовки. Кликабельность зависит от того, насколько высоко это соответствие.
Как вариант, можно использовать шаблоны Яндекс.Директ. Они позволяют автоматически подставлять в заголовок часть запроса пользователя, например, название модели. Но это подойдет только для товаров, у которых много модификаций.
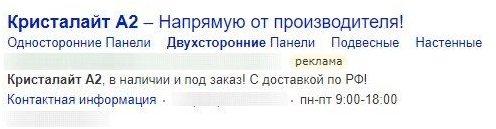
Возьмем узкую тематику — светодиодные светильники, направление «панели Кристалайт», группа «Кристалайт двусторонний». Вот ключевики группы:
- Кристалайт двусторонний A1;
- Кристалайт двусторонний A2;
- Кристалайт двусторонний A3;
- Кристалайт двусторонний A4.
Включаем в заголовок и описание шаблон: «Кристалайт двусторонний А#1#». В итоге при поиске в Яндексе светильника А2 пользователь видит объявление именно по этой модели:
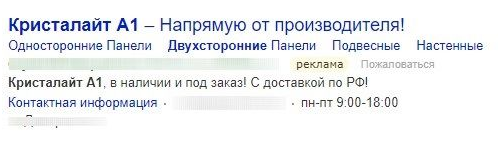
По запросу «Кристалайт двусторонний A1» аналогично:
Для нашего примера по входным дверям это не подойдет, поэтому далее мы рассматриваем общий алгоритм.
Как это работает?
Сервис в режиме онлайн производит сканирование результатов выдачи в выбранной поисковой системе, определяет, по каким запросам находятся одинаковые URL-адреса. В методе «Пиксель Тулс» — дополнительно исключает из анализа ресурсы, которые, скорее всего, не соответствуют вашему сайту и ранжируются не по общей формуле релевантности, будут исключены и результаты, найденные с помощью алгоритма «Спектр».
Время обработки зависит от количества поисковых запросов, но в целом, результат получается довольно быстро.
При скачивании в предложенном названии файла указывается метод обработки, сила группировки и дата.
В файле результатов доступна нумерация поисковых запросов в той очередности, в которой они были добавлены, что позволяет в любой момент отсортировать файл как в исходном варианте.
Также в нем присутствуют столбцы «Группа» и «Релевантный URL на сайте». Релевантный документ определяется даже в случаях, когда сайт находится за пределами ТОП-100 результатов выдачи, и он часто является оптимальной посадочной страницей для данной группы запросов.
Дополнительно выводится количество главных страниц в выдаче Яндекса или Google, что позволяет понять, какую страницу лучше продвигать. Если по большому количеству разных запросов много главных страниц в выдаче, то для оптимального продвижения рекомендуется создавать поддомены.

Еще один столбец — текущая позиция вашего сайта, которая показывает, насколько осмысленно менять релевантную страницу по данному поисковому запросу. Если сайт уже в ТОП-3, то понятно, что менять стратегию продвижения на текущий момент нет необходимости.

Столбец «Количество запросов в группе» позволяет быстро понять, какие группы требуется дополнительно разбить, а какие — наоборот, объединить.
Путем простого форматирования в Excel можно преобразовать файл в таблицу и отсортировать по любым интересующим нас свойствам: релевантному URL, количеству главных страниц либо по количеству запросов в группе.
Это позволяет довольно быстро понять, как классифицировать запросы. Например, если два запроса ассоциированы в одну группу, при этом у них разные релевантные страницы и по ним обоим по 9 или даже 10 из 10 главных страниц в выдаче, соответственно, по обоим запросам желательно продвигать именно главную страницу.
С помощью этого инструмента файл оптимального распределения запросов по посадочным страницам формируется буквально в несколько кликов.
Особенности сбора семантики по видам проектов
В зависимости от размера сайта, количества оказываемых услуг или продаваемых товаров мы собираем семантику различного размера и затрачиваем на это разное количество времени.
Средний сайт с категориями/подкатегориями, но без товаров
Если категорий на сайте много, то для начала узнаем список наиболее интересных клиенту. Если предпочтений нет, выбираем на своё усмотрение. По ним собираем слова из Яндекс Вордстата и чаще всего сразу поисковые подсказки. Если запросов набирается мало, то расширяем список с помощью дополнительных сервисов.
Работаем с получившимся списком, оптимизируем страницы под подобранные для продвижения ключевые слова.
Затем поэтапно собираем запросы для следующих категорий и т.д.
Если в процессе сбора коммерческой семантики находятся информационные запросы и позволяет время, оставляем их в отдельном списке. Такие ключевые слова часто используются в будущем при написании статей для блогов на сайтах.
Процесс отличается от предыдущего вида проекта тем, что на основе собранной семантики мы смотрим, каких срезов не хватает на сайте, но их спрашивают люди.
Срез — это страница с товарами категории или подкатегории каталога отфильтрованными по определенному параметру. Например по цвету, бренду, размеру и т.д.
Вспомним пример, который был выше, про категорию красные платья. Найденные в списке запросов для этой категории «короткие красные платья» и подскажут нам, что следует создать соответствующий срез.
Нельзя забывать, что популярными могут быть не только категории продукции, но и конкретные модели товаров. Находя такие запросы в собранном списке, мы обязательно проверяем их наличие в каталоге сайте.
Примечание. При формировании итогового списка запросов обязательно учитываем геозависимость, коммерциализацию и максимальную достижимую позицию. Почитать об этих факторах можно в нашей статье.
Пошаговая кластеризация на реальном примере
После сбора семантического ядра, его надо распределить по группам и составить структуру будущего сайта, если мы делаем семантику для нового сайта.
В самом начале нам надо принять решение, будем ли мы составлять структуру на основании распределённого по группам семантического ядра или на основании логики/конкурентов. Если второй вариант, то загружаем в программу готовую структуру, которую предварительно составили.
Если же первый вариант, то импортируем ядро, а структуру будем составлять после кластеризации, глядя на готовые группы. В данном примере мы импортируем файл с параметрами, т.к. нам важна частота запросов для дальнейшего принятия решения относительно того, какие группы мы будем использовать в первую очередь, а какие не будем использовать вообще.
Вот как это будет выглядеть после импорта:

Т.к. последнее время Google становится всё популярнее и популярнее Яндекса, принимаем решение собирать данные именно с google.
После регистрации на сервисе XMLRiver, пополняем счёт (1), в разделе «Покупка запросов» (2) копируем ссылку для запросов (3):
Эту ссылку нам надо вставить в окно настроек программы (1), установить топ10 (2) и другие настройки, связанные с местоположением:

Относительно топ10 – больше ставить нет никакого смысла, у Гугла в подавляющем большинстве случаев достаточно качественная выдача и увеличение количества собранных данных не приведёт к улучшению качества кластеризации.
Региональность можно указать как в программе, так и в настройках сервиса
Однако обратите внимание, что если эти данные указаны и в одном и во втором месте, приоритет будет у указанных в программе

Если указываете местоположение в программе, числовое значение этого местоположения надо брать из файла на скриншоте.
Также стоит упомянуть, что если вы хотите собрать данные, например, по Москве, то домен надо выбирать ru, язык — Russian, страну – Russia. Иначе данные могут быть не точны.
После описанных выше настроек и сбора данных переходим непосредственно к процессу кластеризации. Тематика у нас не самая конкурентная, поэтому выбираем вид кластеризации Middle с миграцией (это можно сделать горячими клавишами ctrl+Tab) и попробуем силу группировки 3. Если в результате получится слишком много групп с одним интентом, надо уменьшить силу кластеризации, если же фразы в группах будут слишком разнородными – увеличить и снова провести процесс кластеризации. Для этого заново собирать данные не требуется, достаточно нажать на кнопку «Восстановить», при этом семантическое ядро вернётся в первоначальное состояние до процесса кластеризации.
В нашем случае результат был достаточно хорошим, и, после небольших ручных правок, вырисовалась картина по структуре сайта, которая сразу была создана, а группы распределены по своим категориям.
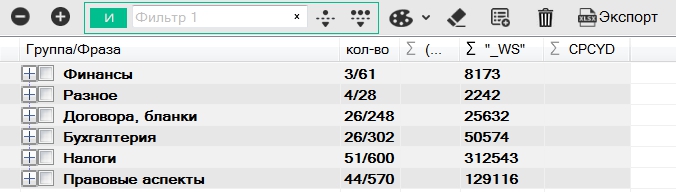
Методы кластеризации
Кластеризация запросов производится по SERP (search engine results page) – странице результатов поиска.
Есть два метода кластеризации:
- Soft-кластеризация – это попарное сравнение выдачи по всем запросам. Запросы объединяются в кластер, если получается заданное количество одинаковых результатов.
- Hard-кластеризация – более сложное сравнение результатов поиска. Выдача сравнивается не только попарно, но и между всеми запросами внутри кластера. Объединение в группы происходит при таком же условии.
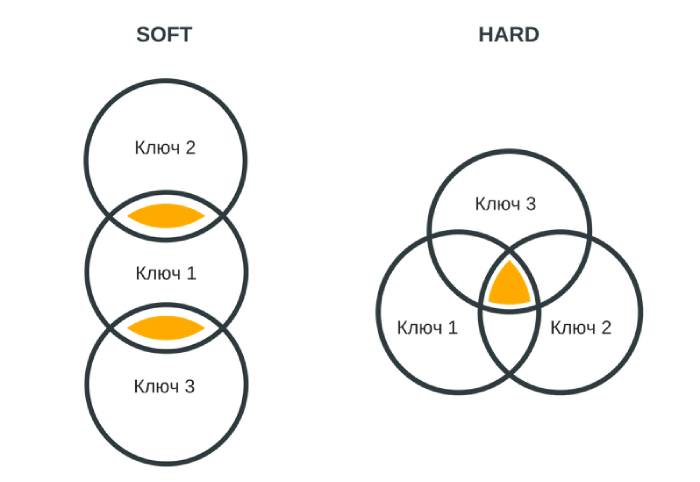 Схемы этих двух методов кластеризации запросов
Схемы этих двух методов кластеризации запросов
После soft-кластеризации получается слишком широкая семантика, включающая множество нетематических запросов. В итоге такое семантическое ядро нужно дольше чистить и приводить в порядок. Hard-кластеризация же дает более точный результат.
Что такое семантическое ядро
Начнем с азов. Семантическим ядром (семантикой) называют упорядоченный набор запросов, которые характеризуют услугу, продукт или вид деятельности, представленный на сайте наиболее точным образом. Сбор семантики – это первый шаг на пути к поисковому трафику. Запросы, распределенные по страницам сайта, помогают «Яндексу» и понимать, о чем именно страницы ресурса, и предлагать эти веб-страницы пользователям в соответствии с их поисковыми запросами.
Собранные разными способами поисковые слова группируются, на основании анализа полученных групп составляется ментальная карта с распределением слов по конкретным страницам. После этого в соответствии с полученной схемой создаются материалы для сайта и оптимизируются страницы.
Процесс объединения ключевых слов из ядра в тематические группы называется кластеризацией.
Заключение
Я рекомендую всегда применять кластеризацию при продвижении сайта, независимо от количества продвигаемых запросов. Исключение составляют только тематики, в которых конкуренция сверхнизкая – качественная группировка запросов по методу топов в таких тематиках практически невозможна ввиду отсутствия в выдаче релевантных ответов.
Главное преимущество использования автоматической кластеризации — это, прежде всего, ускорение работы, что особенно актуально при разборе больших ядер. Используя кластеризаторы, SEO-специалист может разгруппировать огромное количество запросов всего за несколько часов, раньше на выполнение такого же объема работы могли уйти недели или даже месяцы.
Автоматическая кластеризация не дает 100% точного результата, в большинстве случаев кластеры необходимо дорабатывать вручную. Но она существенно упрощает работу оптимизатора, позволяет создать максимально правильную структуру сайта и подготовить грамотные ТЗ.
Материалы по теме: